







sql取group by 分组后的组内最新(最大,最…)的一条数数据
最近一个有个需求是 , 取分组后的组内最新的一条数据, 正常来说写法如下
select a.* from
(
select cluesTaracking_id,cluesId,trackingTime,fail_why from cluestracking
order by trackingTime desc
) a
group by a.cluesId
但是查询结果却是取得id最小的一条数据
不分组查询结果
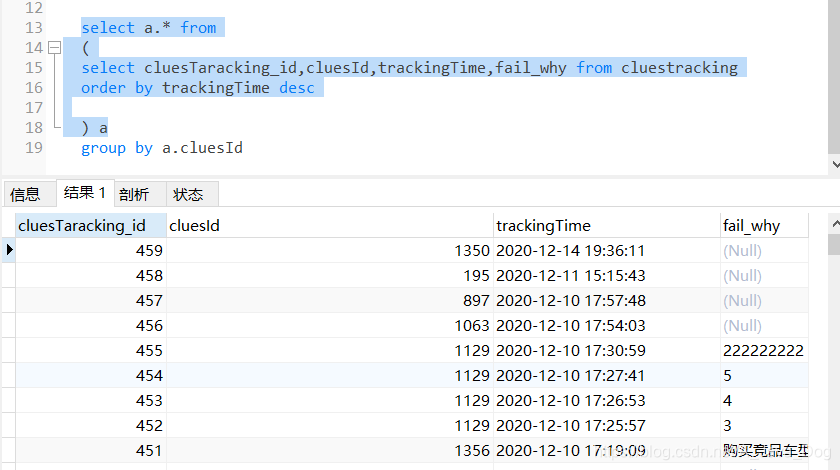
分组后的查询结果
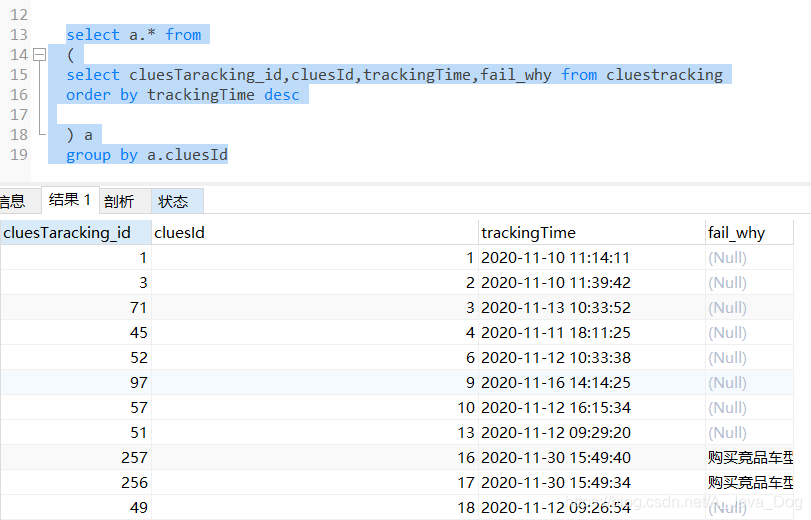
明显可以看出分组后并没有取trackingTime最大的一条数据
解决方案
方法一
在order by后面添加 limit X, 比如这里添加limit 100, sql如下
select a.* from
(
select cluesTaracking_id,cluesId,trackingTime,fail_why from cluestracking
order by trackingTime desc
limit 100
) a
group by a.cluesId
查询结果如下
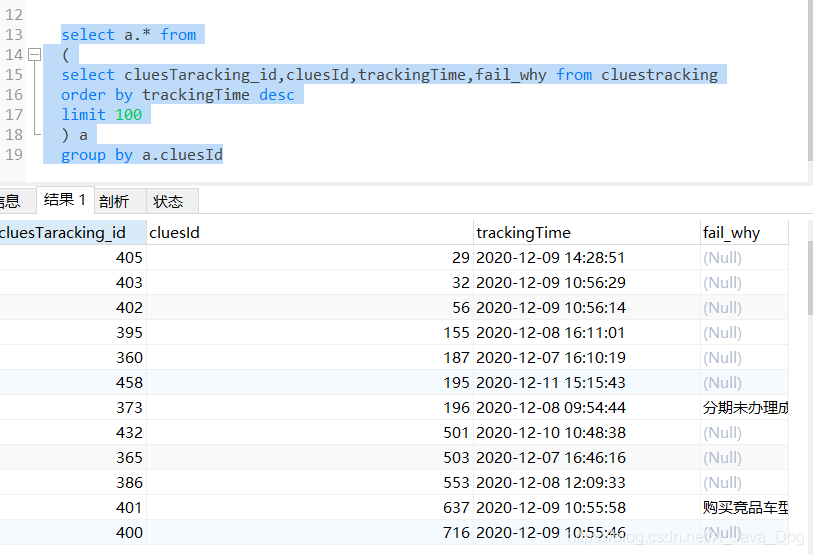
可以看到, 已经将分组后组内最新的一条数据查出
问题解析:
通过explain方式, 查看执行逻辑
将limit 100注释掉
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iEEd1000-1608015395467)(en-resource://database/515:0)]](https://i-blog.csdnimg.cn/blog_migrate/e9a4168a30fd9050e81a0b6ceb1daf6e.png)
发现这里的select_type是SIMPLE, SIMPLE表示这是一个
简单的SELECT语句(不包括UNION操作或子查询操作),
也就是虽然写了子查询和排序, 但是并未生效, 依然使用的是默认的排序, 即按照id升序排列
打开limit 100的注释
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nm6bjULq-1608015395469)(en-resource://database/517:0)]](https://i-blog.csdnimg.cn/blog_migrate/b3b2079c4d33a613354bf3bfd0dfafbb.png)
PRIMARY:
查询中最外层的SELECT(如两表做UNION或者存在子查询的外层的表操作为PRIMARY,内层的操作为UNION)
'DERIVED:
DERIVED表示被驱动的SELECT子查询(子查询位于FROM子句)
由此可见 , 在mysql 5.7中, 如果想要获取分组后的最新数据, 必须加上limit 条数, 这里可以指定一个不可能查询出的数值,如1000等
方法二 使用 MAX() 聚合函数
如
select cluesTaracking_id,cluesId,
MAX(trackingTime),
fail_why from cluestracking
group by cluesId
order by trackingTime desc
查询结果如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ldeDM001-1608015395472)(en-resource://database/519:0)]](https://i-blog.csdnimg.cn/blog_migrate/2a47184b4e351c7135cc0f29fe25519a.png)
方法一的查询结果如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y7oTkcgm-1608015395475)(en-resource://database/521:0)]](https://i-blog.csdnimg.cn/blog_migrate/2aa44f97713bb8c8da729f6fedb07f15.png)
可以看到, 查询结果一致


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











