







AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100+应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等干货。

截至目前,星球内已经累积了2000+AICG时代的前沿技术、干货资源以及学习资源;涵盖了600+AIGC行业商业变现的落地实操与精华报告;完整构建了以AI绘画、AI视频、大模型、AI多模态以及数字人为核心的AIGC时代五大技术方向架构,其中包含近500万字完整的AIGC学习资源与实践经验。

论文链接:Janus/janus_pro_tech_report.pdf at main · deepseek-ai/Janus · GitHub
前言
Janus 是 DeepSeek 团队提出的一个统一多模态理解与生成的模型,能够在单一模型中实现图像理解和文本到图像生成的双重任务。在多模态理解方面,Janus可以处理图像描述、视觉问答(VQA)、地标识别、文字识别等多种任务;在多模态生成方面,Janus也可以根据输入的文本描述生成高质量的图片。Janus-Pro是其最新的升级版本。
Janus的核心创新点在于将多模态理解与生成的视觉编码进行解耦,从而缓解了这两个任务潜在存在的冲突。Janus-Pro在此基础上,优化训练策略(包括增加训练步数、调整数据配比等)、增加数据(包括使用合成数据等)、扩大模型规模(扩大到70亿参数),从而同时提高了模型的多模态理解和生成能力。
Janus 模型架构
Janus和Janus-Pro结构一致,均使用两个独立的编码器来理解和生成图像,而不像之前的做法依赖单个编码器来处理这两项任务。对于图像理解,Janus 使用 SigLIP 编码器将图像转换为丰富的语义特征;而对于图像生成,Janus 使用 VQ Tokenizer 将图像转换为离散标记。这种解耦的设计带来两个收益:
1)将多模态理解与生成的视觉编码解耦,缓解了多模态理解和生成不同粒度需求的冲突;
2)理解和生成任务都可以分别采用各领域最先进的编码技术,可输入其他模态例如点云或音频数据,并使用统一的Transformer进行处理。
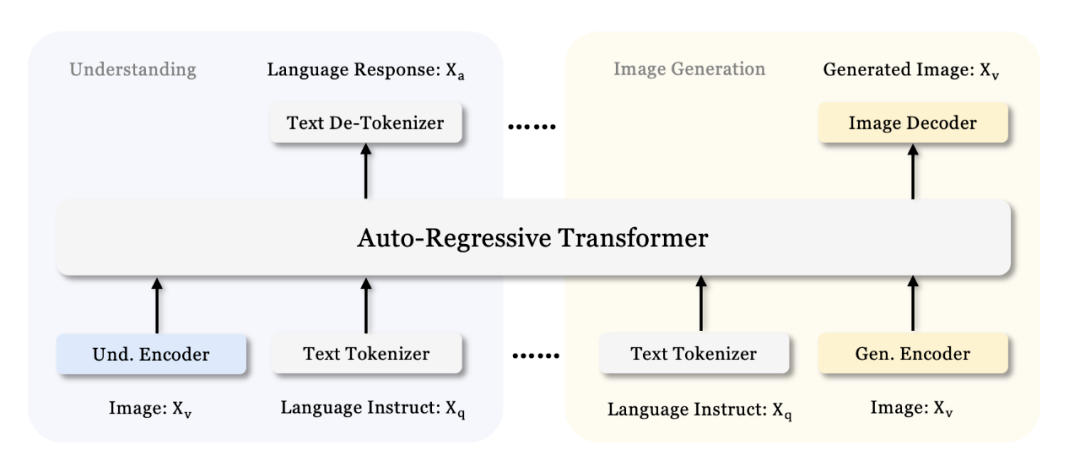
对于纯文本理解、多模态理解和视觉生成任务,Janus采用独立的编码方法将原始输入转换为特征,然后通过统一的自回归 Transformer 进行处理。具体来说:
文本理解:使用大语言模型(LLM)内置的分词器将文本转换为离散的 ID,并获取每个 ID 对应的特征表示。
多模态理解:使用 SigLIP 视觉编码器从图像中提取高维语义特征。这些特征从 2D 网格展平为 1D 序列,并通过一个两层MLP的理解适配器Adaptor将这些图像特征映射到 LLM 的输入空间。
视觉生成:使用 VQ Tokenizer将图像转换为离散的 ID。将 ID 序列展平为 1D 后,使用一个生成适配器Adaptor将每个 ID 对应的码本嵌入映射到 LLM 的输入空间。然后,将这些特征序列连接起来,形成一个多模态特征序列,随后输入到 LLM 中进行处理。
在纯文本理解和多模态理解任务中,Janus都是使用 LLM 内置的预测头进行文本预测;而在视觉生成任务中,Janus使用随机初始化的预测头进行图像预测。整个模型是使用 Next-Token-Prediction 的方式进行训练的,采用 causal attention mask,和 LLM 的训练方式一致,遵循自回归框架。
Janus代码解析
代码目录:PaddleMIX/paddlemix/models/janus at develop · PaddlePaddle/PaddleMIX · GitHub
(1)文本生成代码
调用模型的 generate 方法生成回答。
输入参数包括:
- input_ids: 文本输入的 token ID 序列。
- inputs_embeds: 处理后的嵌入向量。
- position_ids: 位置 ID 序列。
- attention_mask: 注意力掩码,用于指示哪些位置是有效的输入。
- pad_token_id, bos_token_id, eos_token_id: 分别表示填充、开始和结束的特殊 token ID。
- max_new_tokens: 最大生成的新 token 数量,这里设置为 128。
- do_sample: 是否使用采样生成文本,这里设置为 False,表示使用贪婪解码。
- use_cache: 是否使用缓存机制加速生成。
(2)图像生成代码
1.方法: generate
2.参数:
- mmgpt:JanusMultiModalityCausalLM类就是一个Janus模型的实例,负责生成图像和文本。
- vl_chat_processor: 多模态对话处理器,用于处理文本和图像的输入。
- prompt: 输入的文本提示,用于引导图像生成。
- temperature: 采样温度,控制生成的随机性。值越低,生成结果越稳定。
- parallel_size: 并行生成的图像数量。
- cfg_weight: Classifier-Free Guidance(CFG)权重,用于控制条件生成和无条件生成的混合比例。
- image_token_num_per_image: 每张图像对应的 token 数量。
- img_size: 生成图像的尺寸。
- patch_size: 图像分割的 patch 尺寸。
3.步骤:
1)文本处理:使用vl_chat_processor的分词器将文本提示编码为输入ID,然后转换为Paddle张量。
2)初始化token:创建一个用于存储输入token和生成图像token的张量。对于并行生成的每个样本,都复制输入token,并在奇数索引的样本中插入填充token。
3)输入Embedding:将token转换为模型可以理解的Embedding形式。
4)生成图像token:通过一个循环,逐步生成图像的每个token。在每个步骤中:
- ·更新position id 以反映当前token生成的位置序号。
- ·使用模型的语言模型部分生成下一个token的概率分布。
- ·根据条件和无条件生成的 logits 以及温度调整概率分布。
- ·使用paddle.multinomial根据调整后的概率分布采样下一个token。
- ·使用生成的token生成图像Embedding,并更新输入Embedding以用于下一次迭代。
5)解码图像:将生成的图像token解码为图像数据。
6)后处理和保存:将解码后的图像数据标准化为0-255之间的整数,并保存为JPEG文件。
Janus快速体验
飞桨星河社区教程链接:
【PaddleMIX】快速体验DeepSeek的多模态理解生成模型 - 飞桨AI Studio星河社区
我们以Janus-Pro-1B为例,在单卡V100上只需7G显存即可推理完成图像理解和图像生成。
下载 PaddleMIX代码库:
# clone PaddleMIX代码库
git clone https://github.com/PaddlePaddle/PaddleMIX.git
cd PaddleMIX安装PaddlePaddle环境
# 提供三种 PaddlePaddle 安装命令示例,也可参考PaddleMIX主页的安装教程进行安装
# 3.0.0b2版本安装示例 (CUDA 11.8)
python -m pip install paddlepaddle-gpu==3.0.0b2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# Develop 版本安装示例
python -m pip install paddlepaddle-gpu==0.0.0.post118 -f https://www.paddlepaddle.org.cn/whl/linux/gpu/develop.html
# sh 脚本快速安装
sh build_paddle_env.sh安装PaddleMIX环境
# 提供两种 PaddleMIX 依赖安装命令示例
# pip 安装示例,安装paddlemix、ppdiffusers、项目依赖、paddlenlp
python -m pip install -e . --user
python -m pip install -e ppdiffusers --user
python -m pip install -r requirements.txt --user
python -m pip install paddlenlp==3.0.0b3 --user
# sh 脚本快速安装
sh build_env.sh图像理解命令
# Janus/Janus-Pro understanding
python paddlemix/examples/janus/run_understanding_inference.py \
--model_path="deepseek-ai/Janus-Pro-1B" \
--image_file="paddlemix/demo_images/examples_image1.jpg" \
--question="描述一下这个图片。" \
--dtype="bfloat16"结果:

这张图片展示了一只红熊猫,它正趴在木板上,背景是一些树枝和绿色的树叶。红熊猫的毛色主要是棕色和白色,它的耳朵和脸部有明显的白色毛发,眼睛周围有白色的斑纹。红熊猫看起来非常可爱,它似乎在休息或观察周围的环境。
图像生成命令
# Janus/Janus-Pro generation
python paddlemix/examples/janus/run_generation_inference.py \
--model_path="deepseek-ai/Janus-Pro-1B" \
--prompt="江边有一艘船。" \
--dtype="bfloat16"结果:

PaddleMIX中已经复现了Janus 和 Janus-Pro 的推理流程,通过解析代码我们也更深入地理解模型的实现细节和技术创新,跟着教程链接一起动手实践一下吧!
推荐阅读
AIGCmagic社区介绍:
2025年《AIGCmagic社区知识星球》五大AIGC方向全新升级!
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
2025年《AIGCmagic社区知识星球》五大AIGC方向全新升级!
AI多模态模型架构之模态生成器:Modality Generator
AI多模态实战教程:
AI多模态教程:从0到1搭建VisualGLM图文大模型案例
AI多模态教程:Mini-InternVL1.5多模态大模型实践指南
AI多模态实战教程:面壁智能MiniCPM-V多模态大模型问答交互、llama.cpp模型量化和推理
技术交流
加入「AIGCmagic社区」,一起交流讨论,涉及AI视频、AI绘画、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【lzz9527288】,备注不同方向邀请入群!
更多精彩内容,尽在「AIGCmagic社区」,关注了解全栈式AIGC内容!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









