







前言
上篇文章中介绍的Horpool算法与KMP算法,同属于字符串匹配算法,并且同样利用了预处理的方式,只是二者预处理的方法不同罢了,但根本上都是为了减少不必要的比较过程。相比于Horpool算法,KMP算法更为的高效。
一、算法思想分析
KMP算法存在一个预处理过程,并且这个预处理同样是针对模式串的。那么,既然KMP算法和Horpool算法都存在预处理,我们首先就要理解,这个预处理的机制是如何的?为什么这样进行预处理?
KMP算法思想较复杂,分析过程篇幅较长,请做好思想准备。
KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。而其具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。
KMP算法,利用的是最长的相同的前缀和后缀,以此来构造回溯点,从而减少字符串比较过程。如何利用最长的相同前缀和后缀?
我们用模式串abcdaabcab模拟一下过程,假设当前我们正在将模式串下标为7的字符串c与文本中某个字符比较,而其前面的比较都是匹配的,但是当前字符是不匹配的(就是这个c和文本中对应的比较字符无法匹配)。那么,这个时候,我们就要开始回溯模式串了,就是要回到上一个比较点。可是我要如何确实上一个回溯点,才能保证我比较的次数最少呢?
按照蛮力法的思想,我们就要会到第一个字符了(这里也就是指的a),然后重新比较。可是,我们前面都比较了那么多次了,我们是不是可以利用前面的结果呢?既然我已经匹配到字符c(下标7)了,说明我前面的所有字符都已经匹配成功,而我只需要往前查找一个最长的与前面的子字符串相同的字符串不就可以减少我的比较次数了?这里指的就是前缀后后缀,即在匹配失败的前面的字符串中寻找一个最长的相同的前缀与后缀。那为什么需要这样呢?想象一下,按照蛮力法,我应该是回到第一个字符重新比较的,可是如果我前面已经可以确认第一个字符,甚至是后面很多字符,都是肯定匹配的(因为我已经在c前面匹配过了的!),那么我还需要回到第一个字符么?我直接回到我匹配的最长前缀的后面一个字符即可,然后去继续比较,直到我匹配成功!
这个局部匹配信息是怎样的匹配信息呢?我们来举个栗子来讲解:
假设模式串为 abcdaabcab ,那么利用KMP算法生成的预处理结果(局部匹配信息)如下图。
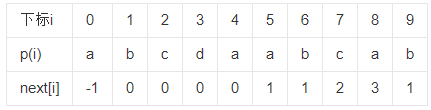
对照着这个图,我们来讲解该预处理结果是如何生成的。
- 首先定next[0]的值为-1,这个是一个初始化过程。这个初始化的结果,我们后面会用到的。
- 依次遍历模式串,从第一个(下标为0)开始,而我们要定义一个用来回溯的标记k,且初始值为-1(其实就是next[0])具体作用,讲解后就知晓。再初始化一个标记j,其功能是用来记录当前遍历的位置。
- 比较模式串下标为k的字符和模式串下标为j的字符是否相同,在这里可能大家就有个疑问了,k的初始值为-1,数组会越界的吧?直接比较自然会越界,但在比较这两个字符前,我们还有一个条件需要确认,那就是k的值是否为-1(也就是next[0]),如果为-1,那么接下来也就不用比较了,对吧?
- 所以总结来说,条件就是k==-1或(模式串下标为k的字符和模式串下标为j的字符相同),如果满足这个条件,那么我们就将k加1,j加1,然后赋next[j]=k。这里其实是一个不好理解的点,简单来说,如果当前k为-1,说明当前又回溯到第一个字符了,我们就需要将j位置字符的回溯点设置为第一个字符。而如果两个字符比较成功,那么我们就将j位置字符的回溯点设置为k+1。这里有些不好理解,主要现在我是在讲解预处理结果的生成过程,稍后会讲核心思想的。
- 那么,如果不满足这两个条件呢?说明我们当前无法标记回溯点,我们就需要将当前的标记k,直接进行回溯,直到找到满足上述条件的时候才能标记j的回溯点(其实这个地方最不好理解,大家看起来可能比较费劲,这个真得费点劲去理解了)。
预处理完成之后,需要进行的就是比较过程了。既然我们的预处理结果已经得出来了,并且已然理解回溯过程了,那么,接下来讲解一下算法实现过程:
- 对模式串和文本,都从头开始比较。
- 如果当前模式串是在开头或者是当前模式串字符与对应位置的文本字符匹配,那么我们将文本标记加一,即去比较下一个字符。
- 如果我们模式串既不是在开头,并且对应位置的字符比较之后也不相同,那么说明,我们要开始回溯了(因为我们当前匹配失败)。即利用next()函数,回到上一个回溯点。其实这里KMP算法的实现过程,和模式串预处理过程有些类型,如果理解了预处理过程,KMP比较过程不难理解(但就是预处理过程比较难理解啊)。
- 重复上述二、三步,直到匹配成功,或是匹配失败。
KMP算法思想其实不是很容易理解,其关键点就是利用了最长的前缀和后缀,减少我们需要比较的过程,关键在于如何回溯?我为什么要这样确定回溯点?这里的话,我能力有限,讲解的可能不是很透彻,大家可以参看代码来理解。
二、算法效率分析
假设模式串长度为m,文本长度为n。模式串的预处理过程是O(m),而比较过程则其实是O(n),因为回溯过程基本上都是常量级别,这里就忽略了。所以总的算来,KMP算法的算法复杂度为O(m+n),显然,这是一个非常之高效的算法。
三、算法代码
C语言
KMP算法,纯粹用文字去描述的话,我觉得是很难理解的,推荐大家用例子去一个一个推敲,这样理解起来会比较容易。或者先看看代码来理解理解,这样或许对思想有所启发。
/*KMP算法 利用预处理模式串 获得回溯点 空间换时间算法*/
#include<stdio.h>
#include<string.h>
#define MAXN 1000000
int next[MAXN];
/* 全局文本/模式串 */
char s[MAXN],t[MAXN];
/*获取回溯数组next的函数*/
void getNext() {
int j=0,k=-1;
/* 第一个位置无法回溯 */
next[0]=-1;
while(j<strlen(t)) {
/* 两个条件的原因:要么我就是一直回溯到了第一个next 这个时候第一个next[0]为-1 那位当前位置的next[j]再怎么都可以为0(k++)
要么就是回溯时期的字符和当前j位置的字符等于 那么,我们还是获取一个next[j]
*/
if(k==-1||t[j]==t[k]) {
j++;
k++;
next[j]=k;
}
/* next函数的一个精华点 */
else k=next[k];
// 为什么会这么写?当前字符串无法匹配 我们的k位置在向前回溯
// 想象一下 如果我们当前匹配失败 那么我们该回到哪里再来?显然是当前位置上传所匹配到的字符串长度位置(最长前缀)
}
}
/* 简化一下 全局变量暂时不传参 */
int KMP() {
getNext();
int i=0,j=0; // i跟踪文本s j跟踪模式串t
int sLen=strlen(s),tLen=strlen(t);
while(i<sLen&&j<tLen) {
// 这里-1就和上面getNext方法对应了!
if(j==-1||s[i]==t[j]) {
j++;
i++;
} else {
j=next[j]; // 和上面一样的道路 开始回溯匹配
}
}
// printf("%d %d",i,tLen);
if(j>=tLen) return (i-tLen); // 老样子 获取首位 需要减去长度
return -1; // -1则无
}
/*
书本指的是《算法设计与分析基础》
测试数据一 (书本数据 见截图)
BARBER
JIM_SAW_ME_IN_A_BARBERSHOP
测试数据二 (书本习题一)
BAOBAB
BESS_KNEW_ABOUT_BAOBABS
测试数据三
00001
1000个0
测试数据四
10000
1000个0
*/
int main() {
printf("请输入模式串t:\n");
gets(t);
printf("\n请输入文本s:\n");
gets(s);
printf("匹配位置:%d",KMP());
return 0;
}
后记
相比于Horpool算法,KMP算法是较难理解,其关键点就在于理解回溯这个思想。理解了为什么要去回溯?我如何进行回溯?理解了这些,KMP算法才会好理解一些,或许也正是因为KMP算法难理解,它才是一个如此高效的算法。毕竟越好的东西嘛,有时候也就越深奥。














 117
117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









