







今天又是给大家分享一个最近练手django的一个简易数据分析可视化的项目,以下是该项目的简单介绍。
项目名称:中国高校数据可视化分析项目。
项目实现功能:
1:登录以及注册(相关信息保存在mysql数据库中)
2:数据爬虫获取相关数据存放在csv文件和MySQL数据库里。
3:数据可视化分析展示(ep:高校地区分布,各省份的本科和专科的占比,各省份的211/985数量分布占比,全国高校录取分布排行榜,全国高校数据直达,全国开设专业数量排行榜,办学类型占比,就业前五大专业以及各个行业的工资情况和各高校专业学科等级分类等等)
4:引入中间件技术,提高网页的安全性,防止无缓存账号信息的跨页面访问。
5:较为和谐的前端布局以及自定义404报错动画页面。
项目涉及技术:
前端(html,css,javascript),mysql数据库,echars可视化工具,python基础以及爬虫及数据分析,django模板框架。
接下来我把项目结构图先附上:

data:存放爬虫以及现成csv文件数据。
middleware:中间件(放在无缓存账户信息的跨页面登录).
spilder:爬虫实现。
static:前端样式集合(css,js)。
tempates:前端html页面文件夹。
models:数据库。
views:数据分析业务函数。
以上为项目主要的结构说明,其他相关结构便不在此做相关说明解释。
接下来我将放置其中的一张数据分析效果图,并详细介绍是如何实现的,以及后端的数据是如何传递到并且在前端页面显示的。
如下:
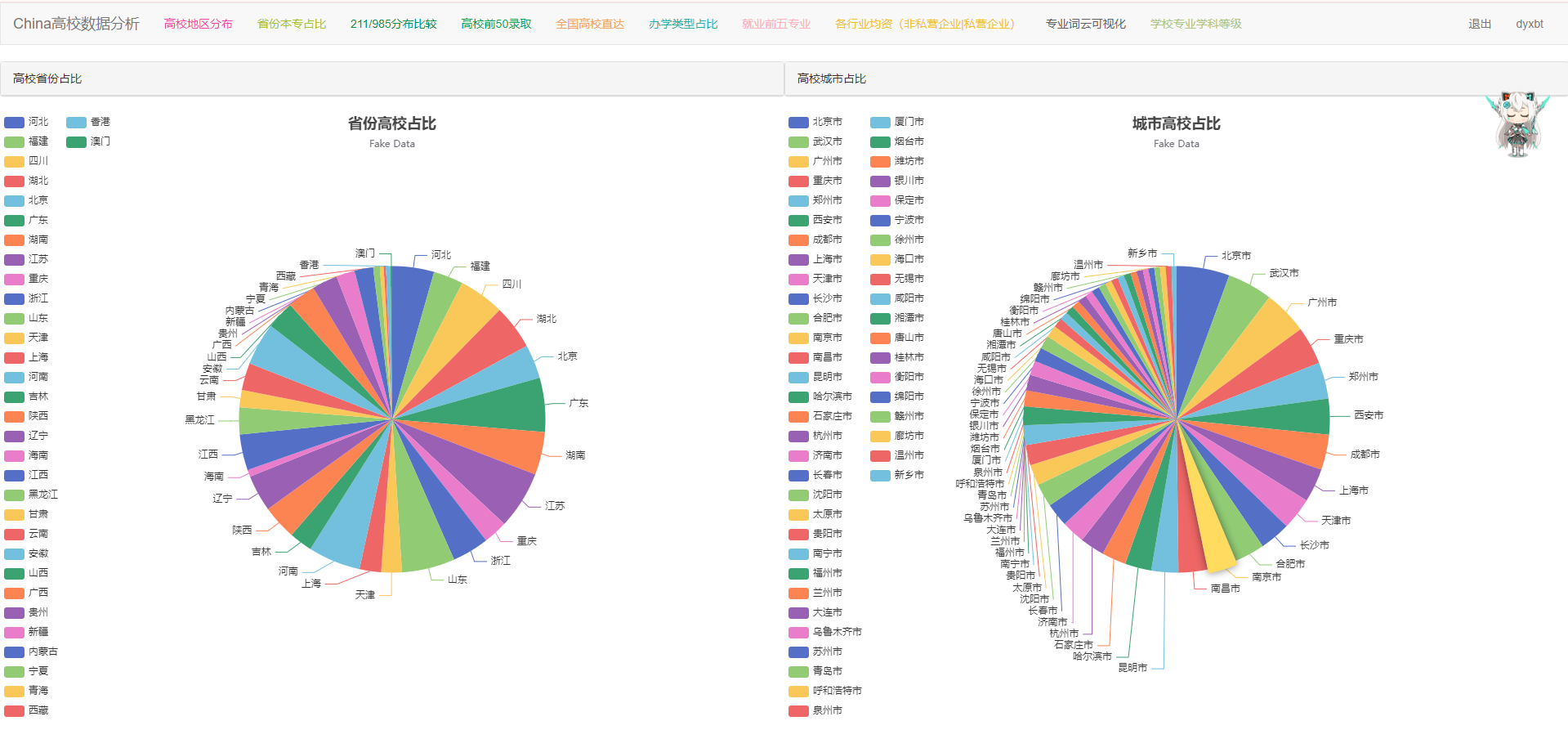
这个页面我做啦全国高校的省份和城市的数量圆形分布占比,我们一个一个分析来看。
先看左边的省份高校占比:
第一步:我们要进入echars官网,首先要选取我们的数据最终要展示为什么样的样式,比如说我们就选取饼图的pie的第一个样式(某站点用户Access From)如下:

我们进入他的代码编辑部分可以发现,他的数据部分为data字段(列表里嵌套许多小字典):

所以我们需要将我们的最终数据形式处理成和echars中js代码段的形式一样即可(列表里嵌套小字典)
第二步:现在便是重要的一步啦,如何将我们的数据从csv或者数据库里提取出来最终处理成我们所需要的样子呢?
我先说一下大概思路:我们可以发现字典的样式是 { value: 1048, name: 'Search Engine' },对应我们项目的数据应该把value字段的属性值1048替换成我们的具体省份名称,把name字段的属性值替换成我们具体某统一省份的具体含有高校的数量即可。
为了方便我把这段数据的处理部分的代码复制过来,针对代码来做具体讲解:
def schooladdress(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
selected_field_city = '省份'
selected_field_city_second = '城市'
selected_values_numschool = []
selected_values_numschool_second = []
with open(filename, 'r', encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
selected_values_numschool.append(row.get(selected_field_city))
selected_values_numschool_second.append(row.get(selected_field_city_second))
distData = {}
distData_second={}
for job in selected_values_numschool:
if distData.get(job, -1) == -1:
distData[job] = 1
else:
distData[job] += 1
result = []
for k, v in distData.items():
result.append({
'value': v,
"name": k
})
for job in selected_values_numschool_second:
if distData_second.get(job, -1) == -1:
distData_second[job] = 1
else:
distData_second[job] += 1
result_second = []
for k, v in distData_second.items():
result_second.append({
'value': v,
"name": k
})
sorted_data = sorted(result_second, key=lambda x: x['value'], reverse=True)[:50 ] # 按成绩倒序排序并获取前50个字典
result_second = sorted_data # 将排序后的结果保存在新的列表中
python_data_address=result
python_data_address_second=result_second
return render(request,'schooladdress.html',{"html_data_address":python_data_address,
"html_data_address_second":python_data_address_second,
"userInfo":username})
我们省份字段名称赋予变量selected_field_city,创建空列表selected_values_numschool,然后遍历csv目标文件使用selected_values_numschool.append(row.get(selected_field_city))函数方法便可得到一个列表里面放了csv文件的全部省份信息,诸如【‘河南’,‘安徽’,‘山东’,‘浙江’,‘江苏’,‘河南’,‘安徽’,‘广东’,‘福建’,‘四川’,‘河南‘..........】,接着我们要创建一个空字典,然后
循环遍历该刚才列表for job in selected_values_numschool:
if distData.get(job, -1) == -1:distData[job] = 1
else:distData[job] += 1
这段意思是如何字典没有该省份名称即-1(不存在)则使其的数量设为1,若已经存在则使其的数量加1即可,得到的形式诸如:{’‘河南省’:120,‘安徽省’:110,‘山东省’:100.......}
result = []
for k, v in distData.items():
result.append({value': v,"name": k})
接着创建一个空列,因为是字典,所以k,v遍历刚刚得到的字典集,将字典里的每一个item的v(属性值·)赋值给value字段,将item的k(属性值)省份名称赋值给name字段,后将其追加到新创建的result列表中,最终便得到了如下的样式【{value': 120‘,"name": ’河南省‘},{value': 110,"name": ’安徽省‘},{value': 100,"name": ’山东省‘}........】
我们假设变量html_data_pro=【{value': 120‘,"name": ’河南省‘},{value': 110,"name": ’安徽省‘},{value': 100,"name": ’山东省‘}........】
也即是我们最终需要的数据样式(和echars相契合)
第三步:此时我们已近得到我们需要的数据,接下来就是把数据传递到前端js的位置就可以啦,因为前端的整体布局我引用bootstrap已近搭建好啦,我们把echars的代码直接复制粘贴到前端html页面的js部分区域,接着将第一开始echars的data字段区域(上图标记的蓝色区域)替换成{{html_data_pro | safe}}即可完成。
到此位置我们的省份高校占比页面内容部分即完毕,至于城市高校占比我们只需要对得到的数据进行排序切片即可sorted_data = sorted(result_second, key=lambda x: x['value'], reverse=True)[:50 ]取到该城市含有高校数量最多的前50个城市,然后将数据在前端使用django模板语言渲染即可。
以上便是高校地区分布页面的实现流程,至于其他页面的数据处理实现思路大同小异,具体的下次再做细节补充吧,我把关键的代码粘贴至此:
views:
import django
from django.core.paginator import Paginator
from myapp.models import User,schools,Subjects
django.setup()
import hashlib
from django.shortcuts import render, redirect,reverse
import csv
from .error import *
import os
import pandas as pd
path = os.path.abspath('.')
filename = os.path.join(path,'myapp\data\school.csv')
# 登录页面
def login(request):
if request.method == 'GET':
return render(request, 'login.html')
else:
uname = request.POST.get('username')
pwd = request.POST['password']
md5 = hashlib.md5()
md5.update(pwd.encode())
pwd = md5.hexdigest()
try:
user = User.objects.get(username=uname,password=pwd)
request.session['username'] = user.username
return redirect('index')
except:
return errorResponse(request, '用户名或密码错误!')
# 注册页面
def registry(request):
if request.method == 'GET':
return render(request, 'register.html')
else:
uname = request.POST.get('username')
pwd = request.POST.get('password')
checkPWD = request.POST.get('checkPassword')
try:
User.objects.get(username=uname)
except:
if not uname or not pwd or not checkPWD:return errorResponse(request, '不允许为空!')
if pwd != checkPWD:return errorResponse(request, '两次密码不符合!')
md5 = hashlib.md5()
md5.update(pwd.encode())
pwd = md5.hexdigest()
User.objects.create(username=uname,password=pwd)
return redirect('login')
return errorResponse(request, '该用户已被注册')
# 985/211数量分布
def schoolgrade(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 获取项目根目录
file_path = os.path.join(BASE_DIR, 'myapp/data/school.csv') # 拼接文件路径
data = pd.read_csv(file_path)
list_211=[]
list_985=[]
# 211/985城市占比分布图
unique_values = data['省份'].unique()
for i in unique_values:
list_211.append(len(data[(data['211'] == '是') & (data['省份'] == i)]))
list_985.append(len(data[(data['985'] == '是') & (data['省份'] == i)]))
html_data_grade1 = list_211
html_data_grade2 = list_985
html_data_city = unique_values
# print(html_data_city, html_data_grade1, html_data_grade2)
return render(request, "school92type.html", {"html_data_city":html_data_city, "html_data_grade1":html_data_grade1, "html_data_grade2":html_data_grade2, "userInfo":username})
# 高校地区分布
def schooladdress(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
selected_field_city = '省份'
selected_field_city_second = '城市'
selected_values_numschool = []
selected_values_numschool_second = []
with open(filename, 'r', encoding='utf-8') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
selected_values_numschool.append(row.get(selected_field_city))
selected_values_numschool_second.append(row.get(selected_field_city_second))
distData = {}
distData_second={}
for job in selected_values_numschool:
if distData.get(job, -1) == -1:
distData[job] = 1
else:
distData[job] += 1
# {“北京”:1,“河南”:2}
result = []
for k, v in distData.items():
result.append({
'value': v,
"name": k
})
for job in selected_values_numschool_second:
if distData_second.get(job, -1) == -1:
distData_second[job] = 1
else:
distData_second[job] += 1
result_second = []
for k, v in distData_second.items():
result_second.append({
'value': v,
"name": k
})
sorted_data = sorted(result_second, key=lambda x: x['value'], reverse=True)[:50 ] # 按成绩倒序排序并获取前50个字典
result_second = sorted_data # 将排序后的结果保存在新的列表中
python_data_address=result
python_data_address_second=result_second
return render(request,'schooladdress.html',{"html_data_address":python_data_address,
"html_data_address_second":python_data_address_second,
"userInfo":username})
# 高校录取分数
def schoolsrank(request):
username = request.session.get("username")
types = schools.objects.values_list('location', flat=True).distinct()
# 将城市放入列表中
typelist = list(types)
list1 = [];
list1_name = [];
list2 = [];
list2_name = []
cityname = request.GET.get('cityname')
print(cityname)
print('hello')
if cityname not in typelist:
obj1 = schools.objects.all().order_by('-score')[0:10]
obj2 = schools.objects.all().order_by('-star_ranking')[0:10]
for i in obj1:
list1_name.append(i.school_name)
list1.append({'value': i.score, 'name': i.school_name})
for i in obj2:
list2_name.append(i.school_name)
list2.append({'value': i.star_ranking[0], 'name': i.school_name})
context = {"userInfo": username, "list1": list1, "list1_name": list1_name, "list2": list2,
'list2_name': list2_name, 'typelist': typelist}
else:
obj1 = schools.objects.all().filter(location=cityname).order_by('-score')[0:10]
obj2 = schools.objects.all().filter(location=cityname).order_by('-star_ranking')[0:10]
for i in obj1:
list1_name.append(i.school_name)
list1.append({'value': i.score, 'name': i.school_name})
for i in obj2:
list2_name.append(i.school_name)
list2.append({'value': i.star_ranking[0], 'name': i.school_name})
context = {"userInfo": username, "list1": list1, "list1_name": list1_name, "list2": list2,
'list2_name': list2_name, 'typelist': typelist}
return render(request, 'schoolsrank.html',context)
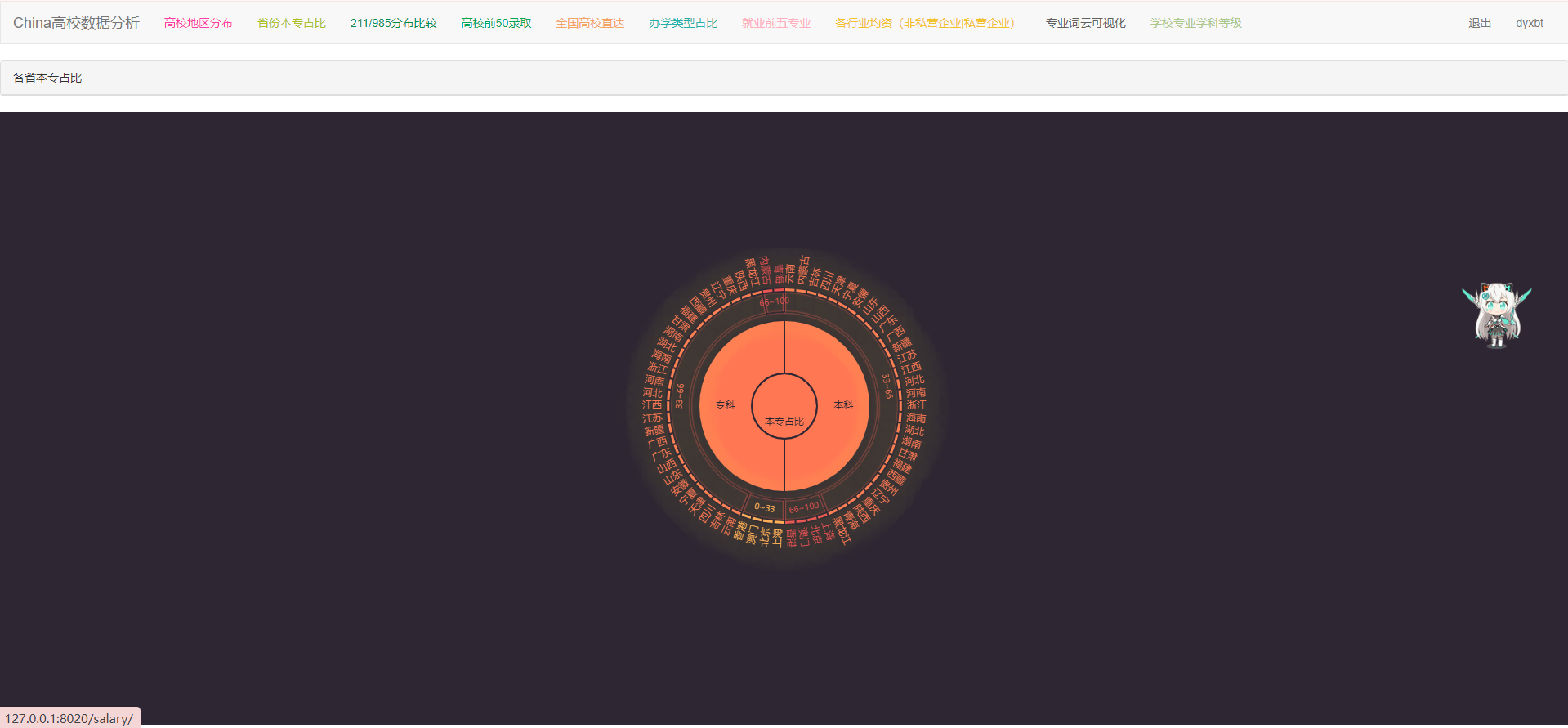
def school_benzhuan(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 获取项目根目录
file_path = os.path.join(BASE_DIR, 'myapp/data/school.csv') # 拼接文件路径
# data = pd.read_csv(file_path)
df = pd.read_csv(file_path, encoding='utf-8')
new_df = df[["省份", "水平层次"]]
new_df_grouped = new_df.groupby("省份")
undergraduate_res_ls = []
specialty_res_ls = []
undergraduate_low_dict = {'name': "0~33", 'children': []}
undergraduate_middle_dict = {'name': "33~66", 'children': []}
undergraduate_upper_dict = {'name': '66~100', 'children': []}
specialty_low_dict = {'name': "0~33", 'children': []}
specialty_middle_dict = {'name': "33~66", 'children': []}
specialty_upper_dict = {'name': '66~100', 'children': []}
for i, j in new_df_grouped:
area_dict = {'name': i}
undergraduate_rate = j.loc[j["水平层次"] == "普通本科"].count() / j.value_counts().sum()
specialty_rate = j.loc[j["水平层次"] == "专科(高职)"].count() / j.value_counts().sum()
undergraduate_rate = float(undergraduate_rate[0])
specialty_rate = float(specialty_rate[0])
if undergraduate_rate < 0.33:
undergraduate_low_dict['children'].append(area_dict)
elif undergraduate_rate < 0.66:
undergraduate_middle_dict['children'].append(area_dict)
else:
undergraduate_upper_dict['children'].append(area_dict)
if specialty_rate < 0.33:
specialty_low_dict['children'].append(area_dict)
elif specialty_rate < 0.66:
specialty_middle_dict['children'].append(area_dict)
else:
specialty_upper_dict['children'].append(area_dict)
undergraduate_res_ls.append(undergraduate_low_dict)
undergraduate_res_ls.append(undergraduate_middle_dict)
undergraduate_res_ls.append(undergraduate_upper_dict)
specialty_res_ls.append(specialty_low_dict)
specialty_res_ls.append(specialty_middle_dict)
specialty_res_ls.append(specialty_upper_dict)
html_data_ben=undergraduate_res_ls
html_data_zhuan=specialty_res_ls
return render(request,'schoolbenzhuan.html',{'html_data_ben':html_data_ben,'html_data_zhuan':html_data_zhuan,"userInfo":username})
def read_csv_file(file_path):
data = []
with open(file_path, 'r', encoding='utf-8') as csv_file:
reader = csv.DictReader(csv_file)
for row in reader:
data.append(row)
return data
# 全国高校直达
def school_list(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 获取项目根目录
csv_file_path = os.path.join(BASE_DIR, 'myapp/data/school.csv') # 拼接文件路径
schools = read_csv_file(csv_file_path)
# 获取选择的省份
selected_province = request.GET.get('province')
all_provinces = set([school['省份'] for school in schools])
# 筛选学校数据
if selected_province:
schools = [school for school in schools if school['省份'] == selected_province]
# 处理分页
paginator = Paginator(schools, 10) # 每页显示10条数据
page_number = request.GET.get('page')
page = paginator.get_page(page_number)
context = {
'schools': page,
'selected_province': selected_province,
'all_provinces': all_provinces,
"userInfo":username
}
return render(request, 'schoolget.html', context)
# 注销
def cancel(request):
username = request.session.get("username")
obj = User.objects.get(username=username)
obj.delete()
return render(request, 'login.html')
# 就业率
def workrate(request):
username = request.session.get("username")
return render(request,'workrate.html',{ "userInfo":username})
# 办学类型
def schoolstate(request):
username = request.session.get("username")
userInfo = User.objects.get(username=username)
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 获取项目根目录
file_path = os.path.join(BASE_DIR, 'myapp/data/school.csv') # 拼接文件路径
# 统计某一字段的值的数量
data = pd.read_csv(file_path)
value_counts0 = data['办学类型'].value_counts()[0]
value_counts1 = data['办学类型'].value_counts()[1]
value_counts2 = data['办学类型'].value_counts()[2]
total = value_counts0 + value_counts1 + value_counts2
return render(request,'schoolstate.html',{"html_data_state0":value_counts0,'html_data_state1':value_counts1,"html_data_state2":value_counts2,"total":total,"userInfo":username})
# 行业均资
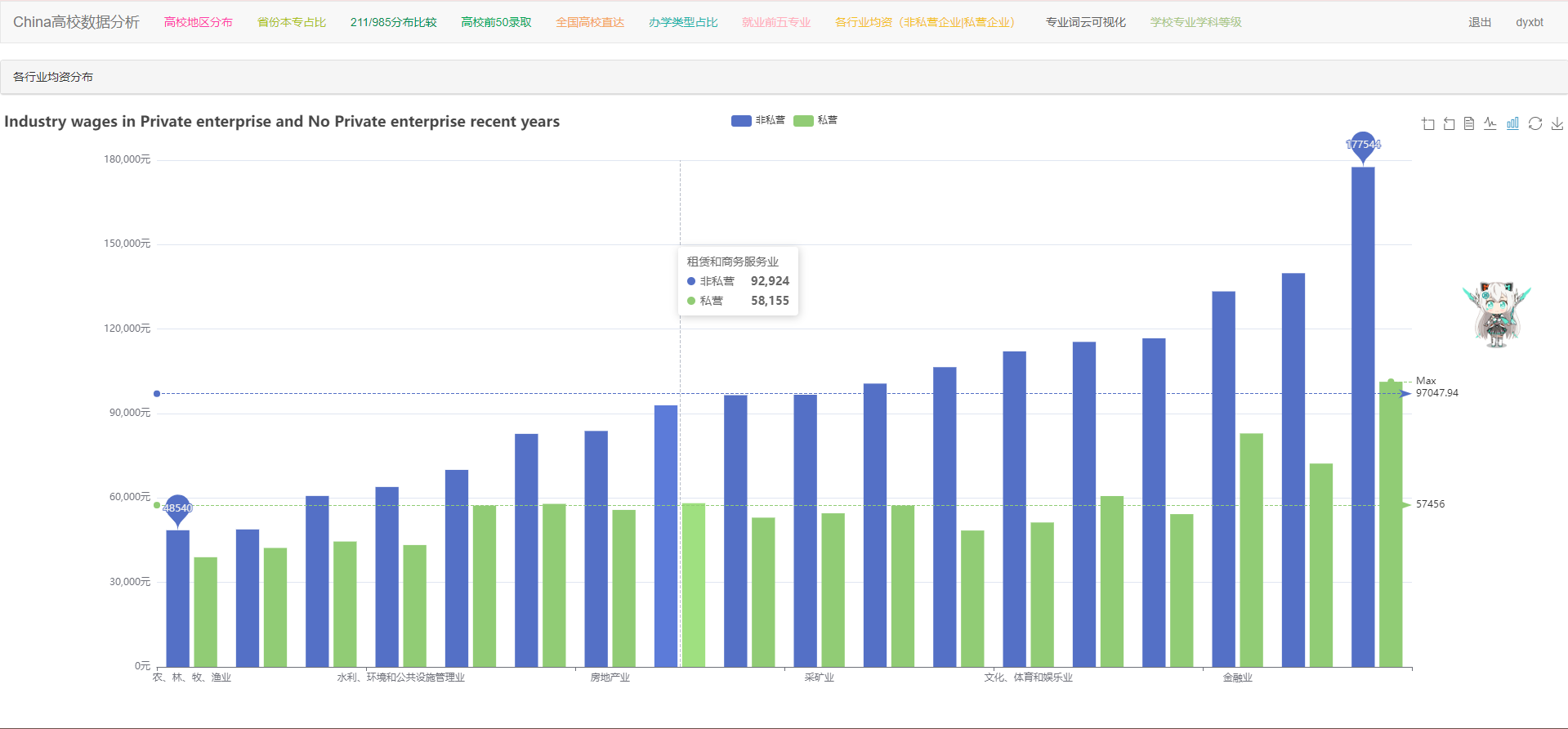
def salary(request):
username = request.session.get("username")
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 获取项目根目录
file_path = os.path.join(BASE_DIR, 'myapp/data/salary.csv') # 拼接文件路径
data = pd.read_csv(file_path)
def get_column_values(csv_file, column_name):
values = []
with open(csv_file, 'r', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
values.append(row[column_name])
return values
csv_file = file_path
column_major = '行业'
column_noself = '非私营单位就业人员平均工资(元)'
column_self = '私营单位就业人员平均工资(元)'
column_values = get_column_values(csv_file, column_major)[::-1]
column_noself_values = get_column_values(csv_file, column_noself)[::-1]
column_self_values = get_column_values(csv_file, column_self)[::-1]
html_data_major=column_values
html_data_noself=column_noself_values
html_data_self=column_self_values
return render(request,'salary.html',{'html_data_major':html_data_major,'html_data_noself':html_data_noself,'html_data_self':html_data_self,"userInfo":username})
def majorciyun(request):
username = request.session.get("username")
return render(request, 'wordcloud.html', {'userInfo':username})
def schoolsub(request):
username = request.session.get("username")
subtypes = Subjects.objects.values_list('subtype', flat=True).distinct()
subtypelist = list(subtypes)
results = Subjects.objects.values_list('result', flat=True).distinct()
resultslist = list(results)
subtypename=request.GET.get('subtypename');resultname=request.GET.get('resultname')
print(subtypename,resultname)
if subtypename and (resultname not in resultslist):
subobj=Subjects.objects.all().filter(subtype=subtypename)
elif resultname and (subtypename not in subtypelist):
subobj=Subjects.objects.all().filter(result=resultname)
elif subtypename and resultname:
subobj=Subjects.objects.all().filter(subtype=subtypename,result=resultname)
else:
subobj=Subjects.objects.all()
context = {'subjects': subobj, 'subtypelist': subtypelist, 'resultslist': resultslist, 'userInfo': username}
return render(request, 'schoolsub.html',context)
def schoolscore(request):
defaultType = '不限'
schoolnamelist=[];liberalartslist=[];sciencelist=[]
provincenames=schools.objects.all().values_list('location', flat=True).distinct()
provincenamelist=list(provincenames)
proname=request.GET.get('proname')
for i in schools.objects.all().filter(location=proname):
schoolnamelist.append(i.school_name)
liberalartslist.append(i.liberalarts)
sciencelist.append(i.science)
context = {'provincenamelist':provincenamelist,'schoolnamelist': schoolnamelist, 'liberalartslist':liberalartslist, 'sciencelist':sciencelist, 'defaultType':defaultType, 'proname':proname}
return render(request, 'schoolscore.html',context)分装好函数方法后,然后在url上经行地址调用就好了





 最后我把使用matplotlib绘制词云的流程和代码说一下:
最后我把使用matplotlib绘制词云的流程和代码说一下:
- 导入需要的包,如numpy、PIL、matplotlib、wordcloud、pandas和jieba等。
- 对文本进行分词处理,可以使用jieba分词库,将文本分割成一个个词语,并去除停用词。
- 统计每个词语出现的频率,生成词频字典。
- 根据词频字典生成词云图,可以设置词云图的形状、颜色、字体等参数。
- 将生成的词云图保存到本地或者展示在网页上。
import matplotlib.pyplot as plt
import pandas as pd
import jieba
from wordcloud import WordCloud
import os
# 读取csv文件并进行数据处理
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
file_path = os.path.join(BASE_DIR, 'myapp/data/professional.csv')
df = pd.read_csv(file_path)
text = ''.join(df['专业名称'].tolist())
stopwords = set(open('stopwords.txt', 'r', encoding='utf-8').read().split('\n'))
words = [word for word in jieba.cut(text) if word not in stopwords]
# print(words)
# 将处理后的数据转化为字典格式
word_dict = {}
for word in words:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 1
# 生成词云图
# wordcloud = WordCloud(background_color='white').generate_from_frequencies(word_dict)
wordcloud = WordCloud(font_path='msyh.ttc', background_color='white', width=800, height=600)
wordcloud.generate_from_frequencies(word_dict)
plt.imshow(wordcloud)
plt.axis('off')
plt.savefig('ciyun.jpg')
plt.show()今天先写到这里,明天再继续编辑,就先暂时发布啦,另外如果需要该项目的同学可以私信我,项目中如果有不足的地方还请雅正,睡觉了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











