






大多数开源LLM框架中,都会需要指定LLM参数。这些参数通常是用一个词典—— llm_kwargs 来存储。
使用案例
answer_generator = LLMChain(
llm=MY_LLM,
prompt=PROMPT,
llm_kwargs={
"max_new_tokens": 512,
"top_p": 0.9,
"temperature": 0.6,
"repetition_penalty": 1.2,
"do_sample": True,
}
)常用参数列表
(参考LangChain官网:langchain_community.llms.huggingface_endpoint.HuggingFaceEndpoint — 🦜🔗 LangChain 0.1.12)
| 参数名 | 参数类型 = 默认值 (HuggingFace) | 描述 |
| temperature | Optional[float] = 0.8 | 较低的温度会使LLM更加诚实,较高的温度会更加有创造力(范围0-1)如果是0,则给定相同输入,每次输出结果不变。 (HuggingFace 默认值 0.8,LangChain默认值0.7) 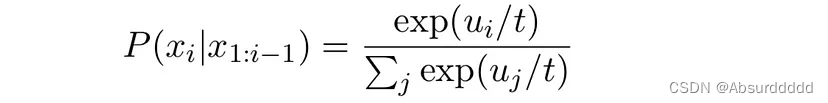 |
| max_new_tokens | int = 512 | 最大生成的tokens数量。 |
| top_p | Optional[float] = 0.95 | 采样涉及的百分比(top percentage)只考虑前百分之多少进行采样。(范围0-1) |
| top_k | Optional[int] = None | 只采样排名前k个词,根据likelihood scores 来采样。(范围1-正无穷)如果取值为1,则和greedy decoding 效果一样。 |
| repetition_penalty | Optional[float] = None | 重复生成的惩罚。惩罚之前生成过的token。降低该token的概率。(范围1-正无穷) 取值为1.0意味着不惩罚。
|
| do_sample | bool = False | 是否激活概率采样,能激活的采样可以是:多项式抽样、束搜索多项式抽样、Top-K抽样和Top-p抽样。(temperature、top_p、top_k都是基于概率采样的方式,所以要求do_sample=True才可以起作用) |
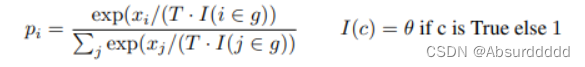
Top_p 通常设置为一个较高的值(如 0.75),目的是限制低概率选项。同时使用 top_k 和 top_p ,则意味着:既满足 top_k 又满足 top_p。如果同时启用 k 和 p,top_p 将在 top_k 之后起作用。
参考文献(推荐阅读)
LLM的decoding策略:https://towardsdatascience.com/decoding-strategies-that-you-need-to-know-for-response-generation-ba95ee0faadc
Hugging Face 文本生成策略以及对应的参数设置:
https://huggingface.co/docs/transformers/generation_strategies
top_k 和 top_p 的区别:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









