







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的木马流量检测系统
项目背景
随着互联网的迅猛发展,网络安全问题日益突出,其中木马病毒是一种常见的网络攻击手段。木马流量检测对于维护网络安全具有重要意义。传统的木马流量检测方法主要基于特征匹配和统计分析,但这种方法存在误报率高、适应性差等问题。近年来,深度学习在计算机视觉和自然语言处理等领域取得了显著进展,为木马流量检测提供了新的解决思路。基于深度学习的木马流量检测系统可以自动学习和提取木马流量的特征,实现更准确的检测和分类,对于提高网络安全防护能力具有重要意义。
设计思路
算法理论技术
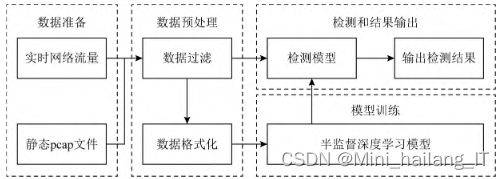
木马流量检测系统主要包括数据准备、数据预处理、模型训练以及检测和结果输出四个功能模块。系统接收实时网络流量或静态pcap文件作为输入数据。数据预处理模块对输入数据进行详细处理。训练数据经过数据过滤和格式化,用于模型训练。待测数据经过数据过滤后,输入模型进行检测,并输出结果。木马流量检测系统通过数据准备、预处理、模型训练和检测输出等功能模块实现对木马流量的检测。
半监督深度学习方法利用有标记数据训练网络,并通过隐藏层提取特征。然后使用这些特征训练分类算法对未标记数据进行分类,将分类结果作为未标记样本的伪标签。通过多次训练,网络对未标记样本的预测逐渐准确,从而提高模型性能。半监督深度学习模型中,无标记样本无法直接使用交叉熵作为损失函数,同时噪声正则化也会对半监督学习性能产生影响。
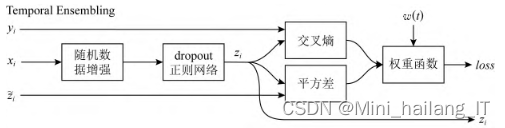
为了解决这个问题,改进后的模型采用自集成思想,利用随机数据增强和dropout正则化网络输出预测值并计算交叉熵。对于未标记样本,计算当前预测值与之前epoch的预测值之间的平方差,构成模型的损失函数。该模型通过指数滑动平均(EMA)计算之前epoch的模型输出,实现集成思想。
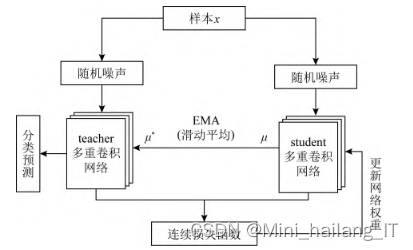
MeanTeacher模型是一种半监督深度学习方法,通过教师-学生模型的交互学习,使用教师模型的预测作为学生模型的目标,从而提高模型性能。教师模型的参数通过指数滑动平均得到,解决了无标签数据信息更新慢的问题。模型使用均方误差和交叉熵损失函数来优化学生模型,同时利用高斯分布初始化权重参数。MeanTeacher模型在半监督学习中具有较好的性能表现。
基于虚拟对抗的MeanTeacher模型在木马流量检测中应用了对抗训练方法。通过引入对抗样本和使用对抗噪声来训练模型,该方法能够提高模型的鲁棒性和抵抗对抗攻击的能力。使用虚拟对抗训练方法可以同时处理有标记和无标记样本,通过寻找使预测结果偏离正确标签或虚拟标签的方向来计算扰动。这种方法有效解决了半监督学习中随机噪声增强方式对模型性能的不利影响,提高了木马流量检测的准确性和鲁棒性。
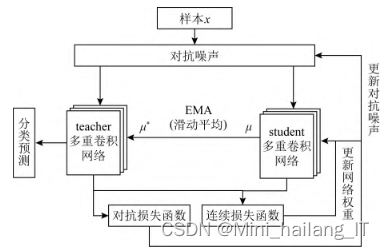
虚拟对抗MeanTeacher模型,将虚拟对抗训练与MeanTeacher模型相结合,以提升模型的泛化能力。对抗噪声可以帮助抵御对抗样本攻击,并通过添加扰动来更好地拟合对抗样本,从而比随机噪声具有更好的正则化效果,提高模型的泛化性能。在虚拟对抗MeanTeacher模型的训练过程中,同时进行对抗噪声的训练和MeanTeacher网络的训练。模型在每个训练步骤中通过梯度下降使连续损失函数和对抗损失函数都最小化。虚拟对抗MeanTeacher模型相对于传统的MeanTeacher模型有三个变化:输入样本中添加对抗噪声,增加对抗损失函数,并且网络权重的更新同时依赖于连续损失函数和对抗损失函数。
数据集
公开可用的木马流量数据集较为有限,且往往不能完全满足我们的研究要求。因此,我们决定自制一个更贴近实际网络环境、更具多样性的木马流量数据集。首先,我们收集了各种类型的木马流量样本,这些样本来源于不同的攻击场景和木马变种。为了丰富数据集的多样性,我们还模拟了多种网络环境和攻击场景,生成了多种不同特征的木马流量样本。接下来,我们对这些样本进行了预处理和标注工作,将木马流量样本分为不同的类别,并提取了相应的特征。
模型训练
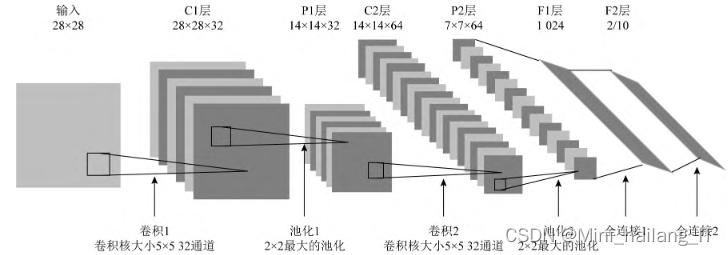
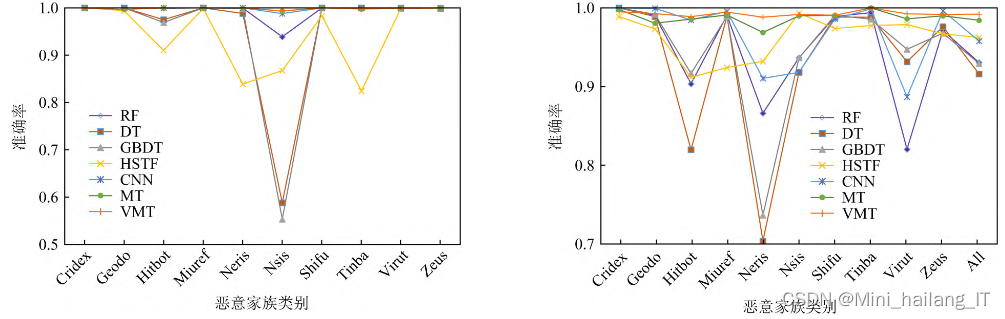
实验使用了四个评价指标来评估实验结果,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1-Score)。准确率表示分类器正确分类的样本所占的百分比,反映分类器对各类样本的正确识别情况;精确率表示被标记为正类的样本实际为正类的百分比;召回率表示正样本(木马样本)被正确标记为正的百分比。TP表示正确分类的正类样本数,TN表示正确分类的其他类样本数,FP表示错误分类的正类样本数,FN表示错误分类的其他类样本数。F1-Score是综合考虑精确率和召回率的指标,用于衡量分类器的综合性能。这些评价指标用于对实验结果进行综合评估。
相关代码示例:
import tensorflow as tf
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam', loss=tf.keras.losses.BinaryCrossentropy(), metrics=['accuracy'])
# 加载有标签数据
X_labeled, y_labeled = load_labeled_data()
# 加载无标签数据
X_unlabeled = load_unlabeled_data()
# 在有标签数据上训练模型
model.fit(X_labeled, y_labeled, epochs=10)
# 使用训练好的模型进行预测
y_pred = model.predict(X_unlabeled)
# 根据预测结果判断是否为木马流量
malware_traffic = np.where(y_pred > 0.5)[0]
# 打印检测到的木马流量的索引
print("Detected Malware Traffic Indexes:", malware_traffic)海浪学长项目示例:
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









