







 本文介绍了一种利用深度学习技术开发的答题卡自动识别评分系统,详细描述了项目背景、设计思路,包括图像预处理、区域分割、边缘检测等步骤,以及如何创建自定义数据集和使用数据增强技术。开发环境主要包括Python、OpenCV等工具。
本文介绍了一种利用深度学习技术开发的答题卡自动识别评分系统,详细描述了项目背景、设计思路,包括图像预处理、区域分割、边缘检测等步骤,以及如何创建自定义数据集和使用数据增强技术。开发环境主要包括Python、OpenCV等工具。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的答题卡自动识别评分系统
项目背景
传统的答题卡评分方式通常需要人工进行,这不仅费时费力,而且容易出现人为误差。而深度学习技术在图像处理和模式识别方面取得了显著的进展,能够高效准确地处理大量的答题卡数据。能够在短时间内处理大量答题卡,大大提高了评卷的效率。相比传统的人工评卷,自动评分系统可以大幅缩短评卷周期。在提高评分效率、减少评分错误、降低评卷成本和提供数据分析等方面具有重要的意义和应用价值。
设计思路
自动评分方法的流程包括以下几个步骤:首先,使用相机或扫描仪采集答题卡的原始图像。然后对图像进行预处理操作,包括均值滤波、灰度变换、自适应二值化、开运算形态学处理和二值化图像反转等,以去除噪声并提取答题区域。接下来,对预处理后的图像进行双重Hough直线检测和区域分割,以获取信息区域和答题区域图像。然后对信息区域和答题区域图像分别进行高斯滤波处理,并通过Canny算子进行边缘检测。对于答题区域的最大轮廓ROI区域,进行开运算形态学处理以进一步减少噪声。接下来,通过非零像素点检测,提取学号和各题选项的答案,并将其保存在二维数组中。最后,根据参考答案对学生的答案进行比对,完成评分。
均值滤波是一种平滑图像的操作,它的作用是去除图像中的高频噪声。噪声通常表现为图像中的突然亮度或颜色变化,对后续的图像处理和分析步骤可能产生干扰。均值滤波通过计算像素周围邻域的平均值,将每个像素的值替换为其邻域的平均值,从而减少噪声的影响。这样可以使图像变得更加平滑,并去除一些小尺寸的噪声细节。
灰度变换是将彩色图像转换为灰度图像的过程,它的作用是简化图像的信息并减少计算量。在答题卡自动识别中,通常只需要关注答题区域的填涂情况,而不需要考虑颜色信息。通过将彩色图像转换为灰度图像,可以去除颜色对后续处理步骤的干扰,简化图像的处理和分析。灰度变换将每个像素的彩色值转换为一个灰度值,通常使用加权平均法或简单平均法进行转换,得到一个单通道的灰度图像,其中灰度值表示像素的亮度。
Hough直线检测与区域分割是答题卡自动评分系统中的重要步骤。通过Hough直线检测,可以矫正答题卡的方向,并计算出最长的直线,以便对答题卡进行区域分割。区域分割的目的是将答题卡分成信息区域和答题区域两个部分,以便更精确地定位答题卡中的有效信息,例如准考证号区域和答题区域。
区域分割后,对分割得到的信息区域和答题区域图像进行高斯滤波处理,以平滑图像并减少噪声的影响。然后使用Canny算子进行边缘检测,得到图像中的边缘信息。对于边缘检测得到的最大轮廓ROI区域,进行开运算形态学处理,以进一步减少噪声,并获得更清晰的轮廓。
通过非零像素点检测,可以判断学生的填涂信息。非零像素点指的是在ROI区域中像素值非0的点,表示学生填涂了该选项。通过计算填涂位置的像素点值,可以形成一个非零像素点的二维数组。根据该数组,可以提取学号和各题选项的答案。
最后,根据参考答案进行评分。通过比对学生的填涂结果与参考答案,可以确定每道题的得分情况。非零像素点二维数组中的每个一维数组代表一道题的四个选项(A、B、C、D),非零值像素点表示学生填涂了该选项。根据填涂的选项与参考答案进行比对,可以确定学生的得分。
相关代码示例:
import numpy as np
reference_answers = ['A', 'B', 'C', 'D']
non_zero_pixels = np.array([[0, 0, 255, 0], [0, 255, 0, 0], [0, 0, 0, 255]])
student_id = ''
for pixel_value in non_zero_pixels[0]:
if pixel_value != 0:
student_id += reference_answers[pixel_value]
answers = []
for row in non_zero_pixels[1:]:
answer = ''
for pixel_value in row:
if pixel_value != 0:
answer += reference_answers[pixel_value]
answers.append(answer)
score = 0
for i, student_answer in enumerate(answers):
if student_answer == reference_answers[i]:
score += 1数据集
由于网络上没有现有的合适的数据集,我决定自己去收集答题卡图像并制作一个全新的数据集。我在不同的考试场景中拍摄了大量答题卡图像,涵盖了各种填涂情况和不同的答题模式。通过现场拍摄,我能够捕捉到真实的场景和多样的填涂情况,这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为答题卡自动识别评分系统的研究提供有力的支持,并为该领域的发展做出积极贡献。
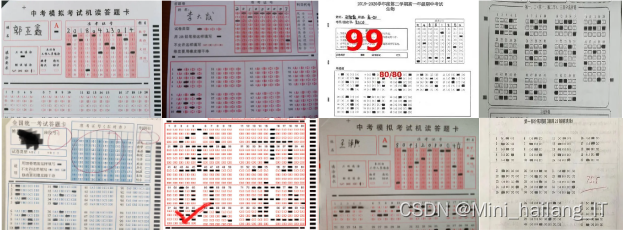
为了扩充数据集的多样性和泛化能力,我使用数据增强技术对收集到的答题卡图像进行处理。我采用了旋转、缩放、平移、模糊等操作,并添加了不同的噪声和变换,以增加数据集的样本多样性。通过数据扩充,我能够训练出更鲁棒的模型,提高系统对于不同答题卡的识别和评分准确性,进一步提升系统的实用性和可靠性。

相关代码示例:
def data_augmentation(image):
# 随机旋转图像
angle = random.uniform(-10, 10)
height, width = image.shape[:2]
rotation_matrix = cv2.getRotationMatrix2D((width/2, height/2), angle, 1)
rotated_image = cv2.warpAffine(image, rotation_matrix, (width, height))
# 随机缩放图像
scale_factor = random.uniform(0.8, 1.2)
scaled_image = cv2.resize(rotated_image, None, fx=scale_factor, fy=scale_factor)
# 随机平移图像
tx = random.randint(-20, 20)
ty = random.randint(-20, 20)
translation_matrix = np.float32([[1, 0, tx], [0, 1, ty]])
translated_image = cv2.warpAffine(scaled_image, translation_matrix, (width, height))
# 随机模糊图像
blur_type = random.choice(['gaussian', 'median'])
if blur_type == 'gaussian':
blurred_image = cv2.GaussianBlur(translated_image, (5, 5), 0)
else:
blurred_image = cv2.medianBlur(translated_image, 5)
# 随机添加噪声
noise_type = random.choice(['salt', 'pepper', 'gaussian'])
if noise_type == 'salt':
noise_image = add_salt_noise(blurred_image)
elif noise_type == 'pepper':
noise_image = add_pepper_noise(blurred_image)
else:
noise_image = add_gaussian_noise(blurred_image)
return noise_image实验环境
操作系统为Windows 10。配置包括Intel Core i7,主频为2.3GHz,16GB内存。开发过程中主要采用的编程语言是Python ,开发工具包括PyCharm 、OpenCV 、PyQt和MySQL 。
在软件工程的思想指导下,利用Python、PyQt5、OpenCV和PyCharm等工具和库,设计并实现了界面友好、功能灵活的答题卡自动评分系统。系统通过图形界面提供用户友好的操作界面,同时具备灵活的功能,能够处理各种类型的答题卡。
海浪学长项目示例:



















 3468
3468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









