







K-Means Clustering(k均值聚类算法) 属于无监督学习算法, 它可以发现 k 个不同的簇, 每个簇的质心采用簇中所含值的均值计算而成.
| 优点 | 容易实现 |
| 缺点 | 可能收敛到局部最小值, 在大规模数据集上收敛较慢 |
| 适用数据类型 | 数值型 |
基础概念
1. 无监督学习
目标变量不存在, 即不区分训练集与测试集, 没有训练阶段.
2. SSE
Sum of Squared Error(SSE, 误差平方和), 用于度量聚类效果的指标, 它是样本点到其所属簇的质心的距离的平方和, SSE 值越小表示数据点越接近它们的质心, 聚类效果也越好.
算法描述
1. K-Means
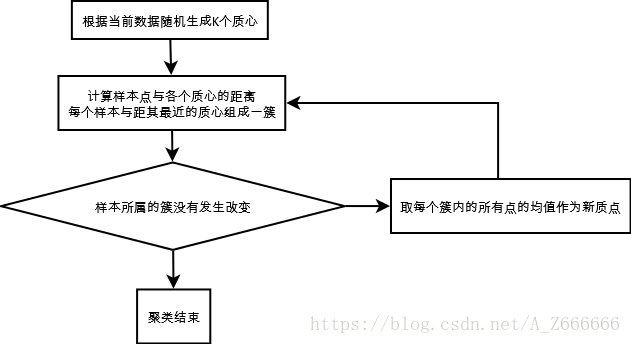
(1). 随机选取K个质心
(2). 遍历每个样本点, 与距离其最近的质心作为一簇, 最后共生成 K 个簇 (代码 47-60 行)
(3). 重新计算K个质心, 即将每个簇中所有样本点求均值, 得到新的质心 (代码 66-68 行)
(4). 重复(2)->(3), 若 (2) 进行完后, 每个样本点所属的簇都没有发生改变, 则聚类完成
(5). 当聚类完成后, 应该能得到K个质心的坐标, 各个样本点所属的簇及其与质心的误差(距离)
2. 二分 K-Means
二分 K-Means 算法是为了解决 K-Means 会碰到的收敛到局部最小值的情况而提出的.
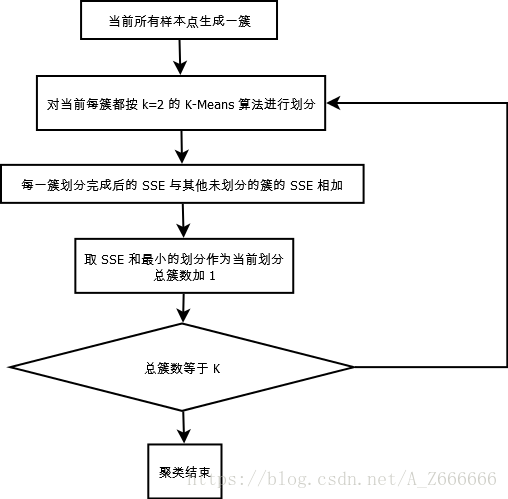
(1). 初始化时, 将所有样本点作为一个簇 (代码 82-83 行)
(2). 每一步划分都增加一个簇, 直至簇的总数为 K 为止
(3). 每次划分时, 都尝试对当前每个簇进行 K=2 的 K-Means 划分, 划分完后, 将此簇划分出来的 2 个簇的 SSE 与其他簇的 SSE 相加; 取总 SSE 最小的划分为当前划分 (代码 95 - 108 行)
算法流程图
1. K-Means
2. 二分 K-Means
代码
# -*- coding: utf-8 -*
from numpy import *
# 加载数据, 最后一列为其实际所属类别
# 数据由 tab 分隔
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float,curLine) # map all elements to float()
dataMat.append(fltLine)
return dataMat
# 计算两个向量的欧氏距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
# 基于数据集构建 K 个随机质心, 这些质心必须在数据集的范围内
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n))) # 存放随机质心, k 行 n 列
for j in range(n):
minJ = min(dataSet[:,j]) # 第 j 列的最小值
rangeJ = float(max(dataSet[:,j]) - minJ) # 第 j 列的范围
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
# kMeans 算法
# 1. 参数 k 表示需要划分的簇的大小
# 2. 返回值为分好类后的质心 及 各个样本点所属簇和样本点到质心的距离
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0] # 数据集行数, 即样本数
# 存放簇分配结果, 第 1 列为簇索引, 第二列为存储误差(当前点到质心的距离)
# 误差可以用来评价聚类的效果
clusterAssment = mat(zeros((m,2)))
# 初始取 k 个随机质心
centroids = createCent(dataSet, k)
clusterChanged = True
# 如果遍历所有样本点后, 它们所属簇都未发生变化, 则说明分类完成
while clusterChanged:
clusterChanged = False
# 对每个样本, 将其 assign 到与它距离最近的质心
for i in range(m):
minDist = inf;
minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI;
minIndex = j
# 样本点所属簇发生了变化
if clusterAssment[i,0] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
# 重新计算质心
# 以每个簇中所有样本点的均值为新质心
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent,:] = mean(ptsInClust, axis=0) # 求均值
return centroids, clusterAssment
# 二分 kMeans 算法
# 1. 参数 k 表示需要划分的簇的大小, distMeas 为计算两点间距离(误差)的函数
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
# 存储每个点分配到的簇及误差
clusterAssment = mat(zeros((m,2)))
# 初始取所有点的均值作为质心
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] # 初始只有一个质心
# 遍历所有的样本点, 计算这些样本点到质心的距离(误差)
for j in range(m):
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
# 每个循环都会增加一个簇, 直至 k 个簇
while (len(centList) < k):
lowestSSE = inf
# 遍历所有已分的簇, 对每个簇中的数据采用 k 为 2 的 kMeans 分成两簇
# 取划分后误差(SSE)最小的划分作为下一步的划分
for i in range(len(centList)):
# 取当前簇中的所有点
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]
# 按 k=2 进行 kMeans 划分
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
# 计算误差
sseSplit = sum(splitClustAss[:,1])
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
# 取最小误差
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
# 保存最佳划分的质心
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList)
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]
centList.append(bestNewCents[1,:].tolist()[0])
# 保存簇索引及误差
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss
return mat(centList), clusterAssment
if __name__ == "__main__":
# 测试 kMeans
# datMat = mat(loadDataSet('testSet.txt'))
# myCentroids, clustAssing = kMeans(datMat,4)
# print myCentroids
# 测试 二分 kMeans
datMat3 = mat(loadDataSet('testSet2.txt'))
centList,myNewAssments = biKmeans(datMat3,3)
print centList说明
本文为《Machine Leaning in Action》第十章(Grouping unlabeled items using k-means clustering)读书笔记, 代码稍作修改及注释.
好文参考
1.《K-Means 算法》
2.《漫谈 Clustering (1): k-means》
3.《K-means聚类算法》














 905
905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









