



点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看讲者讲解回放!
作者简介
虞健翔,华东师范大学博士生
概述
近年来,科学论文的快速增长压倒了传统的审查机制,导致出版物的质量参差不齐。尽管已有方法探索了大型语言模型(LLMs)在自动化科学审查方面的能力,但它们生成的内容往往是通用的或片面的。为了解决上述问题,本文介绍了一个自动化论文审查框架SEA。它包括三个模块:标准化、评估和分析,分别由模型SEA-S、SEA-E和SEA-A代表。首先,SEA-S提炼了GPT-4的数据标准化能力,用于整合对一篇论文的多个评审。然后,SEA-E利用标准化数据进行微调,使其能够生成建设性的评论。最后,SEA-A引入了一种新的评估指标,称为不匹配分数,以评估论文内容和评论之间的一致性。此外,本文设计了一种自我修正策略,以增强一致性。在八个会议的数据集上进行的广泛实验结果表明,SEA可以为作者生成有价值的见解,以改进他们的论文。
论文地址:https://arxiv.org/pdf/2407.12857
代码链接:https://ecnu-sea.github.io/
Background
近年来,人工智能领域或机器学习领域的各大会议投稿数量不断增加,人们经常在各大公众号上看到诸如某会议投稿数量再创新高的消息。
随着投稿数量的增加,评审工作量也随之大幅增加。这可能导致一些问题,比如审稿质量参差不齐。在公开的社交媒体上,也时常能看到一些主席委员(AC)或投稿人对评审质量的负面反馈。
另一方面,近年来大模型的发展非常快速且火热。大模型以其强大的文本处理能力在各个领域,尤其是垂直领域中得到了广泛应用。
Motivation
基于以上背景,作者希望探索大模型在自动化同行评审中的应用。研究的主要动机是期望自动化评审能够为研究者提供及时且有价值的反馈和意见,提升工作质量。例如,投稿周期有时可能长达三个月甚至更久,通过自动化评审,科研学者可以在高完成度的情况下投递稿件,从而能够快速投入到下一个研究项目中,加快科研进度。

Introduction
现有的一些自动化审稿方式主要分为两类。第一类是基于提示(prompt)的方式,大模型在训练阶段或者强化学习阶段(RLHF)往往需要与人类偏好对齐,这导致大模型在推理时倾向于讨好人类,生成的评审意见往往价值较低,或者给出的意见过于笼统。另一种方法是基于监督微调(SFT)的,这些方法使用对应一篇文章的单个评审意见进行微调,这样得到的结果可能存在片面性。训练数据可能来自不同的会议或不同年份,评审的格式和标准也各不相同。
在右侧的图中,模拟了一篇文章可能收到的三个评审意见。一个评审可能指出文章的写作需要提升,另一个可能建议增加一些图例,还有一个可能希望增加更多解释性文本。在理想的评审意见中,期望能够整合这三个评审的意见,提供一个更加全面和高质量的评审反馈。

Method
接下来介绍研究方法的具体实施步骤。本研究的流程主要分为三个部分:标准化、评估和分析。
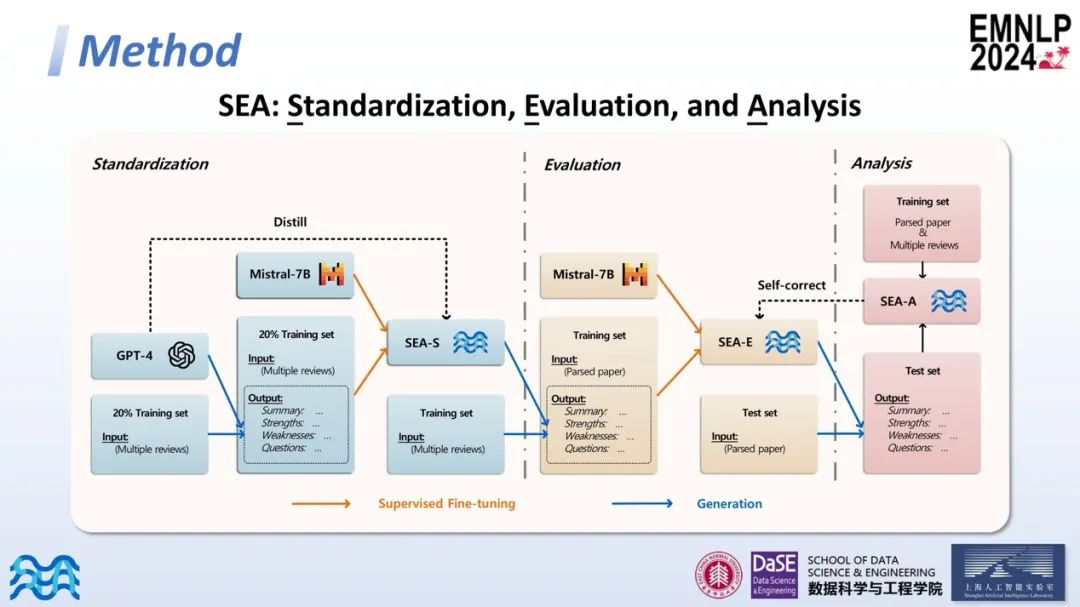
在标准化部分,作者希望整合一篇文章的所有评审意见,消除冗余和错误,集中关注文章的优点和缺点。具体来说,作者使用了训练集20%的数据,并借助GPT-4对这些评审意见进行整合,形成统一的格式和标准。这构成了一个特定微调的数据集。
随后,作者对一个适应长文本的开源模型Mistral-7B进行微调,以蒸馏GPT-4的数据整合能力,最终得到数据标准化模型SEA-S。值得一提的是,SEA-S提供了一种泛化范式,可以应用于其他领域以获得标准化的评审意见。

接下来,作者将训练集中所有文章的评审意见输入到SEA-S模型中,以获得标准化和高质量的评审意见。然后,对论文进行解析,包括PDF解析和文本及代码提取。基于解析后的论文、标准化的评审意见及定制的提示,我们形成了另一个指令微调数据集,并微调另一个Mistral-7B模型,得到SEA-E。
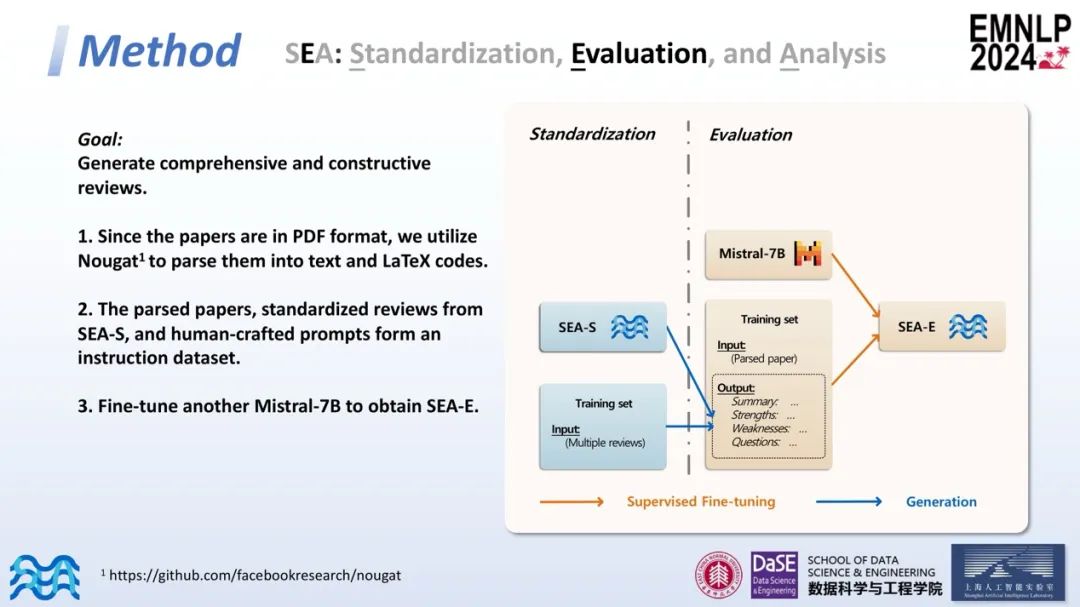
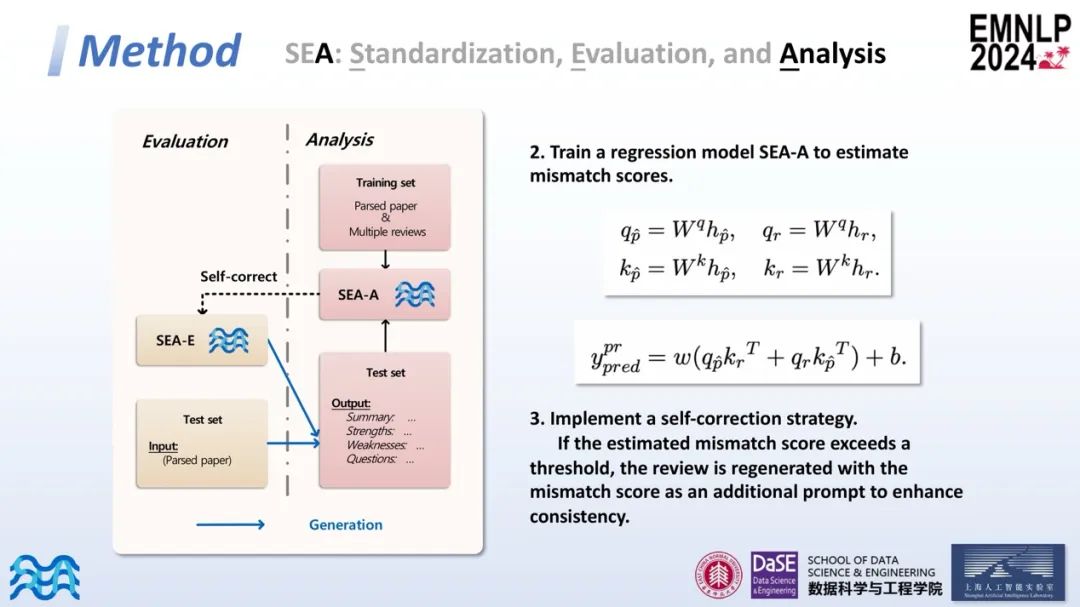
经过以上处理后,SEA-E可以生成规范且高质量的评审意见。生成评审后,团队对这些评审进行了进一步的分析。引入了一个新的度量标准——不匹配度分数(Mismatch score),用以衡量论文与生成评审的一致性。具体来说,在训练集中计算每篇文章的加权平均分,并据此计算每个评审意见的不匹配度分数。在公式中,c表示评审的置信度(confidence),s表示评审打出的分数(score)。不匹配度分数是评审的评分减去加权平均分,作为一个参考标准。较高的不匹配度分数表示评审意见与论文偏离较大,可能意味着较低的审稿质量;接近于0的不匹配度分数表示评审意见相对中立,与论文较一致。

接着,作者计算了论文和评审之间的相互注意力,并训练了一个回归模型SEA-A来估计不匹配度分数。在训练完模型后,实施了一个自我矫正机制:如果SEA-E生成的评审超过了一定的阈值,则重新生成该评审,加入新的提示以提高其与论文的一致性。
Demo
接下来,作者展示了一些生成的示例,这些示例主要分为六个部分:总结(summary)、优点(strengths)、缺点(weaknesses)、问题(questions)、四个评分以及对论文的决定(接受或拒绝)和相应的理由。值得高兴的是,这些生成的评审意见与作者在实际投稿过程中收到的评审意见高度一致。

接下来展示的示例是对比本文所提方法与基线模型的效果。Mistral-7B作为一个直接推理模型,我们发现其在评分部分(如Soundness)中,无法很好地遵循指定格式,因此输出的并不是分数而是文本。Mistral-7B random则是根据一个随机选取的评审意见进行监督微调得到的结果,相对来说内容比较单薄。而Mistral-7B 3.5则替换了SEA-S的标准化模块,用GPT-3.5进行整合,最终得到的评审结果中存在一些冗余和无效的信息。
对于本文方法生成的评审SEA-E和SEA-EA(SEA-EA是加入分析模块和自我矫正机制产生评审结果),可以看出这种方法生成的评审格式规范,内容丰富。

Experiment
Main result
具体来看生成内容的质量,在主实验中,研究者使用了NIPS 2023和ICLR 2024的80%数据作为训练集。在测试时,研究者使用了跨领域(cross-domain)和同领域(in-domain)两个大模块的数据集。在所有这些数据集中,研究方法的流程所生成的评审结果表现最为优异。

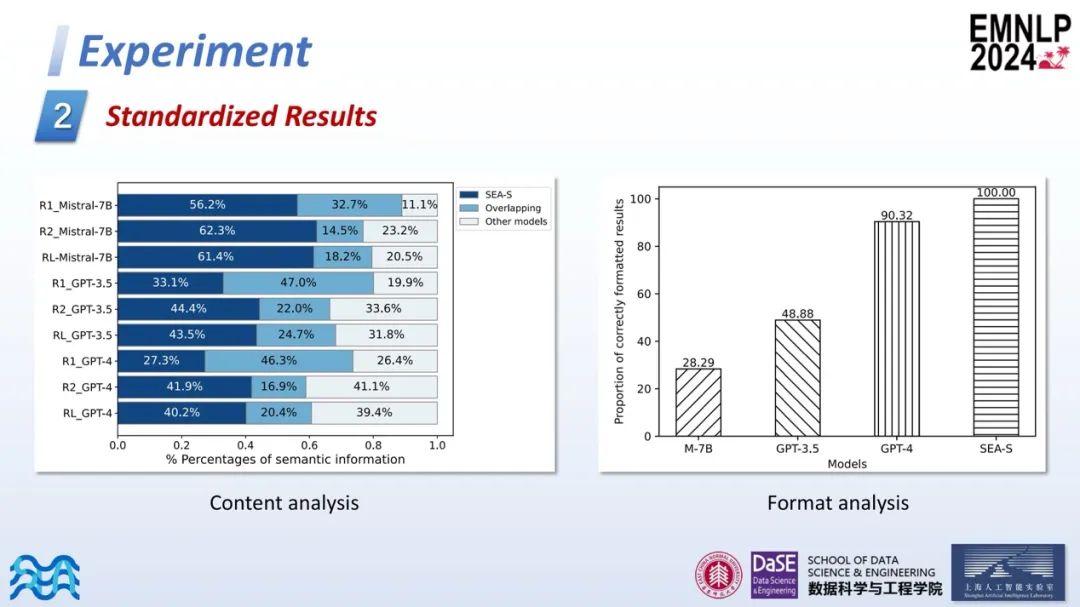
Standardized Results
第二部分是对SEA-S标准化结果的测试。比较了SEA-S与其他模型生成的标准化结果后发现,在内容丰富性上,SEA-S生成的结果明显更为丰富。在格式遵循方面,SEA-S能够百分之百地遵循指定格式,表现超越了作为蒸馏模型的GPT-4。
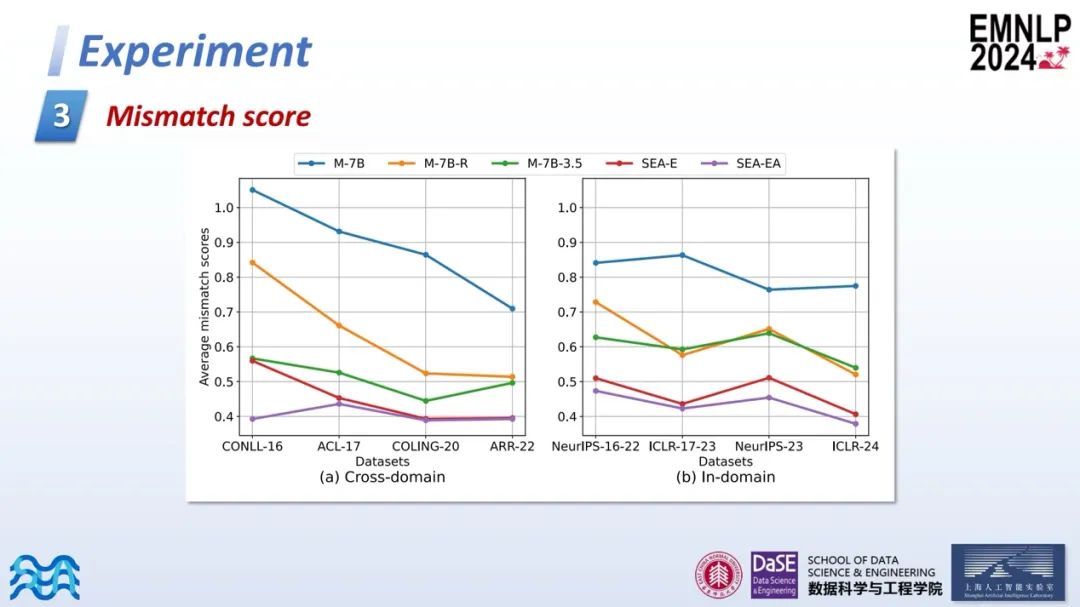
Mismatch score
第三部分是关于不匹配度分数(Mismatch score)的测试。在研究流程中,SEA-E和SEA-EA的Mismatch score分值均为最低,这表明它们与论文的一致性最高。
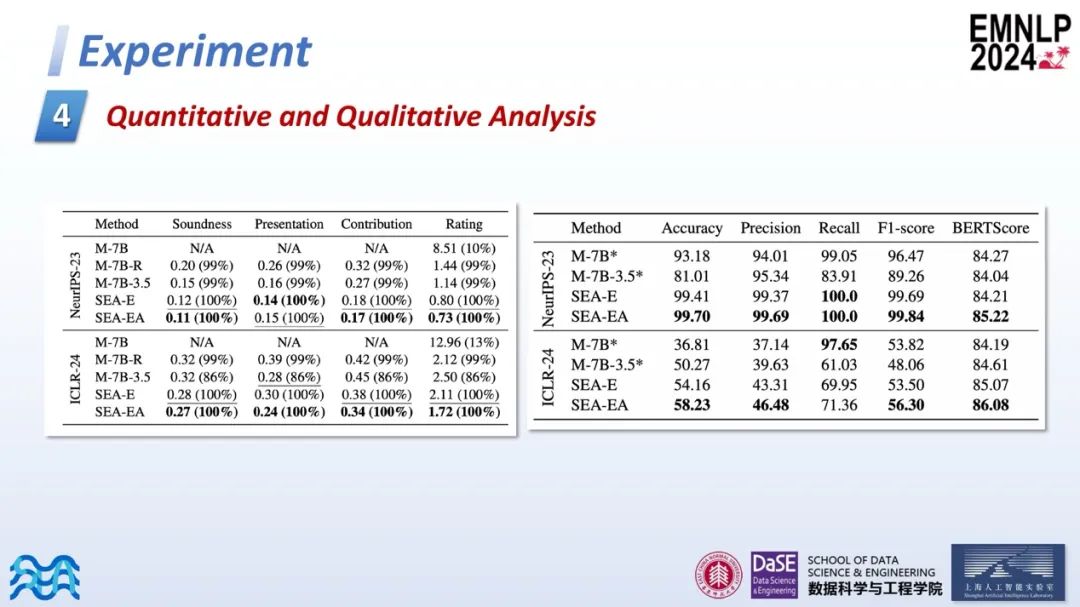
Quantitative and Qualitative Analysis
此外,作者对生成的四个评分进行了定量分析。研究通过计算生成评分与真实评分之间的均方误差(MSE)来进行评估,括号内表示有效生成的评分,因为并非所有模拟生成的评审内容都是有效的。右侧进行了定性分析,主要关注录取(accept)和拒绝(reject)的决策。
在NIPS 2023的数据集中,由于大部分论文被录取,因此整体指标较高。在ICLR 2024的数据集中,Mistral-7B的召回率(recall)很高,但精确率(precision)较低,这说明其更倾向于接受论文。SEA模型在一定程度上缓解了这一问题,主要是因为错误样本集中在评分中等的论文。
Human and GPT evaluation
第五部分是最后进行的人工评估和GPT评估。作者从不同维度来衡量生成评审和标准化结果的质量,SEA在这些评估中均获得了一致的好评。

Conclusion
总结本研究的工作,研究团队提出了一个自动化同行评审框架SEA。首先,通过使用SEA-S,可以将不同会议的评审内容进行标准化。其次,作者设计了自我矫正机制和不匹配度分数(Mismatch score)来提高论文与评审的一致性。实验结果显示,SEA在各个方面均展现了其优越性。
最后,作者希望这一工作能够为广大科研工作者提供帮助,助力未来的科研进步。

本期文章由陈研整理
往期精彩文章推荐

NeurIPS 2024 | AutoManual让大模型智能体像人类一样通过记笔记来适应新环境
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看讲者回放!


















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









