






点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
概述
由于数值计算的局限,物理信息神经网络(PINNs)只能在离散的采样点上进行优化,限制了它们在全部定义域上的效果。本文提出并从理论上分析了一个全新的PINN优化范式:局域优化,可以有效降低PINN的泛化误差。进一步,我们提出RoPINN算法,在不增加任何梯度计算开销的情况下,一致提升了5种PINN网络在19类PDE求解任务上的效果。

作者:吴海旭,罗华坤,马越洲,王建民,龙明盛
链接:https://arxiv.org/pdf/2405.14369
代码:https://github.com/thuml/RoPINN
1. 引言
求解偏微分方程(PDE)对众多科学与工程领域十分关键。鉴于深度模型强大的非线性拟合能力,物理信息神经网络(PINNs)被提出并被应用于求解PDE。具体地,PINNs将PDE的约束(如初始条件、边界条件、方程)设置为目标函数,利用深度学习框架的自动求导功能精确近似PDE导数项,通过不断优化深度模型的输出与梯度,使其满足目标方程,从而完成求解。
虽然深度模型在理想情况下具有通用逼近能力,但是由于PINNs额外约束了深度模型梯度,在实际优化过程中面临巨大挑战。因此,PINNs的优化问题也成为该领域的基础问题。为此,之前工作的提出了损失函数加权、重要区域重采样、新优化器等众多方案。
不同于上述方法,本文从一个更加基础的视角来思考PINN:目标函数的定义。
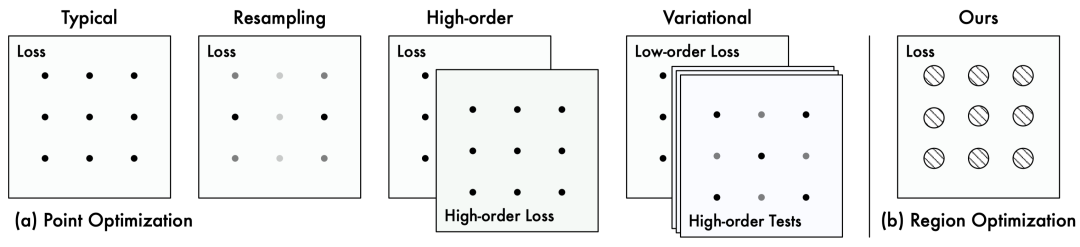
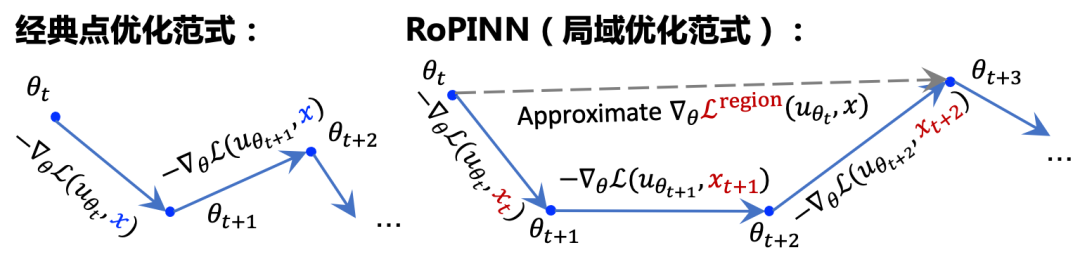
如下图所示,经典PINNs的目标函数定义在有限采样点上,本文称这种训练范式为点优化(Point Optimization),然而这样的定义显然与“在全定义域上求解PDE”的目标不匹配。
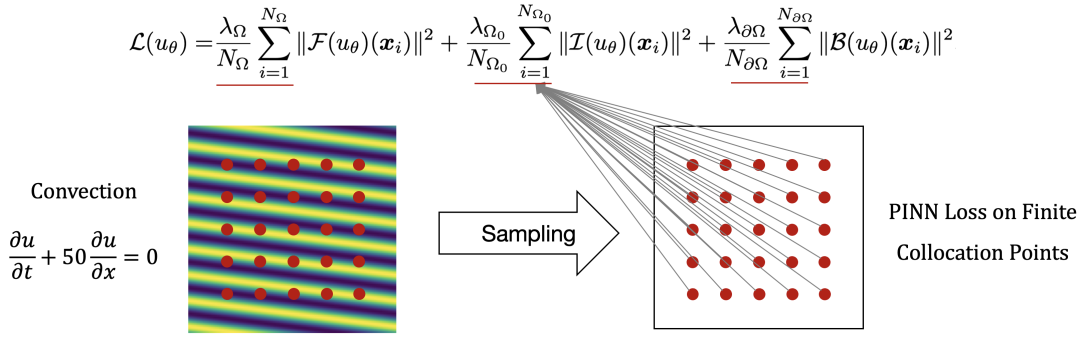
针对上述问题,本文提出并从理论上分析了一个全新的PINN优化范式:将优化过程从采样得到的散点扩展到它们周围的近邻区域,即局域优化(Region Optimization)。进一步,我们基于这个全新理论框架设计了一个实用的优化算法RoPINN。相比于点优化,RoPINN具有以下优势:
更优泛化误差:局域优化范式可以有效降低PINNs在全定义域上的泛化误差,同时也为理论分析提供了一个更加通用的框架,首次直观地揭示了PINNs训练过程中泛化与优化的平衡关系。
高效优化算法:相比标准的点优化,RoPINN算法不会带来额外的梯度计算开销,非常高效地实现了我们提出的局域优化范式。
一致效果提升:RoPINN一致地提升了5种不同的PINN模型(包括PINN、QRes、FLS、KAN和PINNsFormer)在19种PDE上的效果。
2. 局域优化
PDE包含方程、初始条件、边界条件三项,可以被形式化为:
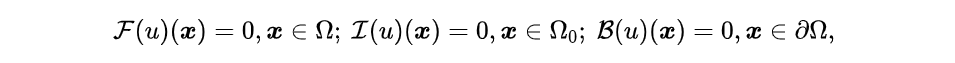
其中,分别表示PDE的方程约束、初始条件和边界条件。
(1)点优化(Point Optimization):对于参数为的深度模型,经典的点优化目标函数定义为:
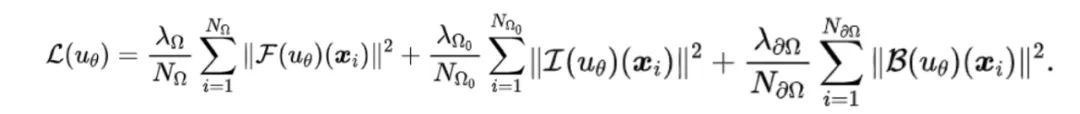
(2)局域优化(Region Optimization):如上所述,为了解决点优化无法充分地“在全定义域上求解PDE”的问题,我们提出将优化过程从采样得到的散点扩展到它们周围的近邻区域。因此,本文将局域优化范式定义为:
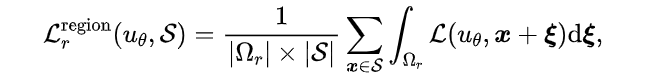
其中,表示扩展之后得到的局域空间,是表示局域大小的超参数。
尽管表面上看,局域优化的定义需要采样更多的点来实现积分,我们在下一节提出的RoPINN算法可以高效地实现这一新范式,并且没有增加采样点数量以及梯度计算开销。特别地,“局域”的引入,也给PINNs的理论分析带来了一个更加通用便捷的框架。本节将继续讨论两种优化范式之间的理论性质。
2.1 泛化误差界
为了避免采样点选取造成的影响,本文关注泛化误差期望(generalization error in expectation),定义如下:
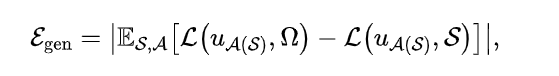
其中,表示从全定义域中采样得到的优化点,表示训练算法,表示训练得到的模型参数。
为了方便分析,我们假设损失函数对于模型参数是,。
(1)点优化下的泛化误差期望:在上述假设下,若使用经典的点优化损失函数优化步(第步的步长为),可以证明
如果对于模型参数是凸函数,并且,则。
如果对于模型参数是非凸函数,但是有上界,同时优化步长单调不增,则
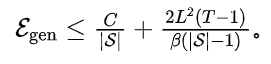
(2)局域优化下的泛化误差期望:在与点优化相同的假设下,如果使用局域优化损失函数优化步(第步的步长为),可以证明
如果对于模型参数是凸函数,并且,则
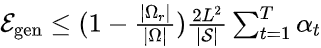 。
。如果对于模型参数是非凸函数,但是有上界,同时优化步长单调不增,则,其中是与训练初期性质有关的常数
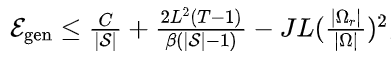 。
。
通过上述理论分析,我们可以直观的得到,引入局域可以以线性速度降低泛化误差。
此外,局域优化也提供了一个更加通用的理论框架,经典的点优化对应的特例。对于另外一个全局采样的极端情况(即),这一情况等价于直接在全定义域上优化损失函数。因此,泛化误差会降低为0。但是实际上,这一理想情况并不会被满足,因为当很大时需要很多的采样点,才可以精确近似,即存在很大的优化误差。关于实际算法的理论分析,会在3.3节进一步展开。
2.2 高阶方程约束
在我们提出的局域优化范式中,局域积分项会在“放松”对于损失函数光滑性的要求。具体对比如下:
(1)高一阶约束的局域优化:在与上述分析相同的光滑性假设下,可以证明,使用高一阶的局域损失函数依然可以满足与2.1节相同的泛化误差期望。
(2)高一阶约束的点优化:当我们使用高一阶的点优化损失函数则无法实现与上一节相同的泛化误差。例如,如果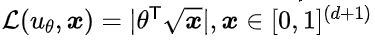 ,对于满足1-Lipschitz-1-smooth。然而,当时,是无界的,也就意味着并没有保持原有的光滑性假设。
,对于满足1-Lipschitz-1-smooth。然而,当时,是无界的,也就意味着并没有保持原有的光滑性假设。
上述对比意味着,当PDE方程中存在高阶项时,使用局域优化方式更容易帮助PINN训练。
3. RoPINN
在上述理论的基础上,我们进一步提出了RoPINN作为一个实用的PINN训练算法。它非常高效地实现了我们在第2节中提出的局域优化范式。

如上图所示,RoPINN包含两个交替的步骤:蒙特卡洛近似(Monte Carlo Approximation)和置信域校准(Trust Region Calibration),前者使用采样高效地近似局域积分,后者自适应地调节局域大小来控制近似误差。下面会介绍具体实现以及对应的理论分析。
3.1 蒙特卡洛近似
在局域优化的定义中,损失函数为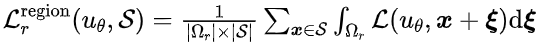 ,其中对于局域的积分项无法直接计算,因此,在RoPINN中,我们提出使用简单有效的蒙特卡洛近似方法。具体来说,为了近似目标函数的梯度,在每步迭代中,我们会在局域中均匀采样一个点计算梯度。
,其中对于局域的积分项无法直接计算,因此,在RoPINN中,我们提出使用简单有效的蒙特卡洛近似方法。具体来说,为了近似目标函数的梯度,在每步迭代中,我们会在局域中均匀采样一个点计算梯度。
这一设计可以带来以下性质。
(1)期望近似:上述设计在期望意义下实现了局域优化,具体为:
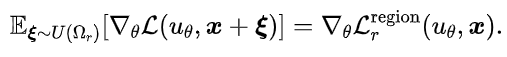
(2)高阶优化:除了没有增加采样点外,上述采样策略也等价于一个高阶损失函数,可以加强对于PDE一阶约束的优化。具体地,通过泰勒展开,我们可以得到
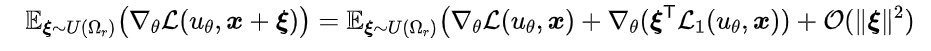
其中 表示高一阶损失函数。
(3)收敛速度:可以证明,当使用蒙特卡洛近似时,局域优化损失函数的收敛速度为:
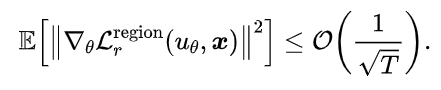
3.2 置信域校准
虽然在期望意义下,上述采样策略等价于局域优化,但是在每一步中,只采样一个点也会带来梯度估计误差,过大的误差会造成训练的不稳定。具体地,梯度估计误差的期望为:
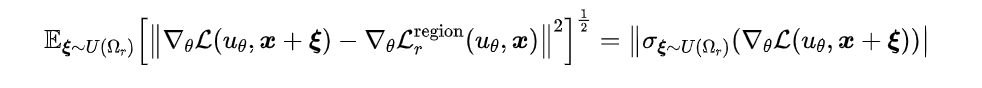
为了保证训练稳定性,我们提出控制局域大小,从而得到更加可靠的梯度下降。根据上式,我们得到梯度估计误差的期望为局域内的梯度方差。为此,我们称局域内损失函数梯度方差小的区域为“置信域(Trust Region)”。通常情况下,方差与局域大小呈现反比(因为距离更远的采样点,PDE性质更有可能不相似)。因此,我们如下调整局域大小:
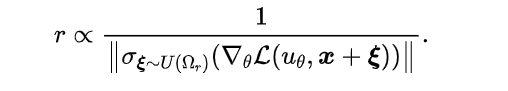
上述设计中,需要计算局域内的损失函数梯度方差,这一过程也需要多个采样点才可以实现。为了追求高效的优化策略,我们提出使用“多个相邻优化步之间的梯度方差”近似“局域梯度方差”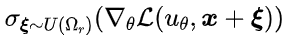 ,这一近似过程也有良好的理论保证(具体请见论文)。类似的思想(基于优化过程中统计量来调整优化过程)也被广泛应用于Adam、AdaGrad等优化器的设计中。
,这一近似过程也有良好的理论保证(具体请见论文)。类似的思想(基于优化过程中统计量来调整优化过程)也被广泛应用于Adam、AdaGrad等优化器的设计中。
特别地,上述计算并不需要额外的采样点或者梯度计算,只需要维护一个迭代过程中的定长梯度队列即可。因此,相比于经典的点优化,RoPINN依然保持了原有的计算效率。
3.3 PINN中优化与泛化的平衡
在第2节中,我们证明了理想状态下局域优化的泛化误差界为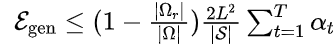 。但是在3.2节中,我们也提到过大的局域尺寸,会给蒙特卡洛近似带来很大的梯度估计误差。上述分析其实隐式揭示了PINN训练过程中的优化与泛化之间的平衡关系。这一关系可以被如下定理直观地表达:
。但是在3.2节中,我们也提到过大的局域尺寸,会给蒙特卡洛近似带来很大的梯度估计误差。上述分析其实隐式揭示了PINN训练过程中的优化与泛化之间的平衡关系。这一关系可以被如下定理直观地表达:
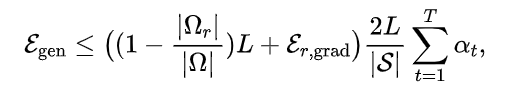
其中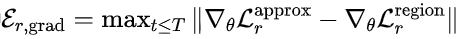 ,表示训练过程中,RoPINN中使用蒙特卡洛近似的局域优化与精确局域优化之间的误差上界。更加严格的表述及证明请见论文。
,表示训练过程中,RoPINN中使用蒙特卡洛近似的局域优化与精确局域优化之间的误差上界。更加严格的表述及证明请见论文。
类似2.1节,基于上述定理,我们观察到:
当应用经典点优化范式时,且,虽然没有梯度估计误差,但是并没有给泛化误差带来优化。
当每步都在全局采样点时(对应各种采样算法),,但是会带来很大的梯度估计误差,因此也难以实现最优的泛化性质。
相比于上述两个极端情况,我们提出的RoPINN算法可以自适应地调节局域大小,从而可以更好地平衡PINN在训练过程中的优化与泛化性。
4. 实验
为了充分验证RoPINN的有效性,我们在5种不同PINN模型、19种不同PDE上进行了验证。
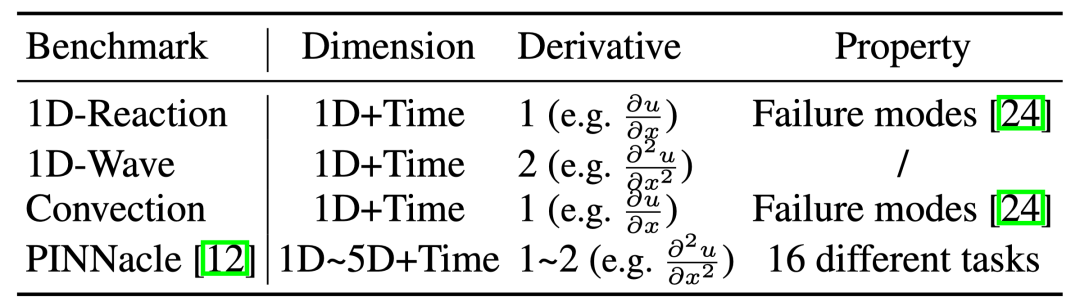
4.1 主要结果
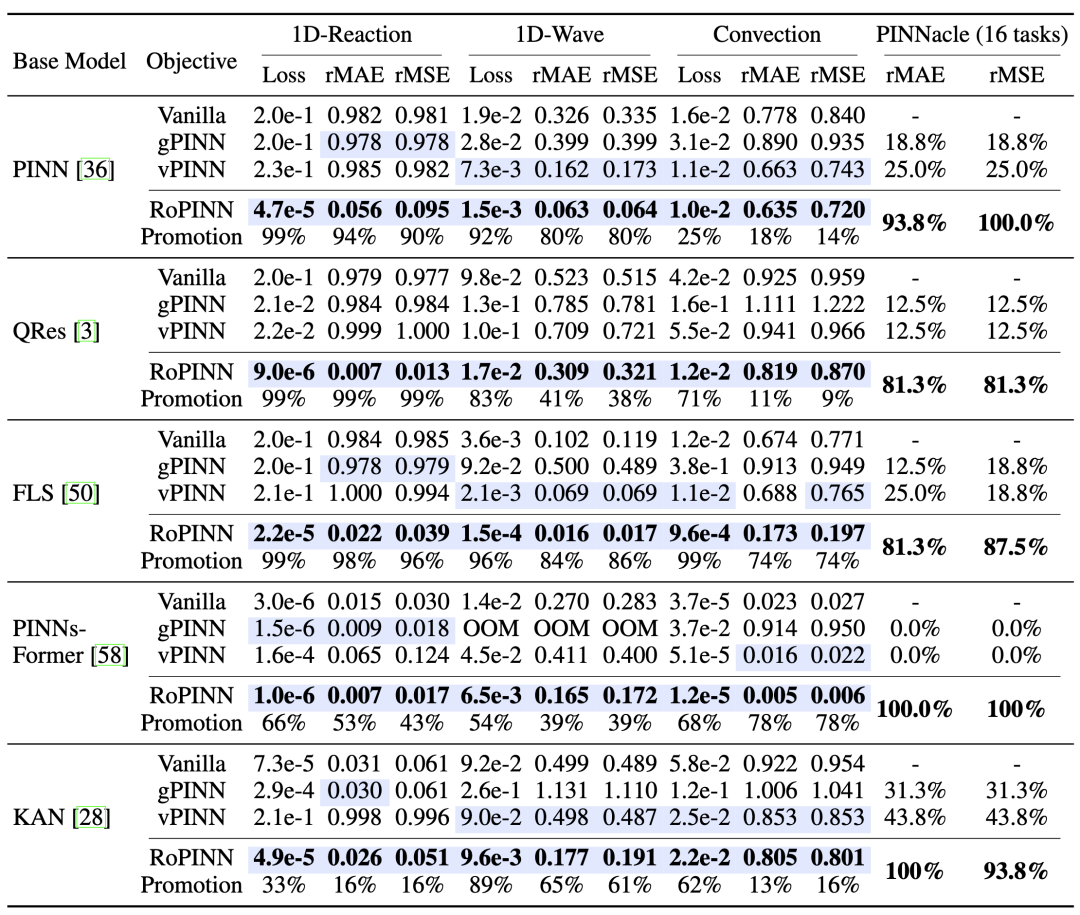
如上图所示,相比于高阶正则项方法gPINN和变分方法vPINN,RoPINN可以一致性地提升PINN模型在PDE求解上的效果。特别地,RoPINN也同样适用于KAN以及PINNsFormer这两类新的PINN主干网络,验证了算法的通用性。
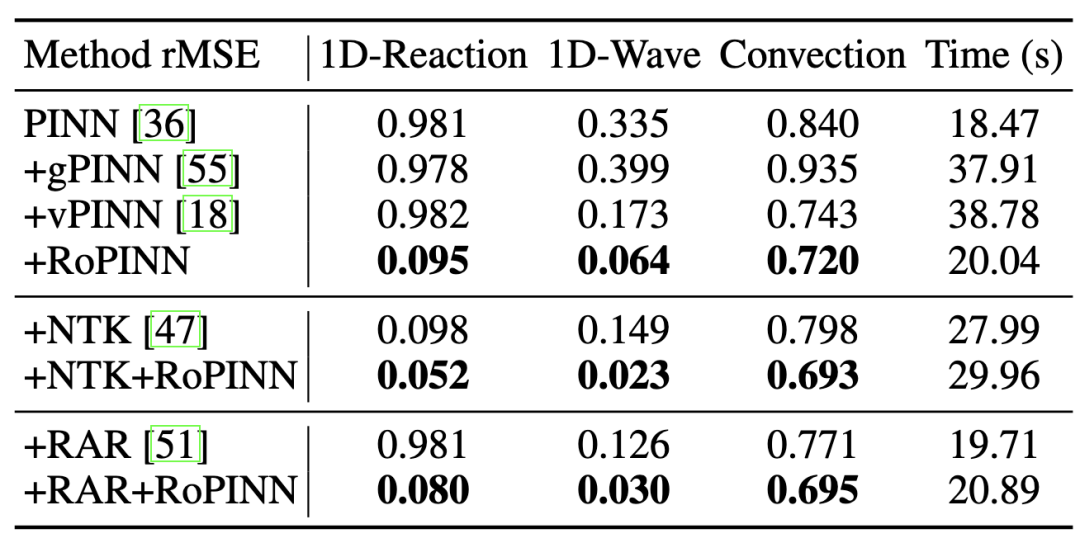
因为RoPINN关注损失函数的定义,与前人提出的采样方法、损失函数加权方法贡献正交。如上图所示,RoPINN也可以与上述方法结合使用,以得到进一步效果提升,同时也保持了算法的计算效率。
4.2 消融实验
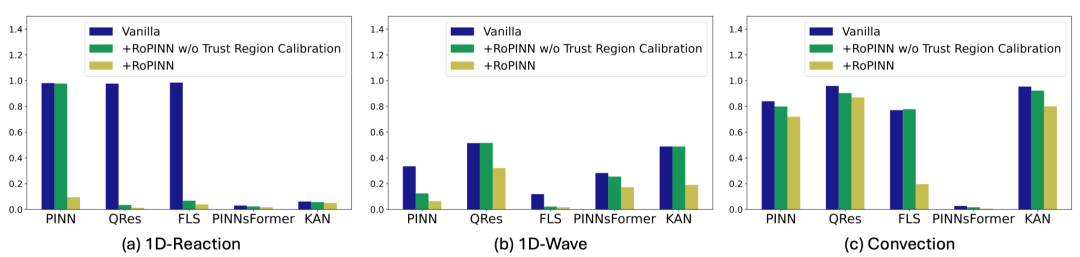
如上图所示,单纯基于蒙特卡洛采样的局域优化在大部分情况下也可以提升模型效果,但是在一些PDE上仍然存在不稳定情况。通过应用RoPINN中提出的置信域校准的策略,可以一致地得到大幅度提升。这也印证了3.3节所展示的平衡优化与泛化的重要性。
4.3 优化过程分析
4.3.1 初始局域尺寸影响
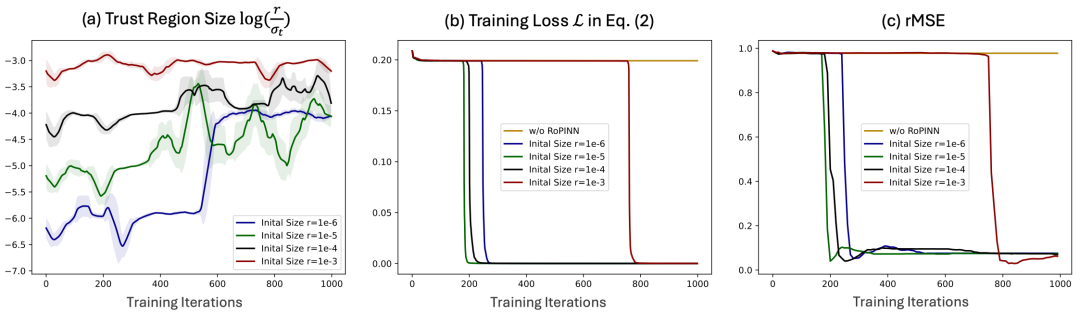
如上图(a)所示,我们发现,即使在训练初始阶段设置的局域尺寸不一样,RoPINN也会逐步将调整至接近大小,直观展现了RoPINN对于泛化与优化的平衡过程。特别地,图(b-c)表示,如果一开始将设置为接近平衡点的值,则会带来更快的收敛速度。
4.3.2 局域采样点数量影响
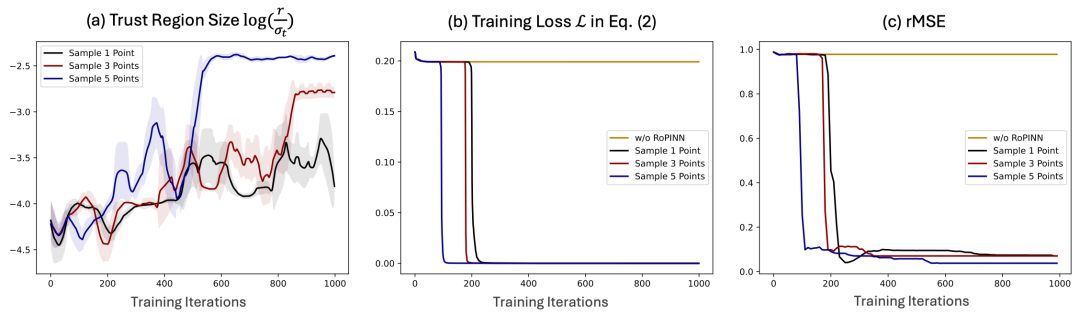
为了追求算法效率,RoPINN默认只在局域内采样一个点。但是如上图所示,更多的采样点会带来更加准确的梯度估计,从而使得最终平衡得到的局域尺寸更大,也会带来更快的收敛速度和更好的效果。
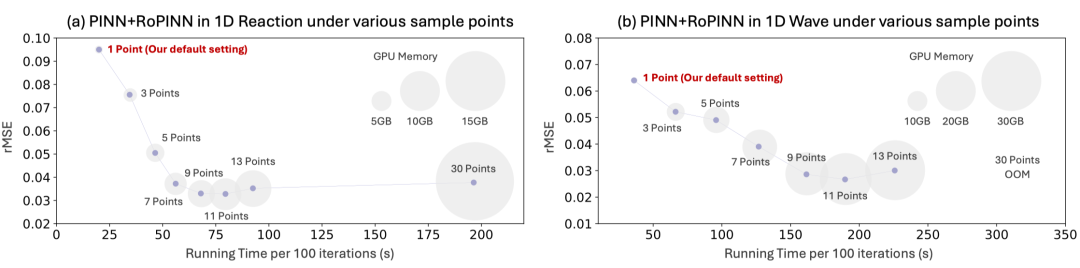
事实上,如果我们持续增大局域采样点,计算开销会线性增加,并且在10个点左右达到饱和。
4.4 模型可视化
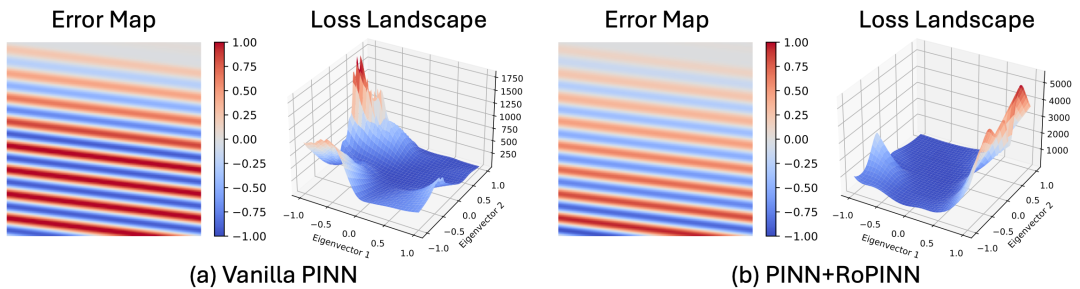
在主实验结果中,我们注意到,RoPINN可以在一定程度上提升模型对于“PINN失败案例”的求解效果。为分析这一结果的原因,我们在上图可视化了在Convention方程上训练得到模型的损失景观(Loss Landscape),发现RoPINN可以得到比经典点优化更加光滑的优化曲面。
5. 总结
在本文中,为解决PINN领域长期存在的优化问题,我们提出并理论分析了一个全新的PINN优化范式:局域优化,可以有效降低PINN的泛化误差。在这一理论的基础上,我们进一步提出了一个实用的优化算法RoPINN,在不增加额外梯度计算开销的情况下,一致地提升了多种PINN模型的PDE求解效果。
特别地,“局域”的引入也为研究者们理解PINN的工作原理提供了一个简洁通用的理论框架,首次揭示了PINN在训练过程中的优化与泛化的平衡关系,希望可以为后续算法的设计提供新思路。
内容来源于清华大学软件学院机器学习组官方公众号(THUML-LAB)
往期精彩文章推荐

KDD 2025预讲会:10位一作的论文分享与话题思辨|12月18日全天直播
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 了解更多论文信息!


















 20
20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









