







引用:引用可以看作是对已定义变量的别名,变量名实际上是对一段连续存储空间的别名。
关于引用几点比较重要的内容:
(1)定义引用时必须进行初始化。
(2)初始化的值要能取地址,不能用一个立即数进行初始化。
int &p = 100;//这是错误的(3)引用不能改变,一旦初始化,不能引用其他变量名。
(4)访问引用变量,永远访问的是被引用变量的内存。
引用的这几点重要的内容,可以反应出引用相对于指针来讲,更加安全。她不会引用一个未初始化的内存块,建议在C++中更多使用引用。
提出一个问题,引用究竟有没有进行内存的开辟?许多书籍上写出引用没有开辟空间,到底对不对呢,还是理解的方向不正确?
下面通过一段代码分析
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int &b = a;
int *p = &a;
b = 20;
cout <<"a = "<<a<<",b = "<<b<<",*p = "<<*p<<endl;
*p = 30;
cout <<"a = "<<a<<",b = "<<b<<",*p = "<<*p<<endl;
return 0;
}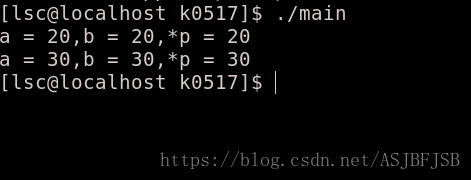
由上图看出,修改引用和修改指针都达到修改a内存块值的目的。也就是说 a b *p似乎是一块内存。
试着输出一下int a = 10;int &b = a;int *p = &a;中a和b的地址,以及p的值。
#include<iostream>
using namespace std;
int main()
{
int a = 10;
int &b = a;
int *p = &a;
cout << hex << "&a = " << &a << ",&b = " << &b << ",p = " << p << endl;
return 0;
}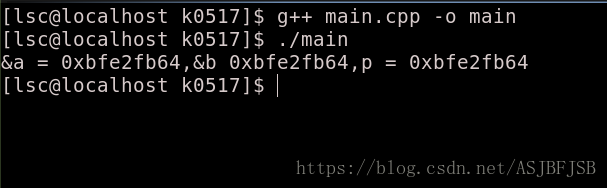
在输出结果中,似乎变量a的地址、引用的地址相同。似乎验证了刚才提到的问题,引用没有开辟独立的内存块。实际则不然,下面看上述代码的反汇编:
1. int a = 10;
2. mov dword ptr [ebp-4],0Ah
3. int &b = a;
4. lea eax,[ebp-4]
5. mov dword ptr [ebp-8],eax
6. int *p = &a;
7. lea ecx,[ebp-4]
8. mov dword ptr [ebp-0Ch],ecx对比上边3,4,5和6,7,8汇编代码,我们发现在底层语言中,压根就没有引用和指针的区别。
在函数栈帧的开辟中,用栈底指针ebp的偏移量表示局部变量的地址。[ebp-4]对应的内存块就是a。
int &b = a;
lea eax,[ebp-4]//就是将内存块a的地址保存在eax寄存器中
//lea指令是移地址指令,对比下边int *p = &a的汇编指令是一摸一样.
dword ptr [ebp-8],eax//[ebp-8]即是引用b的内存块
//所以说引用是开辟了内存块的,用来保存被引用变量的地址。
int *p = &a;
lea ecx,[ebp-4]//就是将内存块a的地址保存在eax寄存器中
//lea指令是移地址指令
mov dword ptr [ebp-0Ch],ecx通过上边的反汇编,我们可以得到的一条结论是:引用实际上开辟了内存用于保存被引用变量的地址。
但是,为什么我们输出引用变量b的地址,却是内存块a的地址呢?
实际上,只要一旦使用,在编译器内部就会自动进行解应用。也就是说永远不可能访问到引用变量b的地址,因为每当你使用引用时,已经经过解引用。
初学者如何方便的定义引用变量呢?
通过上边的分析,引用底层也是一个指针。只是在使用时,就进行了解引用,对程序员来讲这个过程是透明的。
int a=10;
int *p = &a;//首先定义一个指针
//将右边的取地址符&覆盖左边的*符号,即可得到引用变量的定义
int &p = a;定义引用变量引用数组名
//按照上边的规则
int arr[10] = {0};
//首先定义一个指向数组的指针
int (*p)[10] = &arr;
//将右边的取地址符&覆盖左边的*符号,即可得到引用变量的定义
int (&p)[10] = arr;#include<iostream>
using namespace std;
int main(){
int arr[10] = {0};
int (*p)[10] = &arr;
int (&q)[10] = arr;
cout<<sizeof(arr)<<" "
<<sizeof(p)<<" "
<<sizeof(q)<<endl;
return 0;
}
64bit编译器下,指针变量的大小为8个字节。
引用变量作为函数参数
当数组名作为函数参数时会退化为指针,因此实际应用中往往还需要传递数组的长度。
void fun(int arr[]){
printf("sizeof(arr)=%d\n",sizeof(arr));
}
int main(){
int arr[10]={0};
printf("sizeof(arr)=%d\n",sizeof(arr));
fun(arr);
}注:64bit编译器指针变量的大小为8个字节。

引用作为函数参数
void fun(int (&p)[10]){
cout<<"sizeof(p)="<<sizeof(p)<<endl;
}
int main(){
int arr[10]={0};
int (&p)[10] = arr;
cout<<"sizeof(arr)="<<sizeof(arr)<<endl;
fun(p);
return 0;
}
可见当引用变量引用数组名时,作为函数参数不会退化为指针。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









