







背景
数据仓库擅长对结构化数据进行管理、分析。针对半结构化数据,不少数据仓库产品虽然支持了struct、map、array类型来加强对半结构化数据类型的支持,但是这些类型都需要预定义schema,在数据导入、schema变更时有比较大的使用成本。
而Json类型由于其灵活多变,不需要预定义schema,为数据采集、数据分析、schema变更提供了极大的灵活性。在业务变动频繁的互联网,尤其是游戏行业,Json类型被广泛采用。其灵活性可以快速满足业务上对字段的增删要求。此外,Json作为跨语言的协议,也比较好地被各种大数据平台、中间件所支持。
今天,我们邀请质变科技AI-ready数据云团队布道师文军与大家分享话题《如何做好半结构化数据分析》。
挑战
Json类型应用起来比较灵活是因为Json逐行保存了schema信息。以github events数据集(https://www.gharchive.org)为例,每行数据都会重复存储key字段(id、type、actor、payload等)。Json的这种特性对数据仓库来说会带来如下三方面的挑战:
1)Json类型的每行数据都会反复存储key字段信息,导致较大的存储空间
2)通过数据仓库分析Json类型的数据时,需要逐行解析Json结构,占用大量的CPU
3)Json类型作为一个数据仓库表的一个列,作为IO的最小逻辑单元,无法在分析时按需加载Json子字段来减少IO,同时Json子字段不具备索引、裁剪的能力。
github events数据数据样例:
{"id":"2489651045","type":"CreateEvent","actor":{"id":665991,"login":"petroav","gravatar_id":"","url":"https://api.github.com/users/petroav","avatar_url":"https://avatars.githubusercontent.com/u/665991?"},"repo":{"id":28688495,"name":"petroav/6.828","url":"https://api.github.com/repos/petroav/6.828"},"payload":{"ref":"master","ref_type":"branch","master_branch":"master","description":"Solution to homework and assignments from MIT's 6.828 (Operating Systems Engineering). Done in my spare time.","pusher_type":"user"},"public":true,"created_at":"2015-01-01T15:00:00Z"}
面对此类问题,simdjson(https://github.com/simdjson/simdjson)被广泛应用在Json解析加速。相比于naive的实现,simdjson往往能带来10~20x的解析提升。但是,从端到端的视角来看,Json分析查询的耗时主要由Scan + Projection算子组成。simdjson一定程度上解决了projection算子的性能问题,当Json内容较大时,巨大的IO开销让查询的延迟变得不可接受。
Relyt JsonB类型
为了提升Json类型的分析性能、存储密度,Relyt AI-ready Data Cloud新增了对JsonB类型的支持。相比较于Json类型,Relyt在写入JsonB类型时,会对Json字符串进行解析,自动识别schema,并对数据进行结构化存储。从而,用户对Json子字段进行分析时,可以达到scalar类型接近的性能。用户在写入、分析JsonB类型的数据时,完全兼容Json类型的行为。
使用介绍
-- 创建包含JsonB字段的表
CREATE TABLE json_test (f0 json)
WITH(json_expand=on);
-- 写入Json数据
INSERT INTO json_test
VALUES
('{"key1": "value1", "key2": 1234, "key3": true} ');
-- 查询Json的子字段
-- ->>操作符
select f0->>'key1' from json_test;
-- json_extract_text函数
select json_extract_text(f0, '$.[key1]') from json_test;
实现原理
JsonB结构化存储
Relyt在处理Json类型的数据时,会对实际写入的Json数据内容进行统计,统计Json中Json key的出现频率、Json value的类型。在数据持久化到磁盘之前,Relyt会根据统计信息动态决策,哪些Json key需要结构化存储以及Json value的存储类型。Json key以列存文件的schema信息,不会在文件的数据区存储。Json value按照如下的类型转换关系映射成Relyt的类型:
| Json value类型 | Relyt类型 |
| Json array | Array |
| Json object | Struct(not support yet) |
| Json number(整型) | Bigint |
| Json number(浮点类型) | Json |
| Json string | Varchar |
| Json boolean | Boolean |
对于多行Json数据,相同Json key所对应的Json value类型不一致的情况。Json value的类型统一归类为Json类型。对于动态决策后不需要结构化存储的所有Json key,Relyt会将其合并成一个字飞来段,Json value的类型归类为Json类型。
样例一:
写入的Json数据
{"key1": "value1", "key2": 1234, "key3": true}
{"key1": "value2", "key2": 4321, "key3": "true"}由于第一行Json数据的key3的Json value为Json boolean类型,第二行Json数据的key3的Json value为Json string类型。因而,结构化存储时,key3的类型映射为Json类型。
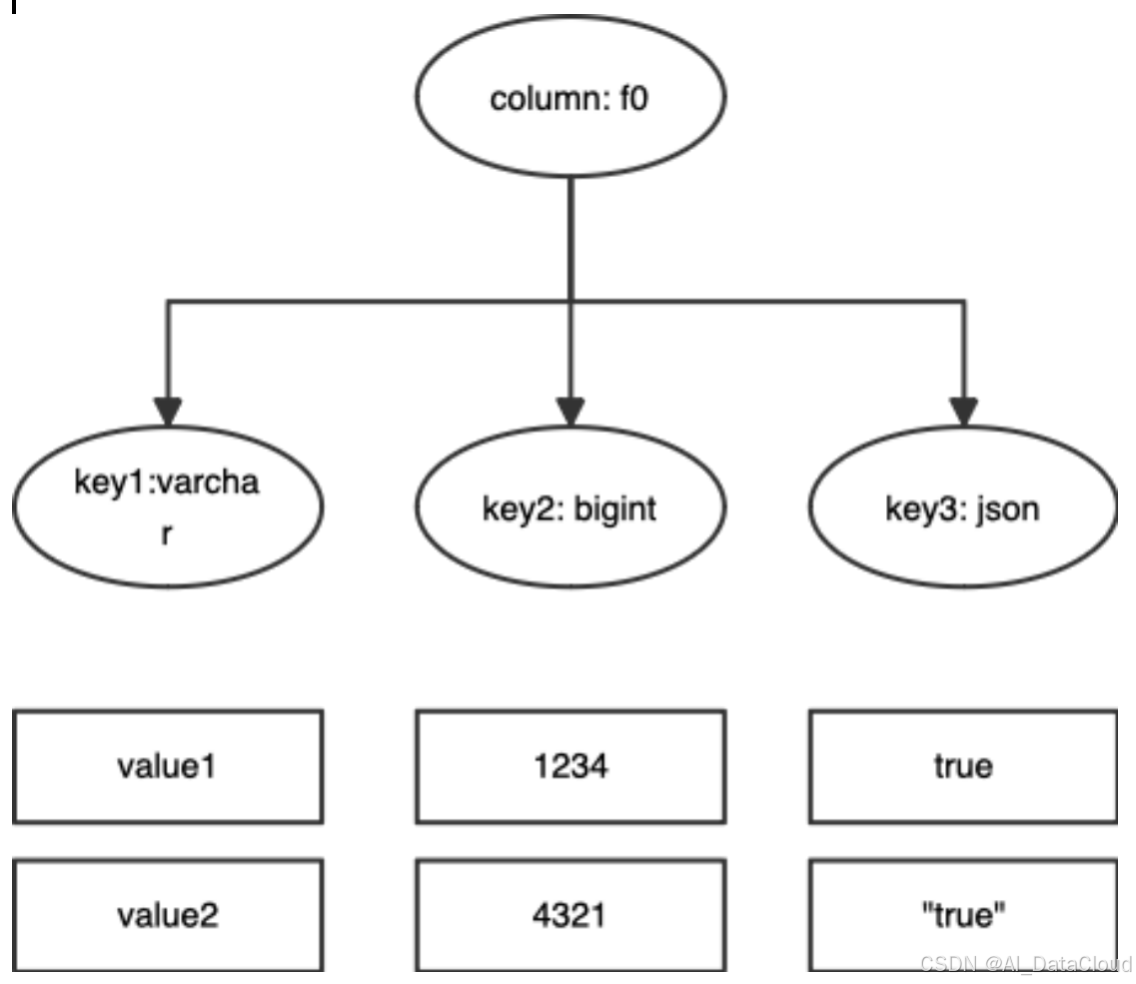
图一
样例二:
写入的Json数据
{"key1": "value1", "key2": 1234, "key3": true}
{"key1": "value2", "key2": 4321}
{"key1": "value3", "key2": 1000}由于Json key "key3"的存在率未超过50%,因而key3并不进行结构化存储。
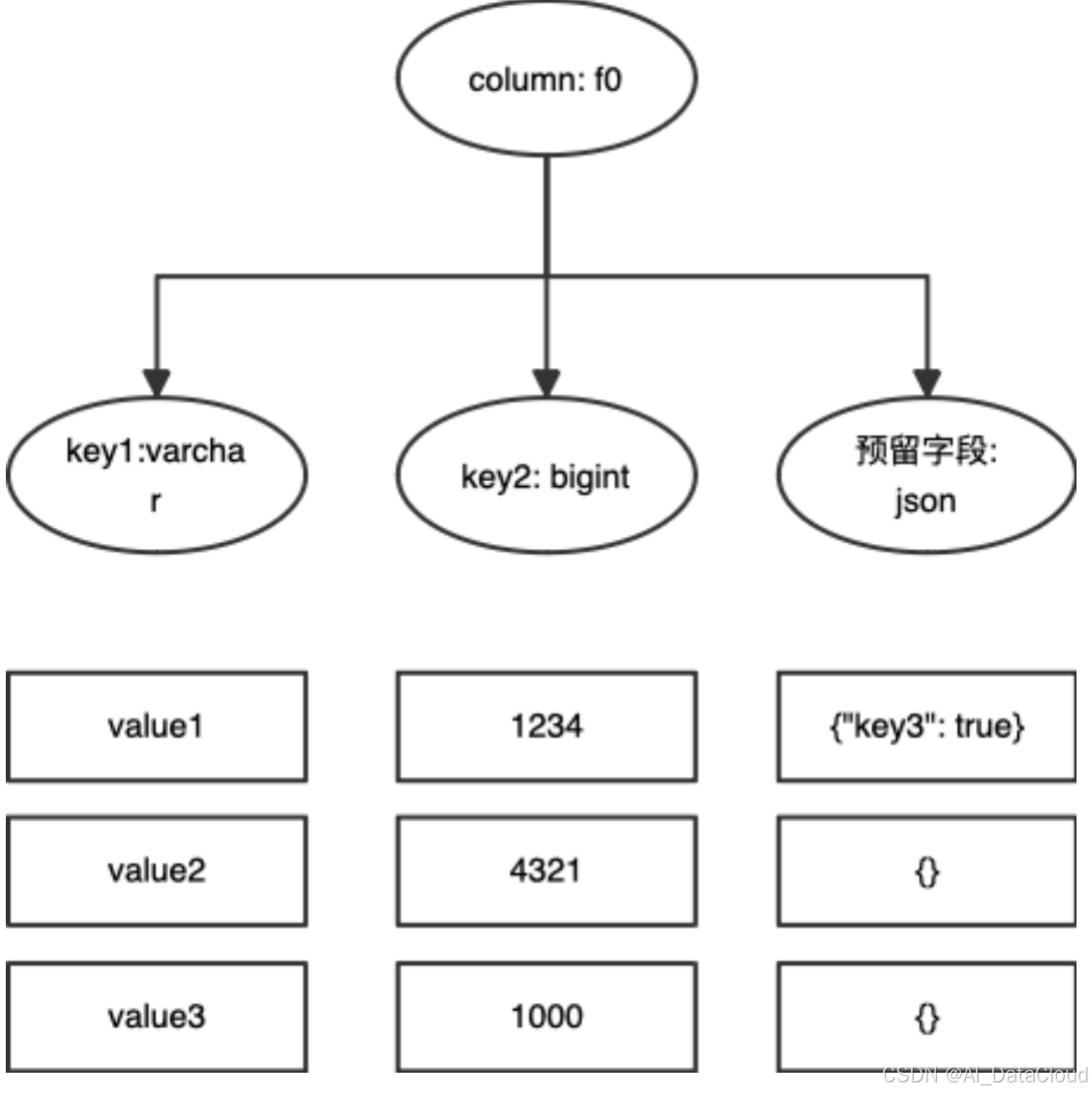
图二
JsonB查询优化
由于JsonB类型已经被结构化存储,Relyt在查询JsonB的数据时,可以只加载查询涉及的Json key数据。与此同时,也可以在Relyt存储类型与json_extract函数的返回类型一致的情况下,也可以进一步节省掉projection算子部分的计算消耗。下面分别从IO裁剪、projection视角来介绍Relyt在查询阶段的优化。
IO裁剪
select f0->>'key1' from json_test where f0->>'key1' = 'value2';以上述SQL为例,Relyt在生成执行计划的时候,会识别->>操作符的有操作数。由于column f0已经被结构化存储了。因而,在生成执行计划的时候,仅仅Scan算子仅仅需要扫描,'key1'子字段。而'key1'、'key2'、'key3'这些子字段,Relyt是用列存来存储的,因而扫描的时候,可以做到只扫描'key1'子字段,从而做到纵向维度的IO裁剪。
此外,'key1'对于列存文件来说与普通的列没有区别。该列上的统计信息、索引等能力,Relyt在查询的时候,依然可以使用,从而达到横向维度的IO裁剪。
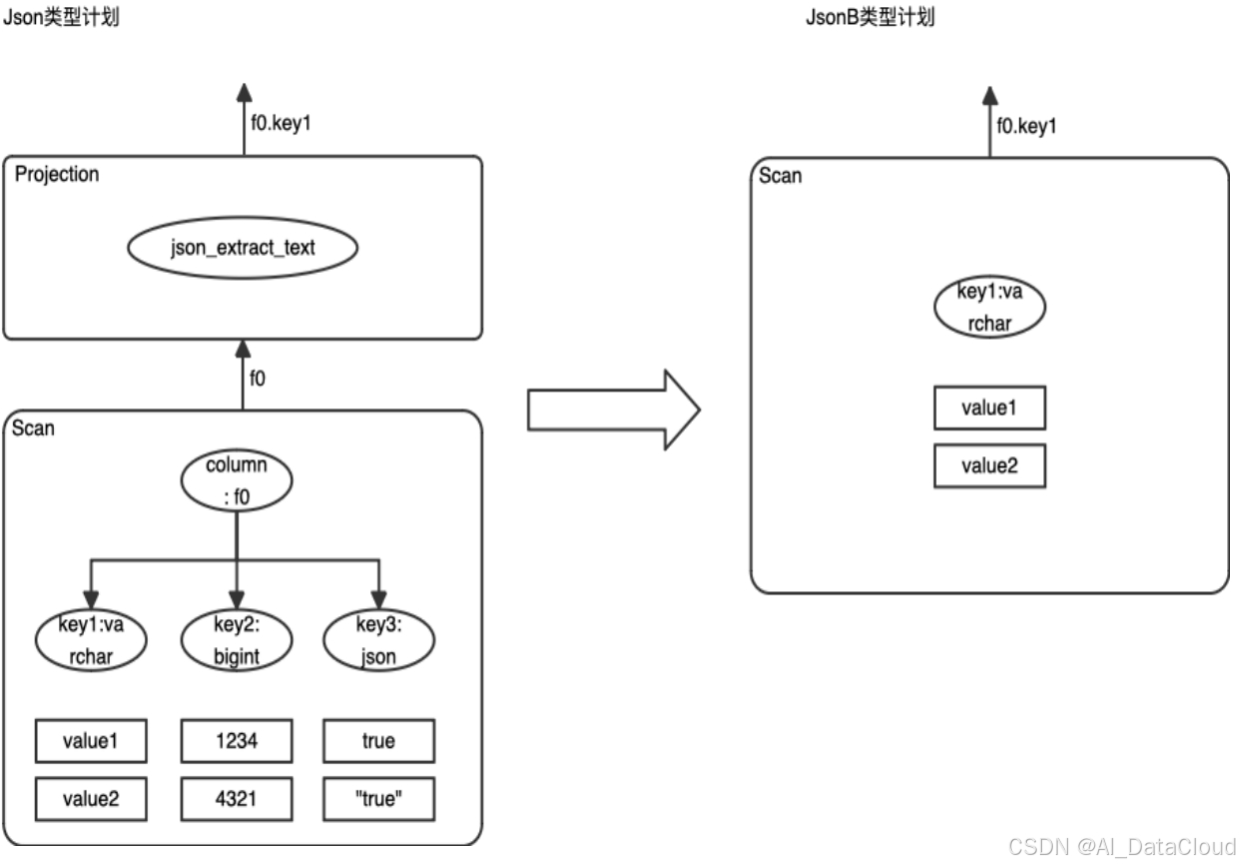 图三
图三
Projection pushdown
如图三所示,针对JsonB的查询,Projection算子的json_extract_text函数优化掉了。因为'key1'的存储类型为Varchar,而json_extract_text的返回类型也是Varchar。不需要再进行额外的Projection计算。而如果'key1'存储的类型为bigint,与json_extract_text的返回类型Varchar不一致的情况下,还是需要额外的cast操作来对类型进行转换。这部分cast操作,我们需要pushdown到Scan算子中进行,因为不同的列存文件之间的JsonB字段的schema可能是不一致的。所以,我们需要文件粒度去决策是否要进行cast操作的计算。
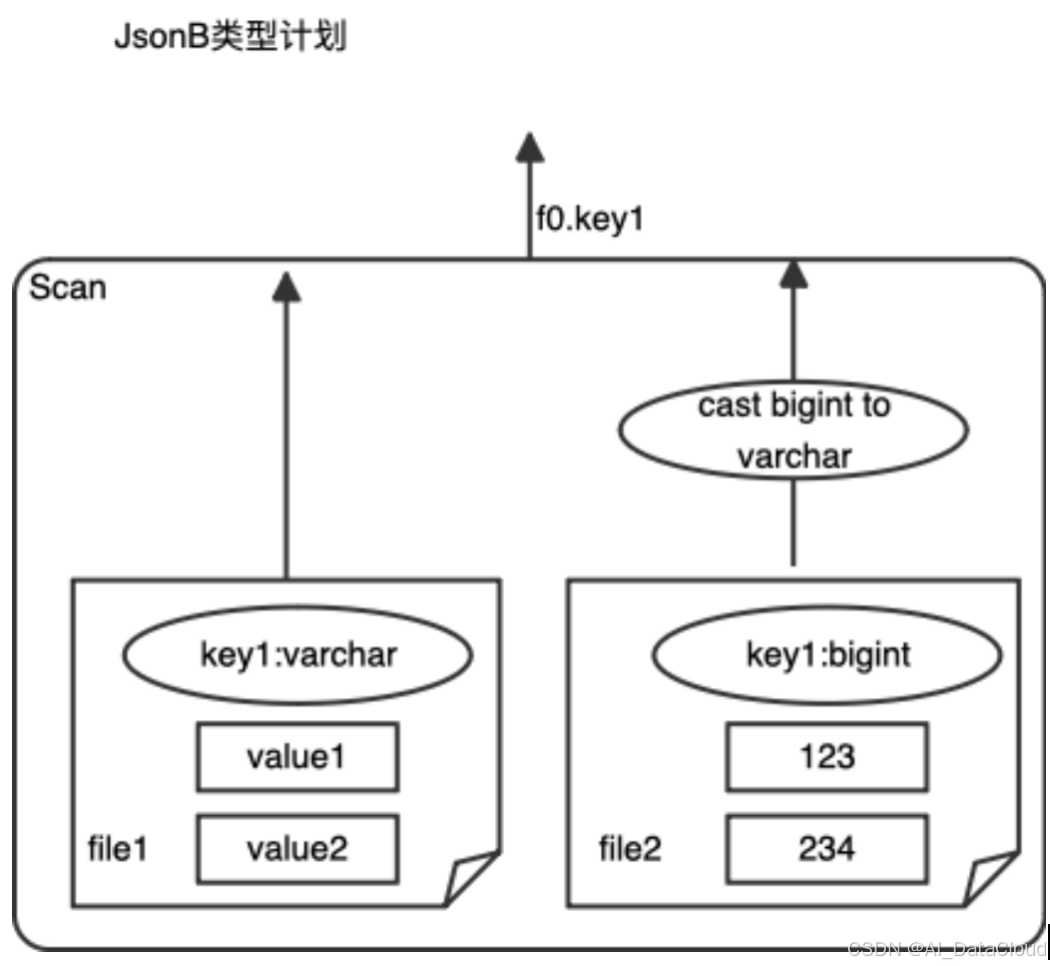
图四
查询效果评估
JsonB类型在Relyt的核心客户上得到了很好的应用,下面的性能数据来自于该客户业务场景下的应用情况。在相同业务数据情况下,分别采用大宽表、JsonB、Json的方案的性能结果。
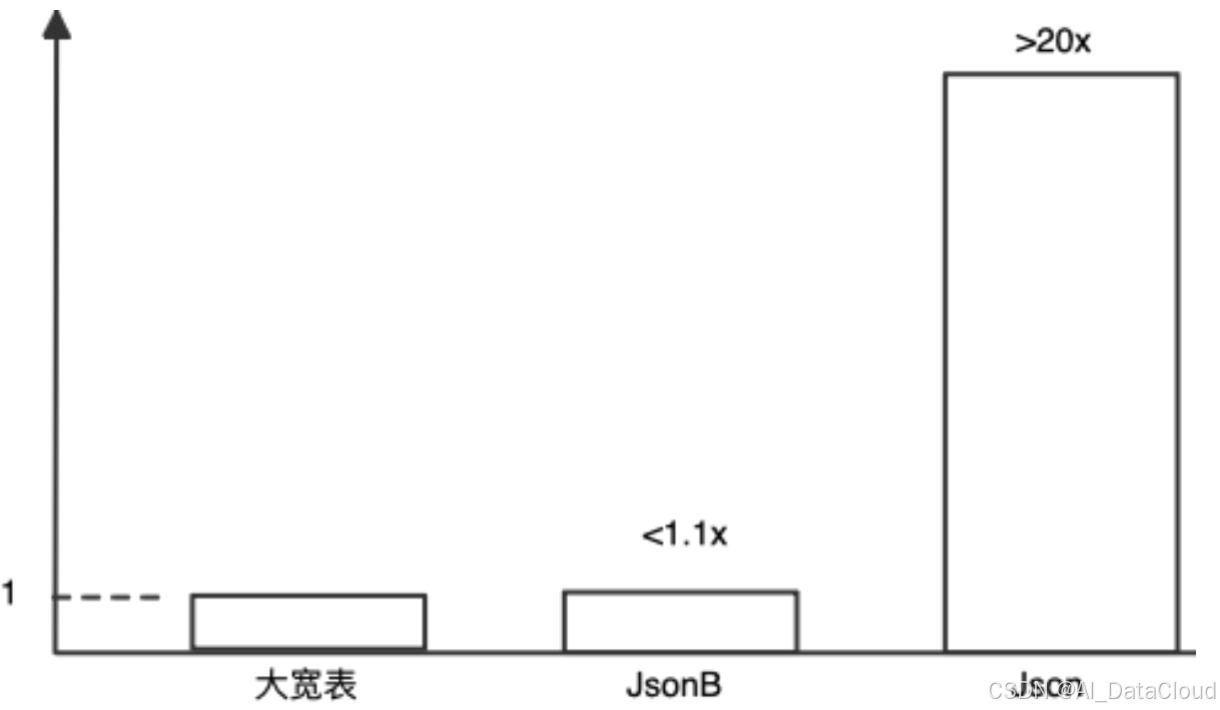
图五
业界相关工作
Doris、Clickhouse都支持了variant类型来解决json数据格式的动态类型的问题,在内存中结构化表示json数据,避免了对json子字段访问的开销。磁盘上都通过高密度的列存来结构化存储json数据。
而spark社区目前也支持了variant类型,同时也通过variant shredding功能来做到列存的方式结构化存储json的子字段从而进一步提升IO裁剪能力。
未来工作
Relyt AI-ready Data Cloud当前仅支持Json第一级子字段的结构化存储,由于多级嵌套子字段在业务中还是比较场景的,这部分的支持我们还在进行中。
随着Spark和数据湖生态对Variant类型支持的完善,Relyt也会在目前湖仓一体的架构下做好对数据湖生态的Variant类型的支持,进一步强化数据湖的非结构化数据处理能力。
相关引用
https://www.alibabacloud.com/help/zh/hologres/user-guide/json-and-jsonb-data-types?spm=a2c63.p38356.0.0.5fd6cf7409IzlM
https://doris.incubator.apache.org/zh-CN/docs/dev/sql-manual/sql-data-types/semi-structured/VARIANT
https://docs.databricks.com/en/semi-structured/variant-json-diff.html
https://www.databricks.com/blog/introducing-open-variant-data-type-delta-lake-and-apache-spark
https://github.com/delta-io/delta/blob/master/protocol_rfcs/variant-type.md
https://github.com/simdjson/simdjson
https://www.gharchive.org
https://mp.weixin.qq.com/s/KVNcd25gngbBESU1QCYxbg
https://github.com/apache/spark/blob/master/common/variant/shredding.md
https://github.com/delta-io/delta/blob/master/protocol_rfcs/variant-type.md#variant-data-in-parquet



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









