







文|王勤龙 (花名:长凡)
蚂蚁集团 AI 系统工程师
文|张吉 (花名:理之)
蚂蚁集团 AI 系统工程师
文|兰霆峰
四川大学 20 级计算机系
背景
如今大语言模型 (LLM) 的分布式训练节点规模越来越大,训练耗时长。比如 OpenAI 在 1024 个 NVIDIA A100 GPU 上训练 GPT-3 大约需要 34 天。训练节点越多,耗时越长,训练期间节点故障概率就越大,况且 A100 GPU 的故障率也相对较高。所以大规模训练作业难免会遇到节点故障。据我们在蚂蚁 GPU 训练集群上观察,一个月内,单卡的故障率约 8%,那么一天单卡的故障率约为 0.27%。常见的故障原因有 Xid、ECC、NVLINK error 和 NCCL error 故障等。对于一个千卡训练作业来说,卡故障导致一天内训练失败的概率高达到 93%。所以训练作业几乎每天都会失败。作业失败后,用户需要手动重启作业,运维成本很高。如果用户重启不及时,中间间隔的时间就会导致 GPU 卡空闲,浪费昂贵的算力资源。
有些故障会导致机器不可用,从而导致可用节点数量不能达到用户指定的数量。这时,训练就不能启动,用户需要手动减少节点数量后重新提交作业。待故障机修复后,用户又需要手动增加作业的节点数来重启作业。这样增大了用户的运维成本,也导致了新节点无法及时加入训练。
为此,DLRover 在 Kubernetes 上基于 Torch Elastic 开发了弹性训练功能,实现 PyTorch 分布式训练的自动容错和弹性。具体功能如下:
-
出现故障后,快速执行节点健康检测,定位故障机并将其隔离,然后重启 Pod 来替换故障节点。
-
健康检测通过后,重启训练子进程来自动恢复模型训练,无需重启作业或者所有 Pod。
-
节点故障导致可用机器少于作业配置,自动缩容来继续训练。集群新增机器后,自动扩容来恢复节点数量。
-
优化 FSDP 并行训练的模型 save/load,支持根据实际卡数 reshard 模型参数,缩短 checkpoint 保存和加载时间。
在 DLRover 弹性容错应用在蚂蚁大模型训练前,一周内千卡训练运行时间占 60.8%,有效训练时间约 32.9%。有效训练时间=模型迭代的步数*每步的时间,除此之外,训练运行时间还包括 checkpoint 保存时间和训练回退时间等。DLRover 上线后,一周内千卡训练运行时间占比提升至 83.6%,有效训练时间提升至 58.9%。
PyTorch 弹性训练框架
弹性训练是指在训练过程中可以伸缩节点数量。当前支持 PyTroch 弹性训练的框架有 Torch Elastic 和 Elastic Horovod。二者显著的区别在于节点数量变化后是否需要重启训练子进程来恢复训练。Torch Elastic 感知到新节点加入后会立刻重启所有节点的子进程,集合通信组网,然后从 checkpoint 文件里恢复训练状态来继续训练。而 Elastic Horovod 则是每个训练子进程在每个 step 后检查新节点加入,子进程不退出的情况下重新集合通信组网,然后有 rank-0 将模型广播给所有 rank。二者的优劣对比如下:
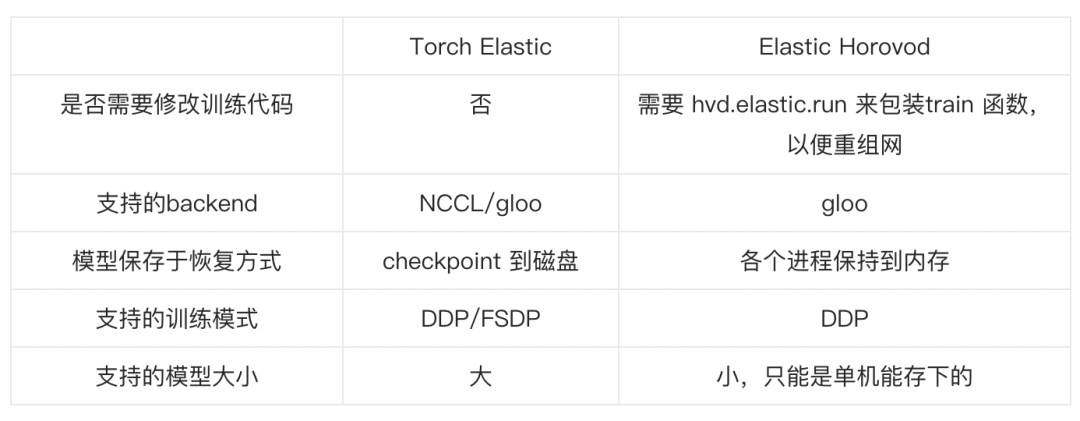
通过上述对比可以看出,Torch Elastic 重启训练子进程的方案对用户更加友好,支持更多的分布式训练策略和模型。而 FSDP 和 NCCL 是当前大模型分布式训练使用最为广泛的技术。所以 DLRover 选择使用 Torch Elastic 重启子进程的方案来实现 Kubernetes 集群上分布式训练的弹性容错。
集合通信动态组网
动态组网是指训练进程可以自动根据动态变化的节点数量来组网集合通信,无需固定给各个节点指定集合通信的 rank 和 world size。动态组网是弹性容错训练必须的,因为弹性容错作业中,节点的失败、扩容或者缩容都会导致节点的 rank 和 world size 变化。所以我们无法在作业启动前给节点指定 rank 和 world size。
Torch Elastic 动态组网
Torch Elastic 启动子进程后,所有子进程需要进行集合通信组网。Torch Elastic 使用 Dynamic Rendezvous 机制来协助子进程组网。每个节点上运行一个 ElasticAgent,ElasticAgent 会从一个共享存储中获取作业节点的 host group,然后将自己的 host 加入 group 并同步到共享存储里。这个共享存储当前默认使用 TCPStore。接着,ElasticAgent 不断从共享存储里获取查询 host group,直到 host group 里的节点数量达到最小节点数量 min_n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









