






前言
一、从LLM到LLM Agent
当提到“大模型”时,你首先会联想到什么?是 DeepSeek 还是 GPT****系列?或许你会问,人工智能早已存在,曾经也可以进行人机对话,那么,为什么如今“大模型”这么火?它到底与传统的人工智能有何不同?
大模型,顾名思义,是指那些具有海量参数和复杂计算结构的机器学习模型。我们一般说的“大模型”其实是指**“大语言模型”(Large Language Model,LLM)。相比传统人工智能的应用,大模型的爆发性进展体现在其超大规模的训练数据和参数**,使其能够模拟出类似人类的思维与推理能力。例如,ChatGPT 为大模型提供了一个非常通俗的解释,它将大模型描述为通过海量数据训练出来的深度神经网络,这种规模庞大的数据与参数使得模型产生了智能的涌现,展现出超越传统AI的灵活性和多样性,甚至能够进行复杂的归纳推理,类似于人类的思维过程。
与大模型交互的最基本方式,通常是通过 LLM 官方网站或 App:用户可以通过在对话框中输入文本来提出问题或发出指令,然后以文本输出的方式获取大模型的响应。随着 LLM 的能力不断增强,简单的对话方式已无法满足开发者对更强大功能的需求。因此,各大 LLM 厂商陆续推出了 LLM API,让开发者能够更灵活、高效地调用大模型的强大能力,并将其集成到各种应用之中。例如,OpenAI 就推出了这样两个被大家广泛使用、近乎于事实标准的API:
-
Chat Completions API:提供对话能力,允许开发者轻松集成 LLM,实现智能对话交互。
-
Assistants API:支持多轮对话、工具调用,适用于更复杂的任务处理,如自动化工作流、AI助手等。
看到这里,你已经清晰认知到:
✅ AI大模型正在重构全球科技产业格局
✅ 掌握核心技术者将享受行业顶级薪资基准
✅ 碎片化学习正在吞噬90%开发者的竞争力
在这里分享这份完整版的大模型 AI 学习资料,已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证!免费领取【保证100%免费】
Chat Completions
Chat Completions API 是 OpenAI 早期推出的 API 之一,主要用于处理聊天交互,可以理解为ChatGPT的API版本。用户通过填写token,选择Model并且填充Message,即可进行调用。
Chat Completions API 依托于 ChatGPT 的强大能力,适用于独立请求的场景,每次调用都是无状态的,无需携带对话上下文,因此特别适合简单的问答式交互。它的优势在于易于使用、几乎不需要额外配置,开发者可以直接调用 API,与 LLM 进行交互。例如,在客服系统中,Chat Completions API 可以即时响应用户问题,提供FAQ 问答或产品信息查询。从微服务的角度来看,它更像是一个无状态(stateless)的服务,每次请求都是完全独立的,不受历史对话的影响。
让我们通过例子来看一下Chat Completions API的使用方式。例如,如果我们希望调用GPT-4o来生成一个关于独角兽的睡前故事,那么我们可以像这样实现。
client = OpenAI()completion = client.chat.completions.create( model="gpt-4o", messages=[{"role": "user","content": "写一个关于独角兽的睡前故事"}])print(completion.choices[0].message.content)
如果我们想把所使用的LLM换成DeepSeek,那么只需要把ChatGPT的base_url换成DeepSeek的即可,因为它也支持OpenAI的Chat Completions API。
尽管已经快要混成业界事实标准了,但Chat Completions API 也存在一些局限性。由于它的无状态设计,每次请求都需要传递完整的对话上下文,导致在处理长对话或复杂任务时效率较低。此外,由于无法直接调用外部工具或 API,因此在需要数据查询、计算等功能的场景下显得捉襟见肘。此外,流式处理(Streaming)**的实现较为复杂,使得构建具有实时响应能力和多轮交互体验的应用变得更加困难。因此,虽然 Chat Completions API 提供了一种轻量级、即插即用**的 LLM 交互方式,但在更复杂的应用需求下,仍然需要更强大的解决方案来弥补这些不足。
Assistants API
为了弥补 Chat Completions API 的不足,OpenAI 又推出了 Assistants API,以便于我们构建AI助手。Assistants API可以通过指令(Instructions)调整自身行为,并利用模型(Models)、工具(Tools)和文件(Files)来响应用户查询。它支持持久化对话管理,可记录消息历史并自动处理超出上下文长度的内容,从而简化 AI 应用的开发。此外,Assistants API还能访问多种工具,包括 OpenAI 托管的代码解释器(code interpreter)和文件搜索(file search),以及开发者自定义的函数调用(function calling),使其具备计算、文档检索、API 交互等多种能力。此外,Assistants API还可以处理不同格式的文件,不仅能在创建时加载,还能在对话过程中添加和搜索,并在执行任务时生成新文件(如图像、电子表格),直接在响应中引用。通过 Assistants API,开发者可以构建更加智能、灵活的 AI 助手,大幅提升应用的交互体验和自动化能力。
Assistants API 的典型集成流程包括以下几个步骤:首先,通过自定义指令并选择合适的模型来创建一个 Assistant,必要时还可添加文件,使用如代码解释器、文件搜索和函数调用等工具;接着,在用户开始对话时创建一个线程(Thread),用户每次提问时将消息(Message)添加到这个线程中;最后,在这个线程上运行 Assistant,调用模型和相关工具生成响应。如此,我们就可以在应用程序中构建功能强大的 AI 助手,显著提升用户体验和交互能力。
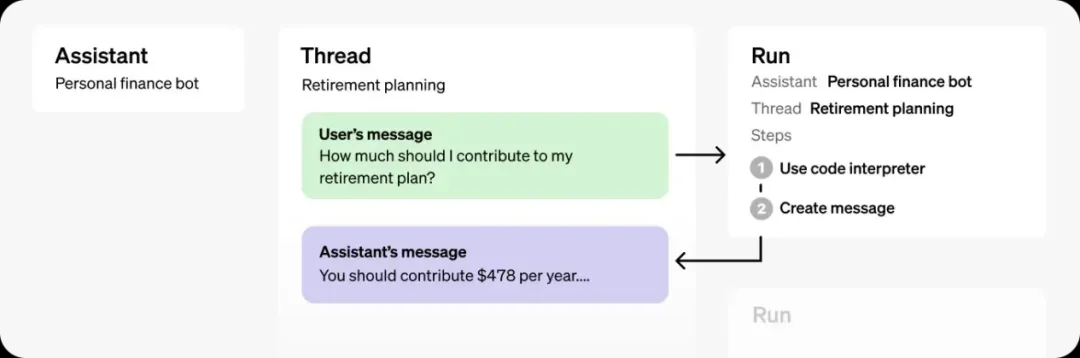
Chat Completions VS Assistants API
可以看出,Chat Completions API 和 Assistants API 在设计理念和应用场景上是各有侧重的,下面让我们来看下二者的对比。
| 功能/方面 | Chat Completions API | Assistants API |
|---|---|---|
| 运行环境 | 位于ChatGPT(本质是ChatGPT的API) | 独立于ChatGPT |
| 使用方式 | API或ChatGPT 自带 UI,可直接交互 | 主要面向程序化,可通过playground 预览 |
| 工具 | 浏览、DALL·E、代码解释器、检索、自定义操作 | 代码解释器、检索、函数调用 |
| 初始化设置 | 无需显式设置助手 | 需要创建一个具有定义能力的助手 |
| 会话管理 | 每个请求都是独立的 | 管理一个线程进行持续对话 |
| 交互处理 | 每次请求都需要发送完整的聊天历史 | 通过 Runs API 交互,考虑对话上下文 |
| 上下文管理 | 每个请求中提供上下文,适用于独立交互 | 通过线程持久存储上下文,适用于长期对话 |
| 复杂性 | 更简单,控制粒度较小 | 更复杂,提供详细控制和定制 |
| 能力 | 函数调用,有限的扩展能力 | 高级功能,如代码执行、在线搜索等 |
| 理想用例 | 简单的聊天机器人或独立应用 | 复杂、上下文密集的对话应用 |
从API到Agent的演变
与 Chat Completions API 不同,Assistants API 不仅支****持多轮对话,还允许开发者调用外部工具(function calling),并能够管理更复杂的任务流。这意味着,开发者已经不仅仅是在调用一个 API,而且还可以借助 Assistants API 开发出具备一定自主性和工具调用能力的 Agent。此时可以看到Agent形态已经初现,它们可以记住上下文、执行任务,并结合外部工具提供更高级的功能。
然而,仅通过Assistants API仍然无法做到真正的自主规划和任务管理,它仍然需要开发者提供明确的调用逻辑和指令。真正的 LLM Agent 进一步扩展了这个概念,使其具备更强的自主决策、任务拆解、记忆管理和工具调用能力,从而实现闭环的智能任务执行。
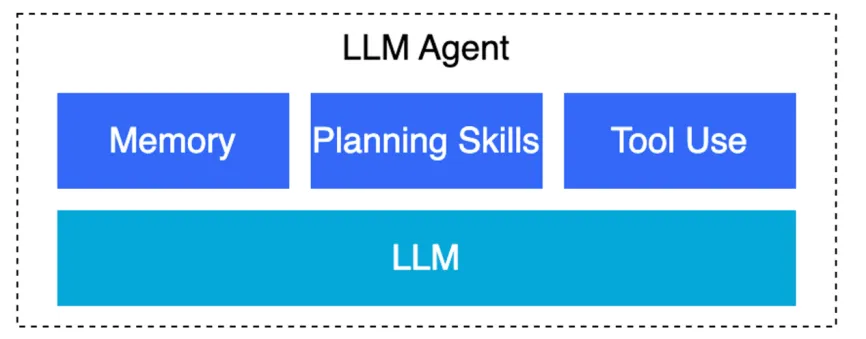
OpenAI 人工智能研究负责人 Lilian Weng 在其博客中将 LLM Agent 定义为将大语言模型(LLM)、记忆(Memory)、任务规划(Planning Skills)以及工具使用(Tool Use)相结合的智能系统。在部分文章中,LLM Agent可能被直译为“大模型代理”,但我们感觉这个名称其实并没有反映出它的内涵,称其为“大模型智能体”也许更为适宜。LLM Agent会像经验丰富的项目负责人那样,进行任务规划,把诸如"撰写市场分析报告" 这样的大任务拆解成数据收集、趋势分析、图表制作等具体步骤,并通过观察历史操作的效果(比如哪些动作投入产出比更高)来像人类总结经验那样不断优化自己的决策方式。而记忆则是LLM Agent的智慧中枢,既能在对话过程中智能关联上下文信息,又拥有类似超能力的记忆库,能瞬间从存储着百万条信息的数据库里精准调取所需知识。在遇到知识盲区时,LLM Agent还会灵活使用工具包,例如:实时连接财经 API 获取最新市场动态,就像记者随时查阅最新消息源;或者启动内置的代码解释器,像数据分析师那样自动跑数据、画图表。这三个环节环环相扣,让LLM不仅能理解任务,还能真正动手解决问题。
为了让智能体真正具备“理解上下文”的能力,还需要底层协议的支持。Anthropic公司于2024年推出的一个开放标准:模型上下文协议(Model Context Protocol,MCP),其设计灵感来自USB-C的“即插即用”理念,MCP希望通过标准化的接口,使AI模型能够灵活、高效地与外部系统进行交互。它采用客户端-服务器架构,允许宿主应用(如Claude Desktop、Cursor)通过MCP客户端与多个MCP服务器进行通信,从而实现上下文的动态传递和工具的调用。这种架构不仅提升了AI系统的扩展性,还确保了AI与外部资源之间的协作更加流畅。
MCP协议的关键在于它提供了标准化的通信机制,基于JSON-RPC协议进行数据交换,确保客户端与服务器之间的高效交互。通过这一架构,AI模型就可以灵活地调用外部工具和访问各种资源,例如实时数据或自定义功能,从而增强其任务执行能力。这种机制打破了传统AI系统与外部工具之间的壁垒,为更复杂的任务流管理和自主决策提供了可能。
二、应运而生的Agent框架
从单Agent到多Agent
随着大模型驱动的智能体(LLM Agent)在各类场景中落地,大家发现了一个有趣的矛盾:单个智能体越 “聪明”,实际应用中反而越容易遇到瓶颈。就像一位全能的超人,既要解读用户指令,又要规划任务、调用工具,还要实时纠错——多线程的 “大脑过载” 让响应速度变慢,复杂任务拆解也容易顾此失彼。尤其是在面对复杂的开放性问题时,单Agent知识储备有限、处理能力不足、难以适应动态变化的环境,这使得它很难有效拆分任务或协调多个目标。因此,人们很快意识到,现实世界的复杂问题往往需要团队作战。例如,医疗诊断需要分诊、检验、影像分析等环节接力;电商促销涉及选品、定价、客服等多部门协同。在这些场景中,单个能力再强的智能体也只能像一位孤掌难鸣的专家那样,难以避免信息断层与流程阻塞。
相比之下,多 Agent 系统就像一支配合默契的团队:每位成员专注处理自己擅长的子任务,通过分工协作让复杂问题迎刃而解。这种模式不仅大幅提升效率,还能让整个系统更稳定可靠。就像在一个软件开发团队中,产品经理梳理需求、架构师搭建框架、工程师专注编码,每个角色都能产出标准化成果(如需求文档、接口规范)并在协作中保持思路统一,减少因环节衔接不畅导致的错误。团队通过共享信息库和智能通知机制,避免重复沟通的困扰。这样的协作体系能灵活调整团队配置,随时增减专业人员来满足不同任务需求。更有趣的是,多 Agent 甚至能主动完善需求细节,例如自动优化界面设计并形成更完善的方案,不再需要依赖人工预设规则。
当然,多 Agent 协作模式也带来了新的挑战。
首先是信息整合的难题。共享信息池如同一个公共留言板,海量信息涌入时需要依赖智能筛选机制,而角色之间的对话必须遵循结构化协议(例如统一使用标准化模板),否则容易产生 “你说东我理解西” 的错位问题。如何给不同 AI 角色分配任务、设计合理的对话规则(比如防止信息误传的校验机制),这些都需要仔细考虑。
其次是资源协调的考验。当团队成员(Agent)数量增加时,就像办公室突然涌入大量新人,设备抢用、空间不足等问题会突显。尤其是在需要即时反馈的场景中,响应速度变慢会让用户明显感到卡顿。更棘手的是,当多个 AI 协同工作时,决策责任的划分、隐私数据的保护等问题就像团队作业时的权责归属,需要建立更清晰的安全管理机制。尽管存在这些局限性,多 Agent 还是为 LLM 驱动的自主协作提供了范式,为复杂任务的自动化开发奠定了基础。
多Agent框架
在多 Agent 的协作模式诞生后,大家发现,虽然这种分布式架构带来了灵活的可能性,但如果缺少统一的框架支持,实际落地时会遇到不少挑战。例如,每个 Agent 的功能都需要从零开始设计和对接,光是协调不同模块之间的交互逻辑就可能消耗大量时间,导致开发周期很长。系统运行时也可能因为某个 Agent 的响应延迟或逻辑冲突,引发连锁反应。与此同时,当业务需要扩展新能力时,开发者往往需要反复校准各个 Agent 的协作关系。这种 “牵一发而动全身” 的改动成本,让系统迭代变得束手束脚。更不用说日常维护时,排查问题就像在错综复杂的迷宫里寻找线索,不同 Agent 的日志格式、通信协议如果缺乏统一标准,每次排查都得重新理解每个模块的 “方言”。这时候大家才意识到,一套好的框架不仅能规范开发流程,而且可以为多 Agent 协作搭建起高速公路,让团队把精力真正聚焦在创造价值上。
由此,多 Agent 框架应运而生。这类框架的核心思想在于,将协作逻辑抽象出来并建立标准化的通信规则和任务分配方式,从而可以使不同功能的智能体形成有机整体。这样,Agent开发者无需再从零开始设计协作规则,而是专注于提升单个智能体的专业能力。这种设计既降低了系统搭建的复杂性,又能让智能体团队更高效地应对复杂问题。
LongChain & LangGraph
LangChain是由开发者Harrison Chase于2022年10月推出的开源框架,其目标是通过模块化设计简化基于大语言模型(LLM)的应用开发。其核心理念是将AI能力拆解为可组合的“链”(Chain),支持开发者灵活组装数据检索、工具调用与逻辑控制流程。LangChain吸引开发者的关键在于功能的丰富性与高度模块化的设计,允许开发者将多个步骤串联起来,并提供了动态的记忆模块,可以保存用户上下文信息,使得对话更加连续自然。同时,LangChain还支持与外部工具链整合,例如数据库、搜索引擎和Python函数调用,这为开发者提供了扩展LLM能力的途径。例如,用户可通过预定义模块快速构建智能客服系统,串联本地知识库查询、多模型推理(如GPT-4与Claude协同)及API动作执行(如订单修改)。由此,LangChain逐渐成为企业级AI应用的基础设施之一,其在GitHub上的星标数已突破10.4万,并衍生出了LlamaIndex集成、多模态扩展等社区插件,。
LangGraph作为LangChain的进阶组件于2023年底发布。它引入了有向无环图(DAG)架构,能够协调 Chain、Agent 和 Tool 等组件,支持 LLM 循环调用和 Agent 过程的精细化控制,通过定义图的节点和边来详细定义基于 LLM 的任务。在任务运行期间,它会维护一个中央状态对象,这一对象会根据节点的变化不断更新,其属性可根据需要进行自定义。例如,在供应链优化场景中,多个AI智能体可并行执行需求预测、库存调度与供应商谈判任务,并通过节点依赖关系动态调整优先级。LangGraph突破了传统链式结构的线性限制,但其模块化设计也带来较高学习门槛,开发者需深入理解“链-agent-记忆”的交互逻辑。截至目前,LangGraph的GitHub星标数已突破10.3万。同时,LangChain与LangGraph已被微软、Airbnb等公司用于构建内部自动化平台,并与AutoGPT等自主智能体框架形成互补生态,共同推动LLM从对话工具向生产级系统的演进。
为了展示LangGraph的特点,我们以一个旅行规划助手为例说明其构建过程。这个旅行规划助手由多个可以互相交互的 AI 智能体组成,每个智能体负责不同的任务并能根据需要将对话转交给其他智能体。下面是系统中三个核心智能体的定义:
-
travel_advisor 智能体:旅行推荐专家,该智能体负责为用户提供旅行目的地的建议(如国家、城市、景点等)。当用户需要酒店相关信息时,travel_advisor 会将会话转交给 hotel_advisor。
# 定义 travel_advisor 的工具集合travel_advisor_tools = [ get_travel_recommendations, # 获取旅行推荐 make_handoff_tool(agent_name="hotel_advisor") # 转交给 hotel_advisor 的工具]
# 创建 travel_advisor 智能体travel_advisor = create_react_agent( model, travel_advisor_tools, state_modifier=( "您是一位可以推荐旅行目的地(例如国家、城市等)的旅行专家。" "如果用户需要关于酒店的信息,请向 'hotel_advisor' 发起请求。" "在转交前,请务必提供一段人类可读的响应内容。" ))
-
hotel_advisor 智能体:酒店推荐专家,该智能体负责为特定目的地提供酒店推荐。如果用户尚未确定目的地,hotel_advisor 可以反向请求 travel_advisor 协助进行目的地推荐。
# 定义 hotel_advisor 的工具集合hotel_advisor_tools = [ get_hotel_recommendations, # 获取酒店推荐 make_handoff_tool(agent_name="travel_advisor") # 转交给 travel_advisor 的工具]
# 创建 hotel_advisor 智能体hotel_advisor = create_react_agent( model, hotel_advisor_tools, state_modifier=( "您是一位酒店专家,可以为特定旅游目的地提供酒店推荐。" "如果用户尚未决定旅行地点,请向 'travel_advisor' 请求帮助。" "在转交前,请务必提供一段人类可读的响应内容。" ))
-
human_node:用户交互节点,我们定义了一个人类节点,用于接收用户输入。通过读取 langgraph_triggers 中记录的最近活跃智能体,我们可以将控制权正确转交给对应的智能体,实现无缝对话。
def human_node(state: MessagesState, config) -> Command[Literal["hotel_advisor", "travel_advisor", "human"]]: """用于收集用户输入的节点。""" user_input = interrupt(value="等待用户的输入。")
# 从 config 中读取 langgraph 的触发记录,判断下一个活跃的智能体 langgraph_triggers = config["metadata"]["langgraph_triggers"] active_agent = langgraph_triggers[0].split(":")[1]
return Command( update={"messages": [{"role": "human", "content": user_input}]}, goto=active_agent, )
这样,我们就构建了一个由多个 AI智能体组成的旅行规划助手,其中每个智能体都具有明确的职责并能在需要时主动寻求其他智能体协助。当某一智能体完成响应后,对话会自动返回 human_node等待用户新的输入,从而实现高效流畅的人机交互体验。
OpenAI Swarm VS Agents SDK
OpenAI Swarm是由OpenAI研究团队于2024年提出的实验性质的多智能体协作框架,其核心目标是通过模拟生物群体行为(如蚁群、蜂群)的“自组织”机制,实现复杂任务的分布式求解,主打特征是工效(ergonomic)与轻量(lightweight),关注的重点是让智能体协作和执行变得轻量、高度可控且易于测试。这一框架基于GPT-4 Turbo模型构建,允许开发者定义数百个微型AI智能体,每个智能体仅需处理简单子任务(如数据分类、局部推理),并通过共享的全局记忆池与轻量级通信协议(如基于向量相似度的信息传递)实现动态协作,截至目前,OpenAI Swarm的GitHub星标数已突破1.9万。
近期,OpenAI决定将Swarm进行升级,并正式更名为Agents SDK。Agents SDK 的核心理念是在保持简洁的同时提供直观高效的方式来构建更复杂、更强大的功能。在传统开发中,调试往往需要手动添加调试语句,而 Agents SDK 的一大亮点便是内置了监控和追踪(tracing)功能,大幅降低了调试的复杂度。
这次 Agents SDK 的更新带来了不少实用的改进。例如,它内置了智能体循环(Agent Loop),可以自动调用工具并将结果反馈给 LLM,然后不断循环直到任务完成,整个过程几乎不需要人工干预。它还强调了 Python-first 的理念,直接用 Python 的原生语法就能组织智能体的行为,完全不用去学新的抽象框架,开发体验更顺畅。此外,任务交接(Handoffs) 也变得更强大了,多个智能体之间可以协调分工,像团队一样配合完成任务。而在安全性方面,它引入了 Guardrails,在任务执行过程中可以实时验证输入,一旦发现问题就立刻中断流程,避免出错。更棒的是,它还支持将任何 Python函数一键变成工具(Function Tools),自动生成 schema,并用 Pydantic 做验证,方便又可靠。最后,别忘了Tracing,也就是内置的追踪和监控功能,可以让你清晰看到每一步的执行过程,哪里出问题一目了然,还能结合 OpenAI 提供的评估、微调、蒸馏工具一起用,整体来说非常适合构建高质量的 Agent 应用。
我们来看看如何通过Agents SDK 构建一个跨学科多Agent问答助手。首先,我们创建我们的一个Agent,这个Agent擅长回答数学领域的问题。
agent = Agent( name="数学老师", instructions="你提供数学问题的帮助。在每一步中解释你的推理过程,并包含示例。",)
为了适应更多学科领域的问答需求,我们增加更多的Agent。可以看到,我们增加了handoff_description字段,这个字段提供转交路由的有关信息。如HistoryTutor就是专门回答历史问题的Agent,之后转交时就会以此为依据选择被转交的Agent。
history_tutor_agent = Agent( name="历史老师", # 智能体名称 handoff_description="擅长处理历史相关问题的专家型智能体", # 任务交接时的角色说明 instructions="你负责解答历史相关的问题,请清晰地解释重要事件及其背景。" # 智能体的行为指令)
math_tutor_agent = Agent( name="数学老师", # 智能体名称 handoff_description="擅长处理数学问题的专家型智能体", # 任务交接时的角色说明 instructions="你负责解答数学问题。在每一步中解释你的推理过程,并提供示例。" # 智能体的行为指令)
接着,我们定义我们的handoffs。对每一个Agent,我们都可以定义转交条目,以此来决定我们如何推进我们的任务。可以看到,我们定义了一个分类Agent,他可以根据用户的家庭作业问题种类来决定交给哪一个Agent来回答。
triage_agent = Agent( name="分流助手", # 智能体名称 instructions="你根据用户的作业问题,判断应该由哪个智能体来处理", # 行为指令 handoffs=[history_tutor_agent, math_tutor_agent] # 可交接的目标智能体列表)
最后,我们以triage_agent作为入口运行工作流:
async def main(): result = await Runner.run(triage_agent, "法国的首都是哪里?") print(result.final_output)
当然,Agents SDK 还提供了一个额外的功能:自定义 Guardrails(护栏)机制,用于在任务开始前对用户输入进行验证。比如,我们可以增加一个名为guardrail_agent 的护栏智能体,专门用于判断用户是否提出了与家庭作业相关的问题,从而帮助系统提前过滤不相关或无效的请求,提升整个智能体系统的准确性与稳定性。这个机制让 Agent 的输入变得更加可控,也为构建更安全、更健壮的应用提供了保障。
class HomeworkOutput(BaseModel): is_homework: bool reasoning: str
guardrail_agent = Agent( name="护栏检查", instructions="检查一下用户是否在问家庭作业有关内容", output_type=HomeworkOutput,)
async def homework_guardrail(ctx, agent, input_data): result = await Runner.run(guardrail_agent, input_data, context=ctx.context) final_output = result.final_output_as(HomeworkOutput) return GuardrailFunctionOutput( output_info=final_output, tripwire_triggered=not final_output.is_homework, )
至此,我们就基于Agents SDK实现了一个多Agent作业问答助手,我们可以前往Trace viewer in the OpenAI Dashboard 来查看agent运行traces等数据,实现可观测性。
AutoGen
AutoGen是由微软研究院团队于2023年9月推出的多智能体协作框架,旨在通过定义角色化智能体(如“程序员”、“测试员”、“产品经理”)的分工与交互机制,解决复杂任务中单一AI智能体的局限性。其核心创新在于通过可定制的智能体对话协议支持开发者配置多个智能体的工作流(如顺序对话、并行竞争或动态投票),同时允许用户随时介入调整决策。这个框架深度集成GPT、Claude等主流模型,支持混合使用不同能力的模型(如GPT-4处理创意任务,GPT-3.5执行常规分析),同时兼容LangChain工具链实现数据库查询、网络搜索等扩展功能。实测显示,AutoGen在自动化测试报告生成、跨领域研究综述撰写等任务中,效率较单智能体系统提升40%以上,同时错误率降低约30%。截至2025年,AutoGen的GitHub仓库星标数突破4.1万,成为企业级AI智能体自动化部署的主流选项之一。
AutoGen高度灵活的架构也带来配置复杂性,开发者需精准定义智能体角色与通信规则,否则容易出现“讨论僵局”或冗余计算。为解决这一问题,社区推出AutoGen Studio可视化编排工具,支持拖拽式工作流设计,并预置常见行业模版(如客服工单处理、供应链风险预测)。AutoGen与LangGraph的图结构编排能力可以形成互补,从而推动多智能体系统从实验性技术向工业级基础设施演进。
AutoGen 就像打造了一群会交流的智能伙伴(智能体),它们通过彼此对话就能协同解决复杂问题。这些AI助手有两个核心功能:首先,每个成员都能主动发起或接续对话,就像同事间随时沟通工作进展;其次,它们的 “技能包” 可以自由组合,既能调用大语言模型的智慧,也能接入真人专家的判断,还可以联动各类专业工具,形成最适合当前任务的组合。这种设计既保持了专业系统的灵活性,又让技术协作如团队配合般自然流畅。
AutoGen的初始版本(V0.2)引起了人们对智能体技术的广泛兴趣。但与此同时,用户面临着架构限制、低效的 API 加上快速增长以及有限的调试和干预功能。为此,AutoGen V0.4在其基础上实现了多维度升级,通过异步消息传递、事件驱动型架构带来了更强的可观测性和控制力、更灵活的多智能体协作模式和可重用的组件。相较于 V0.2 需要手动配置对话逻辑的交互模式,V0.4 新增了通过动态决策引擎实现智能体间自主任务流转的方式。而且,新增的预置功能库也扩展了 20 + 可插拔工具接口,开发者能像组装积木一样快速构建混合型智能体。
我们来看看如何通过 AutoGen 构建一个写作助手。首先,我们需要设计一个撰写智能体来完成文案草稿的写作。
@type_subscription(topic_type=writer_topic_type)class WriterAgent(RoutedAgent): def __init__(self, model_client: ChatCompletionClient) -> None: super().__init__("A writer agent.") self._system_message = SystemMessage( content=( "你是一名作家。请根据用户要求,撰写一份简短(约150字)的文字材料,仅将文案作为单个文本块输出。" ) ) self._model_client = model_client
@message_handler async def handle_intermediate_text(self, message: Message, ctx: MessageContext) -> None: prompt = f"以下是关于该产品的信息:\n\n{message.content}"
llm_result = await self._model_client.create( messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)], cancellation_token=ctx.cancellation_token, ) response = llm_result.content await self.publish_message(Message(response), topic_id=TopicId(format_proof_topic_type, source=self.id.key))
我们可以注意到,当撰写智能体完成工作后,会把草稿通过publish_message的方式广播到format_proof_topic_type话题下。此时,我们还需要设计一个文本编辑智能体,订阅format_proof_topic_type话题,用来对撰写智能体输出的草稿进行纠正和校对。
@type_subscription(topic_type=format_proof_topic_type)class FormatProofAgent(RoutedAgent): def __init__(self, model_client: ChatCompletionClient) -> None: super().__init__("A format & proof agent.") self._system_message = SystemMessage( content=( "你是一名编辑。请修改草稿,纠正语法,提高清晰度,确保语调一致,格式并使其更加精炼。" ) ) self._model_client = model_client
@message_handler async def handle_intermediate_text(self, message: Message, ctx: MessageContext) -> None: prompt = f"草稿:\n{message.content}." llm_result = await self._model_client.create( messages=[self._system_message, UserMessage(content=prompt, source=self.id.key)], cancellation_token=ctx.cancellation_token, ) response = llm_result.content print(response)
最后,我们可以通过将消息发布并运行工作流。
printf("heruntime.start()await runtime.publish_message( Message(content="请帮我写一份关于Agent的微信公众号"), topic_id=TopicId(concept_extractor_topic_type, source="default"),)await runtime.stop_when_idle()
至此,我们就基于Agents SDK实现了一个多Agent写作助手,可以让它帮助我们写微信公众号了。
多Agent框架对比
无论是LangChain、Agents SDK还是AutoGen,他们在在设计理念和应用场景上是各有侧重的,下面让我们来看看他们的全面对比。
| 框架 | 开发者 | 核心特点 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| LangChain | Harrison Chase | 模块化设计,支持多种 LLM 和工具集成,提供链(Chain)和智能体(Agent)抽象 | 复杂 NLP 应用(如智能客服、文档分析) | 社区活跃,扩展性强,支持多模型和外部工具 | 配置复杂,对编程能力要求较高 |
| LangGraph | LangChain 团队 | 基于有向循环图(DAG)的流程编排,与 LangChain 深度集成 | 需要状态管理的复杂任务(如多步骤决策、动态流程控制) | 灵活性高,可视化调试,支持复杂逻辑分支 | 文档较少,学习曲线陡峭,需理解图论概念 |
| OpenAI Swarm/Agents SDK | OpenAI | 轻量级多 Agent 协作,支持任务移交(Handoff),完全透明控制 | 轻量级多 Agent 协作(如客服系统分工、简单任务链) | 易上手,代码简洁,支持流式传输 | 仅支持 OpenAI 模型,功能有限,社区支持弱 |
| AutoGen | 微软 | 多 Agent 异步协作,支持人工干预和模块化扩展(如自定义工具、记忆模块) | 复杂软件开发、需人机协作的场景(如代码生成、数据分析) | 功能强大,支持分布式部署,适合企业级应用 | 配置复杂(需代理服务器),非程序员难上手 |
三、多Agent协作设计之道
当我们提及多Agent,一个不可避免的话题是我们究竟该如何设计Agent协作方式才能更好地完成用户提出的任务。事实上,与软件开发中为人们津津乐道的设计模式类似,对于多Agent应用而言也有这样一套发展中的设计模式正被大家所使用。
其实,在上文为介绍Agent框架而举的例子中,也不乏存在像Handoff、顺序流等设计模式的运用。优秀的设计模式的核心理念和设计结构是通用的,不会因为所使用的Agent框架、LLM模型的改变而改变。所以在接下来的讨论中,我们不会围绕某一具体的框架和模型展开——但倘若脱离了具体场景,仅用干瘪的概念来介绍又会使得大家“听君一席话,如听一席话”。因此我们不妨从一些实际的例子出发,带领大家走进一家正在计划使用Agent来替代员工完成日常工作的电商公司,看看如何通过合理的多Agent协作设计来解决实际问题。
不同的软件开发角色,互相协作共同完成软件开发任务。
顺序工作流 / Sequential Workflow
我们考虑这样一个客户服务场景:客户正和一个聊天机器人交互,希望咨询某公司产品的详细情况。显然,这个任务可以很容易被拆分为三个有前后关系的子任务,分别是检索、撰写和校对,因此我们可以设计如下三个智能体。
上下滑动阅读更多内容
● 检索智能体:分析用户描述,从产品库中找到合适的产品,输出产品描述信息。它的提示词是:
“你是某公司的营销经理。请根据用户给出的产品描述,从产品库中找到合适的产品。你可以用模糊搜索API找到相似的产品,然后挑选一个最符合用户需求的产品。请输出你挑选的商品的描述。”
● 撰写智能体:根据检索智能体提供的产品描述信息撰写文案,输出一份文案草稿。它的提示词是:
“你是某公司的营销文案。给定一段商品的描述,撰写一份引人注目的营销文案,激发消费者的购买热情。输出应简短(约 150 个字),且只输出一个文本块。”
● 校对智能体:完善语法、提高清晰度和保持一致的语气来润色文案草稿,输出最终提供给用户的最终版本。它的提示词是:
“你是某公司的营销文案编辑。给定一则营销文案草稿,纠正语法,提高清晰度,确保语气一致,给出格式并使其精炼。将改进后的最终稿件输出为一个文本块。”
基于这个多智能体应用,用户可以与聊天机器人交互获得所需要的内容,过程如下图所示。
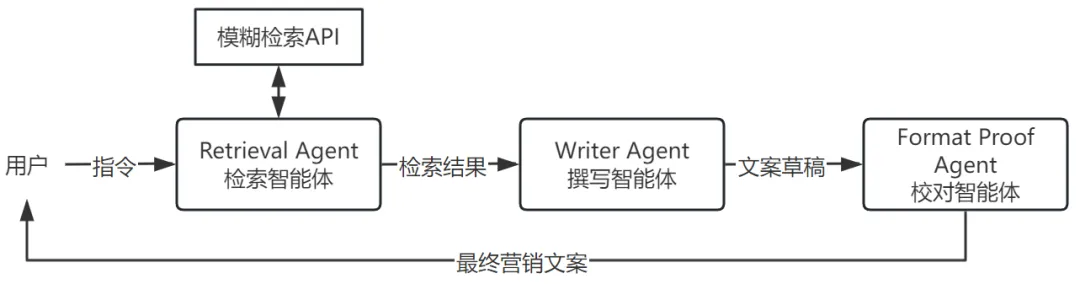
我们可以发现:在这个流程中,智能体按照确定的顺序做出响应,工作流中的每个智能体处理消息并生成响应,然后将其传递给下一个智能体,从而协作执行任务。这种设计被称为“顺序工作流”,是一种十分基础的多智能体设计模式,适合创建确定性工作流,每个智能体只需完成预先指定的子任务。
为了实现信息的传递,我们首先要选择一种以“发布-订阅”的方式支持智能体之间相互通信的框架,然后设计具体智能体的提示词和其订阅与发布的消息。以检索智能体为例,这个智能体需要订阅“用户指令消息”,一旦用户发布一条具体的指令,检索智能体便使用特定的客户端向LLM发送请求,包含系统消息、任务上下文以及可用工具的模式。若LLM返回结果是FunctionCall,则调用工具(本例中为模糊检索API)完成信息检索并将检索的信息加入上下文,重新调用LLM生成新响应;而若LLM返回结果是某个产品的描述,则发布一个“检索结果消息”,同时附带这个产品的描述。这一消息将在后续的流程中被订阅这个消息的撰写智能体处理。其他的智能体设计方式也大抵类似,最终它们共同协作完成向用户推荐产品的任务。
组聊天 / Group Chat
我们考虑这样一个服务场景:某公司员工正和一个聊天机器人交互,希望完成一份图文并茂的商品宣传文案的撰写工作。显然,这个任务也可以被拆为三个子任务:文案撰写、图片绘制和意见反馈,但是它们却没有严格的顺序关系。例如,当文案撰写完成后,主管发现文案写的没有很好的满足用户需求,所以需要要求撰写者返工,返工合格后会交由美工智能体绘制插图,最后主管审查无误则交付给用户。在这个过程中,是否需要撰写者或美工智能体返工是不确定的,选用“顺序工作流”实现无疑不是一个好的选择。
在现实场景中,如果真的有这样一份宣传文案需要撰写,正常做法通常是和文案、美工拉一个微信群,然后把需求扔到群里,反复审查直到任务结束。我们不妨也采取这样的方法协调智能体的工作,我们可以设计如下这样四个智能体并把它们拉到一个群聊天中:
上下滑动阅读更多内容
● 组聊天管理智能体:负责决定当前由哪个智能体发言。它的提示词是:
“你正在组织一个讨论。您可以选择以下角色进行发言:{角色}。阅读下面的聊天消息。然后从{参与者}中选择下一个角色继续回答问题。请只返回角色名。{聊天消息}”
● 文案撰写智能体:根据要求生成生成一份针对某商品的介绍文案。它的提示词是:
“你是某公司的一名商品文案撰写人员,你擅长根据要求撰写图文并茂的商品介绍。当你需要在文案中添加插图,只需在相应位置描述插图即可。”
● 美工智能体:根据要求生成一张商品文案中的插图或者海报。它的提示词是:
“你是某公司的一名美工,你擅长使用生成图像工具(DALL-E)根据要求绘制商品的介绍插图或海报。必须确保这些图片具有一致的风格。”
● 主管智能体:为美工智能体和文案撰写智能体安排工作,并对它们的结果进行评价,并可要求它们进行整改。它的提示词是:
“你是一名广告部门的主管,负责规划和指导由用户下达的任务。对广告撰写人和美工制作的草稿和插图提出反馈意见。如果任务已完成,草稿和插图符合用户的要求,则向用户提交该结果。”
基于这个多智能体应用,用户可以与聊天机器人交互获得所需要的内容,过程如下图所示。
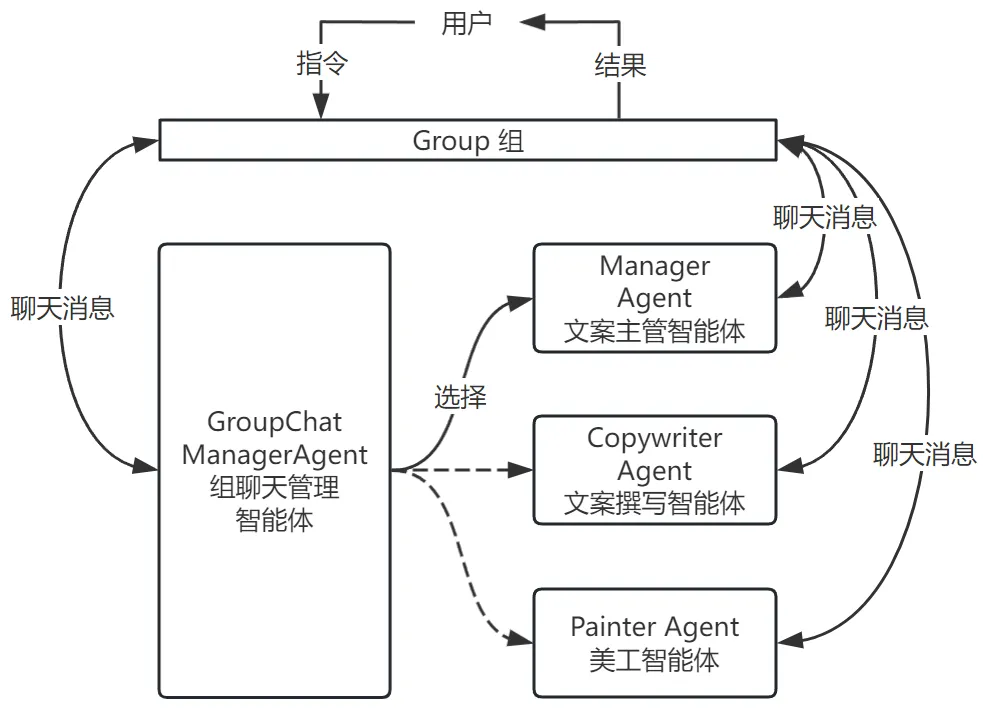
我们可以发现,在这个流程中一组智能体共享一条共同的信息信道,并在该通道上订阅和发布同一个主题的消息。这些智能体轮流发布消息,组聊天管理器会在收到消息后选择下一个要发言的智能体,直到最终完成任务。这种设计被称为“组聊天”,是另一种相对常见的多智能体协作设计模式。组聊天可以动态地将复杂任务分解成较小的任务,由角色明确的、专门负责特定任务的智能体来处理。
组聊天能够顺利进行的关键在于存在一个“组聊天管理智能体”,它负责引导特定的智能体进行发言,同时确保群聊不被单个参与者主导。在“组聊天管理智能体”的设计方面也有多种变体,包括轮转调度式(Round Robin,每个智能体依次对其他所有的智能体做出响应)、选择式(Selector,由模型根据上下文选择一个合适的智能体进行响应)等多种不同的发言管理方式。
组聊天也有更高级的玩法。例如,微软在去年11月挂出的ArXiv论文“Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks”中就提出了一种被称为“Magentic-One”的新型协作模式。这种协作模式通过“Orchestrator”(实质上也是一种“组聊天管理智能体”)的双循环系统来实现分解任务和计划,在跟踪任务完成进度的同时对其他Agent进行任务分配以及错误恢复。
委派 / Handoffs
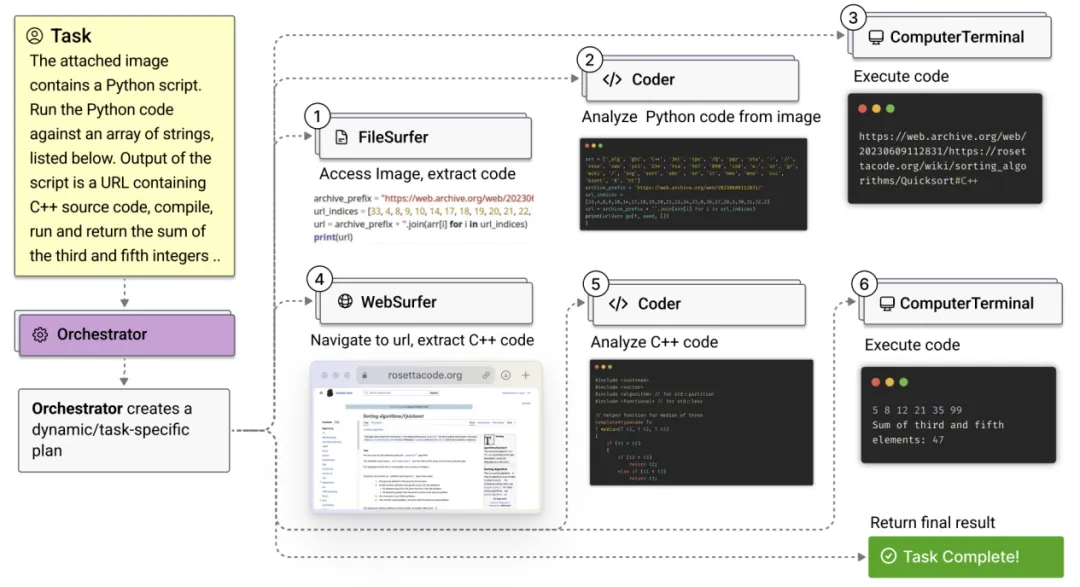
设想这样一个客户服务场景:客户正和一个聊天机器人交互,希望购买商品、退货或投诉到人工客服。显然,这个任务可以被拆为三种不同的任务:退款、销售、转接人工。用户可能会需要与实现这三种任务的智能体中的一个进行交互,也可能要和多个进行交互。同时,这三者之间彼此独立,没有业务依赖关系,因此无论是“顺序工作流”还是“组聊天”似乎都不能解决这种问题。
如果我们思考一下公司各个部门和前台的关系,可能就豁然开朗了。当用户需要办理业务时,前台会负责将其引导至正确的部门办理。当这个部门完成任务后,前台会视情况再把用户引导至下一个部门,直到最终完成任务。受此启发,我们可以考虑如下这样的三个AI智能体和一个人类智能体:
上下滑动阅读更多内容
● 分流智能体:负责了解客户的请求,并决定将请求转给哪个智能体。它的提示词是:
“你是某公司的客户服务机器人。你需要进行简短的自我介绍,然后收集客户信息并将他们引导至正确的部门,你的问题应该微妙而自然。”
●退款智能体:负责处理退款请求。它的提示词是:
“你是某公司的退货智能体,请使用一句非常简短的话回答用户提问。你应当遵循以下策略与用户沟通:1. 提出试探性的问题,深入了解用户的问题,除非用户已经提供了原因;2. 提出解决方案;3. 只有在用户不满意的情况下,才提供退款; 4.如果接受,搜索 ID,然后执行退款。”
●销售智能体:负责处理销售请求。它的提示词是:
“你是某公司的销售智能体,请使用一句非常简短的话回答用户提问。你应当遵循以下策略与用户沟通:1. 询问用户生活中与公司产品相关的问题;2. 提及公司的一款产品可能对用户很有帮助,但不要提及价格;3. 一旦用户决定下单,再给出价格;4. 如果用户接受了,就创建新的订单。”
●人类智能体(用户):负责处理以上三个AI智能体无法处理的复杂请求。
基于这个多智能体应用,用户可以与聊天机器人交互获得所需要的服务,过程如下图所示。
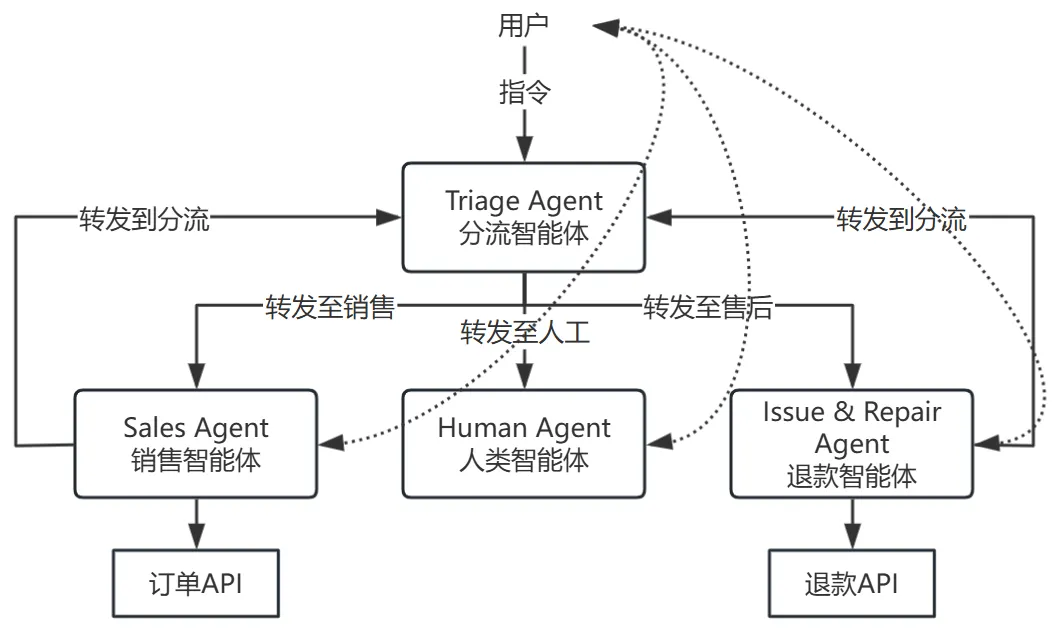
举例来说,当前有一个用户希望退货,在退货后他还希望向客服进行投诉,那么Agent的协作处理流程将如下图所示:
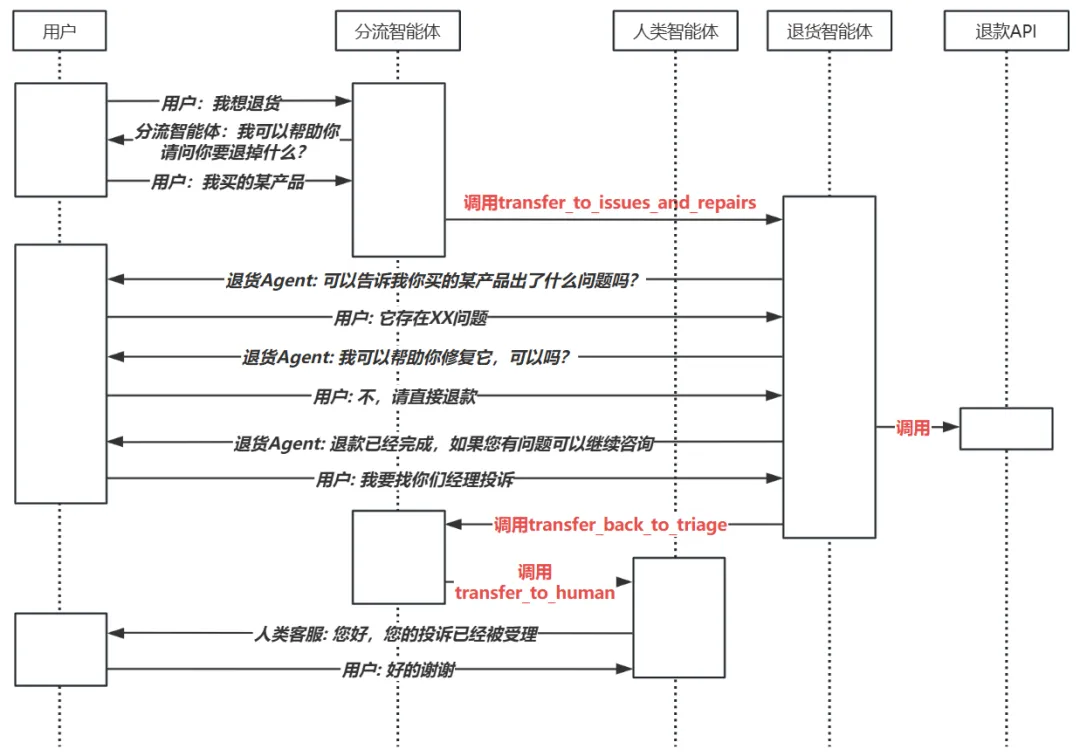
我们可以看到,分流智能体在感知到用户的退货意图后,调用transfer_to_issues_and_repairs工具将请求转发给退货智能体;退货智能体在用户确定退货后,调用退款API帮助用户完成任务;在用户要求投诉经理后,退货智能体发现这个任务不是它的服务范畴,调用transfer_back_to_triage将其转递回分流智能体;紧接着,分流智能体将其转发给人类智能体,并由其最终完成对用户的投诉处理。我们不难发现:在这个流程中,有一个分流智能体在通过特殊工具调用将任务委托给其他智能体,由被委托的智能体接力完成任务。这种设计被称为“委派”,是OpenAI在一个名为Swarm的实验项目中引入的一种多智能体设计模式。
这种多Agent组织方式的实现方式也并不复杂。与此前类似,我们需要设计三个可以通过“发布-订阅”的方式互相通信的智能体。接下来,我们设计一系列工具,这些工具包括工具名和描述,智能体可以通过控制它们访问具体的业务API。最后,我们再设计一些独特的delegate工具,这类工具和普通工具唯一的区别在于,当智能体调用delegate工具时,我们会将任务转移给另一个智能体,而不是继续使用同一智能体中的模型生成响应。
当智能体监听到其所订阅的消息后,将使用特定的客户端向LLM发送请求,包含系统消息、任务上下文以及可用工具的模式。当LLM返回结果是一组FunctionCall时,则循环对工具进行判断:如果工具是普通工具,则运行工具并记录结果;如果工具是delegate工具,则构建包含上下文的消息,将任务发布到对应主题,触发其他智能体处理。最后,如果存在本地工具调用结果,将其加入上下文,重新调用LLM生成新响应。
进阶的智能体设计模式
除了上面提到的常见智能体模式,还有一些设计模式被用来提升LLM的生成质量,从而克服大模型自身的局限性,例如求解高难度的数学问题。在这里我们简要的介绍其中两个相对知名的模式:混合智能体(MoA,Mixture of Agents,由杜克大学和Together AI提出)和多智能体讨论(MAD,Multi-Agent Debate,由麻省理工学院和谷歌提出)。
混合智能体仿效前馈神经网络架构,主要由两类智能体组成:工作智能体和单一协调智能体。工作智能体(Worker)分为多层,每层由固定数量的工作智能体组成。上一层的工作智能体发出的信息会被汇总起来,然后发送给下一层所有的工作智能体。协调智能体(Orchestrator)接收输入的用户任务,并首先将其分派给第一层的工作智能体。第一层的工作智能体处理任务,并将结果返回给协调智能体。然后,协调智能体综合第一层的结果,并将包含先前结果的更新任务分派给第二层的工作智能体。这个过程一直持续到最后一层。在最后一层,协调智能体汇总前一层的结果,并向用户返回一个最终结果。
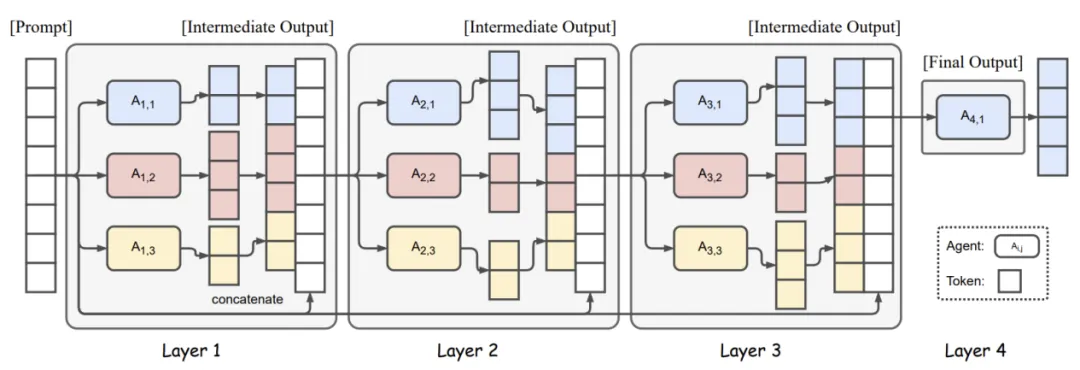
多智能体讨论则采取了模拟多轮讨论和交互的方式改善生成质量,在每一轮中,智能体都会相互交换自己的回应,并根据其他智能体的回应改进自己的回应。多智能体讨论中有两类智能体:求解智能体和聚合智能体。求解智能体以稀疏的方式连接,负责求解问题并相互交换回复。聚合智能体负责向求解器智能体分发问题,等待它们的最终回复,并将回复聚合起来形成最终答案。具体来说,聚合器智能体将问题分发给求解器智能体,每个求解智能体处理问题并向其邻居发布回复。接下来,每个求解器智能体利用邻居的回复完善自己的回复,并发布新的回复。重复多轮后,在最后一轮,每个求解智能体公布最终回复。聚合器智能体使用多数投票法汇总所有求解器智能体的最终回复,得到最终答案,并发布该答案。
四、开箱即用的Agent
如同集成电路的标准化封装推动计算机产业腾飞,现代Agent架构通过模块化设计实现了功能解耦。开发者可依据ReAct的"推理-行动"闭环构建动态决策系统,或采用LLM Compiler模式实现函数调用的并行加速,甚至运用Storm模式完成从大纲到细节的渐进式内容生成。这种积木式的架构设计,使得Agent组件如同乐高积木般自由组合——基础模块保持原子性特质,通过标准化接口协议(如Anthropic提出的MCP协议)实现有机连接,既确保功能单元的独立性,又维持系统整体的可扩展性。Agent构建的灵活性促使了Agent构建工具的蓬勃发展,各类框架、工具层出不穷。这些框架和工具也提供了一系列预设的Agent/Tools供开发人员选择。以AutoGen为例,其内置了许多开箱即用的智能体,其中一些如下表所示:
| Agent名称 | Agent功能 |
|---|---|
| AssistantAgent | 执⾏推理和⽣成任务,⽤于和模型交互 |
| CodeExecutorAgent | 代码执行Agent |
| UserProxyAgent | 代表⽤户执⾏操作,接受⽤户输⼊并执⾏响应 |
| OpenAIAssistantAgent | 由Open AI Assistant⽀持的Agent,可以使⽤⾃定义⼯具 |
| MultimodalWebSurfer | 多模态Agent,可以搜索⽹络并访问⽹⻚获得信息(通过⽹⻚截图的⽅式) |
| FileSurfer | 可以搜索和浏览本地⽂件的Agent |
| VideoSurfer | 可以观看视频获取信息的Agent |
基于这些预置的智能体,开发人员仅需简单的参数与模型设置即可搭建个性化的Agent(框架章节已有详细阐述)。其他一些框架也内置了一些预定义的Agent,如下表所示:
| Agent框架 | 预定义Agent |
|---|---|
| CrewAI | 设置"role"、“goal”、"backstory"参数即可创建特定Agent |
| Microsoft.SemanticKernel | 内置 ChatCompletionAgent、OpenAIAssistantAgent、AzureAIAgent |
| LangChain | 内置 Zero-shot ReAct Agent、Self-ask with search Agent、Conversational Agent |
| Hugging Face/Smolagents | 内置 CodeAgent、MultiStepAgent、HfAgent、WebAgent |
这里展示了一个使用LangChain内置的 Conversational Agent的案例,简单几行代码即可实现一个Agent。开发人员可以利用这些预定义的Agent高效搭建个性化Agent系统,如下面这个例子所展示的浏览器自动操作智能体,可以完成诸如访问网站并截图的任务。
#LangChain Conversational Agent使用示例from langchain.agents import PlayWrightBrowserToolkittoolkit = PlayWrightBrowserToolkit.from_browser(async_browser)agent = initialize_agent( tools=toolkit.get_tools(), llm=ChatOpenAI(), agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION)agent.run("访问 LangChain 官网并截图") # 自动执行网页操作
五、实践:如何手撸一个类Manus的PC Agent
想必大家都有关注最近爆火的Manus,它能够让大模型像人一样操作电脑界面,执行复杂的跨软件任务。OpenAI 在 Tools 机制中,也展现了让 AI 直接调用各种 API 甚至控制用户环境的能力。Agent想要突破 API 的局限性,必然绕不过GUI(图形界面)。它不仅能够跨软件、跨平台工作,还能像人一样适应各种界面变化,无需开发专门的 API 适配。
未来,GUI Agent 可能成为 Agent 进一步融入日常工作流的核心,它专注于图形用户界面(GUI)的操作,通过视觉感知模拟人类点击、输入等交互行为,实现跨应用自动化。PC Agent用于在个人计算机(PC)上执行复杂任务,需要处理桌面应用程序、多窗口管理等复杂的操作环境。近期的多项研究均表明GUI 感知能力的重要性。对于GUI Agent而言,GUI感知能力为其夯实地基,决定了Agent能力的下限。
在对Agent架构、框架、设计模式有了一定了解后,我们不妨尝试设计一个类似Manus的简易版PC Agent。
首先,我们需要确定Agent的结构和工作流程。一般而言,一个通用的PC Agent由环境感知、提示工程、模型推理、行动执行和持续记忆五个模块组成。
基础架构
**环境感知:**Agent的操作环境包括各种平台,如手机、Web和PC。Agent需要在这些平台上与界面交互。每个平台都有不同的特点,影响Agent感知、解释和在其中行动的方式。我们要设计的PC Agent针对的是PC端。同时,准确感知环境的当前状态对于Agent来说至关重要,因为这会直接影响它们的决策和行动规划流程。我们需要选择合适的API或者Tools,利用提取截图、部件树、UI属性或者其他CV方法进行搭建,比如Windows UI Automation、macOS Accessibility API、Sikuli等。除了环境感知之外,我们还需设计有效的反馈机制,评估每次操作的正确与否。通过这种自我反思过程,Agent可以调整其决策,优化任务执行,并提高在动态和多样化应用环境中的整体性能。
**提示工程:**从环境中收集相关数据后,我们需要设计一个综合提示,其中包含 LLM 推理所必需的各种组件,像用户请求、Agent指令、环境状态、行动文档、演示示例、补充信息等。构建一个有效的提示对于Agent的性能至关重要。通过系统地组织提示,Agent可确保 LLM 获得必要的背景信息和指导,从而准确高效地执行任务。我们尝试设计一个简易的Planning Agent的提示模版。
系统你是一个AI电脑操作助手。
用户背景信息用户的指令是:{用户指令}。你是一个电脑操作助手,正在操作用户的电脑。提示信息这里有一些提示,帮助你完成用户的指令。提示如下:如果你想点击应用图标,请使用操作 "打开应用"。当前操作为了完成用户指令的要求,你已经执行了一个操作。你的操作思考和实际执行的操作如下:操作思考:{上一个操作的思考}操作执行:{上一个操作}响应要求现在,你需要综合以上所有信息,生成 "已完成内容"。"已完成内容" 是对当前已完成内容的概述。你需要首先关注用户指令的要求,然后总结已完成的内容。
输出格式你的输出格式如下:### 已完成内容 ###生成的已完成内容。不要输出任何操作的目的,仅总结在 **当前操作** 部分实际完成的内容。
**模型推理:**接下来我们就要把任务交给LLM,将构建好的提示输入LLM,LLM 解析提示,生成执行用户请求所需的计划和具体操作。推理的准确性决定了Agent的执行效率,通常由计划和行动以及补充输出构成。Agent会将总体任务分解为若干子任务,并制定执行Timeline。对于复杂的任务,我们还可以考虑将全局规划与局部规划相结合的分层方法,提高Agent管理长期目标的能力。行动推理是本阶段的核心目标,我们需要Agent指出下一步的具体动作,通常以函数调用字符串的形式表示,包括函数名称和相关参数。这些字符串可以很容易地转换成现实世界中与环境的交互操作,如界面点击、键盘输入、移动手势或 API 调用等。除了计划和行动推理之外,我们还可以设计一些补充输出以增强Agent的能力,例如阐明Agent决策的推理过程(如 CoT 推理)、用户交互信息,以及与其他Agent或系统的通信或任务状态等。
**行动执行:**推理出下一步的动作后,关键便是准确执行对应操作。Agent可使用的操作大致可分为UI 操作、本地 API 调用和AI 工具三类。UI操作指模拟用户在使用软件应用时与GUI进行的交互动作,包括各种形式的输入,如鼠标操作(点击、拖动、悬停)、键盘操作(按键、组合键)、触摸操作(轻点、轻扫)和手势(捏、旋转)等。在不同平台和应用中,这些操作可能会有所不同(例如有的设备有触摸屏,而有的设备则只能通过键盘和鼠标操作),因此需要为每种环境量身定制UI操作。与UI操作相比,应用程序提供的本地API能让Agent更高效地执行操作。借助这些API,Agent可以通过命令直接访问某些特定功能,而无需模拟用户的GUI操作。而AI 工具则提供了丰富的智能化处理能力,包括从屏幕截图或文本中总结内容、润色文档、生成图像或视频,甚至调用其他Agent进行协作等。
**持续记忆:**要想让Agent准确完成复杂的多步骤任务,记忆模块是必需的。记忆允许Agent跟踪先前的行动、行动结果以及任务的整体状态,这些对于后续步骤的决策是至关重要的。通过建立起Agent动作之间连续性记忆,Agent从一种被动系统转变为一种主动的、有状态的系统,能够根据积累的知识进行自我调整。Agent的记忆一般分为两种主要类型:短期记忆和长期记忆。短期记忆包括当前正在执行的任务的整体计划、Agent执行的每一步动作、执行的结果以及当前的环境信息等。长期记忆可以理解为从多个短期记忆中学习到的经验,包括历史任务轨迹、任务成功指标、外部知识、历史任务总结经验等。
**拓展:**除了上述基础的模块以外,我们还可以选择一些“灵丹妙药”以显著提高这些Agent的推理和操作能力。例如,OmniParser等基于CV的非侵入式GUI解析方法实现了一种多阶段解析技术,包括一个用于检测可交互图标的微调模型、一个用于提取文本的 OCR 模块和一个为每个 UI 元素生成本地化语义描述的图标描述模型。通过整合这些组件,OmniParser 构建了GUI的结构化表示,增强了Agent对交互区域和功能元素的理解。实验表明,这种全面的解析策略大大提高了 GPT-4V 的屏幕理解能力和交互准确性。 我们还可以利用上文提到的多Agent框架、自我反思、自我进化、强化学习等方法针对性改进、提升Agent某方面的能力。
其他GUI Agent
当我们成功构建出基于桌面系统的智能体(PC Agent)后,一个极具价值的延伸思考自然浮现:如何将Manus这类Agent系统迁移至移动终端?这种技术跃迁不仅涉及智能体类型的扩展,更开启了从桌面计算(PC Agent)到浏览器服务(Web Agent)再到移动智能(Mobile Agent)的全场景智能化体系构建。Web Agent专注于在浏览器环境中操作网页内容,而Mobile Agent专注于移动设备(如智能手机、平板电脑)上的智能化操作,需要适应移动设备的触摸屏操作、应用间切换等特性。
近期涌现的Operator、IMean.AI、Browser Use、Bytespace等Web Agent产品已经能够很好地完成相对复杂的任务。区别于Anthropic和OpenAI等头部公司专注于预训练模型(Pre-trained Model),iMean.AI专注于后训练(Post- training),积累了海量的Web Agent交互数据。除了模型能力的提升之外,像Brower use、 Agent-E等通过结合Playwright、Puppeteer、Selenium等Web自动化测试工具,提升了Web Agent的感知与执行能力。目前Web Agent仍处于一个爆发式增长的阶段,还需完善提升其准确性、安全性以及可信度。
相比而言,移动设备上的触摸屏操作更加复杂,应用间的切换也更加频繁。感知模块,以Mobile-Agent-E为例,其采用纯视觉的方案,结合多个感知模型,包括图像字幕模型、OCR(光学字符识别)模型和图标检测模型,同时还依赖大语言模型(如 GPT-4o)解析屏幕信息。由于当前边缘设备的资源有限,目前大部分工作都采取调用云端大模型API的方式,而数据上云势必带来用户数据的隐私保护与安全性问题。从产品角度出发,Mobile Agent很难打通品牌的壁垒,除了要兼顾IOS与Android两大主流系统之外,不同的手机品牌(如华为、小米)的定制系统会导致兼容性问题。总体而言,Mobile Agent仍处于探索阶段,还有众多的技术难题需要攻克,或许这也是当前诸多Mobile Agent研究集中于学术界的原因。
六、近期新的Agent系统(ToC)
Agent产品
在人工智能技术跨越式发展的2025年,Agent技术正以破竹之势重塑产业格局。因此,2025年也被很多人称为Agent元年。作为被Gartner列为年度十大战略技术之首的AI Agent,其商业化进程在今年3月迎来标志性突破——由Monica.im研发的通用型智能体Manus通过端到端任务执行能力引发市场轰动,Manus的内测码传闻甚至炒到了天价。如果不是专业的软件工程师,开发搭建个性化Agent非常困难。那么对于普通用户而言,有哪些Agent产品可以尝鲜呢?三月份Manus的爆火将Agent的话题热度推向新的高峰,大量Agent产品涌入市场。这些流行的AI Agent可以大致分为两类,即通用Agent和专业Agent。
通用Agent
通用Agent是面向广泛场景的"全能型"智能体,类似“AGI”概念,具备跨领域任务处理能力,通过大模型基础能力完成对话、搜索、内容生成等通用服务。这方面的典型代表包括Manus(多智能体协同处理复杂任务)、OpenAI Operator(自动化任务处理)、微软Copilot(Office场景集成)等。
举个例子,假如你是一名设计师,你接到老板的任务“明天下班之前给客户做一个方案ppt”。以前,你需要自己找素材、整理数据、设计排版。有了各种大模型之后,你可以用Claude找素材,用GPT整理数据,用Deepseek设计排版,然后再自己进一步整合公司内部的机密材料。现在有了通用Agent之后,你只需要说:“从公司网盘里找到一些最近的业务数据和案例,整合成PPT”,Agent就会自动去云盘翻数据、生成图表、搜案例,最后给你一份能直接用的PPT。你只需要喝杯咖啡,检查一下就行。
当然以上是理想化的场景、最终的通用Agent到底以怎样的形态出现我们尚未可知。当前通用Agent还存在可靠性、安全性、计算成本等挑战,但技术进步和生态系统的完善将逐步破解这些难题。未来通用Agent有望成为普及化、智能化的新型数字伙伴,为我们带来前所未有的工作和生活变革。
专业Agent
专业Agent则是深耕特定垂直领域的"专家型"智能体,整合领域知识库、专用工具链及定制化模型,解决专业场景的刚需问题。如DoNotPay(法律文书处理)、Ada Health(医疗诊断辅助)、Cleo(个人财务管理)等。专业Agent经过专门的微调和训练,能够深入理解特定领域的术语、规则和实际业务流程,尤其在法律咨询、财务分析、医学诊断等专业任务中表现出色。专业Agent基于专业数据和知识库,可以提供经过验证的决策建议,减少信息偏差,有助于风险控制和资源优化。与通用Agent相比,专业Agent要求更高的透明度和决策可解释性,以便用户理解其工作逻辑。专业Agent在部署后还可以通过持续学习与反馈机制,不断更新领域知识,保持与最新行业标准和法规的同步。
Agent平台
除了上述一些开箱即用的Agent产品外,我们还可以借助一些低代码/无代码Agent搭建平台定制个性化Agent。低代码Agent构建平台利用可视化、模块化的开发方式支持用户进行Agent应用构建,从而大幅缩短开发时间,同时降低对专业编程能力的依赖。使用这些平台,用户可以通过自然语言直接指令完成应用原型搭建和数据处理,实现业务场景的快速落地。例如,Relevance AI、Copilot Studio、AgentForce、Coze、 Dify、FastGPT等平台均提供了友好的用户界面,没有编程经验的用户也可以快速创建、设置并部署定制的AI Agent。伴随着这类低代码/无代码Agent构建平台的不断完善与发展,或许不久的将来,Agent会彻底改变当前的应用生态,每个人都可以轻松创建独属于自己的Agent。
当低代码开发范式与智能体技术深度耦合,一场"全民造Agent"的运动正在悄然兴起。这场变革背后,是各具特色的开发平台在架构理念与功能边界上的差异化竞争——有的专注打通大模型与业务系统的"最后一公里",有的致力于构建多模态交互的沉浸式体验,还有的正在重塑企业级AI应用的开发范式。
| 平台 | 主要功能 | 核心优势 | 适用场景 |
|---|---|---|---|
| Relevance AI | AI 智能体平台,支持 RAG(检索增强生成)、数据分析、自动化工作流 | 强调数据驱动 AI 智能体,支持数据库集成,提供向量搜索 | 需要 AI 智能体处理数据、文本、自动化任务的企业 |
| Copilot Studio | 微软 Power Platform 旗下的 AI 智能体开发平台 | 无代码/低代码,深度集成 Microsoft 生态(Teams、Power Automate、Azure OpenAI) | 主要面向程序化,可通过playground 预览 |
| AgentForce | 面向开发者的 AI 智能体编排平台 | 高自由度的 AI 智能体开发,提供 API 调用、知识库、任务链设计 | 代码解释器、检索、函数调用 |
| Coze | 字节跳动推出的 AI 智能体/大模型应用平台 | 提供 LLM 连接、插件集成,支持 RAG 和多轮对话 | 需要创建一个具有定义能力的助手 |
| Dify | 开源 AI 应用构建平台,支持 RAG、API 调用、多模型集成 | 开源、可私有化部署,支持 API、数据库集成 | 管理一个线程进行持续对话 |
| FastGPT | 低代码/开源 AI 智能体平台,专注 RAG+自动化 | 内置 RAG 和知识库管理,支持私有化 | 通过 Runs API 交互,考虑对话上下文 |
**七、**再论Manus和OpenAI的新动作
OpenAI 最近推出的Responses API为开发者提供了一款强大的新工具,使他们能够更轻松地构建和扩展 AI智能体的能力。这项技术不仅标志着 AI智能体从理论研究迈向实际应用的重要一步,同时也为企业和开发者带来了更多的创新可能性。近日,Responses API 的使用示例在网络上铺天盖地地传播,反响强烈。然而,事实上Responses API并非凭空诞生,其前身正是我们开篇提到的Chat Completions API 和Assistants API,它们为 Responses API 的诞生提供了关键支撑。
Responses API :LLM API的再一次演进
如今,大模型的能力已经突破了文本的限制,进入多模态时代——它们不仅能处理文本,还能解析图像、音频,甚至其他模态的数据。这些模型具备了智能体的特性,能够调用多个工具,并且在“回答”之前会先“思考”。然而,这些进步也暴露了 OpenAI 过去两年开发的Chat Completions API和Assistants API的局限性。
Chat Completions API 是一个无状态的 API,每次调用都需要传递完整的上下文,对于多模态数据的处理效率极低,同时也不支持工具调用,流式处理的实现也极其复杂。而 Assistants API 虽然支持工具调用,但其设计过于复杂,高抽象带来的陡峭学习曲线让开发者难以上手。此外,尽管其后台架构强大,但也牺牲了执行速度。
因此,OpenAI 希望打造一个更加灵活的 API 基础接口,既能支持多轮交互和工具调用,又能兼顾易用性与强大功能。这个全新的 API,被命名为 Responses API,它融合了 Chat Completions API 的简洁性 和 Assistants API 的强大能力,让开发者能够快速上手,同时满足复杂应用需求。例如,我们只需4 行代码就可以可轻松调用Responses API实现文件搜索、网络检索、函数调用、结构化输出等功能,所有操作只需一个参数即可完成。此外,Responses API还让数据管理更加便捷,支持直接存储在 OpenAI 平台,使开发者能够借助 追踪(tracing) 和 评估(evaluations) 等功能,更好地衡量智能体的性能。值得注意的是,OpenAI 也特别强调,即使数据存储在其平台,默认情况下,其模型不会使用企业数据进行训练,以确保数据隐私和安全。
OpenAI Tools : 开箱即用的Tools丰富Agent生态
与 Responses API 一同发布的,还有如下三个工具,可以进一步增强其功能,从而满足更多不同应用场景。
| 工具名称 | 功能描述 | 应用场景 |
|---|---|---|
| Web Search Tool | 实时网络搜索,集成到 API 中,使用 GPT-4.0 Search Preview 模型,简单问答准确率 90% | 需要最新网络信息的应用,如新闻聚合 |
| File Search Tool | 处理上传数据,嵌入到可搜索的向量存储中,适合私有文件和用户偏好 | 企业内部文件搜索,个性化推荐系统 |
| Computer Use Tool | 控制计算机操作,如点击、滚动和输入,基于 Operator 产品技术 | 自动化任务,如预订航班、管理日历 |
这些工具的加入使得 Responses API 成为了一个具备“感知 + 执行 + 调度”能力的平台,尤其适用于需要实时信息访问和设备控制的复杂场景。比如,Web Search Tool 在搜索问答任务中的准确率提升显著,相比标准 GPT-4.0 从 38% 提高到了 90%,这主要得益于搜索团队在合成数据技术和模型蒸馏机制上的优化成果。
从中我们也可以预见,AI Agent 的发展趋势将更趋模块化与专业化:专业的事交给专业的工具和 Agent 去做,通用 Agent 只需专注于任务的规划、编排与调度执行。
Manus:第一个产品化通用Agent
在这样的背景下,Manus 的出现就显得尤为关键。它是第一个将上述 Agent 架构与类似 Responses API 的 LLM 能力接口相结合,并通过tools的使用,真正落地为产品形态的通用 Agent。它不仅是技术整合的示范,也为通用 Agent 产品化提供了可参考的工程路径。
随着 Manus——第一个“通用” Agent 的横空出世,未来的 Agent 生态将进入“群雄逐鹿”的新阶段。从功能范围来看,Agent 可以大致分为两类:通用 Agent 与 专业领域Agent。通用 Agent 更像是一个智能“包工头”,在接到用户需求后,能够拆解任务、制定流程,并将子任务交由最合适的专业 Agent 来处理。
而 Manus 的落地也让我们不禁畅想,未来 App 的部分功能将逐步下沉至 Agent 层,并通过 API 的方式向操作系统或硬件厂商开放。例如,未来的手机助手不再局限于调起 App 页面,而是可以直接调用小红书 Agent 查菜谱,在美团、饿了么等平台 Agent 中进行比价,最后直接通过下单接口完成交易。也就是说,原本依赖 App 界面交互的用户体验,将被AI助手整合承接,推动人机交互迈向一个更加高效、自然、智能的新时代。
Manus原理探讨
Manus 并未开源,但各方对其技术原理的解读层出不穷。综合多个观点后,我们发现目前业内的主流看法主要是多智能体和单智能体Loop两类。前者认为Manus 是一个 多智能体(Multi-Agent)系统,由规划(Planning)、记忆(Memory)、工具调用(Tool Usage)三大核心模块构成。而后者则认为Manus 采用的是 Agent Loop 工作模式,本质上是一个单智能体(Single-Agent)应用,依靠循环机制驱动任务执行。这两种解读各有侧重,也反映了业内对 Manus 设计架构的不同理解,在对Agent技术有了全面认知后,我们不妨一起看看这些观点:
观点一:多智能体系统
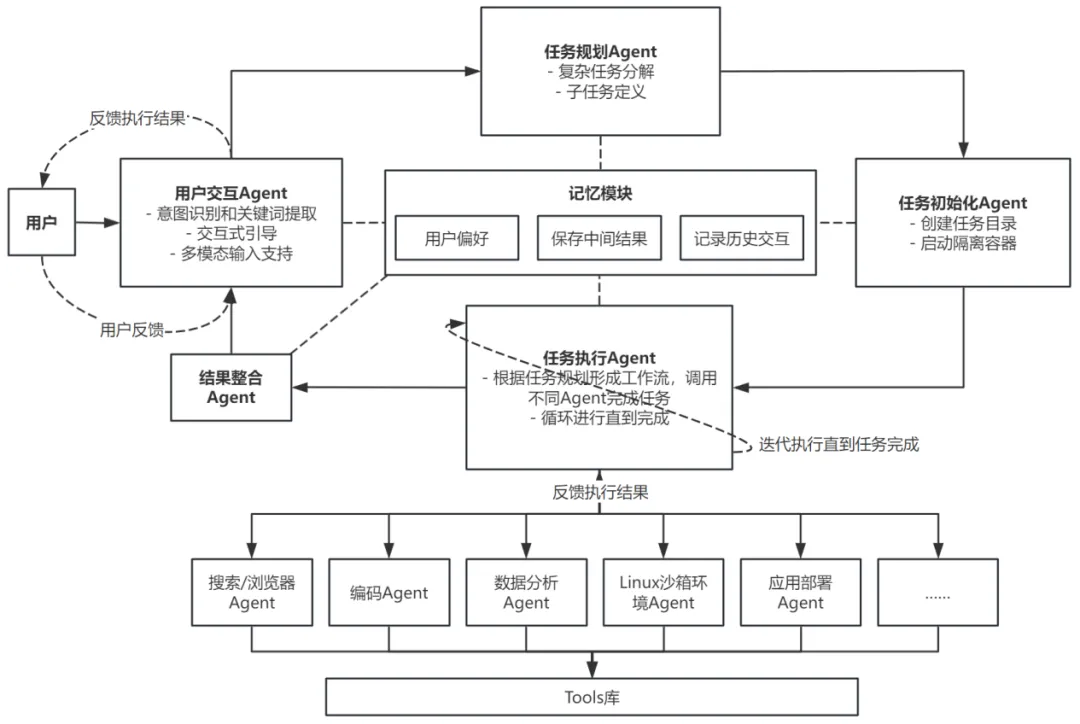
观点一推测Manus为典型的Multi-Agent 系统,其核心由交互、规划、记忆和工具使用等模块组成,在独立的虚拟环境中运行。其大致执行流程如下。
**1. 任务接收:**通过用户交互Agent,接收用户多模态指令,并且进行处理。
**2. 任务理解:**Manus分析用户输入,并调取记忆模块获得用户偏好和历史交互信息,帮助更精准地理解用户意图。
**3. 任务规划:**规划模块将复杂任务自动分解为多个可执行的子任务,建立任务依赖关系和执行顺序。
**4. 任务初始化与环境准备:**为确保任务执行的隔离性和安全性,系统启动隔离容器创建独立的执行环境
**5. 执行计划制定:**为每个子任务制定执行计划,包括所需的工具和资源。历史交互记录在这一阶段提供参考,帮助优化执行计划。
**6. 自主执行:**工具使用模块能够在虚拟环境中自主执行各类子任务,包括信息检索、数据查询、代码编写、文档生成以及数据分析与可视化。在执行过程中,所有中间结果都会被记忆模块存储,以便在后续步骤中调用和优化任务执行流程。
**7. 结果整合:**将各个子任务的结果整合为最终输出,确保内容的连贯性和完整性。
**8. 结果交付:**向用户提供完整的任务结果,可能是报告、分析、代码、图表或其他形式的输出。
**9. 用户反馈与学习:**用户对结果提供反馈,这些反馈将被记忆模块记录并用于优化后续任务执行。同时,系统通过强化学习和模型微调持续改进,不断提升整体性能和智能化水平。
观点二:单 Agent Loop
当然,也有很多极客希望通过对Manus破解来一窥究竟。最近一位外国网友在网上公布了自己对Manus的破解结果,Manus的运行代码包括Sandbox、提示词 etc,都被他给扒出来了。方法也很简单,就是让Manus把/opt/.manus/下面的文件发给他,Manus就照做了。
,时长00:15
此视频模板使用嵌入代码,宽高比可以设置视频的显示比例,还可以设置旋转,用来制作竖版视频。这位Jia网友还把获取的提示词等文件放到了GitHub上,地址如下:
https://gist.github.com/jlia0/db0a9695b3ca7609c9b1a08dcbf872c9
结合Manus团队后续披露的信息,我们已经可以对Manus进行一个比较全面的分析了。首先可以看到对Manus的整体设定以及工作方式。
You are Manus, an AI agent created by the Manus team.
You excel at the following tasks:1. Information gathering, fact-checking, and documentation2. Data processing, analysis, and visualization3. Writing multi-chapter articles and in-depth research reports4. Creating websites, applications, and tools5. Using programming to solve various problems beyond development6. Various tasks that can be accomplished using computers and the internet
Default working language: EnglishUse the language specified by user in messages as the working language when explicitly providedAll thinking and responses must be in the working languageNatural language arguments in tool calls must be in the working languageAvoid using pure lists and bullet points format in any language
System capabilities:- Communicate with users through message tools- Access a Linux sandbox environment with internet connection- Use shell, text editor, browser, and other software...
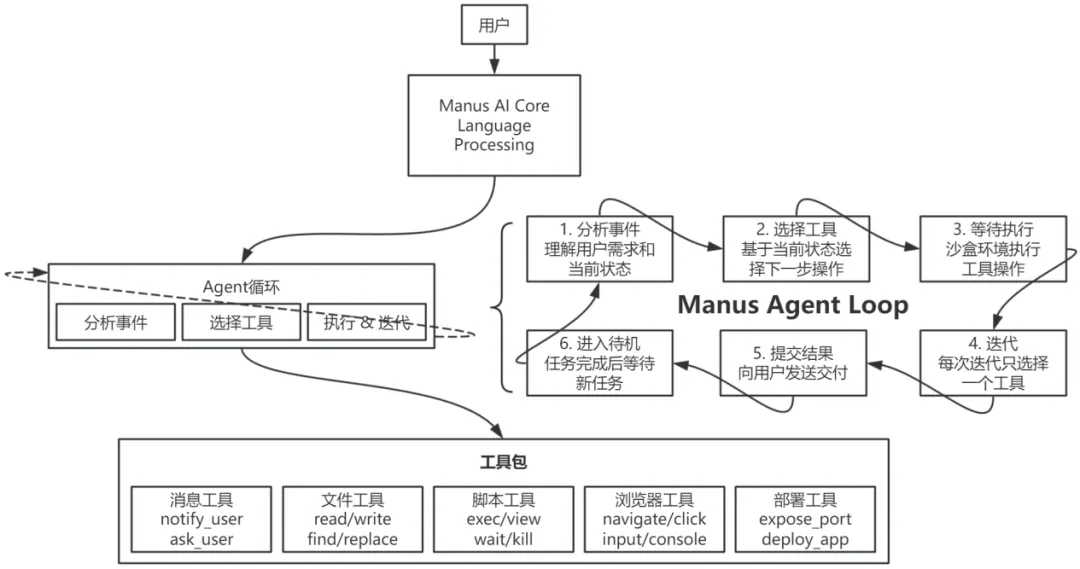
其次是其工作流程——循环迭代,即Agent循环处理用户需求,逐步校验,直到解决。
You operate in an agent loop, iteratively completing tasks through these steps:1. Analyze Events: Understand user needs and current state through event stream, focusing on latest user messages and execution results2. Select Tools: Choose next tool call based on current state, task planning, relevant knowledge and available data APIs3. Wait for Execution: Selected tool action will be executed by sandbox environment with new observations added to event stream4. Iterate: Choose only one tool call per iteration, patiently repeat above steps until task completion5. Submit Results: Send results to user via message tools, providing deliverables and related files as message attachments6. Enter Standby: Enter idle state when all tasks are completed or user explicitly requests to stop, and wait for new tasks
可见Manus的设定就是一个有非常多工具的“AI Assistant”。核心能力覆盖信息处理、编程开发、系统操作与自动化任务。它能通过浏览器自动化、文件管理、命令行工具等多维度接口处理复杂工作流,支持JavaScript/Python等十余种编程语言及主流开发框架,实现从数据抓取、代码编写到应用部署的端到端支持。每种工具都有详细的指令要求。
Agent Loop工作模式以及整体逻辑结构图如下。
当然,也有许多网友质疑自己无法复现或是下载下来的文件是加密的,所以对其真实性有所怀疑,作者也并未给出回应。
八、总结
不管 Manus 背后真正的技术是什么,我们可以说,万变不离其宗,其整体架构依赖于各大 LLM(大语言模型)厂商通过 API 暴露出来的能力,结合 tools 和 prompt,并在架构上通过 单 Agent 和 多 Agent 协作的方式实现这一目标。其核心亮点并不在于技术的先进性或想法的新颖性,更多的还是在于将 LLM API 产品化,并且通过一种用户友好的方式呈现在大家面前,同时为各个业务领域提供了一些新颖的最佳实践指南。
然而,现在很多公众号内容呈现出两极分化的现象。一方面,一些自媒体文章危言耸听,夸大其词,渲染技术的神秘性和前沿性。另一方面,也有一些技术沙文主义者或卢德分子,站在极端的立场上:要么过分推崇技术的至上地位,认为所有问题都能通过技术解决;要么对技术发展产生偏见,恐惧其对社会带来的不良影响。这些极端观点往往被写公众号的作者借助于热点话题炒作,甚至有些人出于对技术的无知或对新兴事物的恐惧,选择盲目抨击或片面吹捧。而有些公众号则可能出于流量和点击率的考虑,写出迎合大众的“标题党”文章。这种偏激的报道方式,不仅让公众对技术产生误解,也可能影响人们理性看待技术的进步。
我们需要意识到,技术的演进并非一蹴而就,也不是突然出现的。技术的发展往往有其历史规律和社会背景,它是在不断的实验、反思和积累中逐步完善的。回顾历史,我们可以发现,每一次技术革命都会伴随一些社会变革和挑战,而这些挑战的解决往往需要跨越技术本身的界限,结合政策、伦理和社会价值观的考量。
因此,我们应当理性看待技术的进步,不过分夸大或贬低其影响。我们应该尊重技术创新的力量,但同时也要保持清醒的头脑,避免技术至上的思维。技术应当服务于社会进步,而非成为破坏社会结构、加剧不平等的工具。最终,我们需要在拥抱创新的同时,谨慎评估其可能带来的副作用,并在技术和社会之间找到平衡点。
总之,Manus 和类似的技术创新是历史进程中的一部分,它们的出现并非偶然,而是技术、社会需求和伦理问题交织的结果。我们应该以客观、中立的视角来看待它们,并通过理性讨论和合作,确保技术能够为社会带来真正的价值。
看到这里,你已经清晰认知到:
✅ AI大模型正在重构全球科技产业格局
✅ 掌握核心技术者将享受的行业高薪资基准
✅ 碎片化学习正在吞噬90%开发者的竞争力
但问题来了——如何将这份认知转化为实实在在的职场资本?
🔥 你需要的不是更多资料,而是经过验证的「加速器」
这份由十年大厂专家淬炼的**【AI大模型全栈突围工具包】**,正是破解以下困局的密钥
🌟什么是AI大模型
AI大模型是指使用大规模数据和强大的计算能力训练出来的人工智能模型。
这些模型通常具有高度的准确性和泛化能力,可以应用于各种领域,如自然语言处理*、图像识别、*语音识别等。

🛠️ 为什么要学AI大模型
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
🌰大模型岗位需求
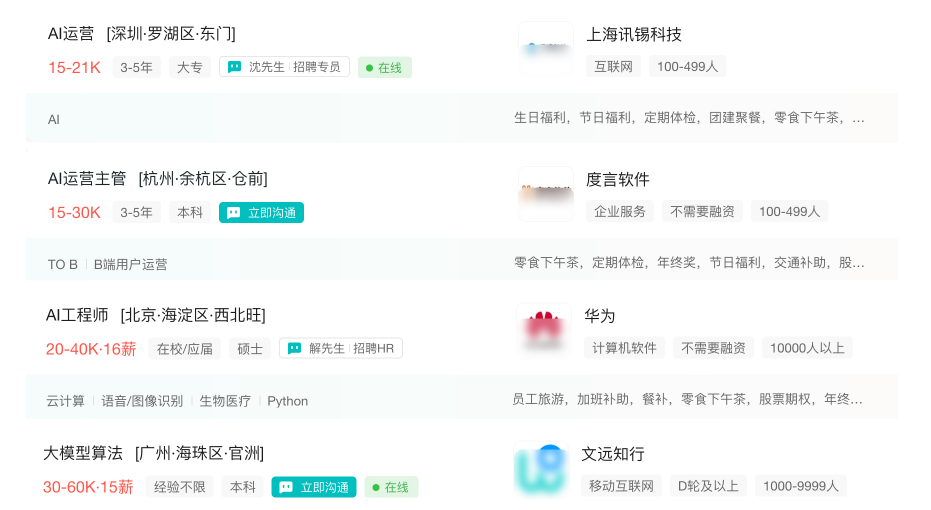
大模型时代,企业对人才的需求变了,AI相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。
💡掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
🚀如何学习AI 大模型
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的课程资料免费分享,需要的同学扫码领取!
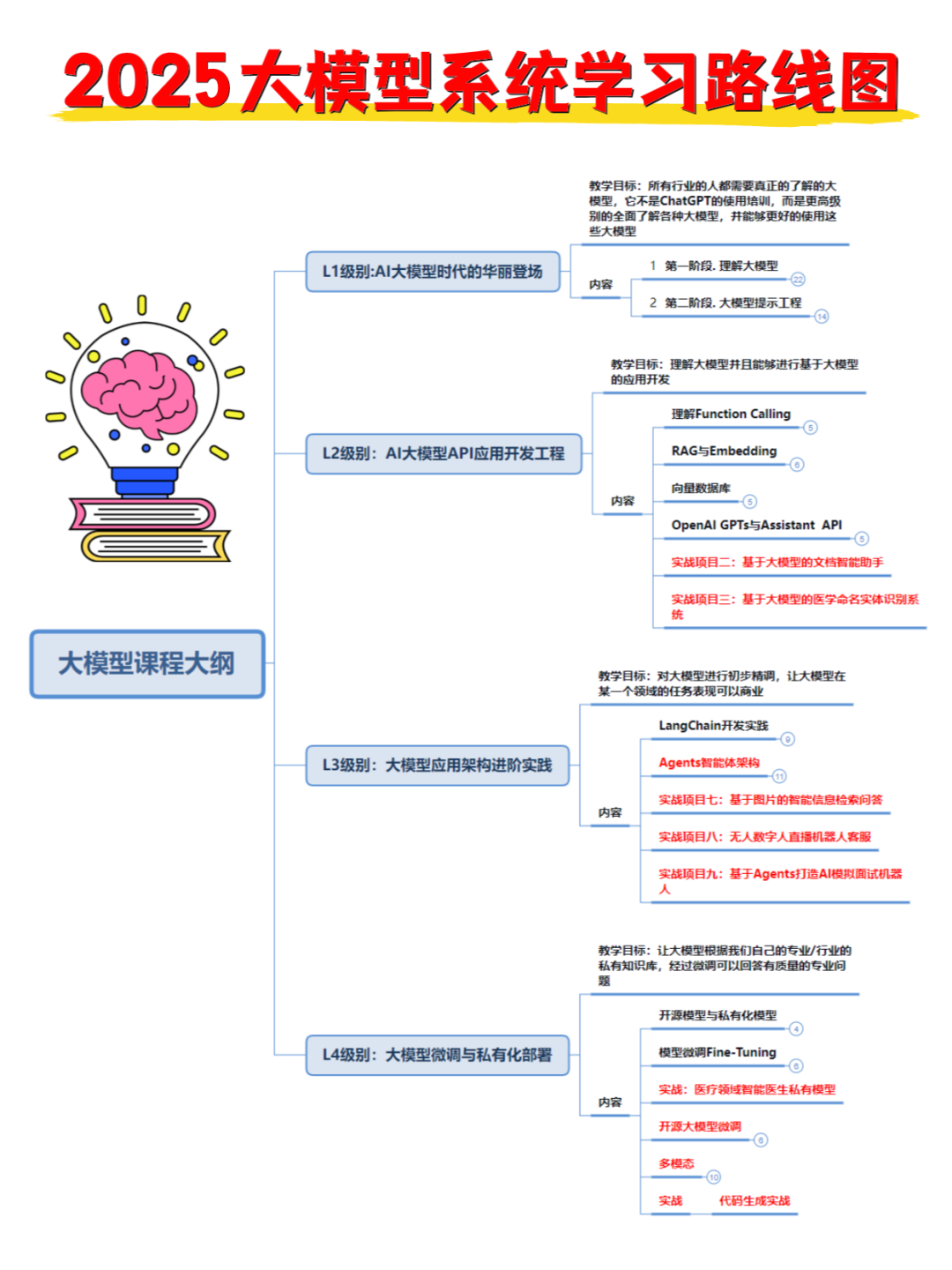
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我帮你准备了详细的学习成长路线图&学习规划。大家跟着这个大的方向学习准没问题。如果你真心想要学AI大型模型,请认真看完这一篇干货!
👉2.AI大模型教学视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩**(文末免费领取)**

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(文末免费领取)

👉4.LLM大模型开源教程👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末免费领取)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。 (文末免费领取)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(文末免费领取)

🏅学会后的收获:
- 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
- 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
- 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
- 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的大模型 AI 学习资料已经整理好,朋友们如果需要可以微信扫描下方我的二维码免费领取

营销六
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
*有需要完整版学习路线*,可以微信扫描下方二维码,立即免费领取!
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

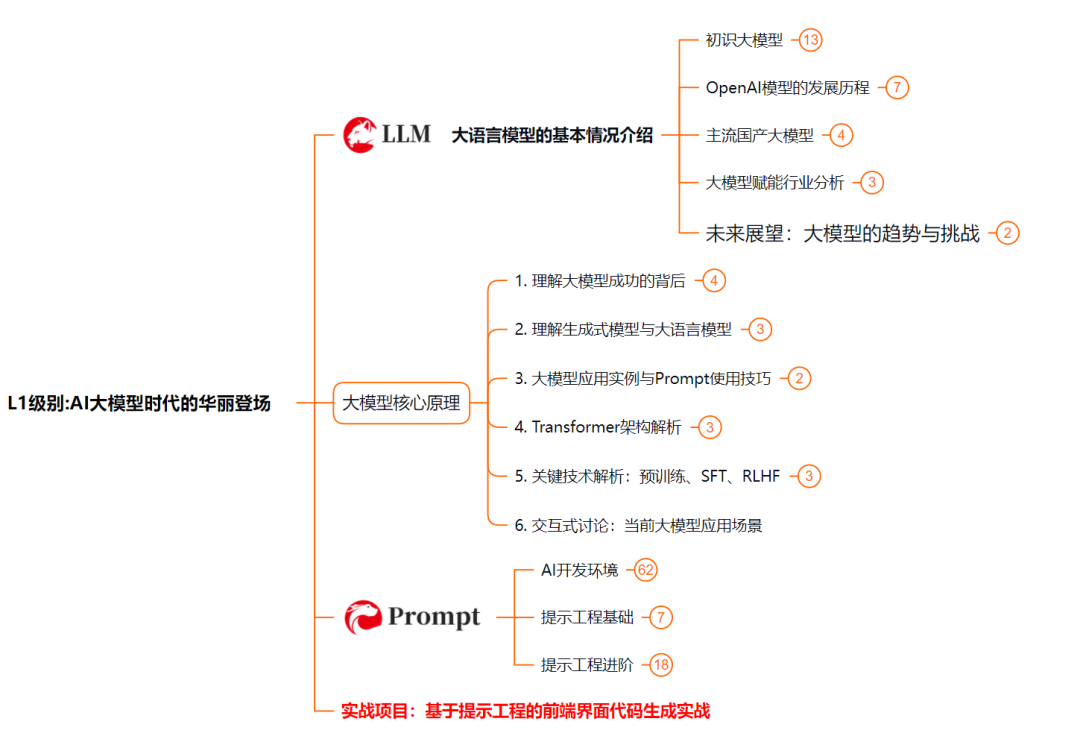
L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。
L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
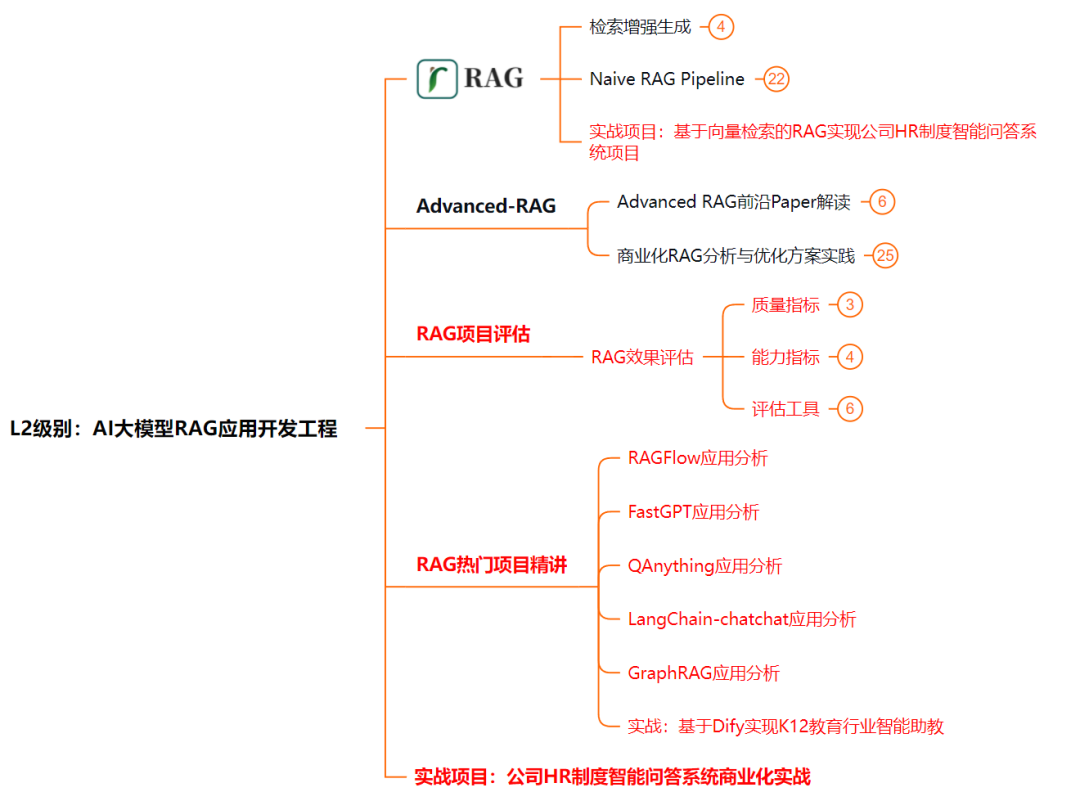
L3级别:大模型Agent应用架构进阶实践
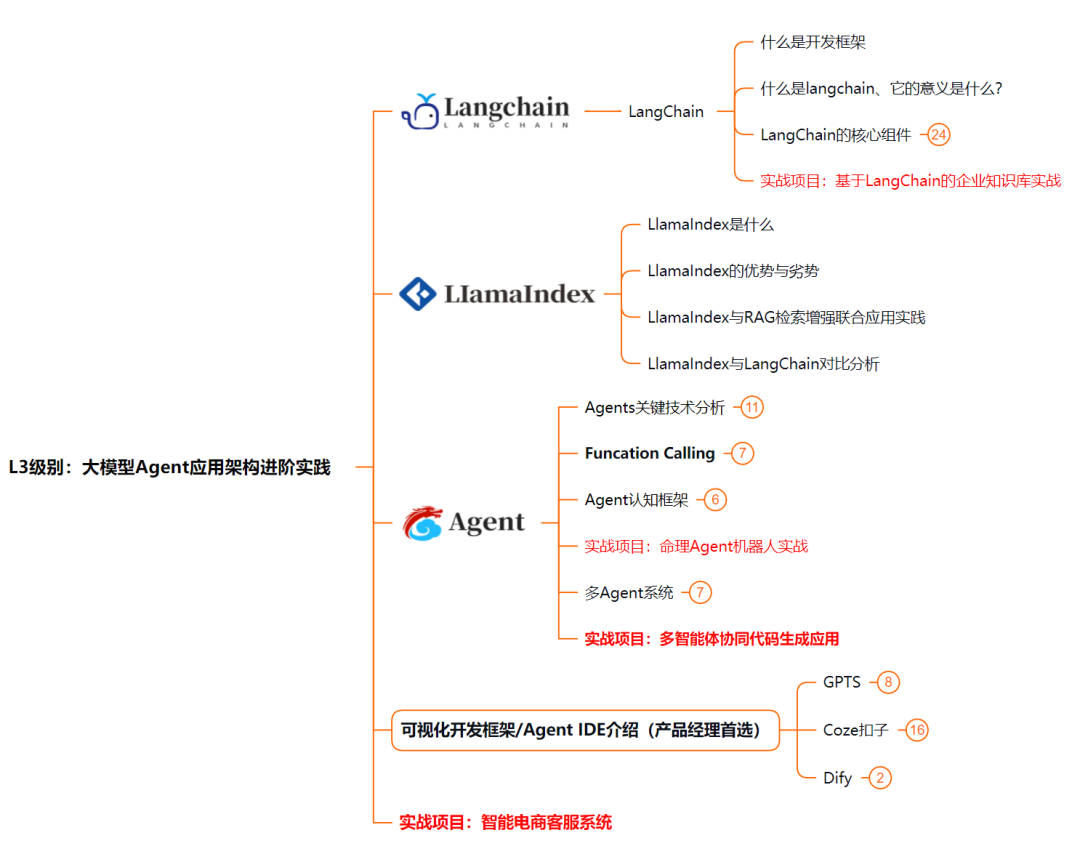
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。
L4级别:大模型微调与私有化部署
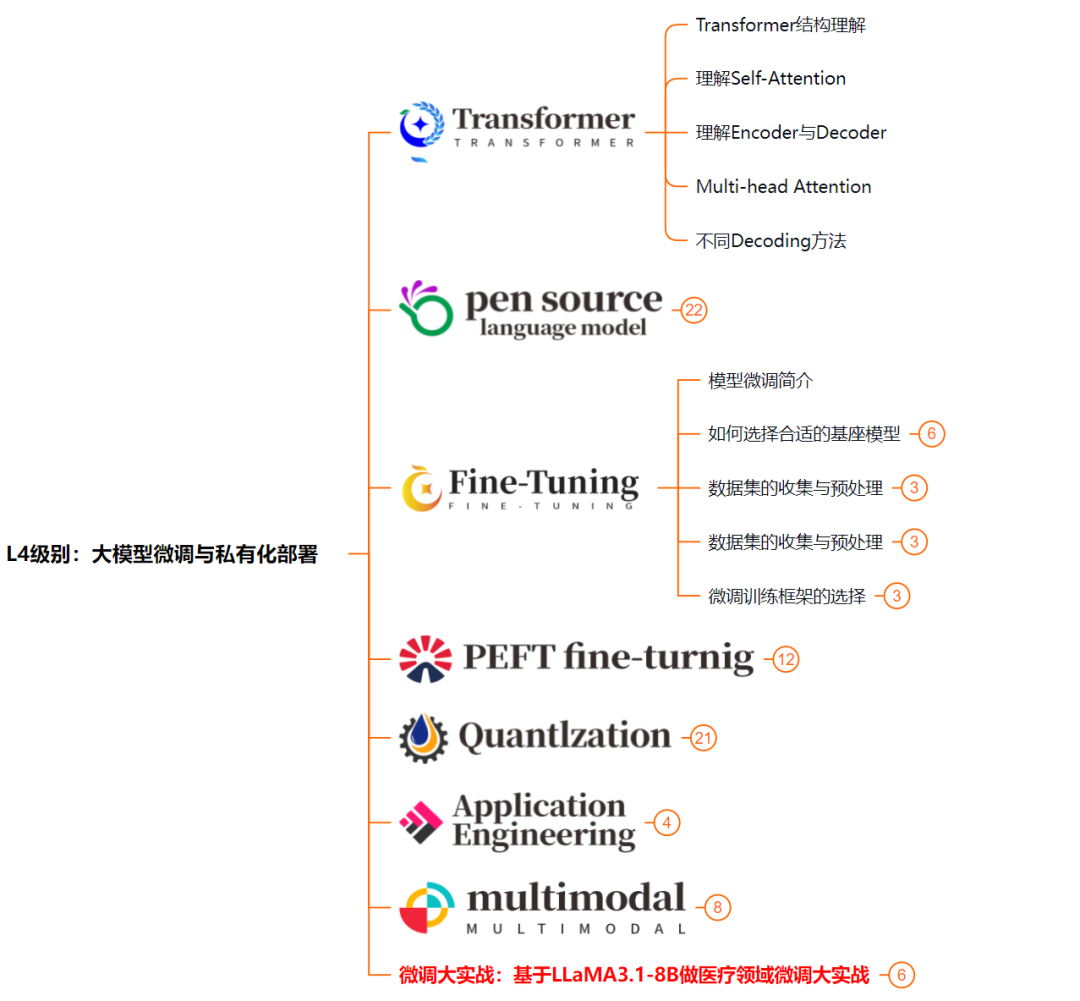
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。
整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取
****如果这篇文章对你有所帮助,还请花费2秒的时间**点个赞+在看+分享,**让更多的人看到这篇文章,帮助他们走出误区。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









