






导读:易用性、开放性已成为大模型新一轮PK的考场。
随着高考成绩公布,AI“做题家”再度引发热议。不久前,浪潮“源1.0”大模型模仿鲁迅、金庸文风成功挑战最难高考作文,并出色完成了文言文阅读,历史、地理等科目考题。
其实,“做题”只是AI大模型的小试牛刀。AI大模型的真正考场在落地应用。因为直面长尾场景和AI开发高门槛等痛点,大模型被视为解决AI落地难的一剂良方。过去两年内大模型雨后春笋般涌现,有实力的科技企业纷纷推出自家的大模型,参数、数据集的规模也不断攀升。
然而,大模型虽好但面临落地应用难题,成为产业界共同的挑战。当下,易用性、开放性成为大模型新一轮PK的考场,不妨看看浪潮“源1.0”大模型交出了怎样的答卷。

大模型,智能时代的算法基础设施
大模型在今天成为产业热点绝非偶然。可以说,它的出现为困境中的AI产业化推开了一扇门。
在大模型出现之前,人工智能模型的通用性不高,一个模型仅专用于特定领域,即“一个模型一个场景”,换个场景就要从0开始重新开发。而且,传统的AI模型开发成本高,周期长,迭代慢,无法适配企业敏捷创新的业务需求。随着AI技术从高频主流场景到低频长尾场景的渗透,场景碎片化与“手工作坊式”开发的矛盾日益加剧,对AI技术提出了挑战,也限制了AI的产业化进程。
大模型提供了一种“预训练大模型+下游任务微调”的全新模式,可以大大提高模型的泛化能力,提高AI的通用求解能力。而且,经过预训练的大模型可以让研究机构和企业“不必从0做起,而是可以在大模型的基础上,从60、或者从90开始做到100”。
“大模型最重要的优势是进入大规模可复制的工业落地阶段,只需小样本的学习也能达到比以前更好的效果,且模型参数规模越大这种优势越明显,这能大大降低各类用户的开发使用成本。”浪潮信息AI软件研发总监吴韶华表示。
正是由于出色的泛化能力,大模型被誉为智能时代的算法基础设施。正如发电厂和高速公路一样,大模型将成为各行各业应用AI技术的底座和创新的源头。
目前,在探索大模型落地的道路上,产业界已经做了很多尝试。其中,轻量化做场景适配以及开源开放,已成为行业共识的两大趋势。目前,两个方向都做得好的企业并不多,浪潮是其中之一。

如何让大模型分身有术
将大模型蒸馏成相对轻量的、更垂直的模型,已经成为产业界的普遍做法。其原理是知识蒸馏(Knowledge Distillation),它是一种基于“教师-学生网络”模式的模型压缩方法,可以将已经训练好的大模型包含的知识,蒸馏提取到另一个小的模型中去。
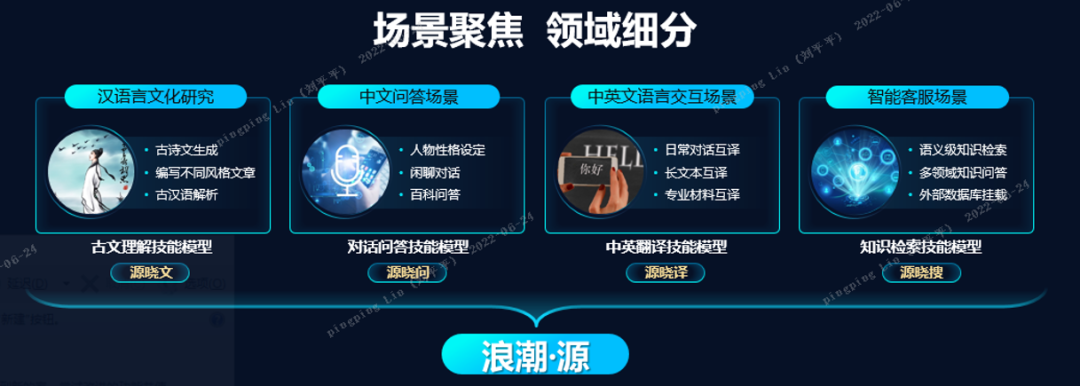
近日,浪潮基于“源1.0”千亿大模型蒸馏出4个百亿参数规模的技能模型:对话问答技能模型、知识检索技能模型、中英翻译技能模型、古文理解技能模型,在细分领域精确度业内领先,获得权威评测基准CLUE、CUGE榜单榜首,并已在南京智能计算中心成功落地运行。「智能进化论」认为,浪潮的技能模型具有“轻、快、强”的特点。
轻
浪潮技能模型的百亿参数规模,大幅降低了训练、推理、部署的门槛,并极大降低了开发训练成本。相当于巨量模型一下子有了N个轻量化“分身”,可以直接面向对话、问答等主流场景化应用。
快
浪潮技能模型将过去动辄几个月甚至几年的大模型开发训练周期,缩短至不足一个月,加速了企业利用技能模型不断创新的速度。
强
分身是为了更专注,浪潮技能模型在性能上并不减配。4个技能模型在相同任务上可保留98%的大模型效果,在特定领域任务中,甚至能得到比大模型更好的效果,但参数量仅是“源1.0”大模型的1/10,推理速率提升9倍。
在各自领域,浪潮四大技能模型在国际权威测评和榜单中都是学霸。比如,对话问答技能模型(源晓问)在业界权威测评WebQA开放问答数据集及CUGE两项榜单均位居榜首,可广泛应用于虚拟人、智能助手、智能客服等场景。中英翻译技能模型(源晓译)在业内权威WMT数据集及CUGE两项榜单均位居榜首,可轻松应对日常中英翻译任务。知识检索技能模型(源晓搜)在WebQA任务上以55.97%的准确度领先业界,可广泛应用于医疗、法律、保险及娱乐等领域的智能客服、个人助理等场景。
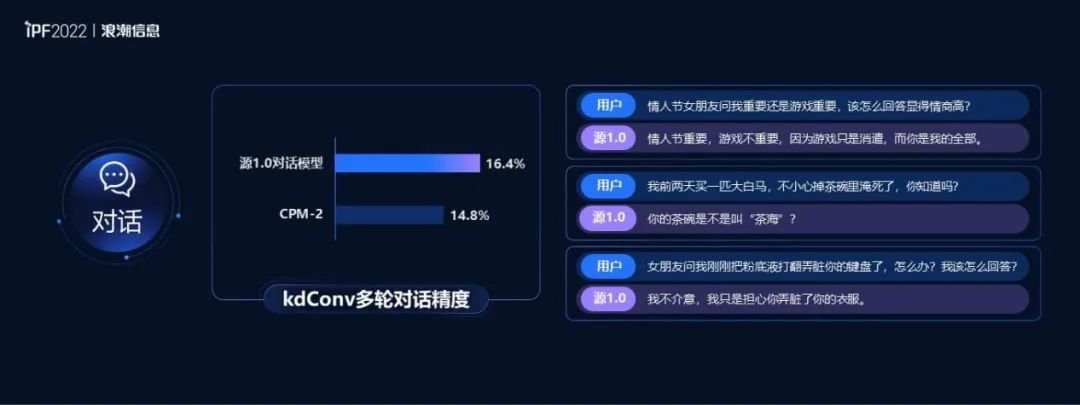
在实际场景中,浪潮四大技能模型的能力已经得到了充分验证。比如,基于业界领先的kdConv多轮对话精度,对话问答技能模型(源晓问)在日常对话场景已经具备相当的情商,达到了“人机难辨”的程度。
此外,正如“三人行必有我师”,技能模型和巨量模型如同身份灵活转换的师生,可以在双方协同中持续进化。通过将执行结果反馈给巨量模型,技能模型和巨量模型的知识与能力可以同步进化,从而实现落地场景越多,模型进化得“越聪明”。
让大模型成为所有人的游戏
如果说,大模型的研发是一场激动人心的游戏,那么它不该只是少数科学家的专利,所有人都应该拥有探索AI想象力的能力。
目前,“源1.0”大模型已经相继完成了模型API、高质量数据集、模型训练代码、推理代码和应用代码等内容的开源开放,在GitHub社区、浪潮源官网均可以申请获取相关的资源。已经有超过600家用户参与到“源1.0”大模型开放开源平台中。

吴韶华表示,为了打造高品质的AI开源社区,“源1.0”大模型从四个方面为开发者提供便利:
第一, 开源了直接可用的代码示例。开发者无需关心底层技术,无需配置编程环境,就可以直接将应用构建于AI大模型的能力之上,在降低开发门槛的同时,让开发人员将精力聚焦核心业务逻辑。
不久前刷屏的AI剧本杀就是开源带来的一个惊喜。基于“源1.0”的开放开源平台,一位普通开发者仅用一个月时间就开发出了“人机难辨”的AI剧本杀游戏。剧本杀中的AI像人类一样,会忽悠,会撒娇耍赖,为了赢得游戏还会撒谎,骗过了不少人类玩家。
AI剧本杀的创作者表示:“可以说源1.0是我见过的大模型开源项目中给到的质量最高的示例代码,好到什么程度呢?好到了我们直接拿来用的程度。”
“在大模型出现之前,如果要做这样一个剧本杀的游戏,需要很强大的模型,既要有对话能力,也要有逻辑推理能力,这对于模型的开发、数据的选择门槛很高。”吴韶华表示。

第二, 向开发者提供大模型API和丰富的开发工具,显著降低了应用开发的门槛。比如,源的官网同步开放和上线了APIExp和Web应用Sandbox(沙箱)开发工具,开发者可在APIExp上设置参数,零代码调用和测试所有已开放的模型服务。Sandbox可以让开发者仅修改少量代码,即可完成包含web交互的应用示例,从而快速验证业务逻辑和功能效果。
第三, 将“源1.0”大模型相关的训练数据开源。目前,已经有开发者直接利用开源的数据集对其模型进行二次训练,得到了明显的精度提升,训练结果甚至登顶CLUE基准评测榜单。
第四,为开发者提供持续的支撑,实现开源社区交流共赢。比如,浪潮有专门的运营团队与开发者无缝沟通。针对深入的技术问题,也有专门的研发团队进行研究和支持,交流成果还会以代码的方式进行开源。
低代码、低门槛,开发工具齐全、开箱即用……这些特点以及NLP巨量模型自身的魅力与潜力,让更多的、不限技术水平的开发者都有机会尝试大模型应用。未来,“源”还会进一步开放模型在线蒸馏、领域模型下载等服务,并完善和丰富更多基于大模型的应用示例。
“数字世界与实体世界的深度融合,为大模型的应用带来了更为广阔的前景。我们愿与各位伙伴一起联合创新,积极探索基于“源”的各类智能化应用。最后期待基于‘源’大模型,我们能够‘结四方之旷友,资数实以相融。’” 吴韶华表示。
目前,大模型还处在非常早期的发展阶段。易用性和开放性决定了大模型的生命力。前路漫漫,未来大模型需要面对的考试还有很多。也许有一天,当大模型人人用得起,当中小企业也可以用大模型来解决问题,大模型才算真正完成了毕业考试。
END
本文为「智能进化论」原创作品。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









