






目录
在机器学习和统计模型中,常见的评价方法(scoring methods)用于衡量模型的性能和预测能力。下面列举了一些常见的评价方法,并提供了详细的说明和示例:
首先,这里有一组数据:
| 预测值 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 真实值 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
整理一下得到:
| 预测值=1 | 预测值=0 | |
| 真实值=1 | 5 | 2 |
| 真实值=0 | 4 | 4 |
其中的数字还有着特殊的含义:
TP(True Positive):5
FP(False Positive):4
FN(False Negative):2
TN(True Negative):4
为了方便查看,我会在每个方法下列出这个表,并将各个数字的特殊含义标注在旁边。
1、准确率(Accuracy)
准确率(Accuracy): 准确率是分类问题中常见的评价指标,它衡量模型正确预测的样本数量与总样本数量之间的比例。值越接近1表示模型预测越准确。
| 预测值=1 | 预测值=0 | |
| 真实值=1 | 5(TP) | 2(FN) |
| 真实值=0 | 4(FP) | 4(TN) |
计算公式如下:
Accuracy(准确率):
=
=
准确率在多类别分类问题中常用,尤其当各个类别的样本数量接近时。
- 优点:准确率简单直观,易于理解和解释。
- 缺点:在处理类别不平衡问题时,准确率可能会给出误导性结果,特别是当不同类别的样本数量差异很大时。
2、精确率(Precision)
精确率(Precision)是指在所有预测为正类别的样本中,真正为正类别的样本数量的比例。它衡量了模型预测为正类别的准确性。
| 预测值=1 | 预测值=0 | |
| 真实值=1 | 5(TP) | 2(FN) |
| 真实值=0 | 4(FP) | 4(TN) |
计算公式如下:
精确率(Precision):
=
=
常用于二分类问题,特别是在处理不均衡类别的情况下。
- 优点:精确率和召回率关注不同的方面,可以提供更全面的模型性能评估。
- 缺点:精确率和召回率在某些情况下是互相矛盾的。提高精确率可能降低召回率,而提高召回率可能降低精确率。因此,需要根据具体问题权衡精确率和召回率的重要性。
3、召回率(Recall)
召回率(Recall)是指在所有真实为正类别的样本中,被正确预测为正类别的样本数量的比例。它衡量了模型对正类别样本的查全率(覆盖率)。
| 预测值=1 | 预测值=0 | |
| 真实值=1 | 5(TP) | 2(FN) |
| 真实值=0 | 4(FP) | 4(TN) |
计算公式如下:
召回率(Recall):
=
=
和精确率一样常用于二分类问题,特别是在处理不均衡类别的情况下。
- 优点:精确率和召回率关注不同的方面,可以提供更全面的模型性能评估。
- 缺点:精确率和召回率在某些情况下是互相矛盾的。提高精确率可能降低召回率,而提高召回率可能降低精确率。因此,需要根据具体问题权衡精确率和召回率的重要性。
注意:精确率和召回率是相关联的指标,它们通常是共同使用的,用于评估分类模型的性能。在某些情况下,精确率和召回率可能会相互矛盾,提高精确率可能会导致召回率下降,提高召回率可能会导致精确率下降。因此,需要根据具体问题和需求权衡两者的重要性。
精确率和召回率的应用场景:
- 精确率更注重模型的预测准确性,适用于对误报较为敏感的问题。例如,在垃圾邮件分类中,更关注将正常邮件误判为垃圾邮件的情况。
- 召回率更注重模型的查全率,适用于对漏报较为敏感的问题。例如,在癌症检测中,更关注不错过真正患病病例的情况。
4、F1值(F1-score)
F1值是精确率和召回率的综合指标,用于平衡模型的准确性和召回能力。它将精确率和召回率的调和平均作为综合评价指标。
| 预测值=1 | 预测值=0 | |
| 真实值=1 | 5(TP) | 2(FN) |
| 真实值=0 | 4(FP) | 4(TN) |
计算公式如下:
F1值(F1-score):
=
=
F1值在需要平衡模型的准确性和召回能力时使用,适用于二分类问题。
- 优点:F1值综合了精确率和召回率的信息,适用于评估模型的整体性能,并能处理类别不平衡问题。
- 缺点:F1值将精确率和召回率一视同仁,对于某些特定问题可能不够准确。
5、python代码示例
这段代码加载了 pandas 库和 LogisticRegression 类。它从一个名为 '鸢尾花训练数据.xlsx' 的 Excel 文件中读取训练数据,并提取了特征和标签。然后,它使用逻辑回归模型对训练数据进行拟合训练。接下来,使用训练好的模型对训练集进行预测,并使用 metrics 模块中的 classification_report 函数生成分类报告,最后将其打印出来。
import pandas as pd
from sklearn.linear_model import LogisticRegression
train_data=pd.read_excel('鸢尾花训练数据.xlsx') # 读取训练数据
train_x=train_data[['萼片长(cm)','萼片宽(cm)','花瓣长(cm)','花瓣宽(cm)']] # 提取特征和标签
train_y=train_data['类型_num']
model=LogisticRegression() # 创建逻辑回归模型
model.fit(train_x,train_y) # 训练模型
predict_x=model.predict(train_x) # 对训练集进行预测
from sklearn import metrics
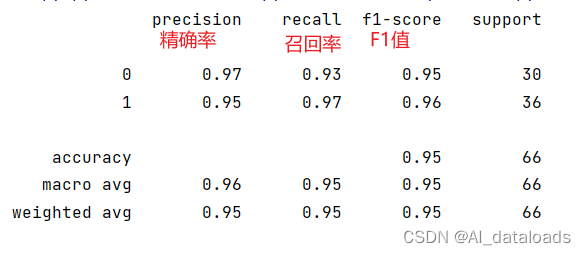
print(metrics.classification_report(train_y,predict_x)) # 打印分类报告
运行结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









