






目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
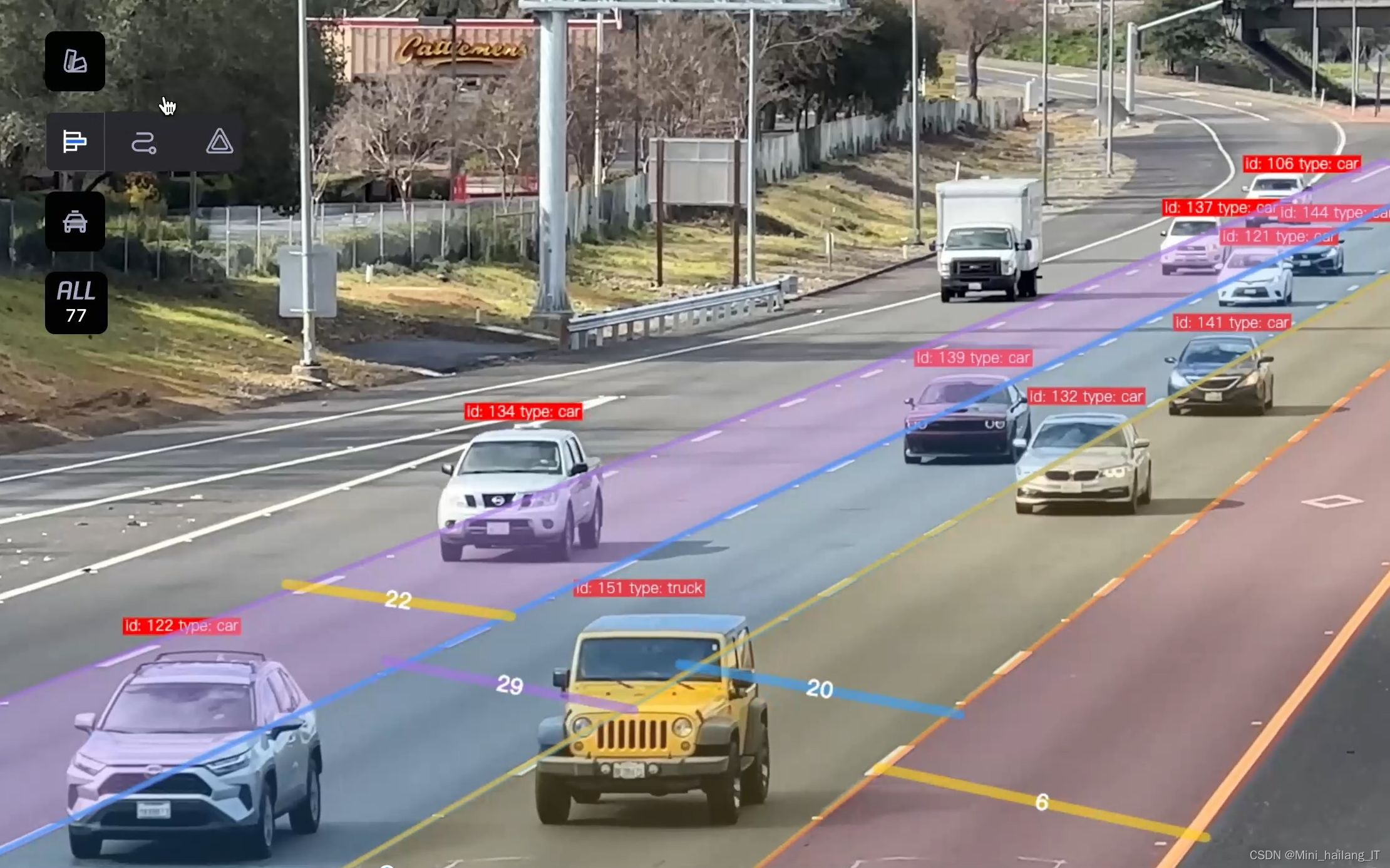
🎯基于深度学习的乒乓球实时检测与追踪系统
项目背景
随着乒乓球运动的普及和竞技水平的提高,如何准确的识别和分析乒乓球的运动轨迹和状态,成为了运动科学和智能体育研究的重要课题。传统的乒乓球检测方法多依赖于人工观察,效率低且容易受到环境因素的影响。利用深度学习和计算机视觉技术,可以实现对乒乓球的自动检测、追踪和分析,极大地提高了检测的精准度和实时性。这不仅为教练和运动员提供了更科学的训练指导,也为智能体育应用的发展提供了新的研究方向,推动了运动科学与人工智能的深度融合。
数据集
图像采集择了自主拍摄与互联网采集相结合的方式,以确保数据的多样性和丰富性。在自主拍摄阶段,利用高清摄像设备在不同光照和背景条件下拍摄乒乓球运动的图像,特别是在乒乓球比赛和训练场景中,捕捉不同角度和速度的乒乓球运动。为增加数据的多样性,还从视频平台和相关网站获取乒乓球比赛视频,通过提取视频中的帧图像以补充数据集。

数据标注是数据集制作中不可或缺的一环。使用Labeling工具对采集到的图像进行标注,标注过程中为每个图像中的乒乓球绘制边界框,并为其分配相应的标签。通过精确的标注,确保模型能够有效地识别和追踪乒乓球的位置与运动轨迹。标注工作完成后,我们对标注结果进行了审核,以确保数据的准确性和一致性,为后续模型训练提供高质量的数据支持。

数据集的划分与数据扩展是提升模型泛化能力的重要步骤。我们将数据集划分为训练集、验证集和测试集,一般采用70%用于训练,20%用于验证,10%用于测试。此外,通过数据增强技术(如旋转、翻转、缩放、颜色变换等),增加训练数据的数量和多样性,从而提高模型的鲁棒性。这一过程不仅丰富了数据集,还帮助模型更好地适应不同的实际应用场景,确保乒乓球实时检测与追踪系统在复杂环境中的有效性。
设计思路
卷积神经网络(CNN)是核心组成部分之一。CNN通过模拟生物视觉系统的工作原理,利用卷积层、池化层和全连接层等结构,提取输入图像中的特征。卷积层通过滑动卷积核对输入图像进行特征提取,能够捕捉图像中的局部特征,如边缘、纹理等。池化层则用于降低特征图的维度,减少计算量和防止过拟合。同时,CNN的多层结构使得模型能够逐层学习更高层次的抽象特征,从而有效提高图像分类和检测的精度。在乒乓球实时检测与追踪中,CNN能够快速而准确地识别乒乓球的位置,为后续的追踪算法提供可靠的信息基础。
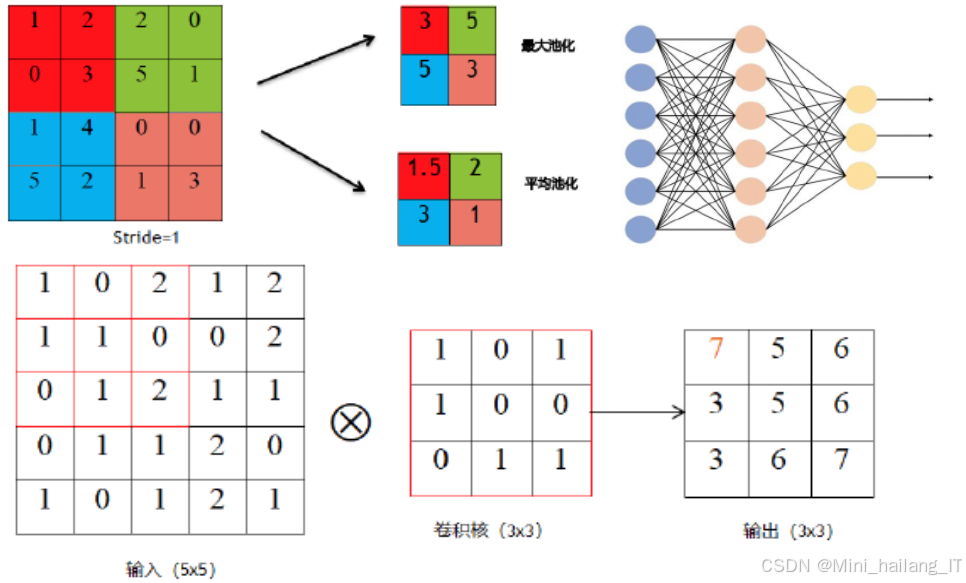
YOLOv5算法是另一关键技术,它采用单阶段目标检测的方法,能够在一次前向传播中实现目标的定位和分类。YOLOv5通过将输入图像划分为多个网格,并预测每个网格中可能存在的目标及其边界框,实现高速的目标检测。该算法结合了多尺度特征提取和自适应锚框机制,使得模型能够有效识别不同大小的目标,适应乒乓球在快速运动状态下的变化。此外,YOLOv5的轻量级设计和高效的推理速度,使其非常适合实时应用场景。这种高效的检测能力为乒乓球的快速识别和追踪打下了坚实的基础,是系统实时性能的保障。
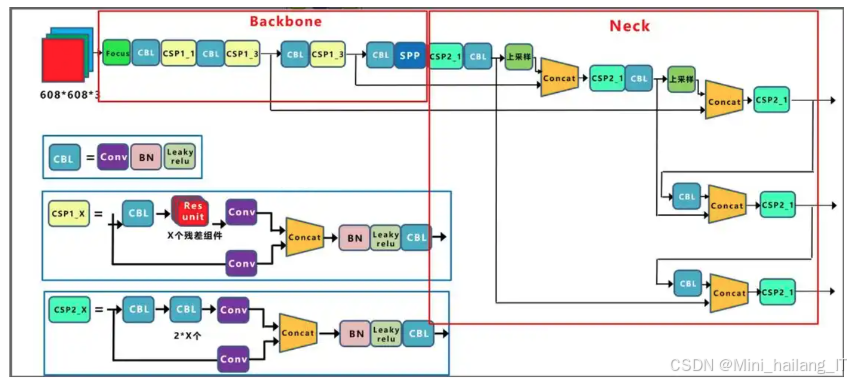
注意力机制在乒乓球实时检测与追踪系统中进一步提升了模型的性能。通过计算特征图中各部分的重要性,注意力机制能够自适应地调整特征权重,从而增强模型对关键信息的关注。具体来说,采用的注意力机制ECA可以在特征图上施加权重,使得模型更专注于乒乓球的特征信息,弱化背景噪声的影响。这种机制不仅提高了乒乓球的检测精度,也增强了模型对复杂场景的适应能力。在实时检测和追踪任务中,注意力机制的引入使得系统能够在动态变化的环境中保持高效的性能,确保乒乓球的准确识别和有效追踪。
模型训练之前,首先需要准备和预处理数据集。数据集应包含丰富的乒乓球图像,涵盖不同的环境、光照和角度。经过标注后的数据集将被分为训练集、验证集和测试集。数据预处理步骤包括图像缩放、去噪声和数据增强,以提高模型的训练效果和泛化能力。
from torchvision import transforms
# 数据预处理和增强
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.ToTensor()
])
# 应用预处理
train_dataset = CustomDataset(transform=transform)选择YOLOv5作为目标检测的基础架构,利用卷积神经网络提取特征,并在此基础上引入注意力机制来增强模型对乒乓球的识别能力。训练过程中需要使用合适的损失函数(如GIOU损失函数)和优化器(如Adam或SGD),并通过验证集监控模型的性能,防止过拟合。训练完成后,使用测试集对模型进行评估。此阶段的关键指标包括Precision(精确率)、Recall(召回率)、平均精确度均值(mAP)等。Precision衡量模型预测的准确性,即正确预测的乒乓球数量占所有预测数量的比例;Recall衡量模型对实际乒乓球的识别能力,即正确预测的乒乓球数量占所有实际乒乓球数量的比例;mAP则是多个IoU阈值下平均精确度的综合评估。
from sklearn.metrics import precision_score, recall_score, average_precision_score
def evaluate_model(model, test_loader):
all_preds = []
all_labels = []
model.eval()
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
preds = torch.argmax(outputs, dim=1)
all_preds.extend(preds.numpy())
all_labels.extend(labels.numpy())
precision = precision_score(all_labels, all_preds, average='macro')
recall = recall_score(all_labels, all_preds, average='macro')
mAP = average_precision_score(all_labels, all_preds)
return precision, recall, mAP
precision, recall, mAP = evaluate_model(yolo_model, test_loader)
print(f'Precision: {precision}, Recall: {recall}, mAP: {mAP}')为了更直观地展示模型的性能,可以绘制Precision-Recall(P-R)曲线。P-R曲线能够帮助我们理解模型在不同阈值下的表现,展示模型的精确率和召回率之间的权衡。通过计算不同阈值下的精确率和召回率,并将其绘制成曲线,我们可以直观地评估模型的综合性能。
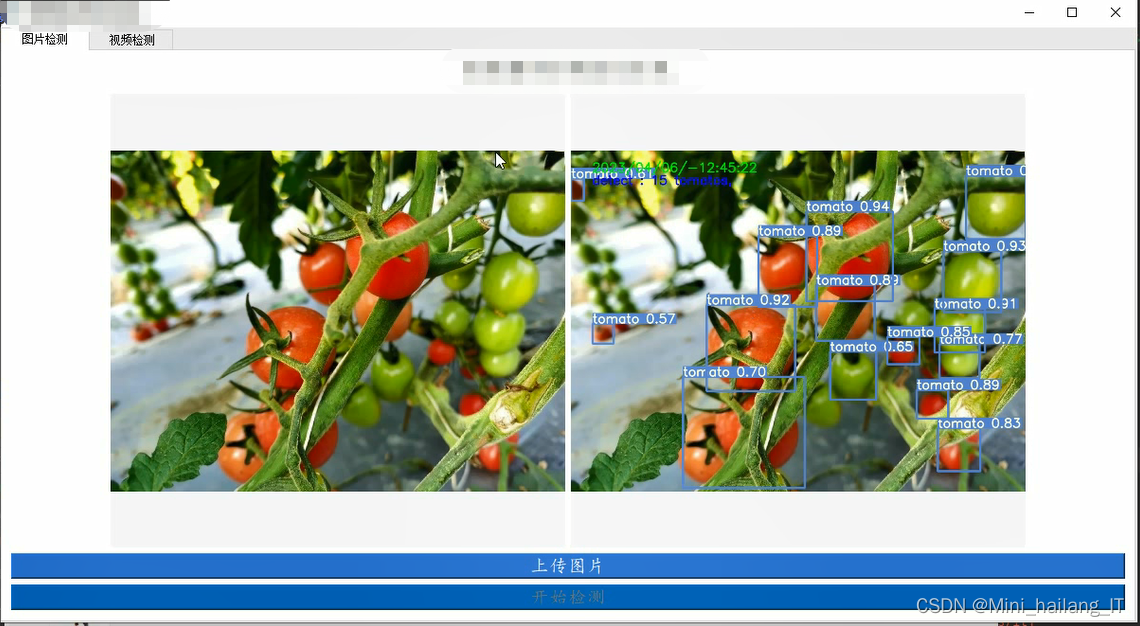
海浪学长项目示例:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









