







环境:
redis cluster集群分别在三个ip上部署了9个节点(7001-7009),三个主节点六个从节点;节点中主从数据同步确保正常;再在三个ip上部署了sentinel26379,sentinel26380,sentinel26381三个哨兵;
客户端连接:
- 使用ServiceStack组件 + .NET CORE 6.0;使用的哨兵+卡槽计算方式创建连接(ServiceStack官网信息说不支持redis cluster集群分区模式连接,要用redis sentinel哨兵模式创建连接,如果要用redis cluster集群分区模式得客户端代码实现,过程比较复杂)。
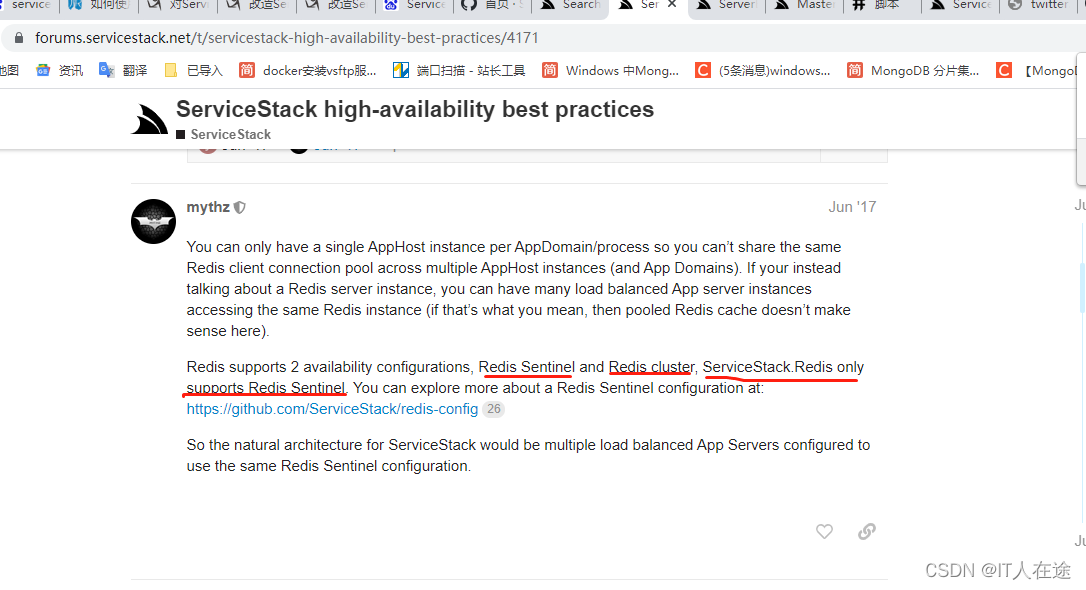
- 备用方案csredis组件 + .NET CORE 6.0;支持redis cluster集群分区和redis sentinel哨兵模式创建连接。
- 备用方案StackExchange组件 + .NET CORE 6.0;支持redis cluster集群分区和redis sentinel哨兵模式创建连接。
故障现象:
一、在csredis组件下出现的故障现象
在测试用例高压状态下手动kill掉当前应用命中的主节点,在配置的主从切换时间内没有顺利切换成功。
下例截图是使用csredis组件进行分析(这组件可以在控制台直观的显示出节点的状态和切换情况)
这个是在Redis Sentinel创建的连接
官网例子

我们的tcp应用


第一步先确认redis节点的状态

上图可以看出目前主节点是7001,7007,7008
第二步再确认sentinel哨兵的监控状态

上图可以看出哨兵监控到的主节点信息状态是正常的;
第三步启动tcp应用程序进行测试用例压测

上图看测试缓存各方面都是正常的;
第四步手动停掉7001主节点,继续进行测试用例压测


上图看到有10分钟左右csredis还是没能正常切换到其它从节点;
再到redis-cli客户查看一下哨兵的情况

发现sentinel哨兵是能正常选举切换到7004为主节点,这样就可以排除掉redis环境的部署问题,问题应该是出现在csredis组件的连接切换上;

这也近一步证明了自己的判断,csredis一直停留在故障节点,没有自动切换到下一点,这时去查看csredis源码

用csredis切换到redis cluster集群分区测试,得到的结果是一样的;然后再阿里云开发平台也发现同样的现象

而且csredis官方版本对redis cluster集群连接说明描述很有限

再压测过程还发现一个情况,就是在节点服务不是人为主动停止,而是哨兵主观下线(非真的挂)情况下,节点间的切换是正常的;如下图:

- 在ServiceStack组件下的故障现象
多方查找资料下发现ServiceStack对官方的redis cluster集群支持比较复杂,所以这里故障只在sentinel哨兵模式下验证;
第一步:配置好哨兵节点和对应的卡槽实例名称

并在连接创建类添加窗体输出,方便查看节点的切换情况

第二步:重复csredis压测步骤,确认哨兵和集群节点之间的状态


第三步:在确保redis集群状态正常的情况下启动tcp进行测试用例压测
在节点都正常的情况下,顺利注册完成,下面先记录一下注册用时

同时通过上面说的的窗体输出节点信息,发现在每个redis读写操作过程就会计算一遍key值所在的卡槽位置(也就是主从节点分布在3个ip端就计算一遍)(现不确定这里是否会有性能方面的问题)

第四步:停掉一个当前主节点试试看



注册工具也卡住不动了;


第五步:这是同样用redis-cli客户端工具去查看节点集群情况和哨兵的监控情况;
可以看到7004由原来的主节点变成了从节点,并且是fail故障状态;7006接替了7004变成了主

哨兵状态监测到也是新的7006为主节点

这样就验证了我之前的猜想,是ServiceStack客户端不能根据故障自动识别到下一个别重新选举出的主节点
这时再手动启动被关掉的7004节点(但因为测试工具交长时间注册不上不能自动恢复注册)
这里还发现了一下现象,在手动关闭掉主节点后,ServiceStack会出现线程阻塞,进而报I/O异常,注册进行不下去;

在csredis和ServiceStack的故障对比下,总结出以下几点:
- 两个组件在手动停掉当前节点后,都没有正常的切换到下个哨兵选举出的主节点;
- csredis在手动停掉当前节点后,注册可以继续往下进行,servicestack则不能顺利进行注册;分析看来csredis在线程释放比servicestack好,servicestack会出现阻塞并出现I/O异常
- 在手动恢复停掉的节点后,而且在tcp应用程序不重启的情况下,csredis能马上恢复正常,redis读写不再报错,注册速度也起来了;而servicestack不能顺利恢复,而且还因为阻塞导致测试工具崩掉;
- 在StackExchange组件下的故障现象
再切换到StackExchange进行以上步骤进行对比
第一步:先用哨兵模式进行创建连接


第二步:确认集群节点和哨兵监控状态

第三步:在确保redis集群状态正常的情况下启动tcp进行测试用例压测
在节点都正常的情况下,哨兵模式出现以下错误,导致注册不能顺利完成;测试了多次还是这样,那就跳过这个模式直接上redis cluster集群模式

第四步:直接上redis cluster集群模式

在官方的集群模式下虽然有小部分redis读写错误;但没有出现上面的异常,可以7500个连接顺利注册完


第五步:停掉一个当前主节点试试看

从下图可以看出在当前7001节点停止后,出现了短暂的异常日志,但错误日志很快就停了,注册也接顺利注册完成,这里控制台虽然没有体现出节点的切换情况,但从日志和注册情况下分析,节点故障是能顺利转移了


接下来看看集群节点和哨兵的状态
可以看到哨兵的也成功的选举出了7006作为主节点,7006在集群中也替换了7001成为了主节点

得出结果是StackExchange 在redis cluster集群模式下的故障转移是正常的,和redis集群环境是的故障转移是匹配上了。
在csredis和StackExchange 的故障对比下(上面已经对比过servicestack,这里就不再去对比了),总结出以下几点:
1、csredis组件在手动停掉当前节点后,没有正常的切换到下个哨兵选举出的主节点;StackExchange 在哨兵模式下也是有问题,但在redis cluster集群模式下可以顺利转移故障;
2、csredis在手动停掉当前节点后,注册可以继续往下进行,但节点一直在恢复状态,redis读写错误日志也在不停的记录,而StackExchange 只出现了短暂的redis读写错误,注册也能马上恢复,顺利的注册完成;
- 在手动恢复停掉的节点后,而且在tcp应用程序不重启的情况下,csredis能马上恢复正常,redis读写不再报错,注册速度也起来了;而StackExchange 不管是在节点停掉是否恢复的状态下,都对注册过程影响不大;
最终选择的方案
经过以上几天的反复测试、验证,个人觉得选择StackExchange +redis cluster集群模式在故障转移高可用方面比较合适;至于长时间的稳定性,还要看测试组同事的任务压测才能体现。
理由:
- 在不用重做或者改变原有的redis集群环境下,可以通过很少改动就可以切换到StackExchange 组件,或者在老系统不做任何改动的情况下,新系统用StackExchange 也可以兼容;
- 从微软NET CORE官方也推荐使用StackExchange 和官方的redis cluster集群模式
- StackExchange 免费开源














 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









