







 本文介绍了如何在Windows上使用Cygwin运行C语言编写的word2vec工具来训练词向量。通过安装Cygwin,配置必要的工具,下载并修改代码,最终成功执行训练并展示了一个简单的近义词查询示例。
本文介绍了如何在Windows上使用Cygwin运行C语言编写的word2vec工具来训练词向量。通过安装Cygwin,配置必要的工具,下载并修改代码,最终成功执行训练并展示了一个简单的近义词查询示例。
在Word2vec模型中,算法可以通过无监督的方法为每个词计算出一个d维的向量,即将每个词映射为d维的空间中的一个点,d维空间中点之间的距离(即每个词对应的d维向量的距离)可反映词之间的相似性。
dav/word2vec是一个经典的利用多线程训练词向量的代码,非常地好用且非常地高效。然而该代码是用Linux C语言写的,而且代码的调度使用的是shell。在Windows上安装Cygwin即可运行该代码。
1.下载Cygwin,安装包可在官网下载,也可加QQ群426491390从群文件中下载。
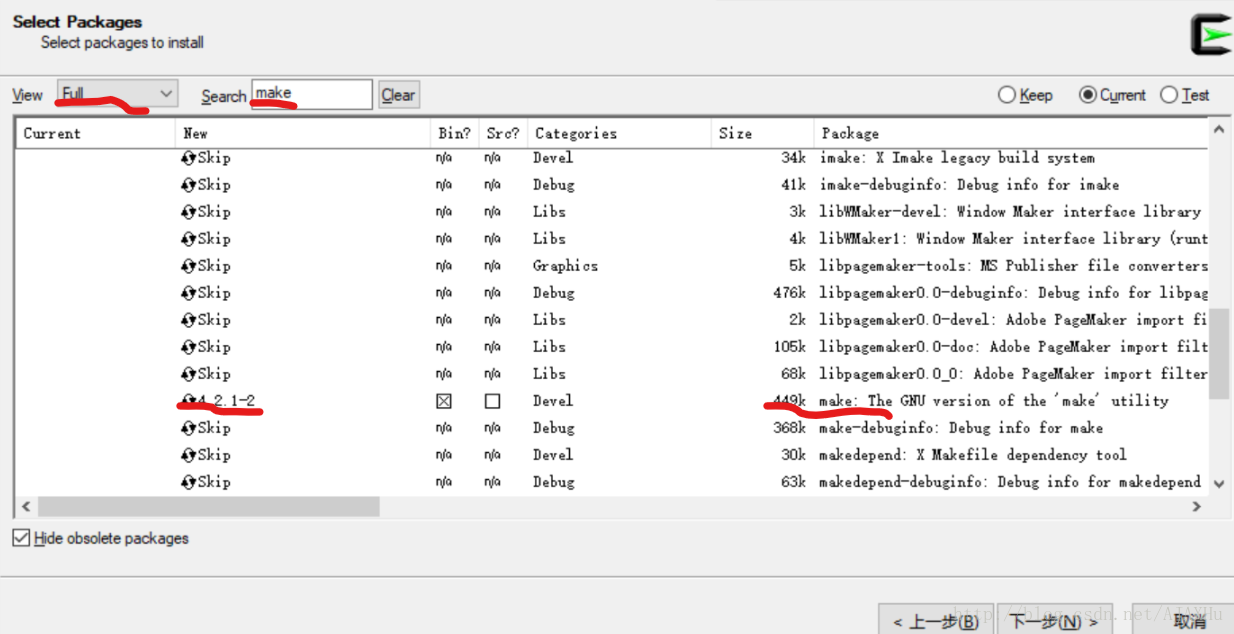
2.在Cygwin中安装gcc、make、wget、unzip命令。例如,安装make命令的方法如下图所示:
3.下载并解压dav/word2vec代码,代码也可从QQ群426491390从群文件中下载。
4.打开Cygwin,进入dav/word2vec所在文件夹(windows目录在Cygwin的/cygdrive目录下),实行命令:
cd scripts
sh demo-word.sh这时候发现报错了,这是因为word2vec中的src/makefile将word2vec.c编译成了类似word2vec而并非word2vec.exe,同样,scripts/demo-word.sh中执行的是bin/word2vec而不是word2vec.exe,因此要对src/makefile和scripts/demo-word.sh都进行一些修改,QQ群426491390群文件中的dev/word2vec版本已经修改过这俩文件。
将src/makefile修改为:
SCRIPTS_DIR 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









