









 本文介绍了基于深度学习的玉米叶部蚜虫检测系统的选题背景、设计思路,包括scSE注意力机制提升目标区域识别效率和空洞卷积空间金字塔池化捕捉多尺度特征。文章详细描述了数据集、实验环境和模型实现,通过对比实验展示了改进模型的性能优势。
本文介绍了基于深度学习的玉米叶部蚜虫检测系统的选题背景、设计思路,包括scSE注意力机制提升目标区域识别效率和空洞卷积空间金字塔池化捕捉多尺度特征。文章详细描述了数据集、实验环境和模型实现,通过对比实验展示了改进模型的性能优势。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的玉米叶部蚜虫检测系统

设计思路
一、课题背景与意义
蚜虫是一种田间常见的害虫,有两百多种子类,严重影响着农林业生产和园艺业生产,在安徽地区有较为广泛的分布。然而,在实际大规模的防治和管理中,人工识别的方法并不适用,成本高、主观性强、准确率低。近年来,深度学习网络逐渐发展了起来,图像采集技术也在不断进步,害虫检测逐渐转向深度学习。
二、算法理论原理
2.1 scSE注意力机制
由于蚜虫目标在图片中的占比很小,在图片上做卷积大部分是无效学习,其计算大多在无关的背景区域进行,这极大地降低了模型工作效率。引入scSE注意力模型。注意力模型能够通过让网络预先学习的方式提前校准特征图不同位置的权重,提高有目标的子区域的重要性。scSE由cSE和sSE两个注意力模块组合而成。cSE是一个包含各通道信息的描述符,由包含全局空间信息的特征图压缩而来,可以让网络更好地表达重要通道的特征。cSE减少无目标的子区域的重要性,让计算尽可能地集中在可疑区域。
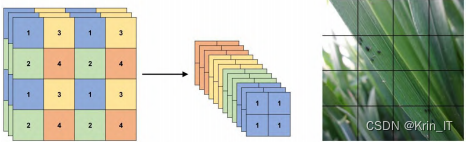
在主干网络中,每经过一层CBS+CSP模块,特征图的尺寸就减半。在下采样的过程中,边缘信息逐渐丢失。引入sSE模块,暂时忽略通道的影响,聚焦在特征图的二维边缘上。注意力机制作为一种提高计算效率的模块,其在网络结构中的位置十分重要。在不同的位置,注意力模块的优势是不同的,甚至可能会成为模型的累赘。具体表现为在不同尺寸特征图中注意力权重计算的参数量的不同。

2.2 空洞卷积空间金字塔池化
ASPP(Atrous Spatial Pyramid Pooling)是基于空洞卷积(Atrous Convolution)和空间金字塔池化(SPP)的。在常见模型的普通卷积和池化操作中,特征图分辨率不断变小,小目标的边缘细节信息容易丢失。蚜虫个体的大小差别很大,而且在部分群落中,大目标和小目标的尺寸差别可以达到5倍。
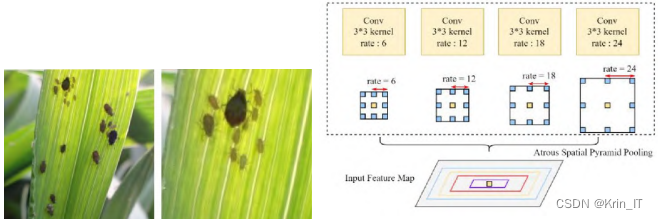
为了更好地学习不同尺寸目标的特征,引入Atrous Convolution,利用不同膨胀速率的空洞卷积核在特征图中捕捉多尺度的上下文信息。这样同时避免了对特征图过度下采样,能够在特征图保持一定尺寸时,通过在卷积核中添加零值,在同等计算代价下扩大感受野,获得更丰富的信息。
相关代码:
import tensorflow as tf
def spatial_pyramid_pooling(feature_map, levels):
pool_outputs = []
# 对每个尺度进行池化操作
for level in levels:
pool_size = tf.math.ceil(tf.shape(feature_map)[1:3] / level)
strides = tf.math.ceil(tf.shape(feature_map)[1:3] / level)
pooled = tf.keras.layers.MaxPooling2D(pool_size=pool_size, strides=strides)(feature_map)
pool_outputs.append(pooled)
# 将池化结果拼接起来
pooled_features = tf.concat(pool_outputs, axis=-1)
return pooled_features
# 示例输入特征图和SPP池化的尺度
input_feature_map = tf.random.normal((1, 32, 32, 128)) # 输入特征图的大小为32x32,通道数为128
spp_levels = [4, 2, 1] # SPP池化的尺度
# 进行SPP池化
pooled_features = spatial_pyramid_pooling(input_feature_map, spp_levels)
# 打印融合后的特征图大小
print("融合后的特征图大小:", pooled_features.shape)三、检测的实现
3.1 数据集
本实验的数据集是使用单反相机在田间实地拍摄采集的数据集。拍摄在春季三月份进行,光照相对温和。拍摄到的照片质量较高,均为1440*1080分辨率。采集的图片涵盖各类实际情况,既有光线较暗的低对比度图片,也有光线较强的高对比度图片。

实验一共在田间采集了361张图片,其中包含不同形态、颜色和大小的总共5,054个蚜虫实例,平均每张图片包含14个蚜虫目标。实验使用LabelImg软件对样本图片进行了逐一标注,在每张图片中,手动地使用矩形框将每只蚜虫标注出,作为训练和测试的Ground Truth真实类别和位置。在进行模型训练之前,实验首先将使用LabelImg产生的xml标注文件原标签转换为Yolo网络需要的txt格式,数据集按照6:2:2划分为训练集、验证集和测试集。

3.2 实验环境搭建
本实验采用Pytorch深度学习框架。CPU采用Intel Xeon E5-2690 v4,显卡使用NVIDIA GTX 3080,操作系统使用Windows 10旗舰版。将基础学习率从原来的0.005调高至0.04,其他超参数配置与原Yolov5保持一致,以达到模型最佳学习性能。
3.3 实验及结果分析
将数据集图片采用改进的Yolov5s模型进行训练和测试。同时,进行了对比实验,将本模型和流行的Yolov3、SSD、RetinaNet和Faster-RCNN算法以及原Yolov5s进行了性能对比。模型训练完成后,使用平均精确率(Average Precision)、召回率(Recall)和检测速度(Speed)作为本次实验的评价指标,进行模型性能评价。
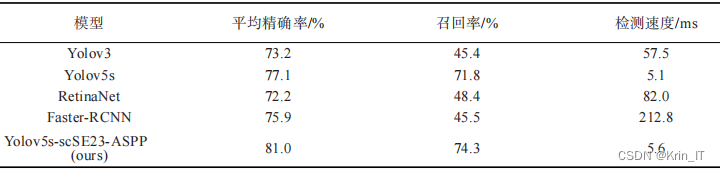
改进后的检测模型弥补了模型本身的不足,同时继承了Yolov5本身学习能力强、检测速度快的优点。不仅可以检测稀疏分布的蚜虫,也可以检测稠密分布的虫群,还可以同时检测到不同大小的虫子。在虫群和稀疏虫子同时存在的图像中,检测效果也非常良好。

相关代码如下:
model = tf.keras.models.load_model('corn_aphid_detection_model.h5')
# 加载类别标签
with open('class_labels.txt', 'r') as f:
class_labels = f.read().splitlines()
# 加载图像
image = cv2.imread('corn_image.jpg')
# 图像预处理
resized_image = cv2.resize(image, (416, 416))
input_image = resized_image / 255.0
input_image = np.expand_dims(input_image, axis=0)
# 进行预测
predictions = model.predict(input_image)
# 解析预测结果
class_ids = np.argmax(predictions[0][:, 5:], axis=-1)
confidences = np.max(predictions[0][:, 5:], axis=-1)
# 设置置信度阈值
confidence_threshold = 0.5
实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









