







前言:
1:利用Python爬虫对实习僧招聘岗位进行数据爬去,输出之后存放在MySQL数据库;
2:使用Pythonweb的Django框架对数据进行可视化图表展示(Echarts);
3:实现了首页数据的指标展示,用户个人基本信息的修改,数据的分页总览以及针对数据库招聘岗位数据信息的字段维度进行可视化图表分析;
4:难度中等,容易上手,页面比较和谐,易二次开发,适合广大中等学生作为学习的参考项目;
项目基本结构:
爬虫代码:
import requests
from bs4 import BeautifulSoup
from lxml import html
import pymysql
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36" }
cnx = pymysql.connect(
host="localhost",
user="root",
password="123456",
database="sxcsql",
#charset='utf8'
)
# 创建游标对象
cursor = cnx.cursor()
a='java'
def detail_url(url):
global a
html1 = requests.get(url, headers=headers).text
soup = BeautifulSoup(html1, 'lxml')
title = soup.title.text
job = title.split("招聘")[0]
company_name = soup.select('.com_intro .com-name')[0].text.strip()
address = soup.select('.job_position')[0].text.strip()
academic = soup.select('.job_academic')[0].text.strip()
good_list = soup.select('.job_good_list')[0].text.strip()
salary = soup.select(".job_money.cutom_font")[0].text.encode("utf-8")
workday = soup.select(".job_week.cutom_font")[0].text.encode("utf-8").decode('utf-8')
worktime = soup.select(".job_time.cutom_font")[0].text.encode("utf-8").decode('utf-8')
salary = salary.replace(b'\xee\x8b\x92', b"0")
salary = salary.replace(b'\xee\x9e\x88', b"1")
salary = salary.replace(b'\xef\x81\xa1', b"2")
salary = salary.replace(b'\xee\x85\xbc', b"3")
salary = salary.replace(b'\xef\x84\xa2', b"4")
salary = salary.replace(b'\xee\x87\x99', b"5")
salary = salary.replace(b'\xee\x9b\x91', b"6")
salary = salary.replace(b'\xee\x94\x9d', b"7")
salary = salary.replace(b'\xee\xb1\x8a', b"8")
salary = salary.replace(b'\xef\x86\xbf', b"9")
salary = salary.decode()
html1 = requests.get(url, headers=headers).text
tree = html.fromstring(html1)
company_avatar=tree.xpath('//*[@id="__layout"]/div/div[2]/div[1]/div[2]/div[2]/div[2]/div[2]/div[1]/a[1]/img/@src')[0]
if '-' in salary:
salary = int(int(salary.split('-')[0]) + int(salary.split('-')[1].split('/')[0])) / 2
elif salary=='面议':
salary=150
else:
salary=int(salary.split('/')[0])
# print(company_avatar,job, salary, company_name, address, workday,worktime,academic,good_list,url)
# 开始存入数据库
insert_query = "INSERT INTO jobinfo (avatar,type,title,money,companyname,address,workday,workmonth,education,tag,link) VALUES (%s, %s, %s,%s, %s, %s,%s, %s, %s,%s, %s)"
data = (company_avatar,a,title,salary,company_name,address,workday,worktime,academic,good_list,url)
print(company_avatar,a,title,salary,company_name,address,workday,worktime,academic,good_list,url)
cursor.execute(insert_query, data)
cnx.commit()
data = ()
def job_url():
for i in range(4, 10):
a='java'
req = requests.get(
f'https://www.shixiseng.com/interns?page={i}&type=intern&keyword={a}&area=&months=&days=°ree=本科&official=&enterprise=&salary=-0&publishTime=&sortType=&city=全国&internExtend=',
headers=headers)
html = req.text
soup = BeautifulSoup(html, 'lxml')
offers = soup.select('.intern-wrap.intern-item')
for offer in offers:
url = offer.select(" .f-l.intern-detail__job a")[0]['href']
print(a)
detail_url(url)
print('开始爬取第'+str(i)+"页面")
job_url()
cursor.close()
cnx.close()
项目后端代码:
import json
from django.db.models.functions import Substr
import time
from django.http import HttpResponse
from django.shortcuts import render, redirect
from wordcloud import WordCloud
from myApp.models import User,jobinfo
from django.db.models import Count,Max,F
from django.db.models.functions import Cast, Substr
from django.db.models import IntegerField
from django.core.paginator import Paginator
from myApp.backends import wouldCloud
# Create your views here.
def register(request):
if request.method == 'POST':
name = request.POST.get('name')
password = request.POST.get('password')
phone = request.POST.get('phone')
email = request.POST.get('email')
avatar = request.FILES.get('avatar')
selected_option = request.POST.get('inlineRadioOptions')
if selected_option == '在校学生':
identymes = 1
elif selected_option == '职场工作者':
identymes = 2
User.objects.create(name=name, password=password, phone=phone, email=email, avatar=avatar, identy=1)
msg = "注册成功!"
return render(request, 'login.html', {"msg": msg})
if request.method == 'GET':
return render(request,'register.html')
# Create your views here.
def login(request):
if request.method == 'GET':
return render(request, 'login.html')
if request.method == 'POST':
name = request.POST.get('name')
password = request.POST.get('password')
if User.objects.filter(name=name, password=password):
user=User.objects.get(name=name, password=password)
username=request.session['username'] = {'name':user.name,'avatar':str(user.avatar)}
return redirect('index')
else:
msg = '信息错误!'
return render(request, 'login.html', {"msg": msg})
def logout(request):
request.session.clear()
return redirect('login')
def index(request):
# 用户注册图表可视化展示
users = User.objects.all()
data = {}
for u in users:
if data.get(str(u.time),-1) == -1:
data[str(u.time)] = 1
else:
data[str(u.time)] += 1
result = []
for k,v in data.items():
result.append({
'name':k,
'value':v
})
# 首页上方时间显示
timeFormat = time.localtime()
year = timeFormat.tm_year
month = timeFormat.tm_mon
day = timeFormat.tm_mday
monthList = ["January","February","March","April","May","June","July","August","September","October","November","December"]
username = request.session.get("username").get('username')
useravatar = request.session.get("username").get('avatar')
joblen=jobinfo.objects.all().count();userlen=User.objects.all().count();
# 查询数据库中城市出现次数,并按出现次数降序排列
city_counts = jobinfo.objects.values('address').annotate(count=Count('address')).order_by('-count')[:3]
# 提取出现次数最多的城市,并格式化为所需格式
top_cities = "~".join([city['address'] for city in city_counts])
# 使用聚合函数 Max 获取最高的 money
max_money = jobinfo.objects.aggregate(max_money=Max('money'))
# 获取最高的 money 的值
highest_money = max_money['max_money']
# 获取数据库中 workday 字段的最大值
max_workday_per_week = jobinfo.objects.annotate(workday_num=Cast(Substr('workday', 1, F('workday') - 3), IntegerField())).aggregate(
max_workday_per_week=Max('workday_num')).get('max_workday_per_week')
# 获取每周的实习时间的最大值
max_workmonth_per_week = jobinfo.objects.annotate(workmonth_num=Cast(Substr('workmonth', 3, F('workmonth') - 6), IntegerField())).aggregate(
max_workmonth_per_week=Max('workmonth_num')).get('max_workmonth_per_week')
# 统计每种学历出现的次数,并按出现次数降序排列
education_counts = jobinfo.objects.values('education').annotate(count=Count('education')).order_by('-count')
# 获取出现次数最多的学历
most_common_education = education_counts[0]['education']
context = {'username': username, 'useravatar': useravatar,'userTime':result,'newuserlist':users,'year':year,'month':monthList[month-1],'day':day,
'joblen':joblen,'userlen':userlen,'top_cities':top_cities,'highest_money':highest_money,'max_workday_per_week':max_workday_per_week,
'max_workmonth_per_week':max_workmonth_per_week,'mmost_common_education':most_common_education}
return render(request, 'index.html',context)
def selfinfo(request):
username = request.session.get("username").get('name')
useravatar = request.session.get("username").get('avatar')
userInfo=User.objects.get(name=username)
context={'username':username,'useravatar':useravatar,'userInfo':userInfo}
return render(request, 'selfinfo.html',context)
# 数据总览检举
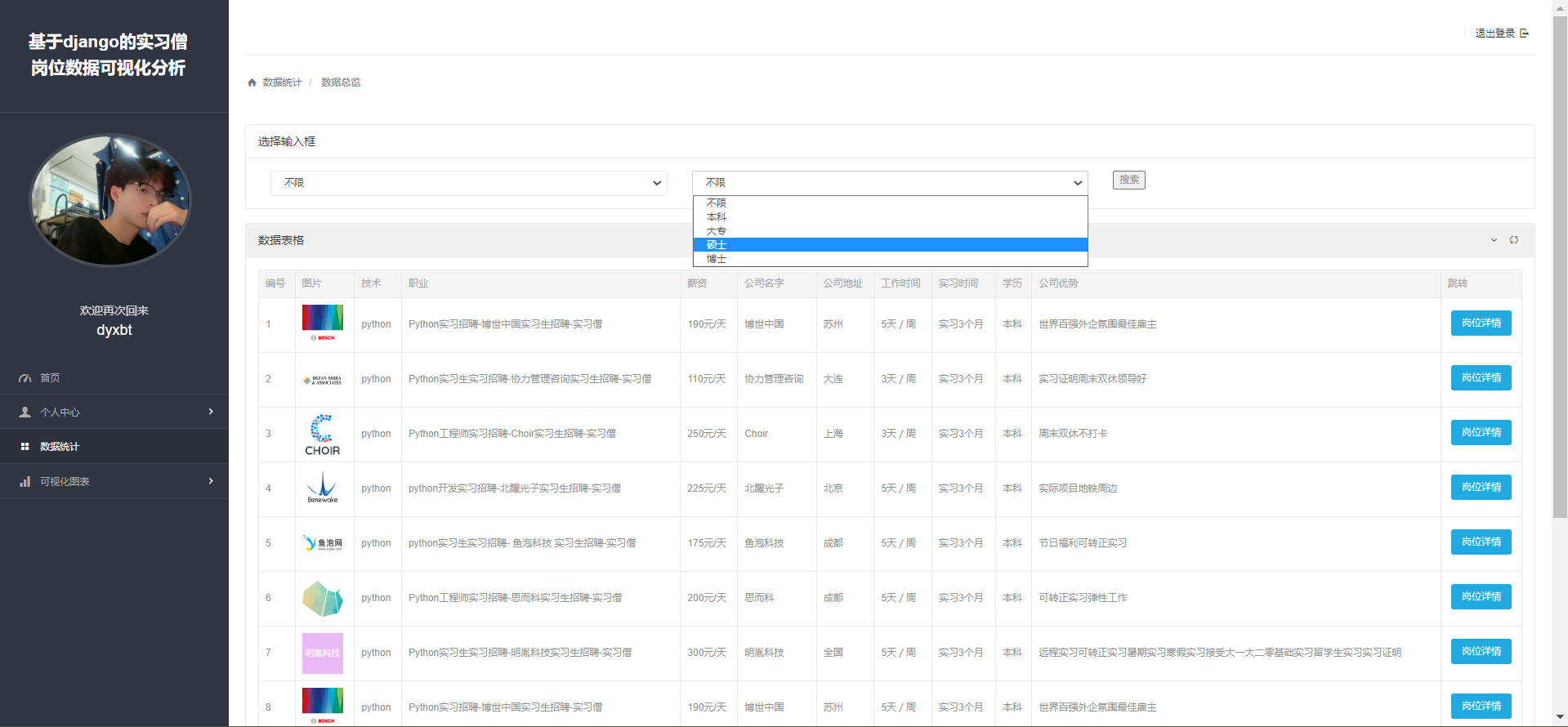
def allJobData(request):
dict_ittype={};dict_education={}
ittypemes = request.GET.get('ittype')
educationmes = request.GET.get('educationtype')
jobinfomes = jobinfo.objects.all()
for d in jobinfo.objects.all():
if dict_ittype.get(d.type, -1) == -1:
dict_ittype[d.type] = 1
else:
dict_ittype[d.type] += 1
ittypes=list(dict_ittype.keys())
for d in jobinfo.objects.all():
if dict_education.get(d.education, -1) == -1:
dict_education[d.education] = 1
else:
dict_education[d.education] += 1
educationtypes=list(dict_education.keys())
if ittypemes:
jobinfomes = jobinfomes.filter(type=ittypemes)
if educationmes:
jobinfomes = jobinfomes.filter(education=educationmes)
tableData = jobinfomes
paginator = Paginator(tableData, 10)
# 根据请求地址的信息来跳转页码数据
cur_page = 1
if request.GET.get("page"):
cur_page = int(request.GET.get("page"))
if cur_page:
c_page = paginator.page(cur_page)
else:
c_page = paginator.page(1)
page_range = []
visibleNumber = 10
min = int(cur_page - visibleNumber / 2)
if min < 1:
min = 1
max = min + visibleNumber
if max > paginator.page_range[-1]:
max = paginator.page_range[-1]
for i in range(min,max):
page_range.append(i)
return render(request, 'allJobData.html',{
'tableData':tableData,
"pagination":paginator,
"c_page":c_page,
'page_range':page_range,
'ittypes':ittypes,
'educationtypes':educationtypes
})
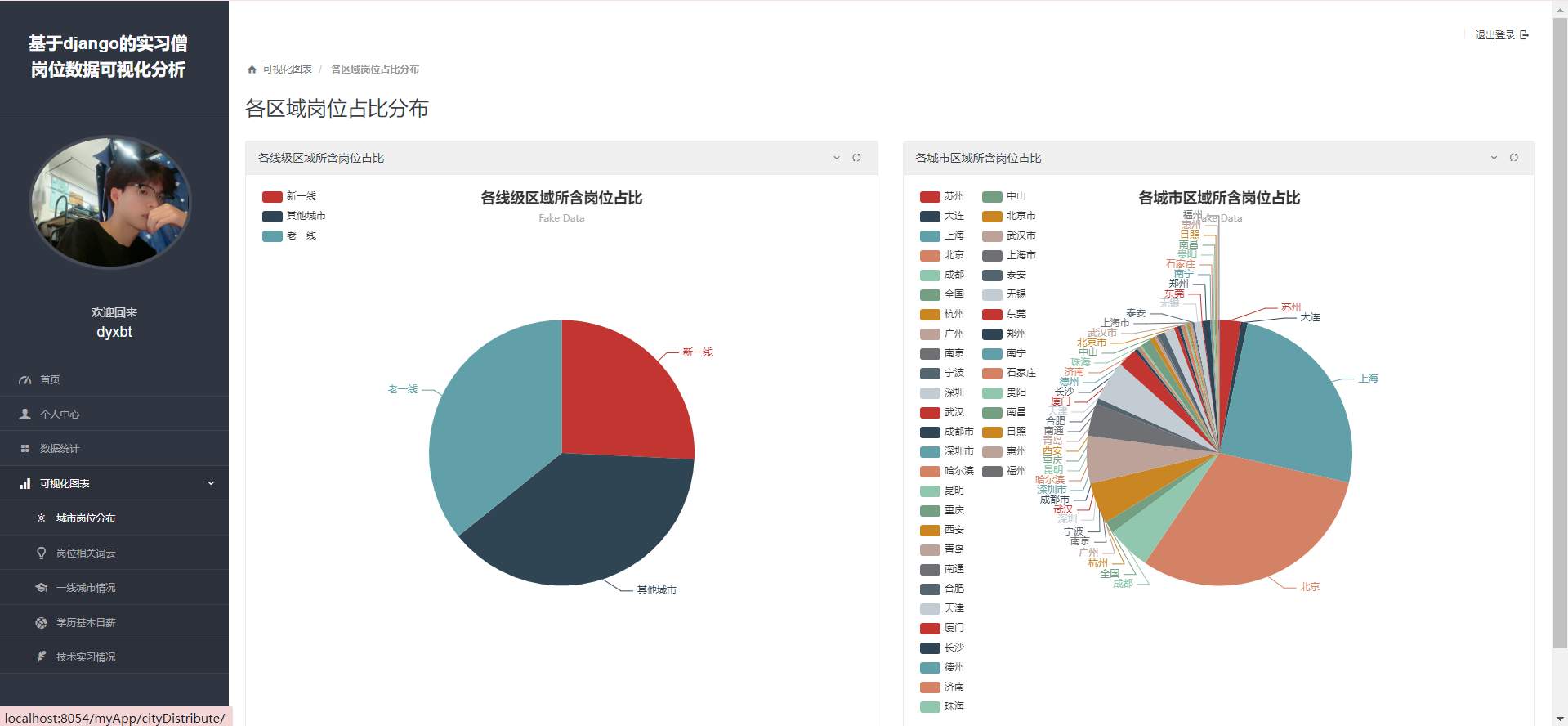
def cityDistribute(request):
username = request.session.get("username").get('name')
useravatar = request.session.get("username").get('avatar')
jobinfomes = jobinfo.objects.all();dict1={};result1=[];dict2={};result2=[];
for i in jobinfomes:
if dict1.get(i.address,-1)==-1:
dict1[i.address]=1
else:
dict1[i.address]+=1
for k,v in dict1.items():
result2.append({
'value': v,
"name":k
})
# 第二张饼图,Cpu处理器发布
for i in jobinfomes:
if i.address in ['北京','上海,‘广州','深圳']:
if dict2.get('老一线',-1)==-1:
dict2['老一线']=1
else:
dict2['老一线']+=1
elif i.address in ['成都','重庆','杭州','武汉','苏州','西安','南京','长沙','天津','郑州','东莞','青岛','昆明','宁波','合肥']:
if dict2.get('新一线',-1)==-1:
dict2['新一线']=1
else:
dict2['新一线']+=1
else:
if dict2.get('其他城市',-1)==-1:
dict2['其他城市']=1
else:
dict2['其他城市']+=1
for k,v in dict2.items():
result1.append({
'value': v,
"name":k
})
context={'username':username,'useravatar':useravatar,'result1':result1,'result2':result2}
return render(request, 'cityDistribute.html',context)
def jobwordcloud(request):
username = request.session.get("username").get('name')
useravatar = request.session.get("username").get('avatar')
# wouldCloud.wouldCloud()
context = {'username': username, 'useravatar': useravatar}
return render(request, 'jobwordcloud.html',context)
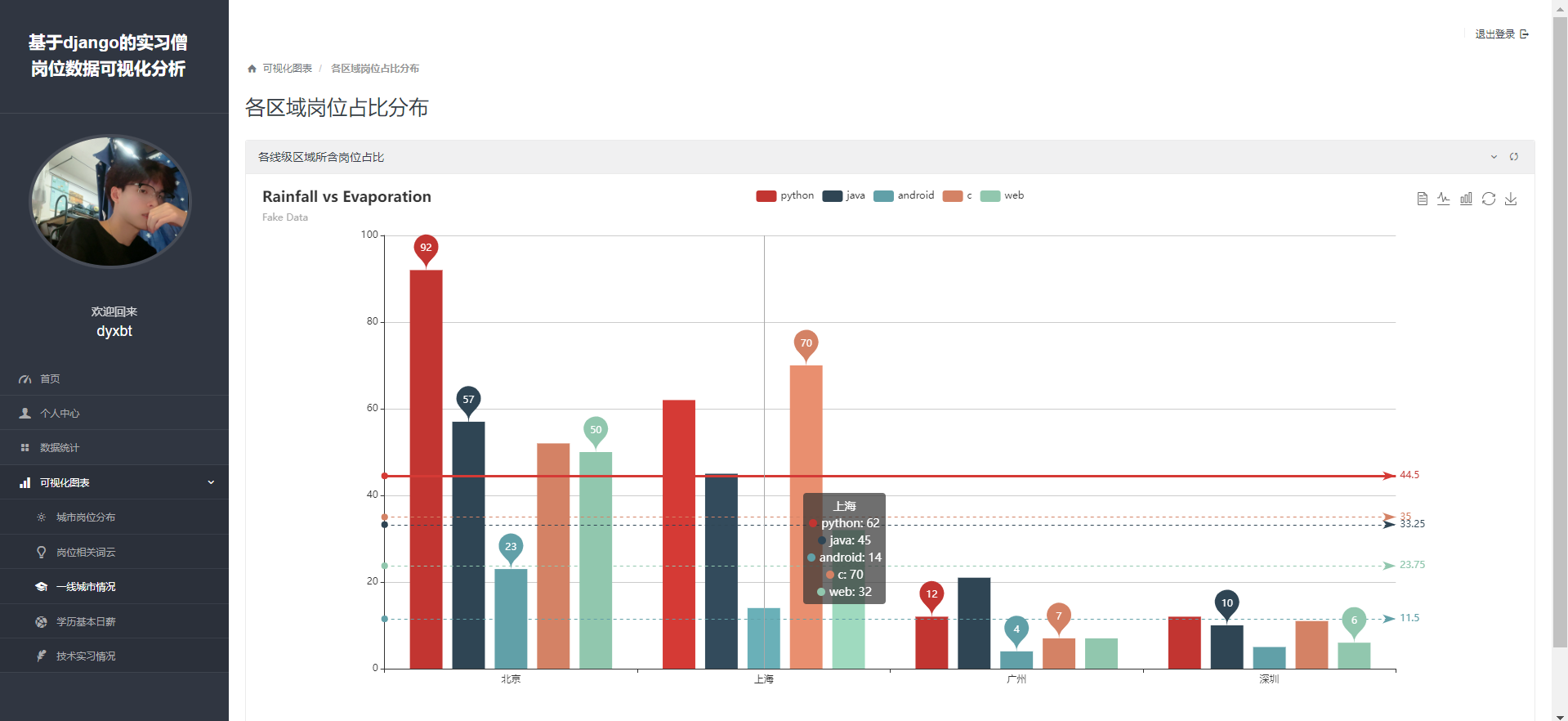
def firstcityjob(request):
username = request.session.get("username").get('name')
useravatar = request.session.get("username").get('avatar')
# 获取所有岗位信息
# 获取城市列表,举例一线城市
cities = ['北京', '上海', '广州', '深圳']
# 获取所有的 type 字段内容
all_types = list(jobinfo.objects.values_list('type', flat=True).distinct())
# 初始化大列表
type_counts = []
print(type(all_types))
# 获取每个类型在每个城市的数量
for type_name in all_types:
city_counts = []
for city in cities:
count = jobinfo.objects.filter(type=type_name, address__startswith=city).count()
city_counts.append(count)
type_counts.append(city_counts)
context = {
'username': username,
'useravatar': useravatar,
'cities': cities,
'all_types':['python', 'java', 'android', 'c', 'web'] ,
'type_counts': type_counts,
}
return render(request,'firstcityjob.html',context)
def jobinfo_chart(request):
username = request.session.get("username").get('name')
useravatar = request.session.get("username").get('avatar')
jobinfos = jobinfo.objects.all()
# 处理薪资数据
salary_data = {}
for job in jobinfos:
if job.education not in salary_data:
salary_data[job.education] = {}
if job.type not in salary_data[job.education]:
salary_data[job.education][job.type] = []
# 将薪资转换为数值类型
if '.' in job.money:
job.money = '150'
else:
salary = int(job.money.split('元')[0])
# 按照一天的薪资计算
salary=salary
salary_data[job.education][job.type].append(salary)
# 计算每种学历和技术对应的平均薪资
avg_salary_data = {}
for education, type_data in salary_data.items():
avg_salary_data[education] = {}
for type, salaries in type_data.items():
avg_salary_data[education][type] = sum(salaries) / len(salaries)
# 将数据转换为echarts需要的格式
chart_data = []
for education, type_data in avg_salary_data.items():
for type, avg_salary in type_data.items():
chart_data.append({"education": education, "type": type, "avg_salary": avg_salary})
# 提取所有技术和学历
dict_language={}
# languages = sorted(set(entry['type'] for entry in chart_data))
for i in jobinfo.objects.all():
if dict_language.get(i.type,-1)==-1:
dict_language[i.type] =1
else:
dict_language[i.type]+=1
languages=dict_language.keys()
languages=['python', 'java', 'android', 'c', 'web']
educations = sorted(set(entry['education'] for entry in chart_data))
print(educations)
print(languages)
# Creating lists to store salaries for each language and education level
salary_lists = [[] for _ in range(len(educations))]
for i, education in enumerate(educations):
for language in languages:
for entry in chart_data:
if entry['education'] == education and entry['type'] == language:
salary_lists[i].append(entry['avg_salary'])
for salaries in salary_lists:
print(salaries)
return render(request, 'jobinfo_chart.html', {'username': username,
'useravatar': useravatar,'chart_data': chart_data,'languages': languages,'educations':educations,'salary_lists':salary_lists})
def typedaycount(request):
username = request.session.get("username").get('name')
useravatar = request.session.get("username").get('avatar')
# 查询不同的workday列表
workday_list = list(jobinfo.objects.values_list('workday', flat=True).distinct())
# 查询不同的type列表
type_list = list(jobinfo.objects.values_list('type', flat=True).distinct())
workday_type_count = []
for workday in workday_list:
workday_count_list = []
for job_type in type_list:
count = jobinfo.objects.filter(workday=workday, type=job_type).count()
workday_count_list.append(count)
workday_type_count.append(workday_count_list)
# 整理结果成列表格式
result_list = [
{"不同的workday列表": workday_list},
{"不同的type列表": type_list},
{"每个workday在不同type中出现的次数": workday_type_count}
]
workday_list = result_list[0]['不同的workday列表']
type_list = result_list[1]['不同的type列表']
workday_type_count = result_list[2]['每个workday在不同type中出现的次数']
########################################################################################################################
type_list = list(jobinfo.objects.values_list('type', flat=True).distinct())
workmonth_list = list(jobinfo.objects.values_list('workmonth', flat=True).distinct())
# 查询不同的type列表
# 查询每个workmonth在不同type中出现的次数
workmonth_type_count = []
for workmonth in workmonth_list:
workmonth_count_list = []
for job_type in type_list:
count = jobinfo.objects.filter(workmonth=workmonth, type=job_type).count()
workmonth_count_list.append(count)
workmonth_type_count.append(workmonth_count_list)
# 整理结果成列表格式
result_list_month = [
{"不同的workmonth列表": workmonth_list},
{"不同的type列表": type_list},
{"每个workmonth在不同type中出现的次数": workmonth_type_count}
]
workmonth_list = result_list_month[0]["不同的workmonth列表"]
type_list = result_list_month[1]["不同的type列表"]
workmonth_type_count = result_list_month[2]["每个workmonth在不同type中出现的次数"]
context = {'username': username,'useravatar': useravatar,
'workday_list': workday_list, 'workday_type_count': workday_type_count, 'type_list': type_list,
'workmonth_list': workmonth_list,'workmonth_type_count':workmonth_type_count}
return render(request, 'typedaycount.html',context)
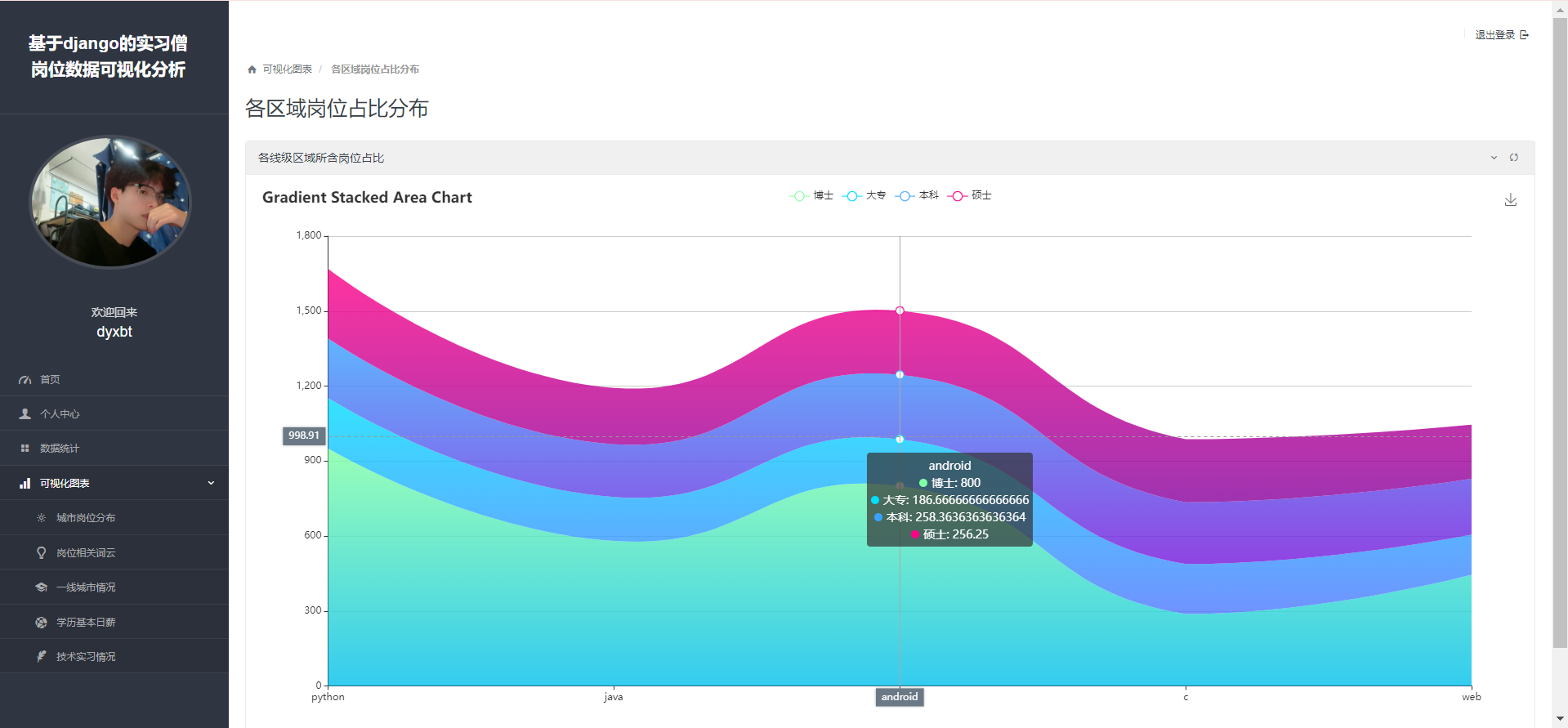
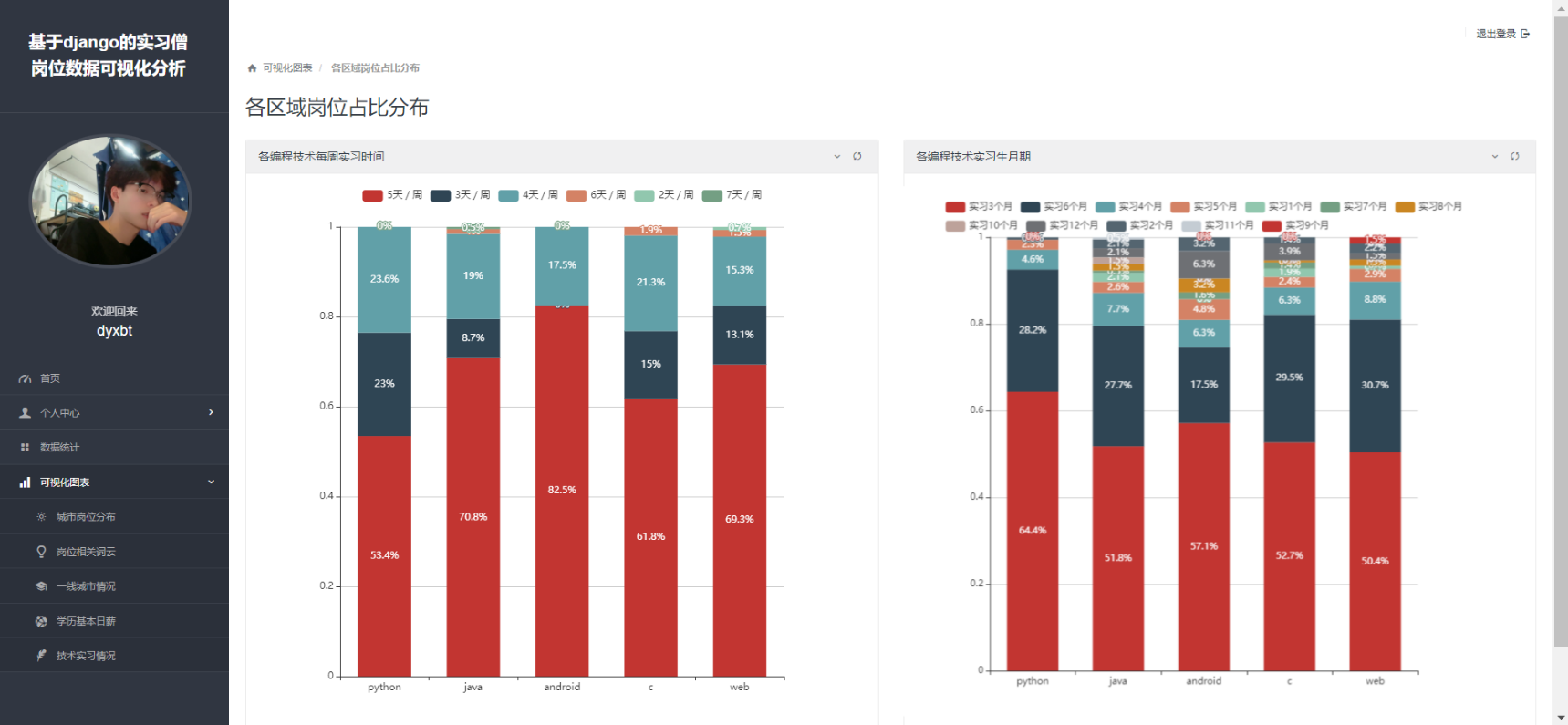
项目截图:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











