






目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于机器学习的异常URL检测系统
项目背景
随着互联网的快速发展,恶意软件和网络欺诈行为也日益猖獗,给用户的信息安全和网络环境带来了巨大威胁。异常URL是恶意软件和网络欺诈活动的常见手段之一。异常URL检测系统通过分析URL的特征和行为,利用机器学习算法来识别和预测恶意URL,帮助用户避免点击和访问潜在的风险网址,从而提高网络安全性和用户的信息保护能力。
设计思路
算法理论技术
基于近邻的协同过滤算法
协同过滤算法是推荐系统中最重要的思想之一。基于近邻的协同过滤算法是目前最广泛应用的方法之一,它通过寻找与目标用户或物品兴趣相似的其他用户或物品,来进行推荐。其中,基于用户的协同过滤算法通过找到与目标用户兴趣相似的其他用户,利用他们的评价或行为数据预测目标用户对未评价或未购买的物品的兴趣程度,并进行推荐。基于用户的协同过滤算法需要依赖用户的历史行为数据。通过比对不同用户的消费记录,找到具有相似消费行为的用户,可以推断它们具有较高的相似性。然后,根据这种相似性,将一个用户未购买但相似用户购买过的物品推荐给该用户。
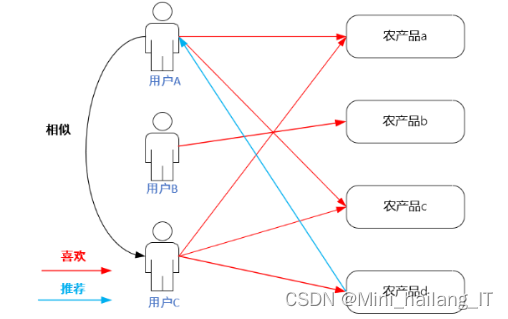
基于物品的协同过滤算法在思想上与基于用户的协同过滤算法相似,但其重点在于计算物品之间的相似度。这种算法可以解决物品冷启动问题,特别适用于推广销量较低或曝光较少的农产品。由于农产品通常具有相对稳定的属性和特征,物品的相似性更容易捕捉。基于物品的协同过滤算法能够提供多样化的推荐结果,让用户接触到更广泛的农产品品种并提供更多选择。
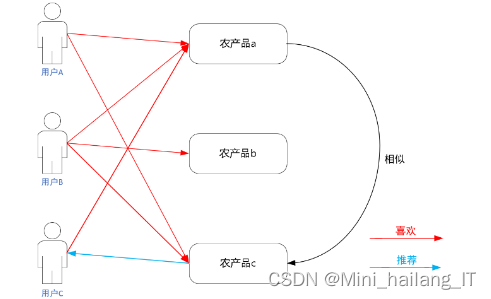
基于模型的协同过滤算法
基于模型的协同过滤算法通过构建和学习推荐模型来进行推荐。与基于近邻的协同过滤算法不同,基于模型的方法不直接依赖于用户或物品之间的相似性,而是通过对用户行为和物品特征进行建模,利用机器学习、深度学习等技术来预测用户对物品的喜好。这种方法可以从大量的用户和物品数据中学习用户的喜好信息,并将这些信息作为生成个性化推荐的依据。
基于模型的协同过滤算法可以利用不同的技术,如联规则算法和聚类算法,来分析用户的评分记录和建立用户和物品之间的关系模型。此外,它也可以应用于社交网络中的推荐,通过利用用户的关系数据,如好友关系,来生成用户的推荐内容,从而帮助用户扩大社交圈。
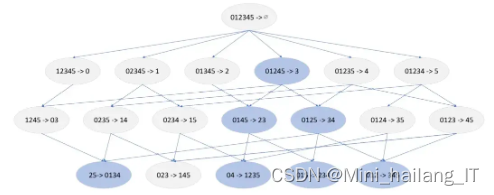
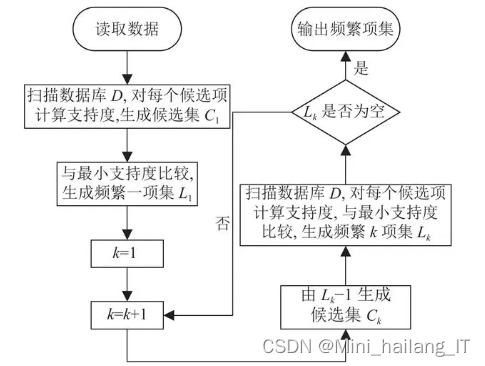
改进后的算法是一种混合推荐算法,通过融合Apriori算法和Item-CF算法的特点,解决协同过滤算法中的数据稀疏性问题。该算法首先利用Apriori算法挖掘频繁项集,补充用户行为信息,然后使用Item-CF算法计算物品相似度,填充用户-物品评分矩阵,以提升推荐效果。通过这种融合的方式,APICF算法能够更好地适应用户的实际需求,并缓解由于数据稀疏性导致的推荐预测问题。
数据集
由于网络上缺乏现有的适用于异常URL检测系统的数据集,本研究决定通过网络爬取的方式收集数据并制作一个全新的数据集。通过开发网络爬虫,我们从不同来源的网页和在线资源中收集了大量的URL样本。这些样本包括正常的合法URL和恶意的异常URL,并涵盖了各种恶意行为和网络攻击的类型。通过网络爬取的方式,我们能够获得真实、多样的异常URL数据,提供可靠的数据基础。
为了增加数据的多样性和覆盖度,本研究对自制的异常URL数据集进行了数据扩充。通过应用数据增强技术和生成模型,我们对原始数据进行了扩充和增强。通过数据合成、特征变换和噪声添加等技术对原始样本进行了增强,生成更多样、更具代表性的异常URL样本。
实验环境
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试算法系统。
模型训练
在本次实验中,为了评估推荐算法的效果,主要使用准确率、召回率和F1值这三个指标。这些指标是在TopN推荐任务中常用的评估指标。准确率衡量了推荐列表中与用户实际喜好相符的比例,召回率评估了算法能够找到多少用户喜欢的物品,而F1值综合考虑了准确率和召回率的平衡性。通过对这三个指标的分析,可以更全面地了解算法的性能和推荐效果。

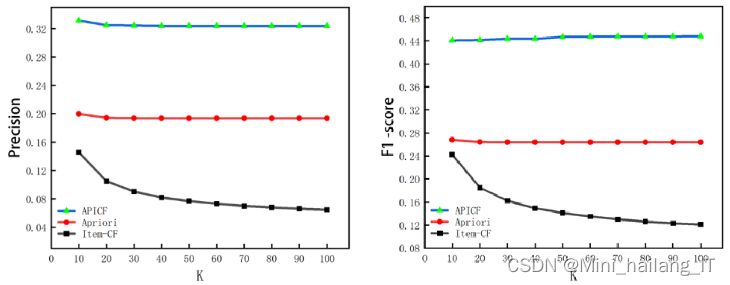
实验通过改变最近邻个数(K)来比较Item-CF算法、Apriori算法和混合推荐算法(APICF)在推荐效果上的差异。初始时,最近邻个数K为10,并每次递增10,直到测试到K值为100为止,得到了10个评测指标数据。通过对比这三种算法的推荐效果,可以得出结论。这样的实验设计可以提供关于不同K值下算法性能的详细比较,帮助评估算法在不同情况下的推荐准确率、召回率和F1值等指标。
相关代码示例:
# 定义函数:计算推荐算法的准确率、召回率和F1值
def evaluate_algorithm(predictions, targets):
# 计算准确率
precision = len(predictions.intersection(targets)) / len(predictions)
# 计算召回率
recall = len(predictions.intersection(targets)) / len(targets)
# 计算F1值
f1_score = 2 * precision * recall / (precision + recall)
return precision, recall, f1_score
# 初始化参数
K = 10 # 初始最近邻个数
increment = 10 # 每次递增的最近邻个数
max_K = 100 # 最大最近邻个数
while K <= max_K:
precision_itemcf, recall_itemcf, f1_itemcf = evaluate_algorithm(itemcf_predictions, targets)
precision_apriori, recall_apriori, f1_apriori = evaluate_algorithm(apriori_predictions, targets)
precision_apicf, recall_apicf, f1_apicf = evaluate_algorithm(apicf_predictions, targets)
# 输出评测指标结果
print("K =", K)
print("Item-CF: Precision =", precision_itemcf, "Recall =", recall_itemcf, "F1 =", f1_itemcf)
print("Apriori: Precision =", precision_apriori, "Recall =", recall_apriori, "F1 =", f1_apriori)
print("APICF: Precision =", precision_apicf, "Recall =", recall_apicf, "F1 =", f1_apicf)
print()
# 更新最近邻个数K
K += increment海浪学长项目示例:
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









