






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

点击 阅读原文 观看作者讲解回放!
作者简介
胡健,伦敦大学玛丽女王学院的博士生,导师是龚少刚教授,这篇文章是在龚少刚教授和严骏驰教授的指导下完成的。
概述
在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。然而,最新发表于 NeurIPS 2024 的研究《Leveraging Hallucinations to Reduce Manual Prompt Dependency in Promptable Segmentation》提出了一个有趣的观点:这些幻觉实际上可以被转化为有用的信息源,从而减少对手动提示的依赖。
这项研究由来自伦敦大学玛丽女王学院和上海交通大学的研究团队进行的,他们开发了名为 ProMaC 的框架,该框架创新性地利用了大模型在预训练过程中产生的幻觉。不仅能够准确识别图像中的目标对象,还能判断这些对象的具体位置和形状,这在伪装动物检测或医学图像分割等复杂任务中表现尤为出色。

论文地址:
https://arxiv.org/abs/2408.15205
代码链接:
https://github.com/lwpyh/ProMaC_code
项目网址:
https://lwpyh.github.io/ProMaC/
研究动机
该研究专注于一种具有挑战性的任务:通用提示分割任务(task-generic promptable segmentation setting)。在这个框架下,该研究只提供一个任务内的通用提示来描述整个任务,而不会具体指明每张图片中需要分割的具体物体。例如,在伪装动物分割任务中,该研究仅提供 “camouflaged animal” 这样的任务描述,而不会告知不同图片中具体的动物名称。模型需要完成两项主要任务:首先,根据图片内容有效推理出具体需要分割的目标物体;其次,准确确定目标物体的具体位置和分割的形状。
尽管如 SAM 这类大型分割模型的存在,能够在提供较为精确的位置描述时有效地进行物体分割,但在伪装样本分割或医学图像分割等复杂任务中,获取这种精确描述并不容易。以往的研究,如 GenSAM [1],提出利用 LLaVA/BLIP2 这类多模态大模型(MLLMs)来推理出特定样本的分割提示,以指导分割过程。然而,这种方法在处理像伪装样本分割这样的场景时,往往因为目标共现偏差(object co-occasion bias)存在而导致问题。例如,在一个只有草原的图像中,如果训练数据中狮子通常与草原共现,LLaVA 可能会偏向于预测草原中存在伪装的狮子,即使图中实际上没有狮子。这种假设的偏好在伪装动物分割任务中尤其问题严重,因为它可能导致模型错误地识别出不存在的伪装动物。

图 1. co-occurrence prior 导致的 hallucination
但是这样的现象就一定是坏事吗?其实并不尽然。考虑到猎豹确实常出没于此类草原,尽管在特定图片中它们可能并未出现。这种所谓的 “幻觉”,其实是模型根据大规模数据训练得出的经验性常识。虽然这种推断与当前的例子不符,但它确实反映了现实世界中的常态。更进一步地说,这种由幻觉带来的常识可能有助于更深入地分析图片内容,发现与图片相关但不显而易见的信息。如果这些信息得到验证,它们可能有助于更有效地执行下游任务。
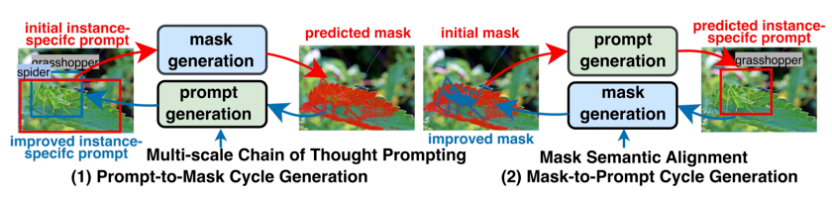
图 2. ProMaC 整体架构
实现方法
如图 2 所示,该研究提出了一个循环优化的 ProMaC 框架,它包括两部分:利用幻觉来从任务通用提示中推理出样本特有提示的 multi-scale chain of thought prompting 模块和将生成的掩码与任务语义相对齐的 mask semantic alignment 模块。前者推断出较为准确的样本特有提示来引导 SAM 进行分割,后者则将生成的掩码与任务语义进行对齐,对齐后的掩码又可以作为提示反向作用于第一个模块来验证利用幻觉得到的信息。通过循环优化来逐渐获得准确的掩码。
具体地,ProMaC 框架如图 3 所示:
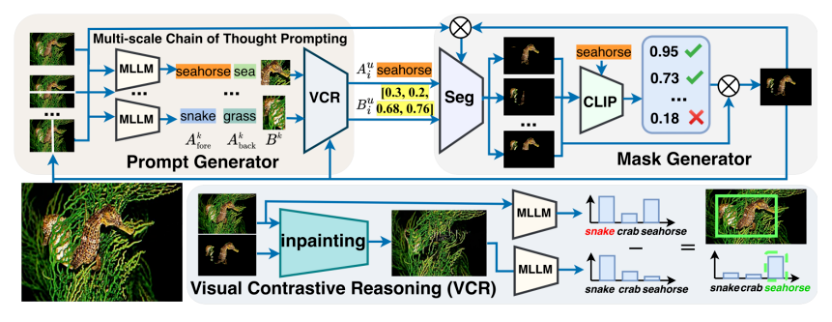
图 3. ProMaC 流程图
多尺度思维链提示
它主要完成两个任务:收集尽可能多的任务相关候选知识,并生成准确的样本特有提示。为此,该研究将输入图像切割成不同尺度的图像块,每个图像块中任务相关对象的不同可见性水平激发了 MLLM 的幻觉。这促使模型在各个图像块中通过先验知识探索图像数据与相关任务之间的联系,进而预测潜在的边界框和目标物体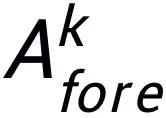 和背景
和背景 名称:
名称:
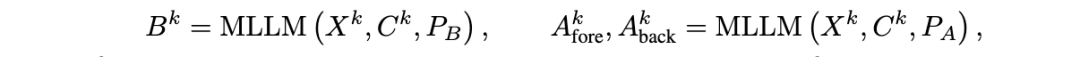
但其中只有正确的信息才值得保留。为此,该研究引入了视觉对比推理(Visual Contrastive Reasoning)模块。该模块首先使用图像编辑技术创建对比图像,这些对比图像通过去除上一次迭代中识别到的掩码部分,生成只包含与任务无关背景的图片。接着,通过将原图的输出预测值与背景图片的输出预测值相减,可以消除由物体共存偏差带来的负面影响,从而确认真正有效的样本特有提示。具体表达式如下:
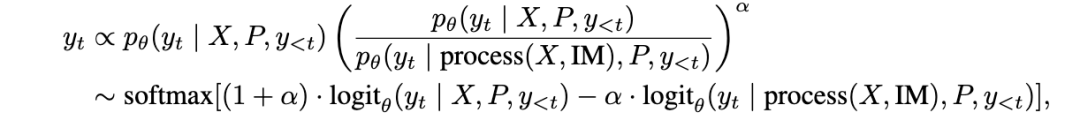
掩码语义对齐
获得的样本特有提示将被送入掩码生成器来产生准确的掩码。首先,样本特有提示被输入到分割模块(SAM)以生成一个掩码。然而,SAM 缺乏语义理解能力,它主要依据给定的提示及其周围的纹理来识别可能要分割的物体。因此,该研究采用了 CLIP 来评估相同提示在不同图像块上生成的各个掩码与目标物体之间的语义相似性。这种方法有助于确保分割结果的准确性和相关性:
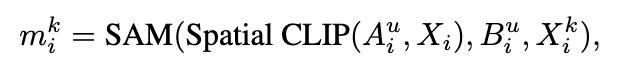
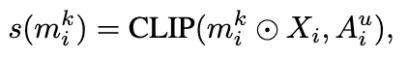
归一化后的相似度用作权重,以加权合成最终的掩码。这个掩码在下一次迭代中有助于生成更优质的背景图片,进而引导更有效的提示生成。这能充分利用幻觉来提取图片中与任务相关的信息,验证后生成更准确的提示。这样,更好的提示又能改善掩码的质量,形成一个互相促进的提升过程。
该研究在具有挑战性的任务 (e.g., 伪装动物检测,医学图像检测) 上进行了实验:
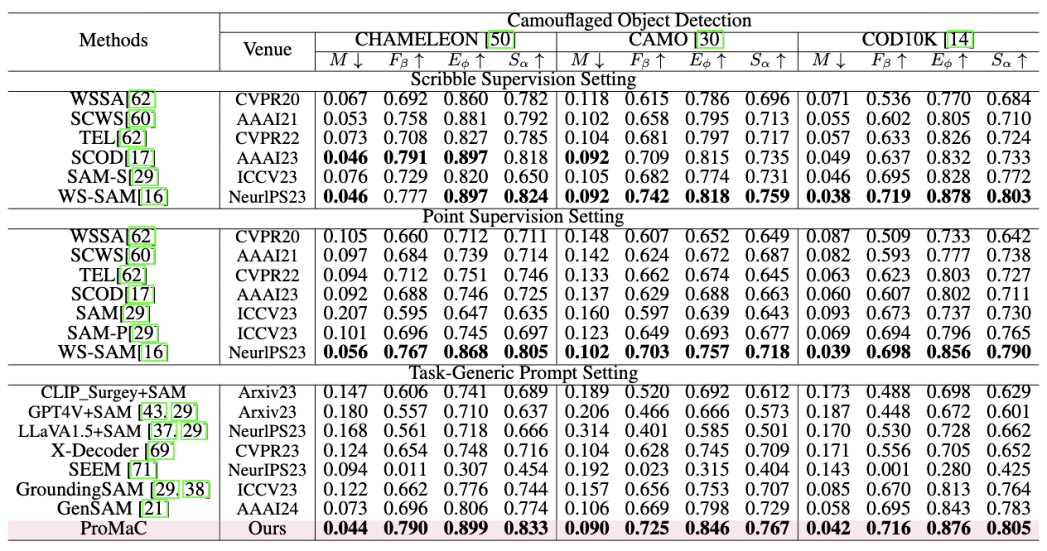
图 4. 伪装样本检测实验结果
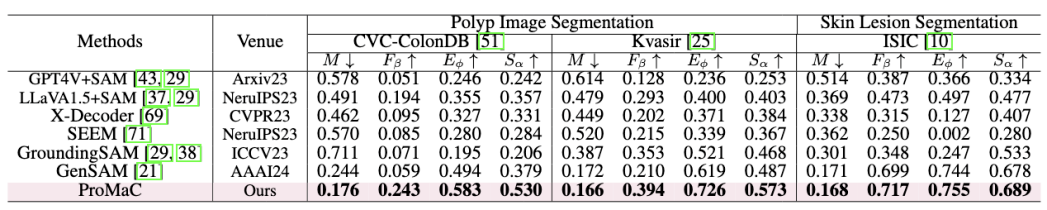
图 5. 医学图像实验结果

图 6. 可视化案例
PromaC 提供了一个新视角,即幻觉不一定就是有害的,如果能加以利用,也是能为下游任务提供帮助。
[1] Hu J, Lin J, Gong S, et al. Relax Image-Specific Prompt Requirement in SAM: A Single Generic Prompt for Segmenting Camouflaged Objects [C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38 (11): 12511-12518.
往期精彩文章推荐
NeurIPS 2024 | 大道至简!时间序列预测真的需要复杂网络架构吗?简单滤波器就已足够
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者讲解回放!


















 32
32

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









