







闯关任务
观看「本关卡视频(https://www.bilibili.com/video/BV1CkSUYGE1v)」和「官网(https://internlm.intern-ai.org.cn/)」、「[GitHub(https://github.com/internLM/)」 写一篇关于书生大模型全链路开源开放体系的笔记
发展历程
-
书生·浦语大模型开源时间线

-
性能对比

-
书生·浦语 2.5 概览:
- 推理能力领先:综合推理能力领先社区开源模型相对InternLM2性能提升20%
- 支持100万字上下文:百万字长文的理解和精确处理性能处于开源模型前列
- 自主规划和搜索完成复杂任务:通过信息搜索和整合,针对复杂问题撰写专业回答,效率提升60倍
核心技术思路
书生·浦语构建了模型能力飞轮,持续迭代优化模型性能,广泛使用模型参与自身迭代,加速能力提升。
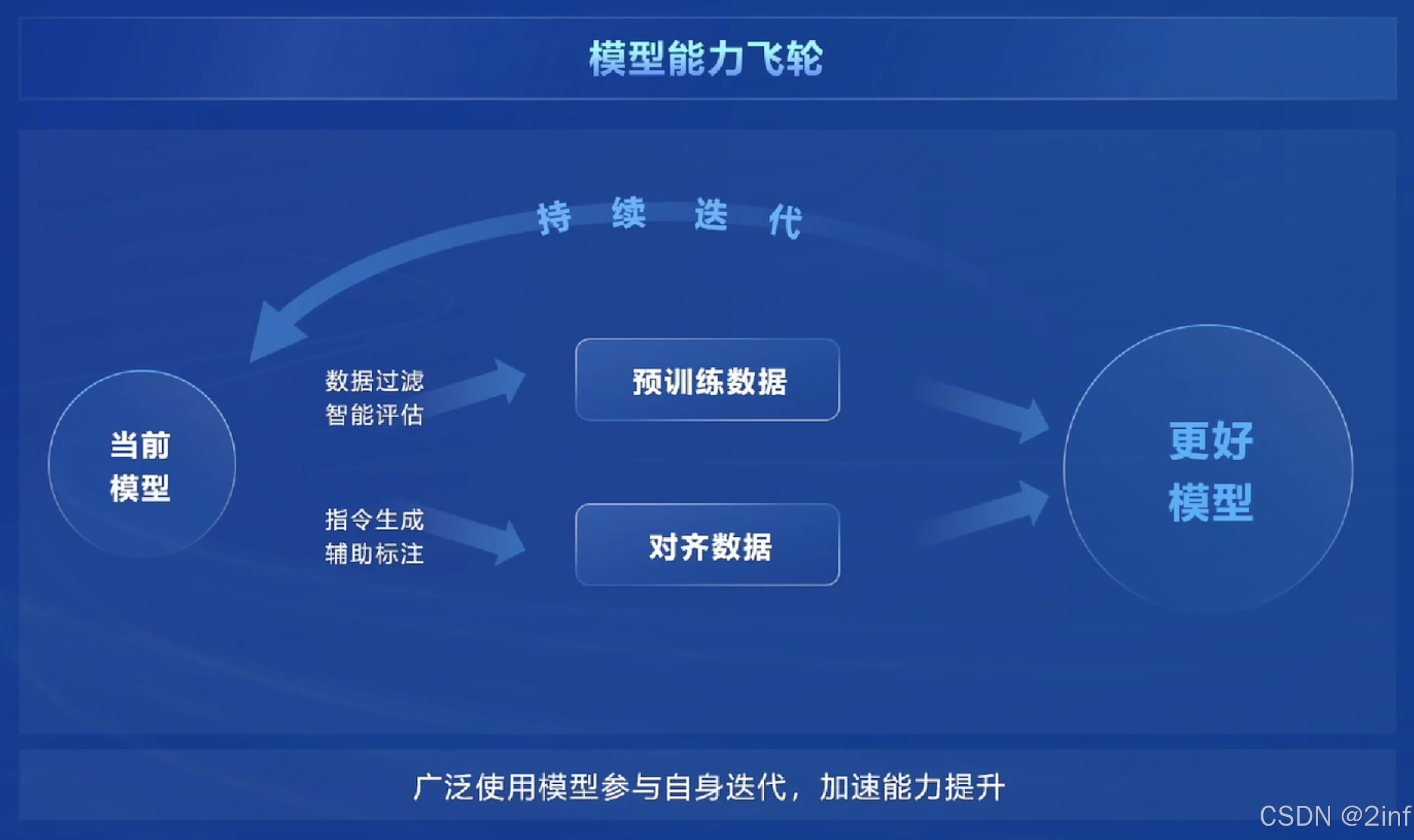
数据驱动模型性能, 高质量合成数据策略:
- 基于规则的数据构造:加入代码,数学公式,数学题解等伪(半)格式化的数据。
- 基于模型的数据扩充:利用已有模型对已有数据进行扩充,比如给代码添加函数、注释。
- 基于反馈的数据生成:利用人类反馈来生成更符合人类偏好的数据。
- 领先的推理能力
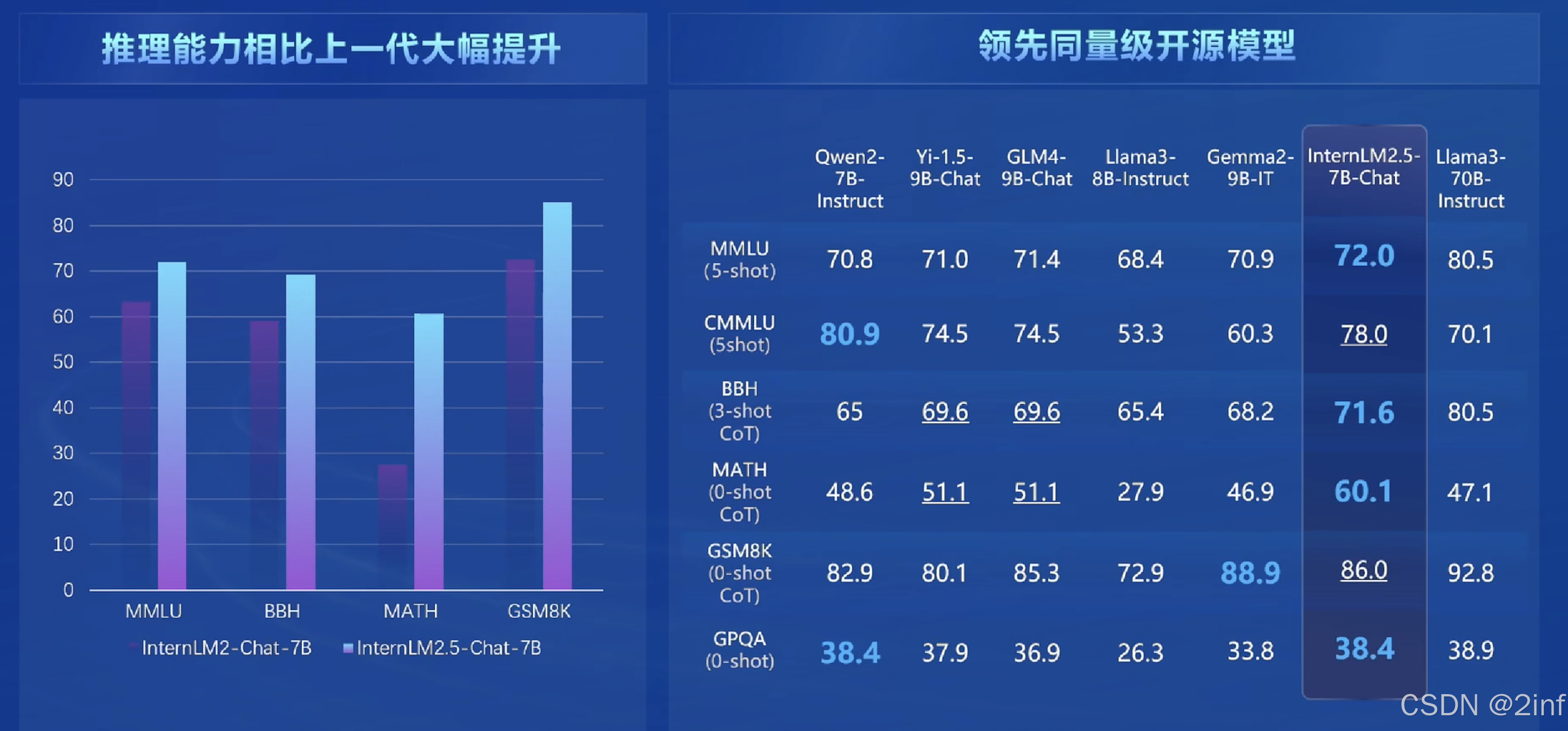
-
100万 Token 上下文的理解和精确处理
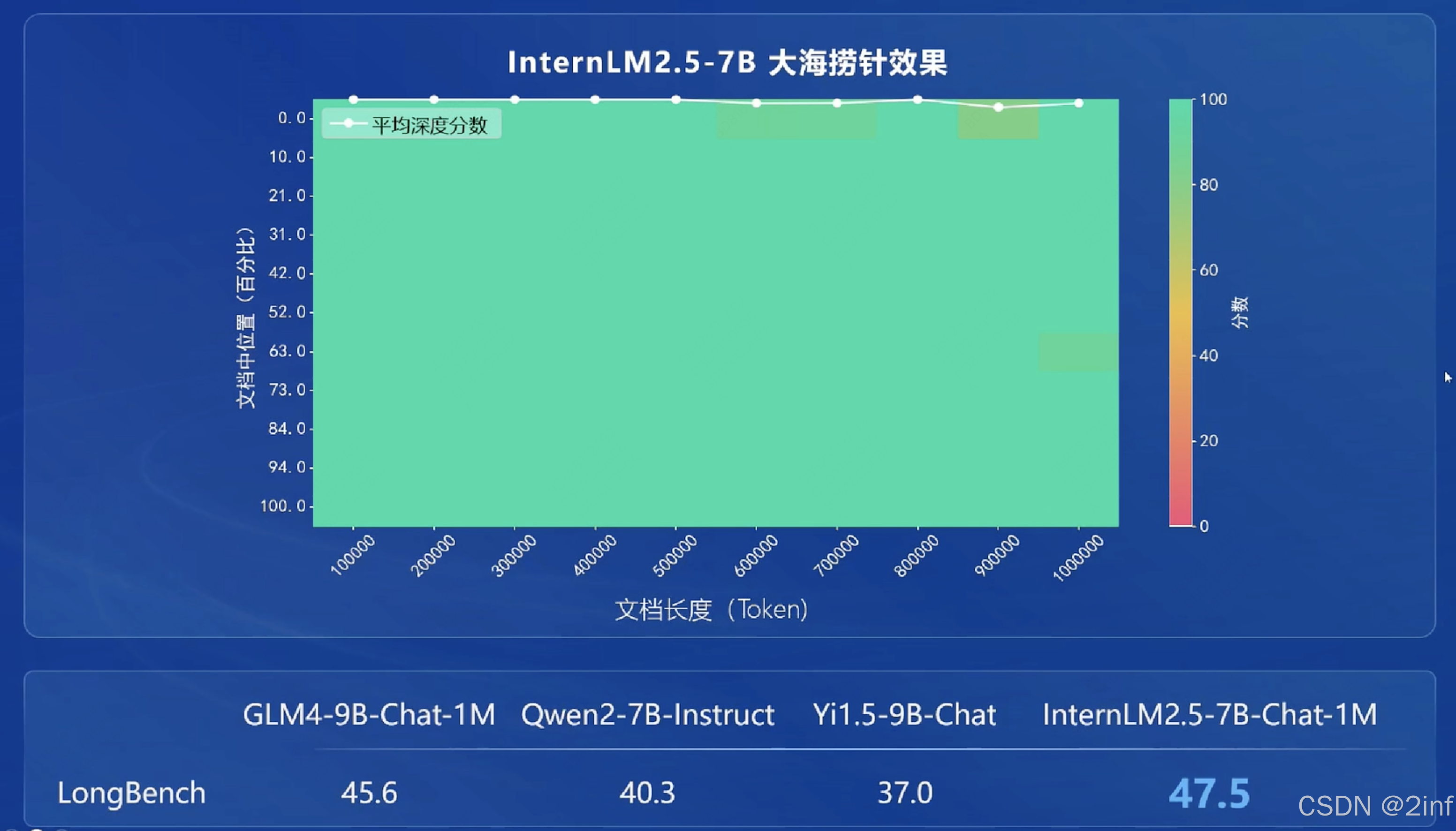
以往 RAG 拆分向量化,对于跨文档存在困难。 -
基于规划和搜索解决复杂问题
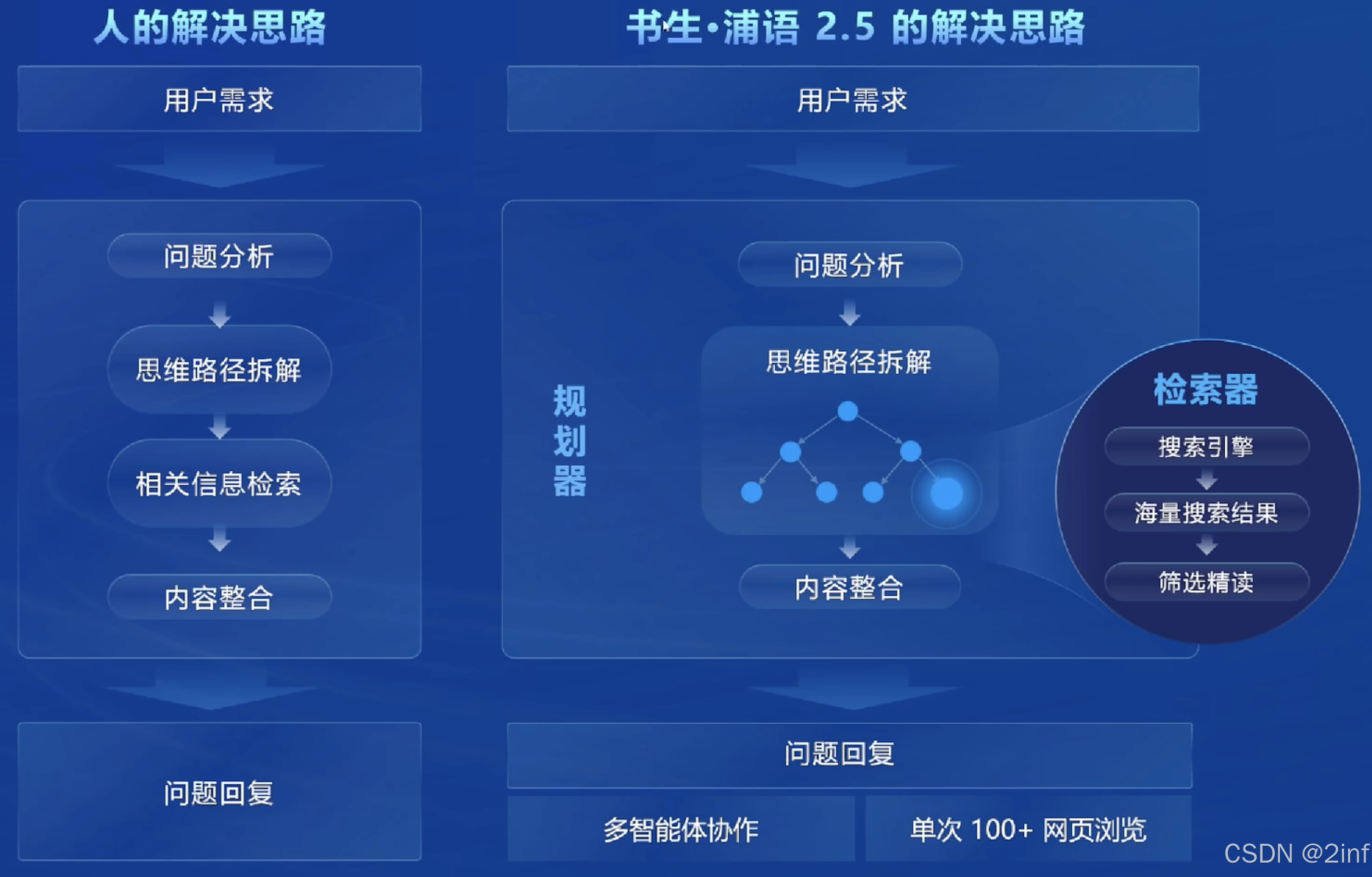
-
书生·浦语开源模型谱系
-
按参数规模
- 1.8B:超轻量级,可用于端侧应用或者开发者快速学习上手
- 7B:模型轻便但性能不俗,为轻量级的研究和应用提供强力支撑
- 20B:模型的综合性能更为强劲,可以有效支持更加复杂的实用场景
- 102B:性能强大的闭源模型,典型场景表现接近GPT-4
-
按应用场景
InternLM-XComposer(灵笔):写作
InternLM-Math(数学):解答数学问题
InternLM-WQX(文曲星):考试
全链条开源开放体系

- 数据

-
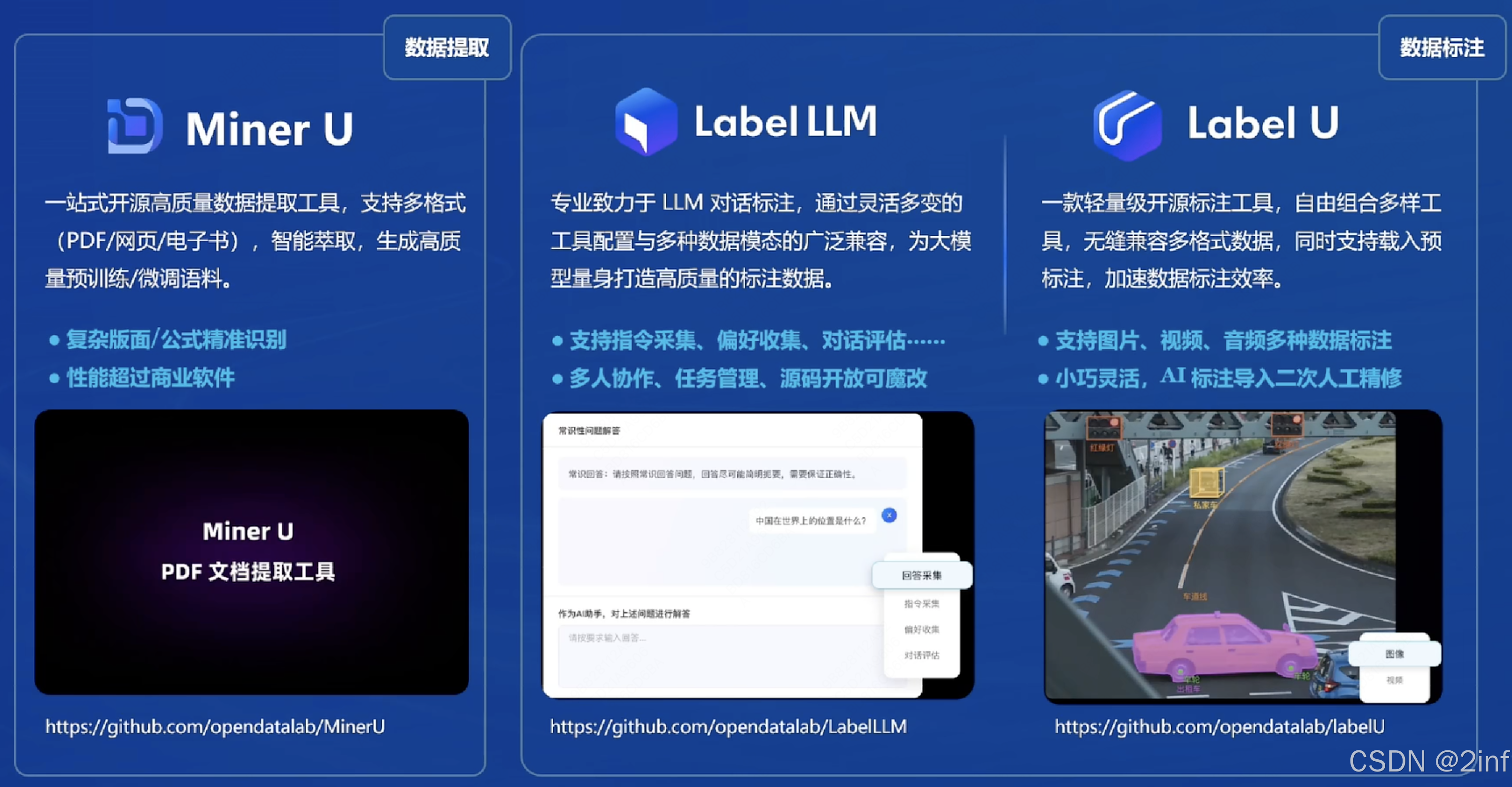
开源数据处理工具箱
- Miner U:一站式开源高质量数据提取工具,支持多格式(PDF/网页/电子书),只能萃取,生成高质量预训练/微调语料
- Label LLM:专业致力于LLM对话标注,通过灵活多变的工具配置与多种数据模态的广泛兼容,为大模型量身打造高质量的标注数据
- Label U: 一款轻量级开源标注工具,自由组合多样工具,无缝兼容多格式数据,同时支持载入预标注,加速数据标注效率
-
预训练 InternEvo
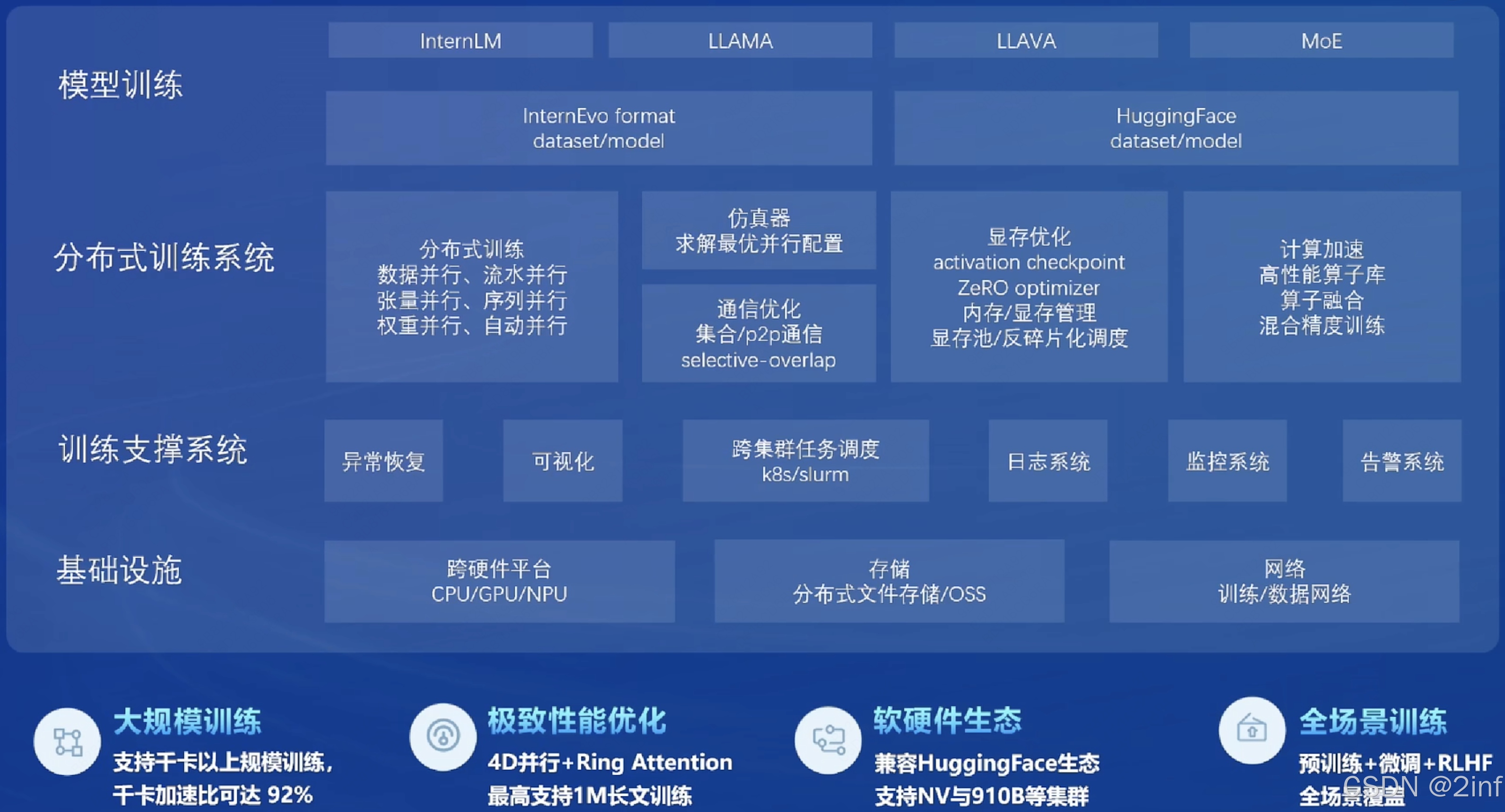
- 微调 Xtuner

- OpenCompass 评测体系

工具(支撑高效评测支持能力分析)-基准(提供高时效性高质量评测集)-榜单(发布权威榜单,洞悉行业趋势)三位一体
- 部署 LMDeploy
部署框架:LMDeploy支持多种开源模型和国产大模型的部署,提供 Python、RESTful、GRPC 等推理接口,支持 TurboMind 和 PyTorch 推理引擎,以及 LayOpenAI 服务和Gradial、TreeTone 推理服务。

-
智能体
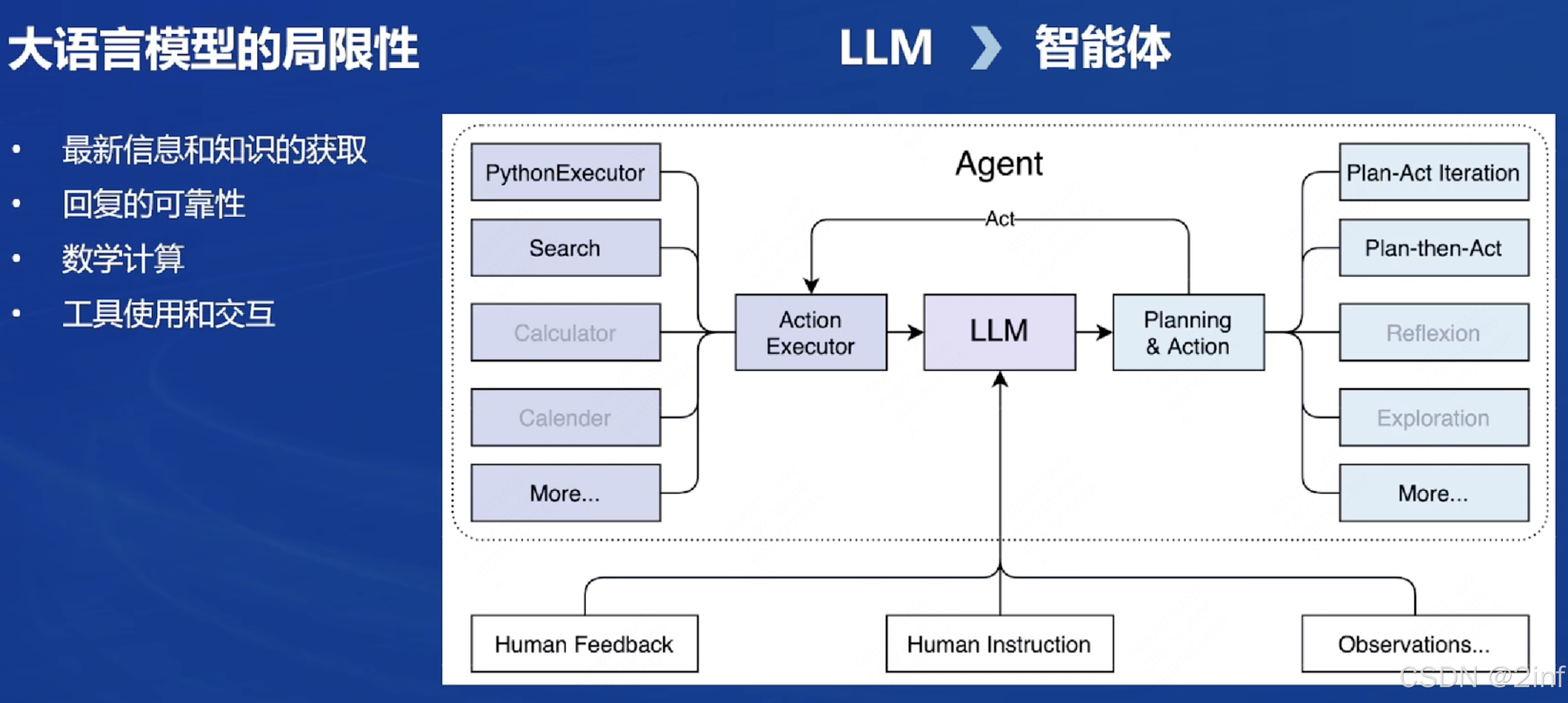
-
企业级知识库构建工具

总结
课程详细介绍了书生·浦语大模型的开源开放体系及其发展历程,使我深刻理解了开源在推动技术进步和知识共享中的重要性,同时也激发了我参与开源社区、贡献力量的热情。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









