






目录
了解交叉验证
交叉验证就是将原始数据(data)进行分组,一部分做为训练集(train),另一部分做为验证集(test),首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型,以此来做为评价分类器的性能指标。可见交叉验证详解
案例(准备工作)
我们话不多说,直接用案例来更清晰的展示

假设这是我们根据用户特征构造出的数据集(一部分),前面还有很多数据
不过没关系,都是特征数据,而Class是标签数据,0代表信用度良好,1代表老赖
如何导入库
我们这个代码需要下载很多库,没有安装的帅哥美女,直接用pip安装即可(建议直接修改源镜像地址,速度快,而且还很方便);具体参考修改镜像源地址
数据标准化
不难发现,我们前面的特征数据,他们的特征值大概在【-1,1】的区间,而Amount列数据很大
所以为了得到更精确的数据,以及方便运算,我们对Amount列做一个标准化
首先我们把数据读进来
data = pd.read_csv('D:\BaiduNetdiskDownload\creditcard.csv')从sklearn库中,导入StandardScaler
from sklearn.preprocessing import StandardScalerss = StandardScaler()
# 用data['Amount'] = 就可以直接将标准化后的数据覆盖到原始数据
data['Amount'] = ss.fit_transform(data[['Amount']])
# fit_transform 就是对数据标准化提取特征值和标签
data_feature = data.drop('Class', axis=1)
# axis=1表示Class这一整列,我们用drop删除Class列,剩下的就是特征数据
data_label = data['Class']
# 单独提取Class标签列切分原始数据
# 首先从sklearn中导入切分函数
from sklearn.model_selection import train_test_split将原始数据进行切分,得到训练数据和测试数据
train_feature_select, test_feature_select, train_label_select, test_label_select = \
train_test_split(data_feature, data_label, test_size=0.2, random_state=1)
# test_size=0.2 表示从样本中抽取20%作为测试数据,剩下的80%作为训练数据
# random_state 表示将随机抽出来的数据固定,这样就不至于每次运行时,得到的数据都不一样(后面参数可以随便给)train_feature_select:切分出来用于训练的特征数据
test_feature_select:切分出来用于测试的特征数据
train_label_select:切分出来用于训练的标签数据
test_label_select:切分出来用于测试的标签数据
案例(交叉验证)
最优惩罚因子
接下来对切分出来的数据进行交叉验证,以此来得到最优参数
# 逻辑回归函数
from sklearn.linear_model import LogisticRegression
# 交叉验证函数
from sklearn.model_selection import cross_val_score# 交叉验证中C值(lanmda)一般取0.01,0.1,1,10,100
c_list = [0.01, 0.1, 1, 10, 100]
# 用来接收每次循环后的正确率
score_list = []
z = 1
for i in c_list:
# 调用逻辑回归函数,先确定最大迭代次数为1000
lr = LogisticRegression(C=i, max_iter=1000)
# 把逻辑回归函数及抽取出来的训练特征和训练标签传入,通过召回率来确定最优解
# cv=10,表示把数据切分成10个样本,每个样本进行一次测试,共10次
recall_score = cross_val_score(lr, train_feature_select, train_label_select, cv=10, scoring='recall')
# 将每次得到的召回率加起来,除以次数,得到平均值,有几个样本就进行几次,所以用len()表示
recall_sc_ave = sum(recall_score) / len(recall_score)
score_list.append(recall_sc_ave)
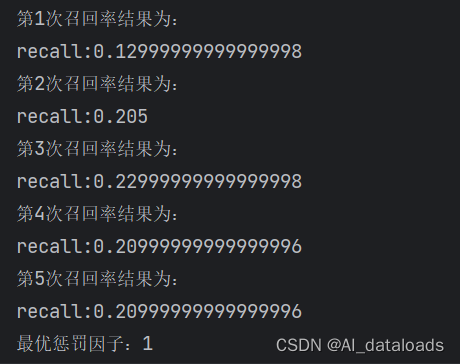
print(f'第{z}次召回率结果为:')
print(f'recall:{recall_sc_ave}')
z += 1
# np.argmax()表示列表中数值最大的索引,用c_list[索引]得到最大数值
score_best = c_list[np.argmax(score_list)]
print(f'最优惩罚因子:{score_best}')结果
最佳迭代次数
我们还可以对迭代次数进行交叉验证,来得到最佳迭代次数,实际上就是求迭代时间最短的
# 需要导入time时间库
import time# 我们取迭代次数分别为500次,800次,1000次,1500次,2000次
iter_best = [500, 800, 1000, 1500, 2000]
# 用来接收代码运行时间,方便比较最佳迭代时间
running_time = []
for j in iter_best:
# 代码开始时间
start = time.time()
# C=score_best 是我们前面得出的最优惩罚因子
lr_best = LogisticRegression(C=score_best, max_iter=j)
# 和前面代码一致
recall_score = cross_val_score(lr_best, train_feature_select, train_label_select,
cv=10, scoring='recall')
recall_sc_ave = sum(recall_score) / len(recall_score)
# 代码结束时间
end = time.time()
best_time = end - start
running_time.append(str(best_time))
print(running_time)
best_iter = iter_best[np.argmin(running_time)]
print(f'最优迭代次数:{best_iter}')结果

最佳迭代次数为1000,所以迭代时间不与迭代次数成正比
总结
交叉验证的目的是为了得到可靠稳定的模型,评估给定算法在特定数据集上训练后的泛化性能的好坏。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









