







文章目录
更多相关内容可查看
并发容器
所谓并发容器就是在多线程环境下能够保证线程安全的容器 , JDK 提供的这些容器大部分在 java.util.concurrent 包中。
ConcurrentHashMap
ConcurrentHashMap 是 Java 并发包 java.util.concurrent 中提供的一个线程安全的 Map 实现。与 HashMap 不同的是,ConcurrentHashMap 采用了分段锁(在 JDK 1.7 及之前)或者无锁化的数据结构(在 JDK 1.8 及之后)来支持高并发的读写操作,并且在并发环境中提供了良好的性能。
JDK 1.7 及之前的实现原理
分段锁实现原理:分段锁(Segment)将hash表进行分段处理,每一段都有一个锁,get的时候可以同时get,put的时候需要分段拿取锁put,实现并发性,扩容也会分段去扩容
JDK 1.8 及之后的实现原理
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
在 JDK 1.8 及之后的版本中,ConcurrentHashMap 的实现有了较大的改进,采用了基于 Node 的无锁化设计。主要的变化包括:
- 移除了 Segment:不再使用分段锁的概念,而是直接对 Node 进行操作。
- 使用 CAS(Compare-and-Swap)操作:在更新数据时,使用 CAS 操作来确保数据的一致性。CAS是一种无锁化的原子操作,它包含三个参数:内存位置(V)、预期的原值(A)和新值(N)。当且仅当 V 的值等于 A 时,才会将 V的值设置为 N。
- 红黑树:当链表长度超过一定阈值(默认为 8)时,会将链表转换为红黑树,以提高查找性能。
用法跟HashMap一样,只不过相比HashMap而言无需考虑线程安全问题了
CopyOnWriteArrayList & CopyOnWriteArraySet
CopyOnWriteArrayList 是 Java 并发包 java.util.concurrent 中的一个线程安全的列表实现。它的核心思想是在修改操作(如添加、设置或删除元素)时复制底层数组,并在新的副本上执行修改,从而保持原数组对读操作的可见性不变。这种写时复制的策略使得读操作(包括迭代和访问元素)可以无锁地并发进行,因此具有非常好的读性能
工作原理(附源码)
底层数据结构:
CopyOnWriteArrayList 底层使用数组(Object[])来存储元素。这个数组被 volatile
关键字修饰,确保了线程间可见性。
读操作:
读操作(如 get、size、迭代等)是无锁的,它们直接访问底层的 volatile 数组。由于 volatile
的语义,读操作可以确保看到最近一次写操作后的数组状态。

CopyOnWriteArrayList 提供了COWIterator内部类来实现迭代的线程安全性。当迭代器被创建时,它会获取当前数组的“快照”,并在迭代过程中使用这个快照。即使其他线程修改了列表,也不会影响已经创建的迭代器。
写操作:
public void replaceAll(UnaryOperator<E> operator) {
if (operator == null) throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
for (int i = 0; i < len; ++i) {
@SuppressWarnings("unchecked") E e = (E) elements[i];
newElements[i] = operator.apply(e);
}
setArray(newElements);
} finally {
lock.unlock();
}
}
- 当执行写操作(如 add、set、remove 等)时,CopyOnWriteArrayList 会先对底层数组进行
加锁(通常使用ReentrantLock 或其他锁机制),以防止其他线程同时进行写操作。- 接着,它会
复制当前数组,创建一个新的数组副本- 在新数组副本上执行实际的写操作(添加、更新或删除元素)。
- 最后,将底层数组的引用指向新的数组副本,并释放锁。这样,后续的读操作将会看到写操作后的新列表状态。
特点
优点
- 读操作的高性能:由于读操作是无锁的,并且可以直接访问底层数组,因此 CopyOnWriteArrayList 在读密集型场景中通常具有很高的性能。
- 线程安全:CopyOnWriteArrayList 是线程安全的,可以在多个线程之间共享而无需额外的同步。
- 迭代时的一致性:在迭代 CopyOnWriteArrayList时,可以看到列表在某一时刻的完整“快照”,而不用担心在迭代过程中列表被其他线程修改。
缺点
- 写操作的开销:每次修改操作(添加、设置或删除元素)都需要复制底层数组,并在新的副本上执行修改。这会导致写操作的时间复杂度和空间复杂度都是O(n),其中 n 是列表的大小。因此,在写密集型场景中,CopyOnWriteArrayList 的性能可能会非常差。
- 内存开销:由于每次修改操作都需要创建新的数组副本,因此 CopyOnWriteArrayList 的内存开销可能会比传统的列表实现(如ArrayList)更大。
- 数据不一致的“最终可见性”:虽然读操作看到的是列表在某一时刻的完整“快照”,但这并不意味着读操作能够立即看到其他线程的最新写操作结果。其他线程的写操作可能需要一些时间才能通过复制底层数组的方式反映到读操作中。
适用场景
CopyOnWriteArrayList 通常适用于读多写少的场景,如缓存、事件监听器等。在这些场景中,读操作的频率远高于写操作,因此 CopyOnWriteArrayList 的高性能读操作可以带来显著的性能提升。然而,在写密集型场景中,应该避免使用 CopyOnWriteArrayList,以免因频繁的数组复制操作而导致性能问题。
ConcurrentLinkedQueue
数据结构
ConcurrentLinkedQueue 由头节点(head)和尾节点(tail)组成,每个节点(Node)包含节点元素(item)和指向下一个节点的引用(next)。节点与节点之间通过 next 关联起来,形成一张链表结构的队列。
初始状态:默认情况下,head节点存储的元素为空,tail节点等于head节点。
入队列操作
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p is last node
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
当元素需要入队时,它们被添加到队列的尾部。假设我们要在一个队列中依次插入4个节点:
- 添加元素1:队列首先更新head节点的next节点为元素1节点。由于tail节点默认情况下等于head节点,所以它们的next节点都指向元素1节点。
- 添加元素2:队列设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点。
- 添加元素3:设置tail节点的next节点为元素3节点(但此时tail节点不指向元素3,因为tail节点是在添加新元素前更新的)。
- 添加元素4:设置元素3的next节点为元素4节点,然后将tail节点指向元素4节点。
入队操作主要做两件事:一是将入队节点设置成当前队列尾节点的下一个节点;二是更新tail节点。但在入队列前,如果tail节点的next节点不为空,则将入队节点设置成tail节点的next节点;如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点。
可能有点绕,建议反复看几遍
ConcurrentLinkedQueue 特性
- 无阻塞:由于ConcurrentLinkedQueue基于链表结构实现,因此不会产生阻塞,支持高并发的访问。
- 多线程安全:ConcurrentLinkedQueue被多个线程共享,可以安全地处理来自多个线程的请求。
- 高效性:通过CAS(Compare-And-Swap)等算法实现了高效的线程同步,减少了线程之间的等待和竞争,提高了系统的性能。
- 无界性:ConcurrentLinkedQueue不限制队列的大小,可以动态地增长。但这也意味着需要合理控制生产者的速度,以防止队列无限制地增长
ConcurrentLinkedQueue 方法
- add(E e) / offer(E e):将指定元素添加到队列的尾部,如果队列满(但实际上 ConcurrentLinkedQueue是无界的)则理论上不会返回false。
- poll():从队列的头部获取并删除一个元素,如果队列为空则返回null。
- peek():获取队列头部的元素,但不删除该元素,如果队列为空则返回null。
- size():获取当前队列中元素的数量(但由于并发性,这个数字可能只是近似值)。
- isEmpty():判断当前队列是否为空。
不支持空元素:ConcurrentLinkedQueue不支持存储空元素(null)。
BlockingQueue
BlockingQueue 是 Java 并发包 java.util.concurrent 中的一个重要接口,它支持在线程之间传递元素。这个接口是线程安全的,主要用于生产者-消费者模式。BlockingQueue 提供了几种在尝试从队列中检索元素时等待队列变为非空,或者在尝试向队列中添加元素时等待队列空间可用的方法。
BlockingQueue特性
- 线程安全:多个线程可以安全地访问 BlockingQueue,而无需额外的同步。
- 插入和移除操作:支持在队列的尾部插入元素(put、offer),在队列的头部移除元素(take、poll)。
- 容量:BlockingQueue 可以是有界的(如 ArrayBlockingQueue、LinkedBlockingQueue 的带参数构造函数),也可以是无界的(如 LinkedBlockingQueue 的无参数构造函数)。
- 等待/通知机制:当队列为空时,尝试从队列中取元素的线程会被阻塞,直到有元素可用;当队列满时,尝试向队列中添加元素的线程也会被阻塞,直到队列中有空间可用。
BlockingQueue方法
- add(E e): 如果可能立即插入元素,则返回 true;否则抛出 IllegalStateException。这个方法在队列满时不会阻塞。
- offer(E e): 如果可能立即插入元素,则返回 true;否则返回 false。这个方法在队列满时不会阻塞。
- put(E e): 将元素插入队列,如果队列满,则等待;InterruptedException 将在等待时被抛出。
- remove(Object o): 从队列中移除指定元素(如果存在)。
- poll(): 检索并删除队列的头,如果队列为空,则返回 null。
- take(): 检索并删除队列的头,如果队列为空,则等待;InterruptedException 将在等待时被抛出。
- peek(): 检索但不删除队列的头;如果队列为空,则返回 null。
常见的 BlockingQueue 实现包括
- ArrayBlockingQueue:基于数组的、有界阻塞队列。
- LinkedBlockingQueue:基于链表的、 默认情况下是无界的,但也可以通过指定一个容量限制来创建有界的 LinkedBlockingQueue。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列,每个插入操作必须等待一个相应的删除操作,反之亦然。
示例
定义两个类:Producer(生产者)和 Consumer(消费者)。生产者将元素添加到队列中,而消费者从队列中取出元素。
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class ProducerConsumerExample {
// 创建一个阻塞队列,这里使用LinkedBlockingQueue作为示例
private static final BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(10);
// 生产者类
static class Producer implements Runnable {
private final int maxItems;
public Producer(int maxItems) {
this.maxItems = maxItems;
}
@Override
public void run() {
try {
for (int i = 0; i < maxItems; i++) {
System.out.println("Producer produced " + i);
queue.put(i); // 当队列满时,会阻塞
Thread.sleep(100); // 模拟耗时操作
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 消费者类
static class Consumer implements Runnable {
@Override
public void run() {
while (true) {
try {
Integer item = queue.take(); // 当队列空时,会阻塞
System.out.println("Consumer consumed " + item);
Thread.sleep(200); // 模拟耗时操作
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break; // 中断后退出循环
}
}
}
}
public static void main(String[] args) {
// 创建并启动生产者线程
Thread producerThread = new Thread(new Producer(10));
producerThread.start();
// 创建并启动消费者线程
Thread consumerThread = new Thread(new Consumer());
consumerThread.start();
// 注意:这里仅作为示例,实际上可能需要额外的机制来确保消费者线程在所有元素被消费后能够优雅地结束
}
}
在这个例子中,创建了一个 LinkedBlockingQueue 实例,并设置了容量为10。生产者线程生成数字0到9,并将它们添加到队列中。消费者线程从队列中取出数字并打印出来。当队列满时,生产者线程会被阻塞,直到队列中有空间可用;当队列为空时,消费者线程会被阻塞,直到队列中有元素可用。
ConcurrentSkipListMap和ConcurrentSkipListSet
介绍
- ConcurrentSkipListMap是一个有序的映射表,其中每个键都映射到一个值。
- 它使用跳表数据结构来实现,跳表是一种通过维护多个有序链表来提供快速查找、插入和删除操作的数据结构。
- ConcurrentSkipListMap的设计目标是提供接近于O(1)的平均时间复杂度,对于常见的操作如get、put、remove等。
内部结构
- ConcurrentSkipListMap内部使用三个内部类来构建跳表结构:Node、Index、HeadIndex。
- 每个节点(Node)都包含两个指针,一个指向同一链表中的下一个元素,另一个指向下面一层的元素。
- 索引节点(Index)和头索引节点(HeadIndex)用于加快查找过程,通过它们可以快速定位到包含目标元素的链表层级
示例
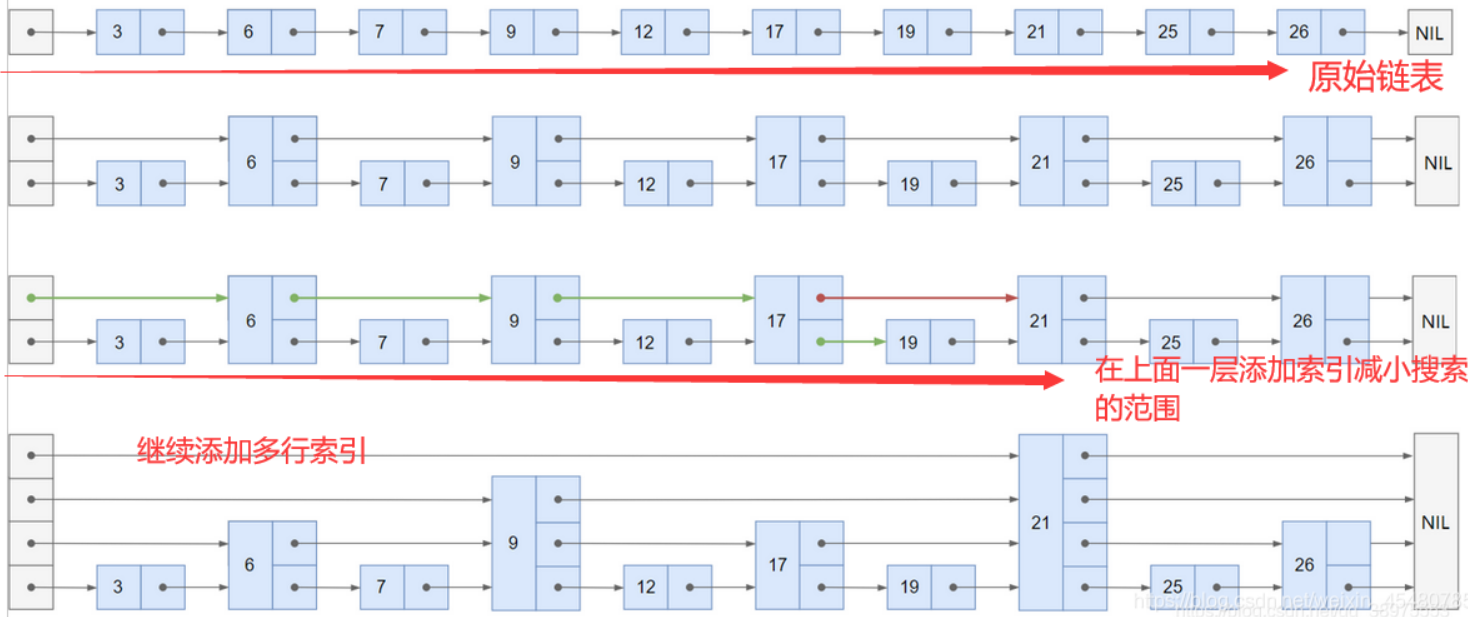
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。如上图所示,在跳表中查找元素 25 查找 25 的时候原来需要遍历 9 次,现在只需要 5 次即可。针对链表长度比较大的时候,构建索引查找效率的提升就会非常明显。
从上面很容易看出,跳表是一种利用空间换时间的算法。
使用跳表实现 Map 和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果
注:虽然ConcurrentSkipListMap提供了线程安全,但在高并发场景下,仍然需要注意竞态条件和其他并发问题。对于大数据量的应用场景,ConcurrentSkipListMap的性能可能不如其他并发数据结构(如ConcurrentHashMap),因为它需要维护额外的跳表结构。
ConcurrentSkipListSet 是 Java 并发包(java.util.concurrent)中的一个类,它实现了 NavigableSet 接口,并提供了线程安全的、基于跳跃列表(SkipList)的无序集合。然而,需要注意的是,尽管 ConcurrentSkipListSet 的元素是无序的(插入顺序不保证),但它维护了元素的自然顺序或根据创建集合时提供的 Comparator 进行排序

















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











