







一、认识ElasticSearch
它的主要用途是做全文检索,依然是基于Apache Lucene的开源搜索引擎。
二、Lucene和ElasticSearch选择使用
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是它相比较于ElasticSearch还是有一定的缺点:
- 使用起来较复杂
- Lucene 不支持集群
ElasticSearch相比较于Lucene具有一定的优点: - ES全文检索框架,使用起来比Lucene更简单
- ES支持集群、支持分布式
- 支持JSON的操作
- 一般大型全文检索都是用ES
- 通过Restfull风格来操作ES
三、ES的典型使用案列
- Github(美国)
- Foursquare实时搜索5千万地点信息
- 德国SoundCloud使用Elasticsearch来为1.8亿用户提供即时精准的音乐搜索服务
- Mozilla公司以火狐著名
- Sony公司使用elasticsearch 作为信息搜索引擎
四、与ES类似框架
- solr(重量级对手)
与ES最大的其区别:solr是实时搜索,效率低。Zookeeper 进行分布式管理,支持更多格式的数据(HTML/PDF/CSV),官方提供的功能更多在传统的搜索应用中表现好于 ES。
五、ES的安装
前提:ES服务只依赖于JDK,推荐使用JDK1.7+。
- 下载安装包
官方下载地址,点击下载 - 运行ES
bin/elasticsearch.bat

- 验证
直接访问:http://localhost:9200

页面得到以上的返回信息,代表ES集群已经启动并且正常运行。
六、Kibana5,辅助管理工具
- 下载地址
- 启动Kibana5 : bin\kibana.bat
- 默认访问地址:http://localhost:5601
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
七、ES的交互方式
1、基于Restful风格
(1)Restful的认识
Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作。
(2)使用Kibana5辅助管理工具进行CRUD操作
先打开工具。

然后访问http://localhost:5601,得到以下界面就代表成功

再用HTTP协议里的动词来实现资源的添加,修改,删除等操作。
- GET 用来获取资源,
- POST 用来新建资源(也可以用于更新资源),
- PUT 用来更新资源,
- DELETE 用来删除资源。
2、使用java操作(下面细讲)
八、ES数据管理
ES面向文档(document oriented),它可以存储整个对象或文档(document)。还会索引(index)每个文档的内容使之可以被搜索。即ES可以进行索引、搜索、排序、过滤操作。
ES使用JSON作为文档序列化格式。JSON被大多语言所支持,而且已经成为NoSQL领域的标准格式。
- 一个文档不只有数据。它还包含元数据(metadata)—关于文档的信息。三个必须的元数据节点是:

细说元素节点: - _index:索引库,类似于关系型数据库里的“数据库”—它是我们存储和索引关联数据的地方。
- _type:在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客等等。
- _id:可以在ELasticsearch中唯一标识一个文档,你可以自定义 _id ,也可以让Elasticsearch帮你自动生成。
- _uid:文档唯一标识(_type#_id)
- _source:文档原始数据
- _all:所有字段的连接字符串
1、下面是对文档的增删改操作:
-
新增操作
有自定义id:

自动生成的id:

批量插入数据

-
更新操作
全部数据更新

局部数据更新(用此方法,解决未更新数据丢失问题)
_update和doc

-
删除操作
这是有自定义id的操作。如果没有自定义id就在创建时赋值生成的随机id即可删除。

2、对文档的查询
(1)通过文档的id查询

(2)批量获取
- 方式一:

- 方式二:

(3)只查询source下面的数据

(4)只查询source下面的数据,指定的列

(5)查询所有文档。也叫空搜索

(6)分页查询
Elasticsearch接受 from 和 size 参数。用法和SQL的limit一样
size : 每页条数,默认 10 pageSize
from : 跳过开始的结果数,默认 0 beginIndex
Limit beginIndex,pageSize
beginIndex = (currentPage-1)*pageSize
- 实例:
如果你想每页显示5个结果,页码从1到3,那请求如下:
GET _search?size=5 --第1页
GET _search?size=5&from=5 --第2页
GET _search?size=5&from=10 --第3页
(7)字符串查询
参数指定:年龄为24岁的用户

参数不指定:年龄为20到25的用户

九、DSL查询与过滤
1、DSL概念;
由ES提供丰富且灵活的查询语言,以JSON请求体的形式出现。
- 查询字符串模式

2、DSL的查询、过滤和分页结合案列
-
组合搜索bool可以组合多个查询条件为一个查询对象,查询条件包括must、should和must_not。
-
== 范围查询与过滤(range)。gt:> gte:>= lt:< lte:<= eq ==
-
前匹配搜索与过滤(prefix),类似SQL中的like ‘key%’
-
准备好数据
要求:查询关键字为iphone,国家为us的,价格范围6000到8000 价格降序。没有展示2条数据
POST shop/goods/1
{
"id":1,
"name":"iphone",
"price":5000,
"local":"us",
"type":"X系列"
}
POST shop/goods/2
{
"id":2,
"name":"iphone",
"price":6000,
"local":"us",
"type":"S系列"
}
POST shop/goods/3
{
"id":3,
"name":"iphone",
"price":7800,
"local":"us",
"type":"plus系列"
}
POST shop/goods/4
{
"id":4,
"name":"iphone",
"price":7000,
"local":"us",
"type":"P系列"
}
- 执行
GET shop/goods/_search
{
"query":{
"bool": {
"must": [
{"match": {
"name": "iphone"
}}
],
"filter": [{
"term":{
"local":"us"
}
},{
"range":{
"price":{
"gte":"5000",
"lte":"8000"
}
}
}]
}
},
"from": 1,
"size": 2,
"_source": ["id", "name", "type","price"],
"sort": [{"price": "desc"}]
}
- 解释

九、分词与映射
1、使用分词与映射的原因
文档的查询是通过关键字查询文档索引来进行匹配,因此将文本拆分为有意义的单词,能提高搜索的准确性。
ES中分词需要对具体字段指定分词器等细节,因此需要在文档的映射中明确指出。
2、IK分词器
ES默认对英文文本的分词器支持较好,和lucene一样,要对中文进行全文检索就需要中文分词器,那么就需要集成IK分词器。
ES的IK分词器插件源码地址
使用步骤:
- maven打包IK插件
- 解压target/releases/elasticsearch-analysis-ik-5.2.2.zip文件
并将其内容放置于ES根目录/plugins/ik - 重启ES服务器
- 测试分词器

(1)IK分词器有两种类型:ik_max_word和ik_smart
- ik_smart:做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
- ik_max_word:将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
(2)文档映射Mapper
ES的文档映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型。(相当于写表结构)
(3)ES字段类型
- 基本字段类型:
字符串:text(分词),keyword(不分词) StringField(不分词文本),TextFiled(要分词文本)
text默认为全文文本,keyword默认为非全文文本
数字:long,integer,short,double,float
日期:date
逻辑:boolean - 复杂数据类型:
对象类型:object
数组类型:array
地理位置:geo_point,geo_shape1)针对单个类型的映射配置方式
- 查询映射类型

- 修改映射类型
(1)Delete shop;删除库

(2)PUT shop;创建库

(3)POST shop/goods/_mapping:指定映射类型
比如:以前id是Long类型,现在指定id为Integer类型

(4)加入数据。
注意:你可以在第一次创建索引的时候指定映射的类型。此外,你也可以晚些时候为新类型添加映射(或者为已有的类型更新映射)。
- 查询映射类型
- 你可以向已有映射中增加字段,但你不能修改它。如果一个字段在映射中已经存在,这可能意味着那个字段的数据已经被索引。如果你改变了字段映射,那已经被索引的数据将错误并且不能被正确的搜索到。
我们可以更新一个映射来增加一个新字段,但是不能把已有字段的类型那个从 analyzed 改到 not_analyzed。 - 同时对多个类型的映射配置方式(不用这种方式 建议大家使用上面一个一个设置)这个指定user 又指定dept
(4)全局模板
案例:
#全局模板覆盖自带的默认模板案例
POST shop/goods/6
{
"id":6,
"name":"iphone",
"price":6600,
"local":"us",
"type_text":"P系列"
}
POST shop/goods/7
{
"id":7,
"name":"iphone",
"price":7000,
"local":"us",
"type_text":"P系列"
}
POST shop/goods/8
{
"id":8,
"name":"iphone",
"price":8000,
"local":"cn",
"type_text":"P系列"
}
全局模板:
#全局模板
PUT _template/global_template
{
"template":"*",
"settings":{
"number_of_shards":1
},
"mappings":{
"_default_":{
"_all":{
"enabled":false
},
"dynamic_templates":[
{
"string_as_text":{
"match_mapping_type":"string",
"match":"*_text",
"mapping":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_max_word",
"fields":{
"raw":{
"type":"keyword",
"ignore_above":256
}
}
}
}
},
{
"string_as_keyword":{
"match_mapping_type":"string",
"mapping":{
"type":"keyword"
}
}
}
]
}
}
}
运行后:
{
"shop": {
"mappings": {
"goods": {
"_all": {
"enabled": false
},
"dynamic_templates": [
{
"string_as_text": {
"match": "*_text",
"match_mapping_type": "string",
"mapping": {
"analyzer": "ik_max_word",
"fields": {
"raw": {
"ignore_above": 256,
"type": "keyword"
}
},
"search_analyzer": "ik_max_word",
"type": "text"
}
}
},
{
"string_as_keyword": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"id": {
"type": "long"
},
"local": {
"type": "keyword"
},
"name": {
"type": "keyword"
},
"price": {
"type": "long"
},
"type_text": {
"type": "text",
"fields": {
"raw": {
"type": "keyword",
"ignore_above": 256
}
},
"analyzer": "ik_max_word"
}
}
}
}
}
}
上面的意思:就是如果索引库里面字段 以_text结尾 就需要进行分词,如果不是,就不分词
测试:
(1)拷贝上面代码执行
(2)删除库 delete shop
(3)创建库 put shop
(4)加入数据测试
POST shop/goods/5
{
“id”:12,
“name_text”:”iphone x”,
“local“:”cnsssss”
}
十、java API
ES对Java提供一套操作索引库的工具包,即Java API。所有的ES操作都使用Client对象执行。
- 先导入依赖包
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
1、先创建一条记录
- java代码

在Kibana中打印是否成功创建
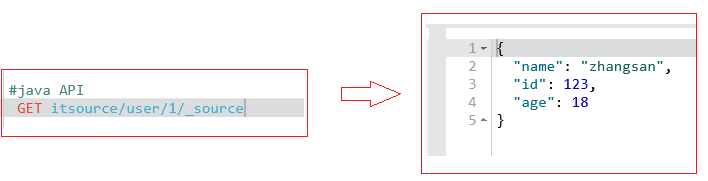
2、获取es里面的数据
- java中

3、ES删除操作
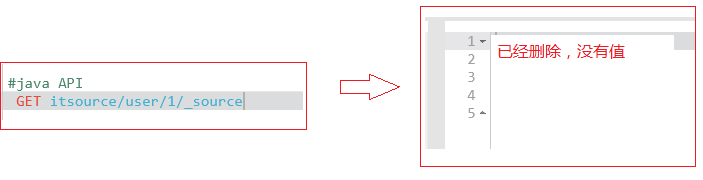
- java代码

- 在Kibana中查询是否还有文档
4、批量操作
- java代码

//批量插入
@Test
public void testBulk() throws Exception{
TransportClient client = getClient();
BulkRequestBuilder bulkRequestBuilder = client.prepareBulk();
for(int i=0;i<=5;i++){
Map mp = new HashMap();
mp.put("id",i);
mp.put("name","张三"+i);
mp.put("age",18+i);
mp.put("class",1);
//批量插入
bulkRequestBuilder.add(client.prepareIndex("crm","classes",i+"").setSource(mp));
}
BulkResponse bulkItemResponses = bulkRequestBuilder.get();
if(bulkItemResponses.hasFailures()){
System.out.println("error");
}
client.close();
}
- 在Kibana中查询是否批量插入成功

5、搜索
根据上面批量插入的数据做搜索操作
- 代码部分

//搜索 1班的人 过滤 age 20-25 分页 0, 3 sort id desc
@Test
public void testDSLQuery() throws Exception{
TransportClient client = getClient();
//BooleanQueryBuilder
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//搜索 1班的人
List<QueryBuilder> must = boolQueryBuilder.must();
must.add(QueryBuilders.termQuery("class",1));
//过滤 age 20-25
List<QueryBuilder> filter = boolQueryBuilder.filter();
filter.add(QueryBuilders.rangeQuery("age").gte(20).lte(25));
//分页 0, 3
SearchResponse searchResponse = client.prepareSearch("crm")
.setFrom(0).setSize(3).setQuery(boolQueryBuilder)
.addSort("id", SortOrder.DESC).get();
System.out.println("总的命中多少数:"+searchResponse.getHits().getTotalHits());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSource());
}
client.close();
}















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









