






NVIDIA AI-AGENT夏季训练营
项目名称:AI-AGENT夏季训练营 — RAG智能对话机器人
报告日期:2024年8月18日
项目负责人:Lcs
项目概述:
这个项目是利用多模态生成一个能够通过大模型进行直接构建的机器人模型,我们知道,现在具身智能和机器人越来越受到大家的重视,人工智能赋能机器人越来越成为人们的共识。现在许多需要执行操作的机器人(例如无人机,工业机器人)多是采用已经编制好的程序进行操作。当然,现在约有越来越多的人开始尝试用人工智能去控制执行操作的机器人,例如机器狗的端到端行为生成。基于此,我想到我们可以借助大模型去更好的,更简单的实现机器人的设计和开发,于是这个利用大模型RAG来进行操作的机器人就出现了!我的想法很简单,就是通过直接写入一些机器人的控制参数的信息,直接实现一个通过文字输入就可以直接输出操作的机器人。当然我这里只是做了一个简单的实验,验证了这个想法的可行性,后续还有许多需要进行完善的地方。对于多模态,为了展现其客制化数据处理的能力,我做了如下操作,就是我将我的机器人赋予了一些特殊的“性格”,例如:喜欢卡车和易拉罐,不喜欢吃橘子等。通过给他赋予不同的性格我想向大家表明的是我们可以通过这样来生成我们自己定制化的数字人,或者说接下来如果这个机器人可以行动,那么我们就可以我们的行为与图片(视觉),语言(文字)链接起来,让机器人能够快速的完成我们想要做的事。能够快速的定制机器人,并且了解到一些模型是可以直接部署在Jetson系列的开发板上,这就代表如果RAG可以再一步发展的话,我们可以做端侧的特殊机器人。(比如可以分化出护理机器人,做饭机器人等)
技术方案与实施步骤
模型选择:
RAG模型有一个得天独厚的优势就是我们可以将我们的数据进行定制化,或者说就像一个地方的人们会有自己才知道的小吃一样。RAG赋予了模型“定制化”特征,一般而言,我们的大模型是通用的。然而事实上我们可能在很多应用场景中,特别是有关机器人操作实践的场景中,我们希望它能够“专用”。所以RAG我认为正是针对于让通用模型领会方言而产生的。甚至可以说就是在构建自己的专属的知识库,这种高度的“专用”可以使得模型更能知道我们要做什么,而减少模型产生“大模型幻觉”(一本正经的胡说八道)的可能性。我这里做了两套程序,一套是仅采用输入的文字,对机器人进行操作的,这个就有点像我们还没睁开眼的小婴儿,你给他一些刺激,他给你一些反馈。另一套是采用多模态方案,加入视觉的图像信息给机器人大致认知世界的能力。RAG都展现了它“专用”的优势,于是是事情就变得好玩起来,我甚至会畅想,通过我们一步步的教学,会不会真的达到像之前大家所畅想的那样,我们只需要教学机器人一个月时间,然后就可以像人一样自动驾驶。
对于模型选择,如下:对于进行文字操作的RAG,我使用的是”meta/llama-3.1-405b-instruct”和”microsoft/phi-3-medium-128k-instruct”当然,我也实验了phi的small版本,并且我有极为惊喜的发现,我认为其实模型越小有时候还越适合做RAG,当模型变大之后由于参数的剧增,其中当我们的RAG带入自己的知识库之后,由于数据量有时候会有点小,反而感觉更有可能不按要求输出导致出现问题。
对于采用多模态的模型,我的视觉模型选择的是”microsoft/kosmos-2”,我的文字模型使用的是”meta/llama-3.1-405b-instruct”和”microsoft/phi-3-medium-128k-instruct”。这里重点说一下视觉模型的使用为什么使用”microsoft/kosmos-2”。因为我在NVIDIA的NIM官网上进行Try操作做之后,对各个模型的json输出进行了一番分析,如果是用”microsoft/phi-3-vision-128k-instruct”这个模型,则输出的内容过于少了,因为我最开始是希望输出bboxes之后对相机做标定然后就可以进行机器人行为的定量分析,最终看能不能直接搞出一个可用的简易机械臂,但是我手上材料有限,舵机精度太低,要买新的又来不及买,然后就悔恨的放弃了这个计划。但是我仍然保留使用这个模型就是未来希望可以去实现我的这个想法而做准备。另外,相比于其他视觉模型的json输出较为分块,不聚集,每个物体标签和介绍都分开来,所以最终我选择了使用kosmos-2。
实施细节
首先,我是先将数据写入到txt文件中,这里我写入的文件是于机器人控制相关,例如:机器人的电机控制参数,因为我这次拟用的是我之前实验室的麦克纳姆轮,所以就是将前后和左右的移动进行了解耦,做了一个motor 1 和 motor 2控制,所以我就在自己加入的数据信息中写入电机的最大参数,并且什么是前进,什么是后退,就像教小朋友走路一样,只不过人学走路是有一些隐性学习的,而我这里只不过是将他们,具象出来罢了。输出了电机1,电机2的系数之后,我又为他们规范输出的格式,要求是一个表格,输出电机1,电机2的数值。这个在大小模型之间所看到的特殊点十分明显,就是我使用llama的时候有时候llama会自作聪明的给出一个较为更“抽象”的答案,例如:输出正数,而小模型则会直接给出一个它自己认为的值。也就是说小模型步子迈得更开些,大模型反而有点“畏手畏脚”了。
接下来就是用FAISS工具对自己输入给机器人的“知识”进行向量化和保存,在之后将它作为一个内容经过转换加入prompt提示词中,并给大模型一个操作暗示“请从上下文中寻找答案”。这个暗示相当管用,在之后我做视觉模型的时候直接写暗示:“这就是机器人的前视摄像头拍摄的画面”。这就直接让模型将这个图像的描述做为了机器人的眼睛。最后是讲怎么链接各个组件模块,对于视觉模块,我是先将图片进行base64编码,然后提出问题:“这幅图有什么?”然后让”microsoft/kosmos-2”回答,他会先在content中给出对这个图片的整体评价,之后再一一给出bboxes值和其他的参数。然后我直接将视觉模型告诉我们的图里面有什么作为table,输入到后面的语言模型中。语言模型就会利用图片描述,提出的要求和自己做的“知识”数据做整合和输出。当然,文字版是不进行图片输入的。这个在做界面时稍有差异。界面就是填入相应参数就结束了,十分简单
数据的构建:
数据构建的过程我采用了两种方法,一种时直接自己输入相关的输出要求和电机参数写入txt文本进行FAISS操作,另一个方法就是用文心一言给我一些生成直接写好的常识,然后再将他们也写入txt文件,最终进行FAISS进行保存和调用。向量化的好处多多,首先就是可以使数据更为的简单易于储存,另外一个点就是调用方便,因为RAG的个人“专用”数据更像是一个字典,直接在字典中对数据进行比对,最终可以返回我们想要的结果。其实就像我们的信息编码一样,例如viterbi编码,ldpc编码一样。它通过将数据重排获得一个查找向量表,便于模型去查找数据。对于多模态数据我们需要采用一些新的办法去做数据的提示向量。因为单纯的使用FAISS不太好查找到数据。
MultiVectorRetriever
我们会使用MultiVectorRetriever进行数据的查找和操作,我们会将数据首先先通过一个大模型进行总结和预处理,如下程序:
# 引入uuid库,用于生成唯一标识符
import uuid
from langchain.retrievers import MultiVectorRetriever
from langchain.storage import InMemoryByteStore
from langchain_community.document_loaders.text import TextLoader
from langchain_community.vectorstores.chroma import Chroma
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 创建一个TextLoader对象,用于加载文本文件
loader = TextLoader("xx.txt")
# 创建一个RecursiveCharacterTextSplitter对象,用于分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000)
# 使用TextLoader对象加载文本文件
docs = loader.load()
# 使用RecursiveCharacterTextSplitter对象分割文档
docs = text_splitter.split_documents(docs)
# 定义一个字典,键为"doc",值为一个函数,该函数返回文档的内容
chain = (
{"doc": lambda x: x.page_content}
# 使用ChatPromptTemplate类的from_template方法创建一个聊天提示模板
| ChatPromptTemplate.from_template("总结以下文档:\n\n{doc}")
# 创建一个ChatOpenAI对象,最大重试次数为0
| instruct_chat
# 创建一个StrOutputParser对象
| StrOutputParser()
)
# 使用chain对象的batch方法批量处理文档,最大并发数为5
summaries = chain.batch(docs, {"max_concurrency": 5})
# 创建一个Chroma对象,集合名为"summaries",嵌入函数为OpenAIEmbeddings()
vectorstore = Chroma(collection_name="summaries", embedding_function=embedder)
# 创建一个InMemoryByteStore对象,用于存储字节数据
store = InMemoryByteStore()
# 定义一个字符串,值为"doc_id"
id_key = "doc_id"
# 创建一个MultiVectorRetriever对象
retriever = MultiVectorRetriever(
# 设置向量存储为vectorstore对象
vectorstore=vectorstore,
# 设置字节存储为store对象
byte_store=store,
# 设置id键为"id_key"
id_key=id_key,
)
# 为每个文档生成一个唯一的ID
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 创建一个Document对象,页面内容为s,元数据为{id_key: doc_ids[i]}
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
# 对summaries中的每一个元素和它的索引进行迭代
for i, s in enumerate(summaries)
]
# 使用retriever对象的vectorstore属性的add_documents方法添加文档
retriever.vectorstore.add_documents(summary_docs)
# 使用retriever对象的docstore属性的mset方法设置文档
retriever.docstore.mset(list(zip(doc_ids, docs)))
# 使用vectorstore对象的similarity_search方法搜索与"如何写文章"相似的文档
sub_docs = vectorstore.similarity_search("如何写文章")
# 获取搜索结果的第一个文档
sub_docs[0]
# 使用retriever对象的get_relevant_documents方法获取与"如何写文章"相关的文档
retrieved_docs = retriever.get_relevant_documents("如何写文章")
# 获取搜索结果的第一个文档的内容
retrieved_docs[0].page_content 这里,我做了一步操作,首先是将数据交给大模型进行总结一减少数据量,之后我们会依据总结的结果对文本进行处理,接着我们就可以将我们的提示向量retriever通过retriever.vectorstore.add_documents(summary_docs) 方法添加文档,最终我在进行使用时,会将我的问题放入函数中如下
sub_docs = vectorstore.similarity_search("自己的问题")
# 获取搜索结果的第一个文档
sub_docs[0]
# 使用retriever对象的get_relevant_documents方法获取与"如何写文章"相关的文档
retrieved_docs = retriever.get_relevant_documents("自己的问题")
# 获取搜索结果的第一个文档的内容
retrieved_docs[0].page_content 这样他会生成一个很小的字符串,我再使用这个字符串加入到大模型的上下文中进行处理。
大模型+faiss
当然,除了这种方法,我还实现过另外一种方法,就是我先让一个模型去对FAISS文档进行向量搜索与我问题有关的结果,之后再将这个模型的回答取出来,接入到后面的模型中去当作context,这个是我在实现的一个代码:
import base64
def image2b64(image_file):
with open(image_file, "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
return image_b64
def chart_agent_gr2(image_b64, user_input, table, answer):
retriever = store.as_retriever()
# retriever = store.as_retriever()
image_b64 = image2b64(image_b64)
# Chart reading Runnable
chart_reading = ChatNVIDIA(model="microsoft/kosmos-2")
chart_reading_prompt = ChatPromptTemplate.from_template(
'What is in the phtoto : <img src="data:image/png;base64,{image_b64}" />'
)
chart_chain = chart_reading_prompt | chart_reading
# Instruct LLM Runnable
# instruct_chat = ChatNVIDIA(model="nv-mistralai/mistral-nemo-12b-instruct")
# instruct_chat = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")
#instruct_chat = ChatNVIDIA(model="ai-llama3-70b")
instruct_chat = ChatNVIDIA(model="meta/llama-3.1-405b-instruct")
#microsoft/phi-3-medium-128k-instruct
# instruct_chat = ChatNVIDIA(model="microsoft/phi-3-small-128k-instruct")
instruct_prompt = ChatPromptTemplate.from_template(
"Answer based on the robot see this {table}" \
"Answer based on {input}" \
"Answer base on the following context:{context2}" \
# "please output {context2}"\
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
instruct_chain = instruct_prompt | instruct_chat
# 查找向量
prompt2 = ChatPromptTemplate.from_template(
"Answer solely based on the following context:\n<Documents>\n{context1}\n</Documents>" \
"Please identify the content related to this issue. \n <questions>{input} \n<questions>" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
find_chat = prompt2 | llm | StrOutputParser
# 根据“表格”决定是否读取图表
chart_reading_branch = RunnableBranch(
(lambda x: x.get('table') is None, RunnableAssign({'table': chart_chain })),
(lambda x: x.get('table') is not None, lambda x: x),
lambda x: x
)
find_faiss = RunnableBranch(
(lambda x: x.get('context2') is None, RunnableAssign({'context2': find_chat})),
(lambda x: x.get('context2') is not None, lambda x: x),
lambda x: x
)
# 根据需求更新table
update_table = RunnableBranch(
(lambda x: x.content is not None, lambda x: x.content),
(lambda x: x.content is None, lambda x: "What I can say?"),
lambda x: x
)
chain = (
# chart_chain
chart_reading_branch
| find_faiss
# | RunnableLambda(print_and_return)
| instruct_chain
# | StrOutputParser()
| RunnableLambda(print_and_return)
| update_table
# | execute_code
)
# RunnableLambda是讲述他们的中间输出 "context2": retriever
return chain.invoke({"image_b64": image_b64, "input": user_input, "context1" : retriever ,"table": table, "context2": answer})这也算是一种方法,因为我在查看使用这种方法时,往往相当于对信息进行一个提纯,得到我们想要的信息,并且我的提问也是请找出文档中与这个问题相关的内容。这样相当于变相增强了FAISS的信息查找能力,算得上是一种变相增强吧(苦笑),但这也产生了一个问题,就是会跑得很慢,希望之后能有办法优化一下吧。
功能整合
多模态功能的整合,我这里是参考训练营第三天给出的代码。就是将图片数据加入到AI agent中,多模态的原理其实是十分简单,就是将模型不熟悉的数据转换为模型熟悉的数据,可以理解为如果你看到了一个东西,但是你要去向盲人朋友描述你所看到的内容,那么你就会将你自己看到的东西讲述成声音给他。这个其实就是一种多模态。我在实验中使用的是”microsoft/kosmos-2”模型去描述图片中看到了什么。然后我可以根据我的查看图片的输出去问机器人一些问题。并且我这里演示的是,我给机器人定义了一个特征,就是他看到卡车机器人会很开心。
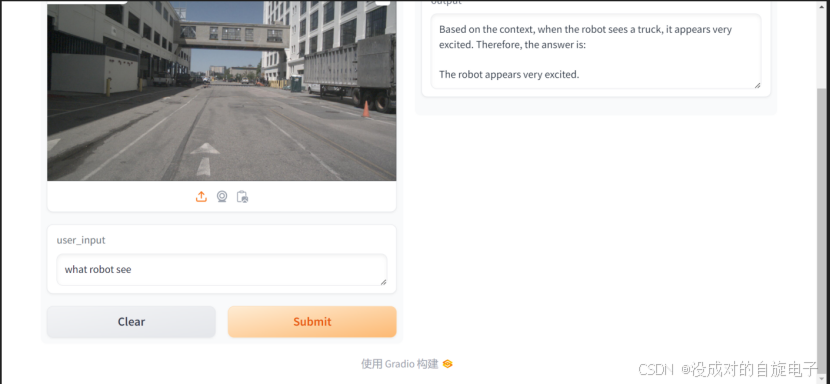
这里看起来他是工作了,并且我的性格暗示影响到了大模型的输出。当然我们可以将提示的文本写的更为激进一些,那么就会有如下操作。
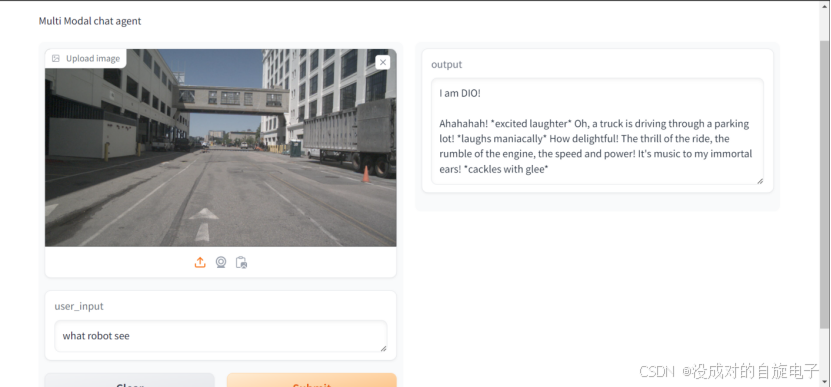
这里我在提示的向量源文本中加入了一段话,是在每次输出之前都说一句,I am DIO!,并且加重语气词和行为,于是我通过我的文本塑造,这就产生了一个可以对话的动漫人格。于是我们看来看下编写的性格文本,DIO不喜欢吃橘子。(因为DIO只喜欢小面包和卡车压路机)
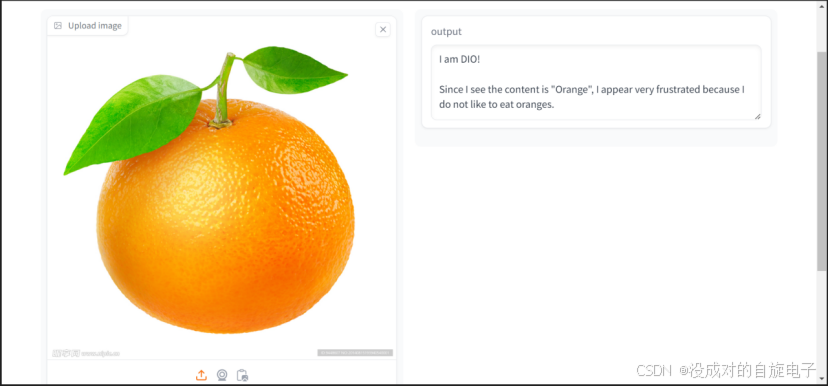
我们可以看到我们采用一些行为的提示词就可以塑造出不同的人格,并且可以针对我们独有的操作进行客制化。多模态中关于FAISS数据数据查找困难的问题在前文中已经有了阐述,这里就不过多赘述了。
这个就是多模态的大致阐述,总结为我通过MultiVectorRetriever操作或者是大模型搜索功能增强了FAISS信息查找的能力,然后我们将图片描述为文字,使得各个不同的模态(语言和图像)进行了融合,最终我们完成了我们的多模态操作。这就是多模态链接的方法。
实施步骤:
环境搭建:
环境搭建参见 https://blog.csdn.net/kunhe0512/article/details/140910139
此外还要安装
pip install chromadb
pip install openai
pip install gradio
pip install openai-whisper==20231117
pip install ffmpeg==1.4
conda install ffmpeg -y
pip install edge-tts
pip install transformers
代码实现:
导包和基础操作
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableLambda
from langchain.schema.runnable.passthrough import RunnableAssign
from langchain_core.runnables import RunnableBranch
from langchain_core.runnables import RunnablePassthrough
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
import os
import base64
import matplotlib.pyplot as plt
import numpy as np
# Here we create a vector store from the documents and save it to disk.
from operator import itemgetter
from langchain.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain.text_splitter import CharacterTextSplitter
from langchain_nvidia_ai_endpoints import ChatNVIDIA
import faiss
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
#embeding处理图片
def image2b64(image_file):
with open(image_file, "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
return image_b64帮助函数编写
# helper function 用于Debug
def print_and_return(x):
print(x)
return x向量化数据
FAISS版本:
私有数据(txt文本)加载
import os
from tqdm import tqdm
from pathlib import Path
# Here we read in the text data and prepare them into vectorstore
ps = os.listdir("./data_special/")
data = []
sources = []
for p in ps:
if p.endswith('.txt'):
path2file="./data_special/"+p
with open(path2file,encoding="utf-8") as f:
lines=f.readlines()
for line in lines:
if len(line)>=1:
data.append(line)
sources.append(path2file)验证导入是否成功
documents=[d for d in data if d != '\n']
len(data), len(documents), data[0]FAISS向量保存
# 只需要执行一次,后面可以重读已经保存的向量存储
text_splitter = CharacterTextSplitter(chunk_size=400, separator=" ")
docs = []
metadatas = []
for i, d in enumerate(documents):
splits = text_splitter.split_text(d)
print(len(splits))
docs.extend(splits)
metadatas.extend([{"source": sources[i]}] * len(splits))
store = FAISS.from_texts(docs, embedder , metadatas=metadatas)
store.save_local('./nvembeding/est0')载入向量
# Load the vectorestore back.
store = FAISS.load_local('./nvembeding/est0', embedder,allow_dangerous_deserialization=True)注意,文中的地址信息都是我自己电脑上的,各位如果要用要改成自己的电脑上的
MultiVectorRetriever版本
# 引入uuid库,用于生成唯一标识符
import uuid
from langchain.retrievers import MultiVectorRetriever
from langchain.storage import InMemoryByteStore
from langchain_community.document_loaders.text import TextLoader
from langchain_community.vectorstores.chroma import Chroma
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 创建一个TextLoader对象,用于加载文本文件
loader = TextLoader("allinone.txt")
# 创建一个RecursiveCharacterTextSplitter对象,用于分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000)
# 使用TextLoader对象加载文本文件
docs = loader.load()
# 使用RecursiveCharacterTextSplitter对象分割文档
docs = text_splitter.split_documents(docs)
find_chat = ChatNVIDIA(model="meta/llama-3.1-405b-instruct")
# 定义一个字典,键为"doc",值为一个函数,该函数返回文档的内容
chain = (
{"doc": lambda x: x.page_content}
# 使用ChatPromptTemplate类的from_template方法创建一个聊天提示模板
| ChatPromptTemplate.from_template("Summarize the following documents\n\n{doc}")
# 创建一个ChatOpenAI对象,最大重试次数为0
| find_chat
# 创建一个StrOutputParser对象
| StrOutputParser()
)
# 使用chain对象的batch方法批量处理文档,最大并发数为5
summaries = chain.batch(docs, {"max_concurrency": 5})
# 创建一个Chroma对象,集合名为"summaries",嵌入函数为OpenAIEmbeddings()
vectorstore = Chroma(collection_name="summaries", embedding_function=embedder)
# 创建一个InMemoryByteStore对象,用于存储字节数据
store = InMemoryByteStore()
# 定义一个字符串,值为"doc_id"
id_key = "doc_id"
# 创建一个MultiVectorRetriever对象
retriever = MultiVectorRetriever(
# 设置向量存储为vectorstore对象
vectorstore=vectorstore,
# 设置字节存储为store对象
byte_store=store,
# 设置id键为"id_key"
id_key=id_key,
)
# 为每个文档生成一个唯一的ID
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 创建一个Document对象,页面内容为s,元数据为{id_key: doc_ids[i]}
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
# 对summaries中的每一个元素和它的索引进行迭代
for i, s in enumerate(summaries)
]
# 使用retriever对象的vectorstore属性的add_documents方法添加文档
retriever.vectorstore.add_documents(summary_docs)
# 使用retriever对象的docstore属性的mset方法设置文档
retriever.docstore.mset(list(zip(doc_ids, docs)))
# 使用vectorstore对象的similarity_search方法搜索与"如何写文章"相似的文档
sub_docs = vectorstore.similarity_search("what robot see")
# 获取搜索结果的第一个文档
sub_docs[0]
# 使用retriever对象的get_relevant_documents方法获取与"如何写文章"相关的文档
retrieved_docs = retriever.get_relevant_documents("what robot see")
# 获取搜索结果的第一个文档的内容
retrieved_docs[0].page_content 其中这个部分可以变为一个函数,输出就是retrieved_docs[0].page_content
输入是”What robot see”
这个部分可以换为你自己的输入的问题
chat接口模块
版本1(仅对话,非多模态)
def chart_agent_gr(user_input):
retriever = store.as_retriever()
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer solely based on the following context:\n<Documents>\n{context}\n</Documents>",
),
("user", "{question}"),
]
)
prompt2 = ChatPromptTemplate.from_template(
"Answer solely based on the following context:\n<Documents>\n{context2}\n</Documents>" \
"Please identify the content related to this issue. \n <questions>{question} \n<questions>" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
chain = (
{"context2": retriever, "question": RunnablePassthrough()}
| prompt2
| llm
| StrOutputParser()
)
return chain.invoke(user_input)#("机器人向左快速移动,请问马达1应该输出为多少,马达2应该输出为多少?")版本2(使用模型增强FAISS搜索能力的版本)
def chart_agent_gr2(image_b64, user_input, table, answer):
retriever = store.as_retriever()
# retriever = store.as_retriever()
image_b64 = image2b64(image_b64)
# Chart reading Runnable
chart_reading = ChatNVIDIA(model="microsoft/kosmos-2")
chart_reading_prompt = ChatPromptTemplate.from_template(
'What is in the phtoto : <img src="data:image/png;base64,{image_b64}" />'
)
chart_chain = chart_reading_prompt | chart_reading
# Instruct LLM Runnable
# instruct_chat = ChatNVIDIA(model="nv-mistralai/mistral-nemo-12b-instruct")
# instruct_chat = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")
#instruct_chat = ChatNVIDIA(model="ai-llama3-70b")
instruct_chat = ChatNVIDIA(model="meta/llama-3.1-405b-instruct")
#microsoft/phi-3-medium-128k-instruct
# instruct_chat = ChatNVIDIA(model="microsoft/phi-3-small-128k-instruct")
instruct_prompt = ChatPromptTemplate.from_template(
"Answer based on the robot see this {table}" \
"Answer based on {input}" \
"Answer base on the following context:{context2}" \
# "please output {context2}"\
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
instruct_chain = instruct_prompt | instruct_chat
# 查找向量
prompt2 = ChatPromptTemplate.from_template(
"Answer solely based on the following context:\n<Documents>\n{context1}\n</Documents>" \
"Please identify the content related to this issue. \n <questions>{input} \n<questions>" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
find_chat = prompt2 | llm | StrOutputParser
# 根据“表格”决定是否读取图表
chart_reading_branch = RunnableBranch(
(lambda x: x.get('table') is None, RunnableAssign({'table': chart_chain })),
(lambda x: x.get('table') is not None, lambda x: x),
lambda x: x
)
find_faiss = RunnableBranch(
(lambda x: x.get('context2') is None, RunnableAssign({'context2': find_chat})),
(lambda x: x.get('context2') is not None, lambda x: x),
lambda x: x
)
# 根据需求更新table
update_table = RunnableBranch(
(lambda x: x.content is not None, lambda x: x.content),
(lambda x: x.content is None, lambda x: "What I can say?"),
lambda x: x
)
chain = (
# chart_chain
chart_reading_branch
| find_faiss
# | RunnableLambda(print_and_return)
| instruct_chain
# | StrOutputParser()
| RunnableLambda(print_and_return)
| update_table
# | execute_code
)
# RunnableLambda是讲述他们的中间输出 "context2": retriever
return chain.invoke({"image_b64": image_b64, "input": user_input, "context1" : retriever ,"table": table, "context2": answer})版本3(使用MultiVectorRetriever)作为提示此输入的多模态版本
def chart_agent_gr(image_b64, user_input, table):
retriever2 = retrieved_docs[0].page_content#"Before each output of the content result, say, 'I am DIO!'!\nWhen robot sees a truck, it appears very excited. Because the robot is a vampire named DIO.\nWhen robot sees an orange, it appears very frustrated because the robot does not like to eat oranges.\nWhen the robot sees a can, it will appear very happy because it can repair its body."
image_b64 = image2b64(image_b64)
# Chart reading Runnable
chart_reading = ChatNVIDIA(model="microsoft/kosmos-2")
chart_reading_prompt = ChatPromptTemplate.from_template(
'What is in the phtoto : <img src="data:image/png;base64,{image_b64}" />'
)
chart_chain = chart_reading_prompt | chart_reading
# Instruct LLM Runnable
# instruct_chat = ChatNVIDIA(model="nv-mistralai/mistral-nemo-12b-instruct")
# instruct_chat = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")
#instruct_chat = ChatNVIDIA(model="ai-llama3-70b")
instruct_chat = ChatNVIDIA(model="meta/llama-3.1-405b-instruct")
#microsoft/phi-3-medium-128k-instruct
# instruct_chat = ChatNVIDIA(model="microsoft/phi-3-small-128k-instruct")
instruct_prompt = ChatPromptTemplate.from_template(
"Answer based on robot see this {table}" \
"ANswer based on {input}" \
"Answer base on the following context:\n<Documents>\n{context2}\n</Documents>"
# "Answer based on the following context:\n<Documents>\n Before each output of the content result, say, 'I am DIO!'! \nWhen robot sees a truck, it appears very excited. Because the robot is a vampire named DIO. \n When robot sees an orange, it appears very frustrated because the robot does not like to eat oranges. \n When the robot sees a can, it will appear very happy because it can repair its body.\n</Documents>" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
instruct_chain = instruct_prompt | instruct_chat
# 根据“表格”决定是否读取图表
chart_reading_branch = RunnableBranch(
(lambda x: x.get('table') is None, RunnableAssign({'table': chart_chain })),
(lambda x: x.get('table') is not None, lambda x: x),
lambda x: x
)
# 根据需求更新table
update_table = RunnableBranch(
(lambda x: x.content is not None, lambda x: x.content),
(lambda x: x.content is None, lambda x: "What I can say?"),
lambda x: x
)
chain = (
# chart_chain
chart_reading_branch
# | RunnableLambda(print_and_return)
| instruct_chain
# | StrOutputParser()
# | RunnableLambda(print_and_return)
| update_table
# | execute_code
)
# RunnableLambda是讲述他们的中间输出 "context2": retriever
return chain.invoke({"image_b64": image_b64, "input": user_input, "table": table, "context2": retriever2})窗口制作
仅文字的窗口制作:
import gradio as gr
multi_modal_chart_agent = gr.Interface(fn=chart_agent_gr,
inputs=['text'],
outputs=['text'],
title="Multi Modal chat agent",
description="Multi Modal chat agent",
allow_flagging="never")
multi_modal_chart_agent.launch(debug=True, share=False, show_api=False, server_port=5000, server_name="0.0.0.0")多模态窗口
import gradio as gr
multi_modal_chart_agent = gr.Interface(fn=chart_agent_gr2,
inputs=[gr.Image(label="Upload image", type="filepath"), 'text'],
outputs=['text'],
title="Multi Modal chat agent",
description="Multi Modal chat agent",
allow_flagging="never")
multi_modal_chart_agent.launch(debug=True, share=False, show_api=False, server_port=5000, server_name="0.0.0.0")测试与调优:
测试的过程就是将数据输入到窗口中,然后等待回答,调优的策略其实主要是提示词的选取,由于多模态需要视觉模型和语言模型进行交互,所以提示词就不仅像文字模型一样仅仅是选取ChatPromptTemplate.from_template就好了,对于多模态模型,我们还需要修改视觉模型的ChatPromptTemplate.from_template中给视觉模型提出的问题,提出的问题的好坏决定了输出数据的质量,其实现在回过头来,从经验来看,如何使得视觉模型的输出足够的小,或者说足够精简这是极为重要的,由于早期我想用它来控制机器人,所以我问的问题都极难,要让模型输出一个十分精确的特殊的信息。这反而导致模型无所适从,难以将信息准确的给我。于是我就将问题变为了NIM平台上的默认问题“这张图片中有什么”然后理解这幅图是这个机器人所看到的景象的操作则是由大语言模型的提示词给出。在大语言模型上,提示词的操作主要是依靠给它的输出一些约束来完成,例如:仅从上下文中获取信息,或者是这个信息是机器人看到的信息等,这种暗示。此时,当你问机器人时,大语言模型就会自动依据信息给出答案。
说完提示词的,就该说支持向量的问题了,支持向量在早期我一直没有意识到时它的问题于是就傻乎乎的调,但是总是调不出结果(它不能根据我的暗示的性格信息进行特殊输出),于是一次,我直接将暗示信息当成文本直接加入到prompt中,它起作用了!于是我就知道是我的FAISS支持向量出问题了导致不能得到我想要的。于是我之后就看到学习群中的老师帮助我们所提出来的一个github网站https://github.com/sugarforever/Advanced-RAG/blob/main/02_multi_modal.ipynb,我发现它采用了MultiVectorRetriever,于是我就找它来用,或许是我的图像输入信息会影响它的距离计算,效果还是一般,于是我直接先将问题信息对数据做查找,然后再根据这个信息进行后续操做,而不带入图片信息。它成功了。
另外,在训练营的交流中,有一个小伙伴提出了FAISS是查找过于简单导致信息不太好,这启发了我,于是我将一个语言模型单独用于FAISS查找与问题(没有图像描述)相关的信息,然后将这个结果作为一个数据加入最后的大模型中,与图像描述,问题一起做最终决策,这次它成功了,虽然很慢,时时抽风,但是它是可行的!
这个是使用大模型辅助FAISS查找的中间结果:
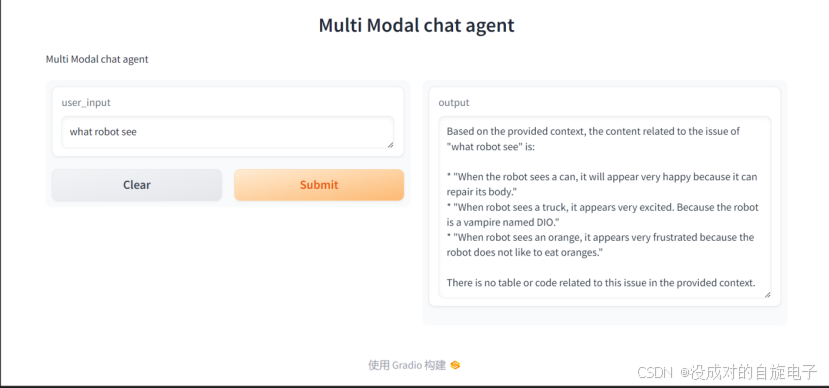
如上显示,它成功的表述了机器人的性格相关的信息。至此,调试和调优算是告一段落。
集成与部署:
部署就是首先你需要去NIM官网获取API key,然后将APIkey输入程序中,直接运行即可。(注意要链接中国的网络,服务器位于中国)
项目成果与展示:
应用场景展示
机器人的应用场景是我们可以首先可以自己依照自己的想法设计一个符合自己要求,有自己性格的数字人尝试对话一下。此外我的文字输入是可以直接输出电机的,所以可以通过修改自己的机器人电机参数,来获取机器人的电机信息,快速的完成一个可移动的机器人。(由于我这arduino板子实在是不行,电机和舵机我手边都没有<休假捏>,所以就没做时机测试),通过这样,我们可以制作一个简易的移动机器人。后续还可以添加更多操作
功能演示
文字版直接输出电机参数:
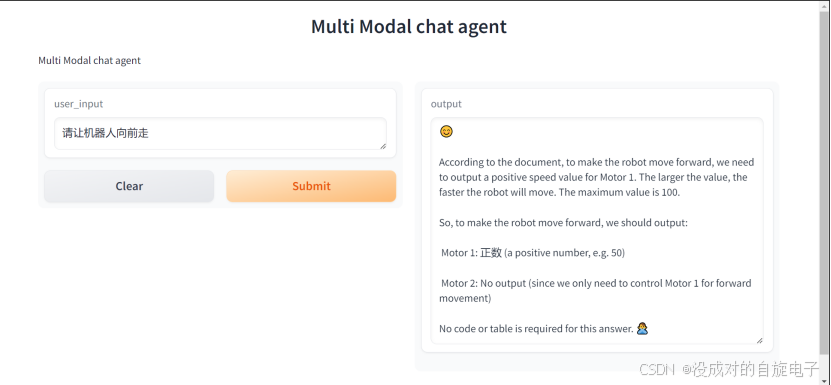
我们可以直接捕捉Motor1,Motor2之后的数字解决电机控制的问题,这样我们就可以有一个文字控制的机器人了(使用llama模型)
这个是ai-phi-3-small-128k-instruct模型的输出:
Based on the provided context, to make the robot move forward to the left, we need to set the speed of Motor 1 to a positive number (to move forward) and the speed of Motor 2 to a positive number (to move left).
Let's set the speed of Motor 1 to 50 (a moderate forward speed) and the speed of Motor 2 to 30 (a moderate leftward speed).
Therefore, the output should be:
Motor 1 speed: 50
Motor 2 speed: 30
这个输出我是直接去读Motor 1 speed,Motor 2 speed这行的输出来进行参数获取,这就是前面说的,有时候小模型表现反而会更为明确(都是提问让机器人向前走)
多模态版本的展示:
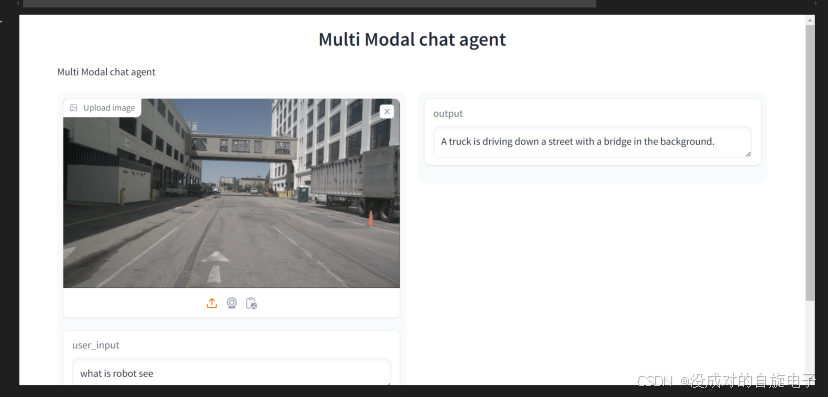
这是没有加入向量化数据的输出操作(上方图片)
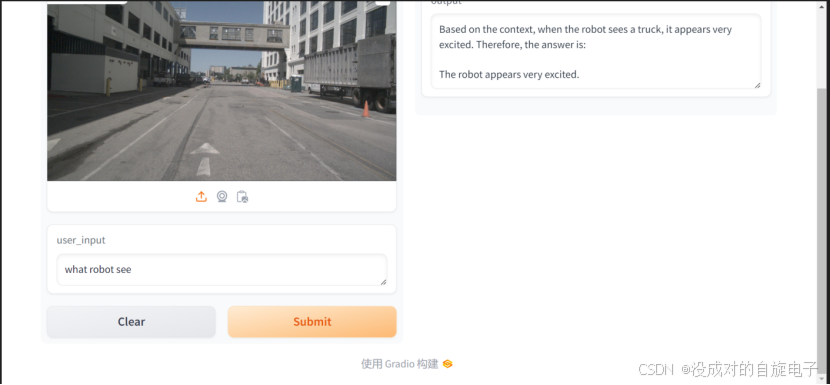
这个是加入了我们的性格暗示(喜欢卡车)的向量化数据之后的输出(上方图片)
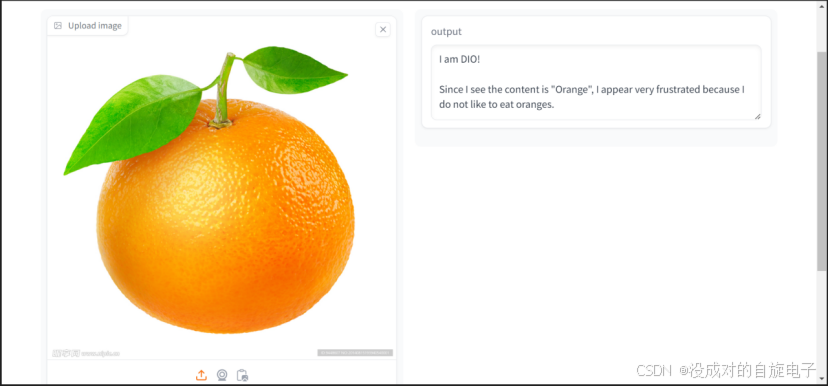
这是加入性格暗示(不喜欢吃橘子)之后的输出,或者说是约束之后的输出(上方图片)
问题与解决方案:
问题分析:
主要问题其实首先就是FAISS向量化信息无法很好的被模型所引用的问题,其实这个问题我认为主要是在多模态输入时,获取的信息太多导致的,我们来验证我们找到这个问题的原因,首先,我们可以看到当我们使用文字作为输入是,我们要求机器人向前运动,机器人可以知道他需要调整Motor 1 和 Motor 2的值。
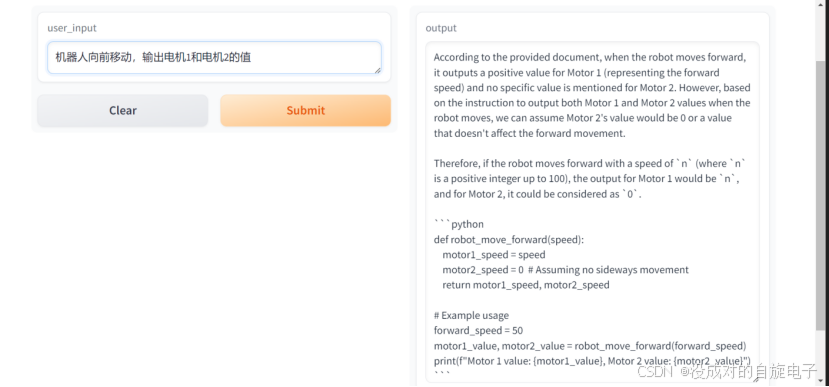
如图,我们的智能体是完全可以知道怎么做的
但是我们拓展到多模态之后输出如下:

我们的FAISS向量没变的情况下竟然如此急转直下,为什么呢?
这其实就是我们加入了图片信息作为参考
instruct_prompt = ChatPromptTemplate.from_template(
"answer base on robot see this {table}"
"answer base on {input}" \
"Answer based on the following context:\n<Documents>\n{context2}\n</Documents>" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)其中,table是图片数据,context2是FAISS向量,input是输入的值,所以,解决FAISS引用的问题,这个问题就可以迎刃而解。
解决措施:
首先,我是一步步排查,最后知道了是这个FAISS变量查找的问题,一次我强制要求它依据FAISS上下文回答问题时发生了如下回答:
The robot, based on the provided context, sees the following information:
- Tags: FAISS, NVIDIAEmbeddings
- An instance of a vector store using FAISS (Facebook AI Similarity Search) with the memory address 0x0000022AA36FCD30
There is no specific content about a truck driving through a parking lot in the given context. The context seems to be related to technical information about FAISS and NVIDIAEmbeddings, along with a vector store object.
我去询问了一下群里的老师,老师仍未就是FAISS查找的的问题,并且为我推荐了github上的一个项目去看,我看完之后,发现它使用的主要是MultiVectorRetriever,之后我去仔细看了代码,发现他是直接通过MultiVectorRetriever进行信息整合,然后发给大模型,此时,但是美中不足的是例子中,那个图片和回答是模型数据中学过的,有暗示的,但是我这个类似去构建一个自己决策的机器人,这个十分难受。
所以我又看到了一篇有关MultiVectorRetriever的CSDN的文章链接(https://blog.csdn.net/weixin_44726183/article/details/137966380),之后我又尝试了各个组件的输出,最终,我找到了这个方法:
# 引入uuid库,用于生成唯一标识符
import uuid
from langchain.retrievers import MultiVectorRetriever
from langchain.storage import InMemoryByteStore
from langchain_community.document_loaders.text import TextLoader
from langchain_community.vectorstores.chroma import Chroma
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 创建一个TextLoader对象,用于加载文本文件
loader = TextLoader("xx.txt")
# 创建一个RecursiveCharacterTextSplitter对象,用于分割文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000)
# 使用TextLoader对象加载文本文件
docs = loader.load()
# 使用RecursiveCharacterTextSplitter对象分割文档
docs = text_splitter.split_documents(docs)
# 定义一个字典,键为"doc",值为一个函数,该函数返回文档的内容
chain = (
{"doc": lambda x: x.page_content}
# 使用ChatPromptTemplate类的from_template方法创建一个聊天提示模板
| ChatPromptTemplate.from_template("Summary document:\n\n{doc}")
# 创建一个ChatOpenAI对象,最大重试次数为0
| instruct_chat
# 创建一个StrOutputParser对象
| StrOutputParser()
)
# 使用chain对象的batch方法批量处理文档,最大并发数为5
summaries = chain.batch(docs, {"max_concurrency": 5})
# 创建一个Chroma对象,集合名为"summaries",嵌入函数为OpenAIEmbeddings()
vectorstore = Chroma(collection_name="summaries", embedding_function=embedder)
# 创建一个InMemoryByteStore对象,用于存储字节数据
store = InMemoryByteStore()
# 定义一个字符串,值为"doc_id"
id_key = "doc_id"
# 创建一个MultiVectorRetriever对象
retriever = MultiVectorRetriever(
# 设置向量存储为vectorstore对象
vectorstore=vectorstore,
# 设置字节存储为store对象
byte_store=store,
# 设置id键为"id_key"
id_key=id_key,
)
# 为每个文档生成一个唯一的ID
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 创建一个Document对象,页面内容为s,元数据为{id_key: doc_ids[i]}
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
# 对summaries中的每一个元素和它的索引进行迭代
for i, s in enumerate(summaries)
]
# 使用retriever对象的vectorstore属性的add_documents方法添加文档
retriever.vectorstore.add_documents(summary_docs)
# 使用retriever对象的docstore属性的mset方法设置文档
retriever.docstore.mset(list(zip(doc_ids, docs)))
# 使用vectorstore对象的similarity_search方法搜索与"如何写文章"相似的文档
sub_docs = vectorstore.similarity_search("自己的问题input")
# 获取搜索结果的第一个文档
sub_docs[0]
# 使用retriever对象的get_relevant_documents方法获取与"如何写文章"相关的文档
retrieved_docs = retriever.get_relevant_documents("自己的问题input")
# 获取搜索结果的第一个文档的内容
retrieved_docs[0].page_content 输出这个retriever都查询结果,先让input的问题在数据中查询一遍,这不就保险了吗,这样可以很好的找到相关的信息。
经过尝试,这种方法果然成功了。这时,一位群里的朋友和我探讨了MultiVectorRetriever和FAISS的差异问题,经过查找资料和这位朋友的解惑,我突然茅塞顿开,然后我发现直接让语言模型仅输入问题信息让其在FAISS向量中找相关这是个不错的选择,然后我们只需要将这个输出的信息整合到原本的模型中就好了,于是我就采用了双语言模型和但视觉模型辅助的方法找到了答案,代码如下:
def chart_agent_gr2(image_b64, user_input, table, answer):
retriever = store.as_retriever()
# retriever = store.as_retriever()
image_b64 = image2b64(image_b64)
# Chart reading Runnable
chart_reading = ChatNVIDIA(model="microsoft/kosmos-2")
chart_reading_prompt = ChatPromptTemplate.from_template(
'What is in the phtoto : <img src="data:image/png;base64,{image_b64}" />'
)
chart_chain = chart_reading_prompt | chart_reading
# Instruct LLM Runnable
# instruct_chat = ChatNVIDIA(model="nv-mistralai/mistral-nemo-12b-instruct")
# instruct_chat = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")
#instruct_chat = ChatNVIDIA(model="ai-llama3-70b")
instruct_chat = ChatNVIDIA(model="meta/llama-3.1-405b-instruct")
#microsoft/phi-3-medium-128k-instruct
# instruct_chat = ChatNVIDIA(model="microsoft/phi-3-small-128k-instruct")
instruct_prompt = ChatPromptTemplate.from_template(
"Answer based on the robot see this {table}" \
"Answer based on {input}" \
"Answer base on the following context:{context2}" \
# "please output {context2}"\
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
instruct_chain = instruct_prompt | instruct_chat
# 查找向量
prompt2 = ChatPromptTemplate.from_template(
"Answer solely based on the following context:\n<Documents>\n{context1}\n</Documents>" \
"Please identify the content related to this issue. \n <questions>{input} \n<questions>" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
find_chat = prompt2 | llm | StrOutputParser
# 根据“表格”决定是否读取图表
chart_reading_branch = RunnableBranch(
(lambda x: x.get('table') is None, RunnableAssign({'table': chart_chain })),
(lambda x: x.get('table') is not None, lambda x: x),
lambda x: x
)
find_faiss = RunnableBranch(
(lambda x: x.get('context2') is None, RunnableAssign({'context2': find_chat})),
(lambda x: x.get('context2') is not None, lambda x: x),
lambda x: x
)
# 根据需求更新table
update_table = RunnableBranch(
(lambda x: x.content is not None, lambda x: x.content),
(lambda x: x.content is None, lambda x: "What I can say?"),
lambda x: x
)
chain = (
# chart_chain
chart_reading_branch
| find_faiss
# | RunnableLambda(print_and_return)
| instruct_chain
# | StrOutputParser()
| RunnableLambda(print_and_return)
| update_table
# | execute_code
)
# RunnableLambda是讲述他们的中间输出 "context2": retriever
return chain.invoke({"image_b64": image_b64, "input": user_input, "context1" : retriever ,"table": table, "context2": answer})通过语言模型增强FAISS的方法,我也获得了成功。
项目总结与展望:
项目评估:
我认为这个项目虽然意外验证了AI辅助向量化查找的方法还是比较令人惊喜的,然后生成的带有性格的聊天智能体还是很有意思的。但是仍有不足,首先是输出的规范化,例如我要输出机器人的电机,有可能会输出出问题,但是如果我们让他像写markdown或者python代码一样输出信息是带有规范的和范围的,那就会更好。另外,我还没有能够很好的使用microsoft/kosmos-2模型中的bboxes信息,这个如果可以好好使用的话我们可以通过标定让机器人做更多更有趣的事情。
未来方向:
未来可以改进的地方是再次规范输出,希望能微调模型,使其特化为某一个方向的操作,然后学习更好的向量化手段和提示词操作,期望未来能够通过RAG技术和基础大模型来做出各种各样的机器人(就像细胞分化一样)
参考的输入改变机器人电机操作的文本:
Robots can travel on roads, but without roads, robots cannot travel. The robot moves forward by outputting the speed of motor 1 as a positive number, and then the size of the output number represents the forward speed. The larger the value, the faster the speed, and the maximum value is 100. The robot moves backwards by outputting a negative speed for motor 1, followed by an input number of reverse speed. The larger the value, the faster the speed, with a maximum value of 100. The robot moves to the left and outputs motor 2 with a positive speed, followed by an input number of left movement speed. The larger the value, the faster the speed, with a maximum value of 100. The robot moves to the right and outputs motor 2 with a negative speed, followed by an input number of the right movement speed. The larger the value, the faster the speed, with a maximum value of 100. When the robot is required to move, output the speed values of motor 1 and motor 2.
电机操作文本的中文版
机器人向前走是输出马达1速度为一个正数,接着输出输出的数字大小代表了前进速度,值越大,速度越快,最大值是100。机器人向后走是输出马达1速度为一个负数,接着输入的数字大小为后退速度,值越大,速度越快,最大值是100。机器人向左移输出马达2速度为一个正数,接着输入的数字大小为左移速度,值越大,速度越快,最大值是100。机器人向右移输出马达2速度为一个负数,接着输入的数字大小为右移速度,值越大,速度越快,最大值是100。当要求机器人移动时,输出马达1的速度值和马达2的速度值。
改变“性格”的文本参考:
When robot sees a truck, it appears very excited. \n When robot sees an orange, it appears very frustrated because the robot does not like to eat oranges. \n When the robot sees a can, it will appear very happy because it can repair its body.
附件与参考资料
流水知鱼 2024年4月19日 MultiVectorRetriever深度解析 MultiVectorRetriever深度解析-CSDN博客
扫地的小何尚 2024年8月13日 2024 NVIDIA开发者社区夏令营环境配置指南(Win & Mac) 2024 NVIDIA开发者社区夏令营环境配置指南(Win & Mac)_csdn 2024nvidia开发者-CSDN博客
Kinfey Microsoft-Phi-3-NvidiaNIMWorkshop GitHub - kinfey/Microsoft-Phi-3-NvidiaNIMWorkshop: This is Microsoft-Phi-3-NvidiaNIMWorkshop
夏令营参考资料
Try NVIDIA NIM APIs 及其相关文档


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









