






目录
5.判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU
一、手写字识别
1.先导入我们需要的库
import torch.cuda
from torch import nn #导入神经网络模块
from torch.utils.data import DataLoader #数据包管理工具
from torchvision import datasets #数据处理工具,专门用于图像处理的包
from torchvision.transforms import ToTensor #数据转换,张数2.下载我们需要的数据集(包括了训练图片和标签)
#datasets.MNIST来加载MNIST数据集作为训练数据集。
#root='data':指定数据集存储的根目录,可以根据需要进行更改。
#train=True:表示加载训练数据集
#download=True:如果数据集在指定路径中不存在,将自动从官方源下载并保存。
#transform=ToTensor():指定数据转换操作,将图像数据转换为PyTorch中的Tensor张量格式。
training_data = datasets.MNIST(
root='data',
train=True,
download=True,
transform=ToTensor(), #张量
) #对于pythorch库能够识别的数据一般是tensor张量
test_data = datasets.MNIST(
root='data',
train=False,
download=True,
transform=ToTensor()
)运行效果:(会下载到你指定的data文件中)
3.展示手写字图片,把训练数据集中前9张图片展示
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):
#这一行代码从训练数据集(training_data)中获取第i+10000个数据样本的图像(img)和标签(lable)
img,lable = training_data[i+10000]
figure.add_subplot(3,3,i+1) #这一行代码将一个3x3的子图添加到Figure对象中,将第i+1个子图作为当前子图。
plt.title(lable)
plt.axis('off')
plt.imshow(img.squeeze(),cmap='gray') #img.squeeze 将维度进行压缩
plt.show()运行效果:
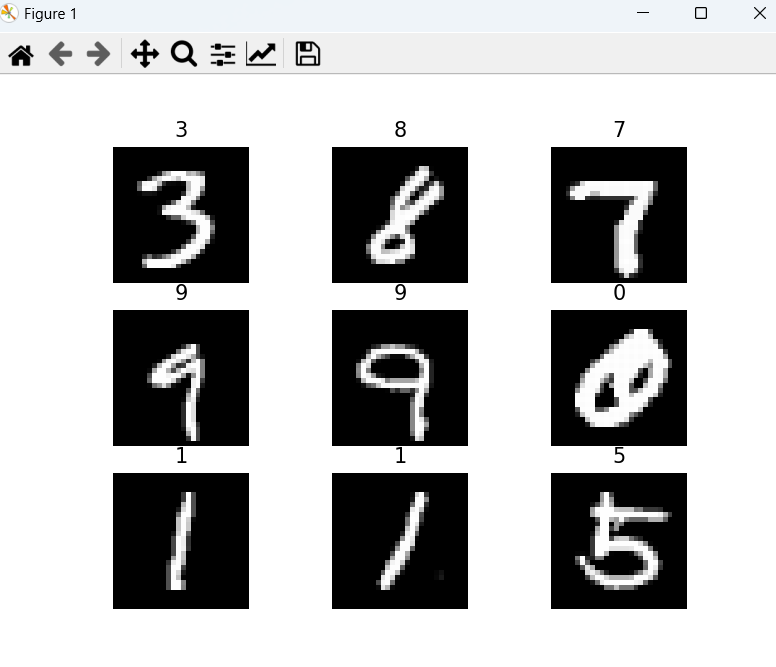
4.创建数据DataLoader(数据加载器)
train_dataloader = DataLoader(training_data,batch_size=64) #64张图片为一个包
test_dataloader = DataLoader(test_data,batch_size=64)
for X,Y in train_dataloader: #X表示打包好的每一个数据包
print(f'Shape of X[N,C,H,W]:{X.shape}')
print(f'Shape of Y:{Y.shape}{Y.dtype}')
break运行结果:

.简单的对这段代码和运行结果进行解释:
-
bath_size:将数据集分成多份,每一份为bath_size个数据,可以减少内存的使用,提高训练的速度。(此处是64张图片为一个包)
-
64: 表示批次大小(batch size),即该张量包含了64个样本。
-
1: 表示通道数(channel),在这里是灰度图像,所以通道数为1。
-
28: 表示图像的高度(height),即每个图像有28个像素点的高度。
-
28: 表示图像的宽度(width),即每个图像有28个像素点的宽度。
5.判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU
import torch
cuda_available = torch.cuda.is_available()
map_available = torch.backends.mps.is_available() #检查MPS的可用性
if cuda_available:
device='cuda'
elif map_available:
device='mps'
else:
device='cpu'
print(f'Using device is {device}')运行结果:
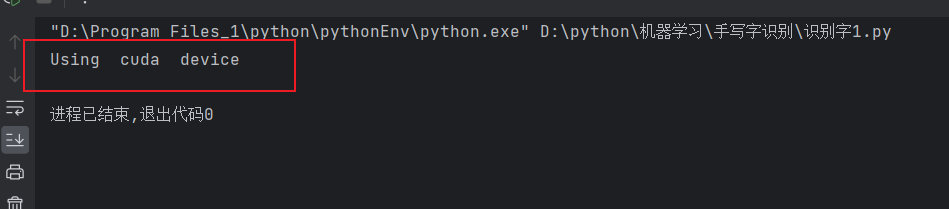
6.创建神经网络
class NeuralNetwork(nn.Module): #通过调用类的形式来使用神经网络
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() #创建一个 nn.Flatten 层,用于将输入的二维图像数据展平成一维向量
self.hidden1 = nn.Linear(28*28,128) #创建一个线性层,输入大小为 28x28(展平后的图像大小),输出大小为 128。这是第一个隐藏层
self.hidden2 = nn.Linear(128,64) #创建第二个线性层,输入大小为 128,输出大小为 64。这是第二个隐藏层。
self.hidden3 = nn.Linear(64,64) #创建第三个线性层,输入大小为 64,输出大小仍然为 64。这是第三个隐藏层。
self.out = nn.Linear(64,10) #创建一个线性层,输入大小为 64,输出大小为 10。这是输出层,通常用于分类问题,其中 10 表示模型要输出的类别数目。
def forward(self,x): #定义了前向传播函数,该函数接收输入数据 x,并描述了如何计算模型的输出。
x = self.flatten(x) #将输入数据 x 展平成一维向量
x = self.hidden1(x) #将展平后的数据传递给第一个隐藏层 hidden1
x = torch.relu(x) #对第一个隐藏层的输出应用 ReLU(修正线性单元)激活函数。
x = self.hidden2(x) #将经过 ReLU 激活的数据传递给第二个隐藏层 hidden2。
x = torch.sigmoid(x) #对第二个隐藏层的输出应用 Sigmoid 激活函数
x = self.hidden3(x) #将经过 Sigmoid 激活的数据传递给第三个隐藏层
x = torch.relu(x) #对第三个隐藏层的输出应用 ReLU 激活函数
x = self.out(x) #将经过 ReLU 激活的数据传递给输出层 out
return x #返回模型的输出
model = NeuralNetwork().to(device) #创建一个神经网络模型的实例,并将其移动到指定的设备上(根据先前定义的 device)
print(model) #打印模型的结构
print('权重个数为:',((28*28)+1)*128+129*256+257*10)运行结果: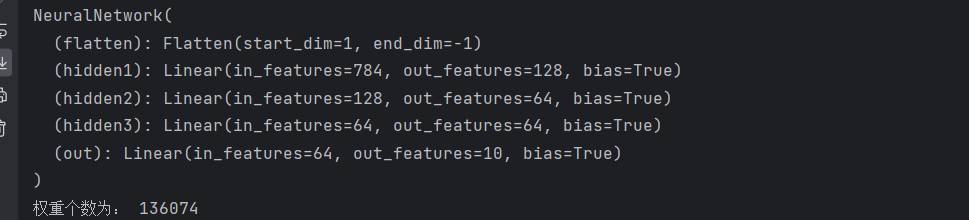
什么是权重:在神经网络中,每个连接都有一个权重,它决定了信号在神经网络中传递时的强度和方向。这些权重是模型通过训练学习到的,以便最小化损失函数并使模型能够对输入数据做出正确的预测或分类。
7.训练深度学习模型
def train(dataloader,model,loss_fn,optimizer): #函数定义,定义了一个名为train的函数,该函数接受四个参数:dataloader(数据加载器,用于提供训练数据批次)、model(深度学习模型)、loss_fn(损失函数,用于度量模型预测与实际标签之间的误差)、optimizer(优化器,用于更新模型的权重以减小损失)。
model.train()
batch_size_num = 1 #这一行代码初始化一个变量batch_size_num,用于跟踪处理的批次数量,初始值为1。
for x,y in dataloader: # 这是一个循环,遍历数据加载器中的每个训练批次。在每个循环迭代中,x 表示输入数据,y 表示对应的目标标签。
x,y = x.to(device),y.to(device) #这一行代码将输入数据 x 和目标标签 y 移动到指定的设备(在代码中应该有一个 device 变量,表示模型所在的设备,通常是 CPU 或 GPU)上进行计算。
pred = model.forward(x) #这一行代码使用模型 model 来进行前向传播,计算输入数据 x 的预测值 pred
loss = loss_fn(pred,y) #使用损失函数 loss_fn 来计算模型预测值 pred 与实际标签 y 之间的损失(误差)。
optimizer.zero_grad() #用于清零优化器 optimizer 中存储的之前的梯度信息。
loss.backward() #执行反向传播,计算损失相对于模型参数的梯度
optimizer.step() #使用优化器来更新模型的参数,以减小损失
loss_value = loss.item() #获取当前批次的损失值,并将其存储在 loss_value 变量中。
print(f'loss:{loss_value:>7f}[num:{batch_size_num}]') #打印当前批次的损失值和批次编号,以便监视训练过程中损失的变化。
batch_size_num += 1 #增加批次编号,以便在下一个批次中使用正确的编号。
loss_fn = nn.CrossEntropyLoss() #用于定义交叉熵损失函数的操作。这通常用于分类任务中,用于度量模型输出与真实类别分布之间的差异。
optimizer = torch.optim.Adam(model.parameters(),lr=0.0015) # 这是一个用于定义 Adam 优化器的操作,该优化器用于更新模型参数以减小损失。lr=0.0015 表示学习率,即每次参数更新的步长。
train(train_dataloader,model,loss_fn,optimizer)运行效果:(运行了938次,并打印每一次的损失值)
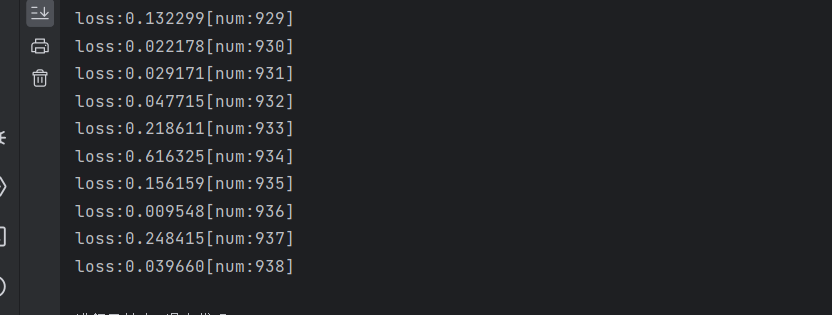
8.对深度学习模型进行测试
def test(dataloader,model,loss_fn):
size = len(dataloader.dataset) #代码计算测试数据集的总样本数,并将结果存储在变量 size 中。
num_batches = len(dataloader) #计算数据加载器中的批次数量,并将结果存储在变量 num_batches 中。
model.eval() #将模型设置为评估模式。在评估模式下,模型不会进行梯度计算和参数更新,而是专注于进行推断(预测)。
test_loss,correct = 0,0 #初始化两个变量 test_loss 和 correct,用于分别存储测试损失和正确预测的数量。
with torch.no_grad(): #上下文管理器,用于在其内部的代码块中禁用梯度计算。这是因为在测试阶段,我们不需要计算梯度,只需要进行前向传播和评估模型性能。
for x,y in dataloader: #循环,遍历测试数据加载器中的每个测试批次。在每个循环迭代中,x 表示输入数据,y 表示对应的目标标签。
x,y = x.to(device),y.to(device) #代码将输入数据 x 和目标标签 y 移动到指定的设备
pred = model.forward(x) #使用模型 model 来进行前向传播,计算输入数据 x 的预测值 pred。
test_loss += loss_fn(pred,y).item() #计算当前批次的损失值,并将其累加到 test_loss 变量中。
correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 这一行代码计算当前批次中正确预测的样本数量,并将其累加到 correct 变量中。它首先使用 argmax 方法找到预测值中的最大值的索引,然后与真实标签比较以确定是否预测正确。
test_loss /= num_batches #平均正确率
correct /= size # 这一行代码计算准确率,将正确预测的样本数量除以总样本数,并将结果存储在 correct 中。
print(f'Test result: \n Accuracy:{(100*correct)}%,Avg loss: {test_loss}') #打印测试结果
test(test_dataloader,model,loss_fn)运行结果:
9.将训练过程重复执行多个周期(epochs)
目的:提高预测的正确率
epochs = 10 #训练循环将运行的总周期数
for t in range(epochs): #创建一个循环,从0到9迭代10次,每次代表一个训练周期(epoch)。
print(f'Epochs {t+1}\n------')
train(train_dataloader,model,loss_fn, optimizer)
print('Done!')
test(test_dataloader,model,loss_fn)运行结果:
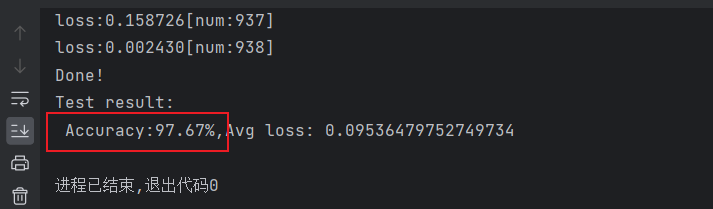
我们可以发现,准确率大大提高,可见将训练过程重复执行多个周期的重要性!
二、代码全览
方便你去复现
import torch.cuda
from torch import nn #导入神经网络模块
from torch.utils.data import DataLoader #数据包管理工具
from torchvision import datasets #数据处理工具,专门用于图像处理的包
from torchvision.transforms import ToTensor #数据转换,张量
'''下载训练集数据集(包含训练图片和标签)'''
#datasets.MNIST来加载MNIST数据集作为训练数据集。
#root='data':指定数据集存储的根目录,可以根据需要进行更改。
#train=True:表示加载训练数据集
#download=True:如果数据集在指定路径中不存在,将自动从官方源下载并保存。
#transform=ToTensor():指定数据转换操作,将图像数据转换为PyTorch中的Tensor张量格式。
training_data = datasets.MNIST(
root='data',
train=True,
download=True,
transform=ToTensor(), #张量
) #对于pythorch库能够识别的数据一般是tensor张量
test_data = datasets.MNIST(
root='data',
train=False,
download=True,
transform=ToTensor()
)
# print(len(training_data))
'''展示手写字图片,把训练数据集中前9张图片展示'''
from matplotlib import pyplot as plt
figure = plt.figure()
for i in range(9):
#这一行代码从训练数据集(training_data)中获取第i+10000个数据样本的图像(img)和标签(lable)
img,lable = training_data[i+10000]
figure.add_subplot(3,3,i+1) #这一行代码将一个3x3的子图添加到Figure对象中,将第i+1个子图作为当前子图。
plt.title(lable)
plt.axis('off')
plt.imshow(img.squeeze(),cmap='gray') #img.squeeze 将维度进行压缩
# plt.show()
'''创建数据DataLoader(数据加载器)
bath_size:将数据集分成多份,每一份为bath_size个数据
优点:可以减少内存的使用,提高训练的速度
'''
'''64: 表示批次大小(batch size),即该张量包含了64个样本。
1: 表示通道数(channel),在这里是灰度图像,所以通道数为1。
28: 表示图像的高度(height),即每个图像有28个像素点的高度。
28: 表示图像的宽度(width),即每个图像有28个像素点的宽度。'''
train_dataloader = DataLoader(training_data,batch_size=64) #64张图片为一个包
test_dataloader = DataLoader(test_data,batch_size=64)
for X,Y in train_dataloader: #X表示打包好的每一个数据包
print(f'Shape of X[N,C,H,W]:{X.shape}')
print(f'Shape of Y:{Y.shape}{Y.dtype}')
break
'''判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU'''
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')
'''创建神经网络模型'''
class NeuralNetwork(nn.Module): #通过调用类的形式来使用神经网络
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() #展开,创建一个展开对象flatten
self.hidden1 = nn.Linear(28*28,128)
self.hidden2 = nn.Linear(128,64)
self.hidden3 = nn.Linear(64,64)
self.out = nn.Linear(64,10)
def forward(self,x):
x = self.flatten(x) #图像进行展开
x = self.hidden1(x)
x = torch.relu(x)
x = self.hidden2(x)
x = torch.sigmoid(x)
x = self.hidden3(x)
x = torch.relu(x)
x = self.out(x)
return x
model = NeuralNetwork().to(device)
print(model)
print('权重个数为:',((28*28)+1)*128+129*256+257*10)
def train(dataloader,model,loss_fn,optimizer):
model.train()
batch_size_num = 1
for x,y in dataloader:
x,y = x.to(device),y.to(device)
pred = model.forward(x)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_value = loss.item()
print(f'loss:{loss_value:>7f}[num:{batch_size_num}]')
batch_size_num += 1
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.0015) #可以用Adam 最好的模型
train(train_dataloader,model,loss_fn,optimizer)
def test(dataloader,model,loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() #测试
test_loss,correct = 0,0
with torch.no_grad():
for x,y in dataloader:
x,y = x.to(device),y.to(device)
pred = model.forward(x)
test_loss += loss_fn(pred,y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches #平均正确率
correct /= size
print(f'Test result: \n Accuracy:{(100*correct)}%,Avg loss: {test_loss}')
epochs = 10
for t in range(epochs):
print(f'Epochs {t+1}\n------')
train(train_dataloader,model,loss_fn, optimizer)
print('Done!')
test(test_dataloader,model,loss_fn)
















 4297
4297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









