






NameNode
hdfs namenode -format
格式化后会在hadoop.tmp.dir目录产生fsiamge文件
[zhangsan@node1 ~]$ cd /opt/bigdata/hadoop/default/dfs/name/current
[zhangsan@node1 current]$ ll
-rw-rw-r--. 1 zhangsan zhangsan 355 Apr 4 08:52 fsimage_0000000000000000000
-rw-rw-r--. 1 zhangsan zhangsan 62 Apr 4 08:52 fsimage_0000000000000000000.md5
-rw-rw-r--. 1 zhangsan zhangsan 2 Apr 4 08:52 seen_txid
-rw-rw-r--. 1 zhangsan zhangsan 207 Apr 4 08:52 VERSION
接下来我们使用工具查看每个文件的内容。
fsimage
Offline Image Viewer(oiv)是一个可以将hdfs的fsimage文件的内容转储为人类可读的格式的工具。支持多种Processor解析方式:Web processor, XML Processor, Delimited Processor, FileDistribution Processor等。
使用方法
bin/hdfs oiv -p XML -i fsimage -o fsimage.xml
-
-p|--processorprocessor -
-i|--inputFileinput file -
-o|--outputFileoutput file -
-h|--help
使用案例
XML Processor
[zhangsan@node1 current]$ hdfs oiv -i fsimage_0000000000000000000 -p XML -o ~/fsimage_0000000000000000000.xml
fsimage_0000000000000000000.xml 文件内容:
[zhangsan@node1 current]$ cat ~/fsimage_0000000000000000000.xml
<?xml version="1.0"?>
<fsimage>
<NameSection>
<genstampV1>1000</genstampV1>
<genstampV2>1000</genstampV2>
<genstampV1Limit>0</genstampV1Limit>
<lastAllocatedBlockId>1073741824</lastAllocatedBlockId>
<txid>0</txid>
</NameSection>
<INodeSection>
<lastInodeId>16385</lastInodeId>
<inode>
<id>16385</id>
<type>DIRECTORY</type>
<name></name>
<mtime>0</mtime>
<permission>zhangsan:supergroup:rwxr-xr-x</permission>
<nsquota>9223372036854775807</nsquota>
<dsquota>-1</dsquota>
</inode>
</INodeSection>
<INodeReferenceSection></INodeReferenceSection>
<SnapshotSection>
<snapshotCounter>0</snapshotCounter>
</SnapshotSection>
<INodeDirectorySection></INodeDirectorySection>
<FileUnderConstructionSection></FileUnderConstructionSection>
<SnapshotDiffSection>
<diff>
<inodeid>16385</inodeid>
</diff>
</SnapshotDiffSection>
<SecretManagerSection>
<currentId>0</currentId>
<tokenSequenceNumber>0</tokenSequenceNumber>
</SecretManagerSection>
<CacheManagerSection>
<nextDirectiveId>1</nextDirectiveId>
</CacheManagerSection>
</fsimage>
FileDistribution Processor
[zhangsan@node1 current]$ hdfs oiv -i fsimage_0000000000000000000 -p FileDistribution -o ~/fsimage_0000000000000000000.fd
[zhangsan@node1 current]$ cat ~/fsimage_0000000000000000000.fd
Processed 0 inodes.
Size NumFiles
totalFiles = 0
totalDirectories = 1
totalBlocks = 0
totalSpace = 0
maxFileSize = 0
##### Delimited Processor
[zhangsan@node1 current]$ hdfs oiv -i fsimage_0000000000000000000 -p Delimited -o ~/fsimage_0000000000000000000.delimited
[zhangsan@node1 current]$ cat ~/fsimage_0000000000000000000.delimited
/ 0 1970-01-01 08:00 1970-01-01 08:00 0 0 0 9223372036854775807 -1 rwxr-xr-x zhangsan supergroup
```
### VERSION
```
[zhangsan@node1 current]$ cat VERSION
#Mon Apr 04 08:52:15 CST 2022
namespaceID=1551467440
clusterID=CID-18aaceee-980c-475a-8d3d-d59b7291541a
cTime=0
storageType=NAME_NODE
blockpoolID=BP-792177474-192.168.179.101-1649033535606
layoutVersion=-63
```
### seen\_txid
```
[zhangsan@node1 current]$ cat seen_txid
0
```
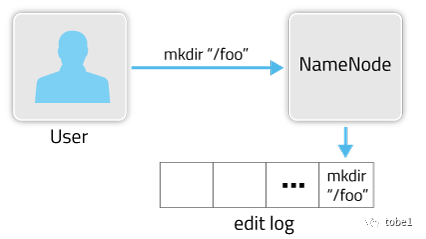
### edits
`edits`文件中记录了`HDFS`的操作日志,现在`HDFS`中没有任何文件,我们创建文件夹`/user/zhangsan`,在创建文件前,先启动`HDFS`。
`Offline Edits Viewer(oev)`是一个用来解析`Edits`日志文件的工具。支持多种`Processor`解析方式:`XML`, `stats`等。
#### 使用方法
`bin/hdfs oev -p xml -i edits -o edits.xml`
#### 使用案例
##### 创建文件夹`/user/zhangsan`
```
[zhangsan@node1 current]$ hdfs oev -i edits_inprogress_0000000000000000001 -p XML -o ~/edits_inprogress_0000000000000000001.xml
```
##### 查看edits
```
[zhangsan@node1 current]$ cat ~/edits_inprogress_0000000000000000001.xml
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>1</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>2</TXID>
<LENGTH>0</LENGTH>
<INODEID>16386</INODEID>
<PATH>/user</PATH>
<TIMESTAMP>1649034484846</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>zhangsan</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>3</TXID>
<LENGTH>0</LENGTH>
<INODEID>16387</INODEID>
<PATH>/user/zhangsan</PATH>
<TIMESTAMP>1649034484856</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>zhangsan</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
</EDITS>
```
##### 上传文件`hadoop-2.7.3.tar.gz`到`hdfs://node1:9000/user/hadoop/`
```
[zhangsan@node1 current]$ hdfs dfs -put /opt/bigdata/hadoop/hadoop-2.7.3.tar.gz /user/zhangsan
```
##### 再次查看edits
```
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>1</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>2</TXID>
<LENGTH>0</LENGTH>
<INODEID>16386</INODEID>
<PATH>/user</PATH>
<TIMESTAMP>1649034484846</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>zhangsan</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>3</TXID>
<LENGTH>0</LENGTH>
<INODEID>16387</INODEID>
<PATH>/user/zhangsan</PATH>
<TIMESTAMP>1649034484856</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>zhangsan</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD</OPCODE>
<DATA>
<TXID>4</TXID>
<LENGTH>0</LENGTH>
<INODEID>16388</INODEID>
<PATH>/user/zhangsan/hadoop-2.7.3.tar.gz._COPYING_</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1649035096135</MTIME>
<ATIME>1649035096135</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-297911069_1</CLIENT_NAME>
<CLIENT_MACHINE>192.168.179.101</CLIENT_MACHINE>
<OVERWRITE>true</OVERWRITE>
<PERMISSION_STATUS>
<USERNAME>zhangsan</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
<RPC_CLIENTID>c2ab8d7c-26da-42c8-a479-121dc16a21aa</RPC_CLIENTID>
<RPC_CALLID>3</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<DATA>
<TXID>5</TXID>
<BLOCK_ID>1073741825</BLOCK_ID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<DATA>
<TXID>6</TXID>
<GENSTAMPV2>1001</GENSTAMPV2>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE>
<DATA>
<TXID>7</TXID>
<PATH>/user/zhangsan/hadoop-2.7.3.tar.gz._COPYING_</PATH>
<BLOCK>
<BLOCK_ID>1073741825</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1001</GENSTAMP>
</BLOCK>
<RPC_CLIENTID></RPC_CLIENTID>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_ID</OPCODE>
<DATA>
<TXID>8</TXID>
<BLOCK_ID>1073741826</BLOCK_ID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2</OPCODE>
<DATA>
<TXID>9</TXID>
<GENSTAMPV2>1002</GENSTAMPV2>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_ADD_BLOCK</OPCODE>
<DATA>
<TXID>10</TXID>
<PATH>/user/zhangsan/hadoop-2.7.3.tar.gz._COPYING_</PATH>
<BLOCK>
<BLOCK_ID>1073741825</BLOCK_ID>
<NUM_BYTES>134217728</NUM_BYTES>
<GENSTAMP>1001</GENSTAMP>
</BLOCK>
<BLOCK>
<BLOCK_ID>1073741826</BLOCK_ID>
<NUM_BYTES>0</NUM_BYTES>
<GENSTAMP>1002</GENSTAMP>
</BLOCK>
<RPC_CLIENTID></RPC_CLIENTID>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_CLOSE</OPCODE>
<DATA>
<TXID>11</TXID>
<LENGTH>0</LENGTH>
<INODEID>0</INODEID>
<PATH>/user/zhangsan/hadoop-2.7.3.tar.gz._COPYING_</PATH>
<REPLICATION>3</REPLICATION>
<MTIME>1649035103318</MTIME>
<ATIME>1649035096135</ATIME>
<BLOCKSIZE>134217728</BLOCKSIZE>
<CLIENT_NAME></CLIENT_NAME>
<CLIENT_MACHINE></CLIENT_MACHINE>
<OVERWRITE>false</OVERWRITE>
<BLOCK>
<BLOCK_ID>1073741825</BLOCK_ID>
<NUM_BYTES>134217728</NUM_BYTES>
<GENSTAMP>1001</GENSTAMP>
</BLOCK>
<BLOCK>
<BLOCK_ID>1073741826</BLOCK_ID>
<NUM_BYTES>79874467</NUM_BYTES>
<GENSTAMP>1002</GENSTAMP>
</BLOCK>
<PERMISSION_STATUS>
<USERNAME>zhangsan</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>420</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_RENAME_OLD</OPCODE>
<DATA>
<TXID>12</TXID>
<LENGTH>0</LENGTH>
<SRC>/user/zhangsan/hadoop-2.7.3.tar.gz._COPYING_</SRC>
<DST>/user/zhangsan/hadoop-2.7.3.tar.gz</DST>
<TIMESTAMP>1649035103337</TIMESTAMP>
<RPC_CLIENTID>c2ab8d7c-26da-42c8-a479-121dc16a21aa</RPC_CLIENTID>
<RPC_CALLID>9</RPC_CALLID>
</DATA>
</RECORD>
</EDITS>
```
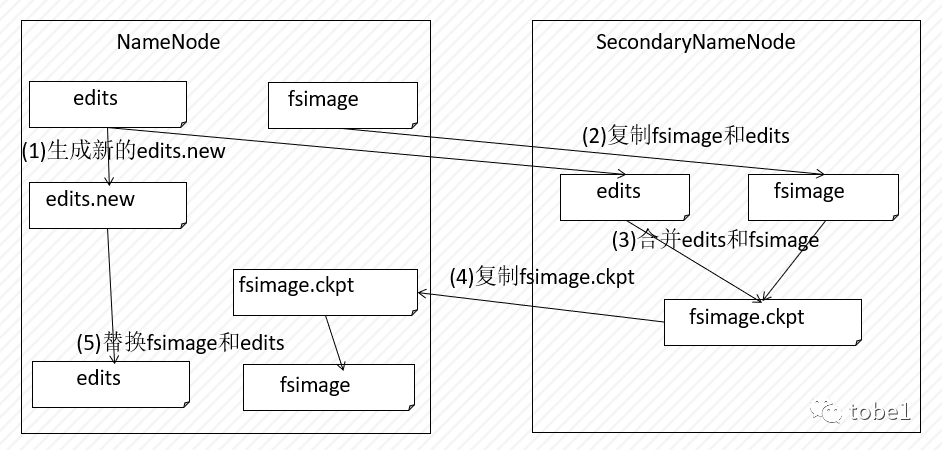
CheckPointing
-------------
检查点是一个获取 `fsimage` 和`edit log`并将它们压缩成新 `fsimage` 的过程。这样,`NameNode`可以直接从 `fsimage` 加载最终状态到内存中,而不是重加载大量的的`edit log`。这是一种效率更高的操作,并减少了 `NameNode` 的启动时间。
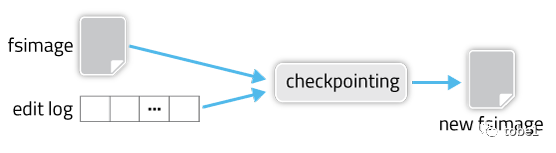
创建新的 `fsimage` 是一项 I/O 和 CPU 密集型操作,有时需要几分钟才能执行。在检查点期间,`NameNode`还需要限制其他用户的并发访问。因此,`HDFS` 不是暂停活动的 `NameNode` 来执行检查点,而是将其推迟到 `SecondaryNameNode` 或备用 `NameNode`,具体取决于是否配置了 `NameNode` 高可用性(HA)。检查点的机制根据是否配置了 `NameNode` 高可用性而有所不同。
















 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









