






前言
2025年被认为是"The Year of Agent",是大模型从Chatbot转向可执行动作的Agent的一年。我们也确实在去年年底到现在看到了很多Agent相关的产品或协议出现:
-
Operator (Computer Use Agent)
-
Deep Research
-
MCP/A2A
-
Manus
-
GenSpark
-
...
这让我们看到了AGI到来的曙光。一旦Agent能替代80%的人类白领工作,那么AGI也就可以认为得到了实现。
作为技术乐观主义者,我曾对此充满信心,并认为这是在1-2年内可实现的目标。这样的信心来自于过去一年我们看到的大模型在很多benchmark上快速饱和。个人也亲身感受到MATH是怎么在短短几个月内从不及格干到90+的。
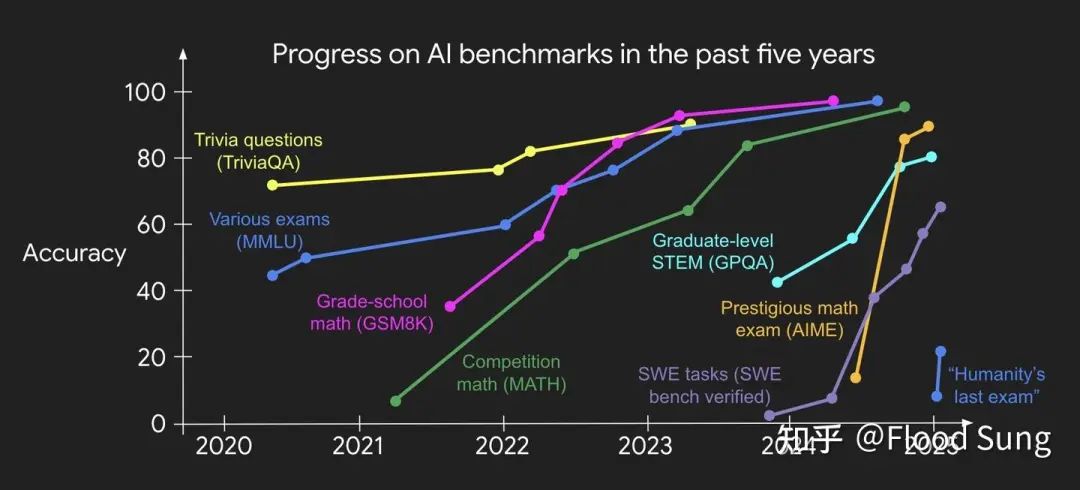
https://x.com/_jasonwei/status/1889096555254456397
这种指数型攀升的趋势让我们对大模型的未来极度乐观,并由此将这个经验迁移到Agent上认为可以一样快速复刻这样的成功,也就是“速胜论”。
然而事实会是这样吗?
恐怕不是!
01
AI做题和做事的Gap
我们畅想着AGI革命能够给我们GDP带来指数级的提升,但是目前出现了一个非常尴尬的局面:
大模型已经在做题上超过了普通PhD的水平,但在贡献GDP上却依然非常有限。
高分低能大概就是现在大模型的真实写照。除了少数特定场景,如写文案,文生图等,大部分真实的工作场景大模型还很难直接发挥作用。做Agent的目标也很清晰直接,就是要补上这个低能的短板,让模型真的有能力去自己干活。
那为什么会有这么大的Gap呢?
2.1 数据是最根本的Gap
纵观深度学习十几年的发展,数据问题永远是第一位的。AI在不同领域的发展速度也完全取决于数据的获取难度。
为什么我们比较共识的认为通用机器人的落地速度要慢很多根本原因在于我们要获取对应的数据难度非常大。目前发展出的遥操作+模仿学习的方法已经比之前能收集的数据多很多,但相比于海量的视频数据,仍然差距非常大。
那为什么大模型在做题上突飞猛进呢?原因也很直接。因为我们有海量现成的题。有了新的RL范式加上海量现成的题,这个事情就变得容易了很多。理论上,我们可以把人类所有已有的有标准答案的题都让大模型来学。而且除了RL外,本身pretraining就包含了海量的做题数据,写文案数据等等。这些都是上图benchmark快速饱和的一些根本原因。
回到Agent,虽然我们更多的是指虚拟场景下的Agent,但我们面临着和通用机器人一样的数据困境:
- 没有真实的数据可以直接模仿
- 没有现成的任务可以用来强化学习
对于1,Agent核心是能调用工具,并利用工具返回的结果进行推理决策。整个轨迹的数据在人类已有的互联网数据可以认为就不存在。所以,要想有这样的轨迹数据要么合成要么收集人类的轨迹,但这个收集的难度和成本就很高且不容易scale了。
对于2,这也是很有意思的一点。在现实世界中,我们往往是通过考试这种间接的形式来判断一个人在某个方向的专业程度。比如我们面试程序员,我们不太可能让其完整的做一个project,而是去考leetcode题。所以,我们没有或者极少像数学题代码题这种现成的题/任务来训练Agent。大部分题都得造。问题是造题造任务一样是一件不容易scale的事情。相比机器人唯一的优势在于如果是在虚拟场景,比较容易做强化学习。
因为有这个数据层面的Bottleneck,Agent的发展速度会比想象的慢很多。
可能这里有人会问最近出来的那么多Agent产品感觉很厉害,日新月异,怎么就会慢呢?
这就涉及到评价标准的问题了。
Agent好不好需要基于真实职业的标准去衡量。
这就和自动驾驶一样了。Agent能力可以根据具体的任务方向定义L1到L5,然后我们可以评估其能力可以到什么程度。
那么既然Agent和自动驾驶是一样的,或者其实自动驾驶属于其中的某个Agent。那么从自动驾驶的落地我们也可以看到问题了。
2.2 有人到无人的Gap
自动驾驶已经搞了10多年,目前也就Waymo在小范围基于高精雷达建图的方式实现了L4,而Tesla虽然也无限接近了,但还需要更多时间。
当然,自动驾驶的核心问题在于其对安全性的要求极其之高,你必须做到几千公里不需要接管甚至0接管才算成功。
我们可以换个场景也就是机械臂抓取问题。这个前几年也有好多家公司如covariant,xyz robotics等在做。那么这个就面临是如何替代人的问题。如果抓取准确率只有70-80%,那么每一个机器人都需要一个人来看着,没有意义。抓取准确率需要做到99.9%(具体数值有点忘了),可以比如一个人看4个机器人,到99.999999% 那么才能几乎不需要人存在自主化运行。
同样的道理应用到Agent上就是
我们需要把Agent的Performance在某个领域做到极高的准确率达到L4才能实现完全替代,在很长时间内Agent的能力将一直在L2上,作为辅助作用存在。
举个例子就是Code。之前我的观点是Cursor将很快被取代,它只是一种中间形式,manus/devin这种才是最终形式。但现在我的观点是Cursor没那么容易被取代,llm会作为copilot在比较长的时间内存在。它能帮你快速的补全,prototype出一些东西,但真正遇到复杂的问题才是程序员需要处理的核心问题,llm要达到L4就有点难了。就如swe bench,现在sota可以到70%分,这是机械臂抓取的demo水平,得能搞到90%甚至99%的水平,能极大概率解决问题用户才可能买单,否则这个roll一次成本很高,结果给你代码一通乱改还没改对就直接劝退了。更何况目前的swe bench也不能代表一切,离agent在我们实际工作的代码里去写入一个关键feature 恐怕还比较远,而这种真正的面向工作场景的题怎么出怎么verify都是很难的问题。
也就是在Code方向上,如果我们需要一两年内能直接替代我们自己是几乎不可能的,但是你说让ai写个简单web并部署则是可行的。所以这里涉及到Agent不同场景上的实现难度问题,下面会讲。
02
Agent的“持久战”

基于上面分析的几点Gap,我们已经得出了结论,要想实现AGI,达到能替代80%的人类白领工作的Agent,是需要非常漫长的时间,可能要5-10年甚至更久,除非有全新的颠覆性技术出现。
所以,不管是Sam Altman还是Dario Amodei 说AGI这一两年就能实现就是一种Hype了。

这种感觉就像n年前说自动驾驶很快就会实现一样。逻辑上AGI怎么做确实大家都知道了搞RL,但我们需要数据。

所以有了上面对Agent的判断,我们其实可以更从容的去打这场Agent/AGI的战争。这会存在一条比较长时的增长曲线,中间要经历无数个不同的milestone才能抵达我们想要的水平。
相比自动驾驶这种单一任务,大模型最大的好处还是在于它的通用性,覆盖的场景非常多,有的场景非常简单已经可以落地,有的场景非常难需要更多时间,所以它永远有增长的空间。
还是以coding为例,现在模型开始可以写web,那么接下来模型是不是可以写个简单app,再接下来模型是不是可以前后端全包去复刻一个复杂的app比如抖音。这些都是不断的挑战,解锁越来越复杂的场景,直到我们能够vibe coding创造一个公司。
由此,我们看到大模型落地会是循序渐进而不是突变式的。而这个事情要持续很多很多年,这可以给大家很大的信心,因为一直有事情做,不用过于担心马上被取代掉哈哈。
路漫漫其修远兮,吾将上下而求索!
一起加油!创造Agent的新世界!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









