







 超级会员免费看
超级会员免费看
 本文介绍了三篇关于静态分析恶意代码的论文,涉及深度学习模型、特征提取和数据集创建。研究利用了字节熵直方图、导入函数表、PE元数据等信息。此外,还探讨了一篇关于恶意代码可视化的论文,通过将二进制样本转为RGB图片进行分类。
本文介绍了三篇关于静态分析恶意代码的论文,涉及深度学习模型、特征提取和数据集创建。研究利用了字节熵直方图、导入函数表、PE元数据等信息。此外,还探讨了一篇关于恶意代码可视化的论文,通过将二进制样本转为RGB图片进行分类。
有关静态分析的三篇论文以及一篇恶意代码可视化的论文阅读
文章目录
基于两维二进制程序特征和深度神经网络的恶意代码检测 15年发表
检测恶意软件的两种方法:第一是规则或者签名(人工制定相关规则进行推理);另一种方法是机器学习,根据数据自动推理模型的参数;折中的方法是利用机器学习技术自动生成签名规则,这种方法具有较低的误报率。
model
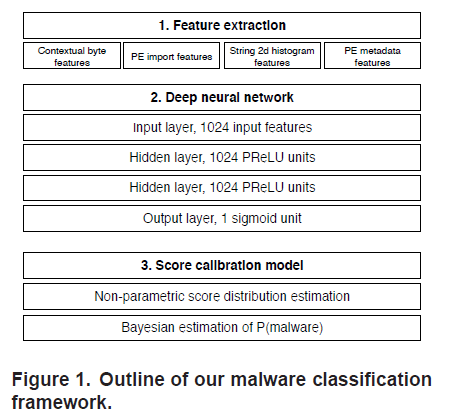
- 四种互补特征的提取
- 深度神经网络
- 概率校准
feature
字节熵直方图
- 滑动一个1024字节的窗口,步长为256字节
- 计算每个1024字节窗口的熵
- 统计滑动窗口(字节,熵值)对,将直方图的每个行向量进行连接
计算二进制的字节熵
class ByteEntropyHistogram(FeatureType):
''' 2d byte/entropy histogram based loosely on (Saxe and Berlin, 2015).
This roughly approximates the joint probability of byte value and local entropy.
See Section 2.1.1 in https://arxiv.org/pdf/1508.03096.pdf for more info.
'''
name = 'byteentropy'
dim = 256
def __init__(self, step=1024, window=2048):
super(FeatureType, self).__init__()
self.window = window
self.step = step
def _entropy_bin_counts(self, block):
# coarse histogram, 16 bytes per bin
c = np.bincount(block >> 4, minlength=16) # 16-bin histogram
p = c.astype(np.float32) / self.window
wh = np.where(c)[0]
H = np.sum(-p[wh] * np.log2(
p[wh])) * 2 # * x2 b.c. we reduced information by half: 256 bins (8 bits) to 16 bins (4 bits)
Hbin = int(H * 2) # up to 16 bins (max entropy is 8 bits)
if Hbin == 16: # handle entropy = 8.0 bits
Hbin = 15
return Hbin, c
def raw_features(self, bytez, lief_binary):
output = np.zeros((16, 16), dtype=np.int)
a = np.frombuffer(bytez, dtype=np.uint8)
if a.shape[0] < self.window:
Hbin, c = self._entropy_bin_counts(a)
output[Hbin, :] += c
else:
# strided trick from here: http://www.rigtorp.se/2011/01/01/rolling-statistics-numpy.html
shape = a.shape[:-1] + (a.shape[-1] - self.window + 1, self.window)
strides = a.strides + (a.strides[-1],)
blocks = np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides)[::self.step, :]
# from the blocks, compute histogram
for block in blocks:
Hbin, c = self._entropy_bin_counts(block)
output[Hbin, :] += c
return output.flatten().tolist()
def process_raw_features(self, raw_obj):
counts = np.array(raw_obj, dtype=np.float32)
sum_ = counts.sum()
normalized = counts / sum_
return normalized
导入函数表
导入表DLL可以帮助模型捕获给定输入二进制文件所依赖的外部函数的调用语义,从而帮助检测启发式可疑文件或具有已知恶意软件家族匹配的导入组合文件
- 256维数组,初始化为0
- 将DLL和导入函数的每个元组散列到[0,255]之间
- 并在数组中增加关联计数
PE元数据信息
- 使用python的pefile库解析二进制文件提取数字可移植可执行的字段
- 汇总为256维数组
label
使用vt打标签:
- 超过30%的杀毒引擎认定恶意软件才标记为恶意软件
- 没有杀毒引擎认定为恶意软件的标记为良性软件
- 0%到30%标毒的恶意软件丢弃,以免影响结果
Network
- 深层神经网络,深层相较浅层更容易拟合参数
- 提高网络的表达能力,同时保持一个易于处理的网络规模
- 解决过拟合并提高反向传播算法的效率
- dropout
- prelu
- 高斯分布对输出大小进行归一化
bayesian校准
提供了基于贝叶斯模型的分数校准
- 将神经网络的输出概率结果转化为恶意软件的近似概率
- 采用KDE取邻域的加权平均值来近似给定C
评估和数据集
两种方式评估
- 内部交叉验证
- 继续订阅威胁情报
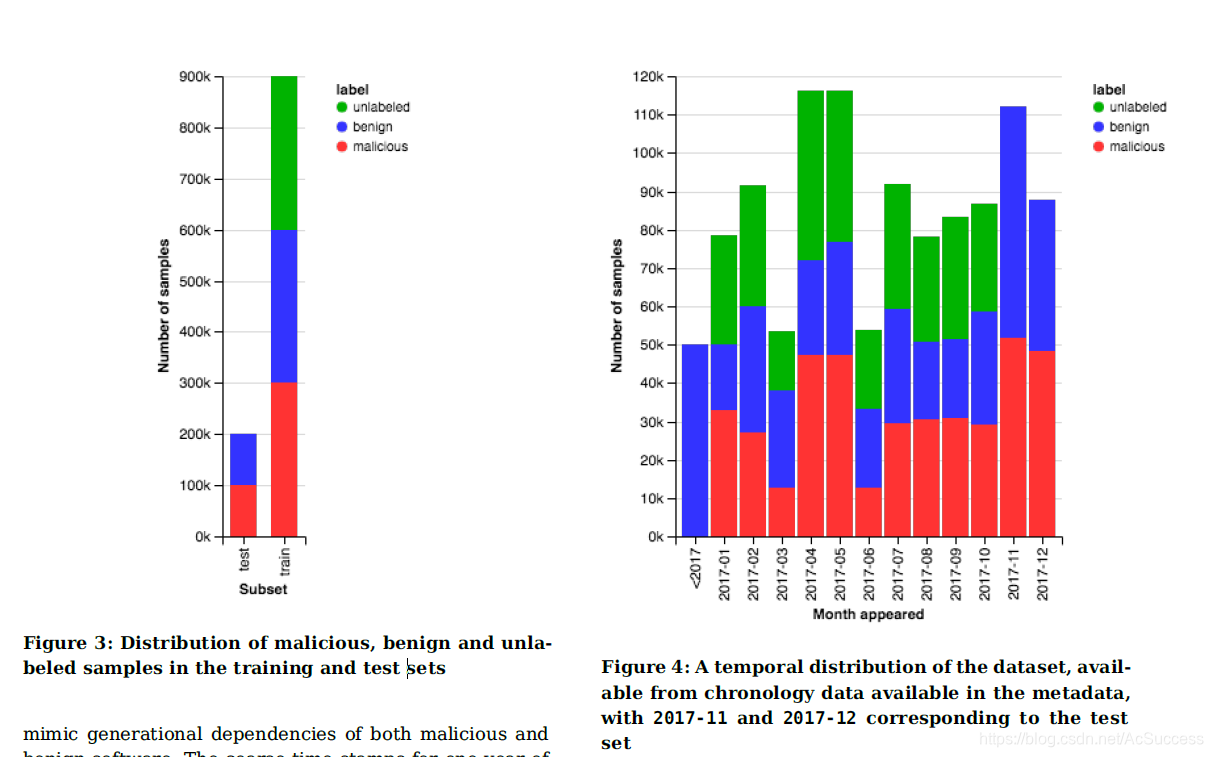
数据集:
- total:431926
- 81910良性
- 350016恶意软件
一个用于训练静态PE恶意软件机器学习模型的开放数据集:EMBER 18年发表
EMBER一个标记的基准数据集
- 有监督的学习模型能自动利用训练数据中文件属性之间的复杂关系来区分恶意样本和良性样本
- 适当正规化的机器学习模型可以推广到新样本
恶意软件检测的基准数据集存在以下掣肘:
- 法律限制:良性二进制文件通常受版权保护,防止共享
- 标签限制,就算是训练有素的专业人士分析,也是一个耗时的工程
- 安全责任和预防措施
PE文件结构
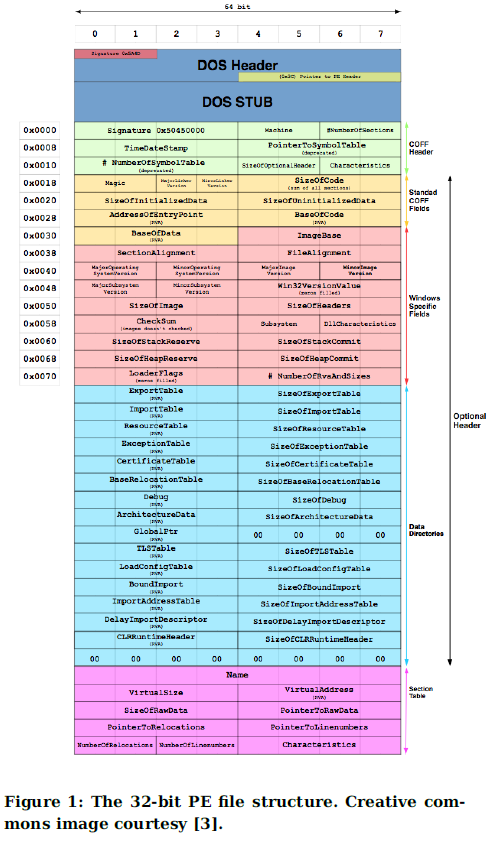
- 导入
- 导出
- 资源:光标、字体、位图、菜单等
- 重定位表
- tls:用于存储特定于线程的局部变量的特殊线程局部存储结构
- 节名称
数据集
数据集包含标注和未标注的(推荐采用半监督学习算法使用)
特征
共使用到了8组静态特征:包括解析格式的特征和格式无关的直方图和字符串计数
解析文件提取的特征
共有五组
- 常规文件信息,文件大小、从PE头获得的基本信息:文件的虚拟大小导入导出函数数量,是否具有调试部分,线程本地存储,资源,重定位或签名以及符号的数量
- 标头信息,从COFF标头中, 提取时间戳,target machine、list of image characteristics,在可选标头中提取目标子系统,DLL特性、主要和次要映像版本、file magic、链接版本、系统版本、子系统版本以及代码,头和commit的大小。在训练前使用哈希算法散列特征
- 导入函数,导入库+函数名。使用哈希算法散列特征 1024维
- 导出函数,哈希为128维
- 节信息,每个节的属性包括名称大小熵虚拟大小及代表节特征的字符串列表
与格式无关的特征
共有三组
- 字节直方图
- 字节熵直方图,窗口2048 步长1024
- 字符串信息,字符串取值范围为0x20到0x7f,至少五个可打印字符串。字符串数量、平均长度、可打印字符的直方图和熵,还包括C:\开头的路径字符数和http://的出现数以及短字符MZ的出现数量
实验
8组特征转为2351维向量特征,使用lightGBM训练了梯度决策树模型
数据集及代码地址:https://github.com/endgameinc/ember
DeepCG: Classifying Metamorphic Malware Through Deep Learning of Call Graphs 19年发表
摘要:调用图 深度卷积神经网络 BIG2015 96%
恶意软件在过去十年间发展迅速,以日益复杂的方式威胁着网络空间,因此引起了学术界和工业界的关注。
基于签名的检测可快速响应已知恶意软件,但随着变种的增加,碎片签名的匹配则越来越困难,为了解决此问题,一项基本任务就是了解特定编制恶意软件家族的变体之间相对不变的稳定特征
GDL
graph : {
// c o l o r s
. . . . . .
colorentry 73: 255 255 255
colorentry 74: 192 187 175
colorentry 75: 0 255 255
colorentry 76: 0 0 0
. . . . . .
// n o d e s
node : { title : ”0” label : ” main” color : 76 textcolor : 73 bordercolor : black }
node : { title : ”1” label : ” sub 401028” color : 76 textcolor : 73 bordercolor : black }
node : { title : ”2” label : ”sub 40102E” color : 76 textcolor : 73 bordercolor : black }
node : { title : ”3” label : ” sub 401060” color : 76 textcolor : 73 bordercolor : black }
. . . . . .
node : { title : ”5” label : ” amsgexit ” color : 75 textcolor : 73 bordercolor : black }
. . . . . .
node : { title : ”106” label : ”GetCommandLineA” color : 80 bordercolor : black }
. . . . . .
// e d g e s
edge : { sourcename : ”0” targetname : ”1” }
edge : { sourcename : ”0” targetname : ”2” }
edge : { sourcename : ”3” targetname : ”7” }
. . . . . .
}
- 包含三个要素:颜色、节点和边
- 可用ida导出
- 有向图
- 颜色:colorentry : color为RGB的桑额参数
- 节点: (title, label, c, tc, bc) title为id,label为函数名,c是文本颜色,tc是边框颜色,bc是恒定值
- 节点按照三种颜色填充:自定义函数填充为黑色,动态导入的DLL函数填充为洋红色,静态链接函数填充为青色
- 边:edge: {sourcename: targetname: } s和t都属于点的title
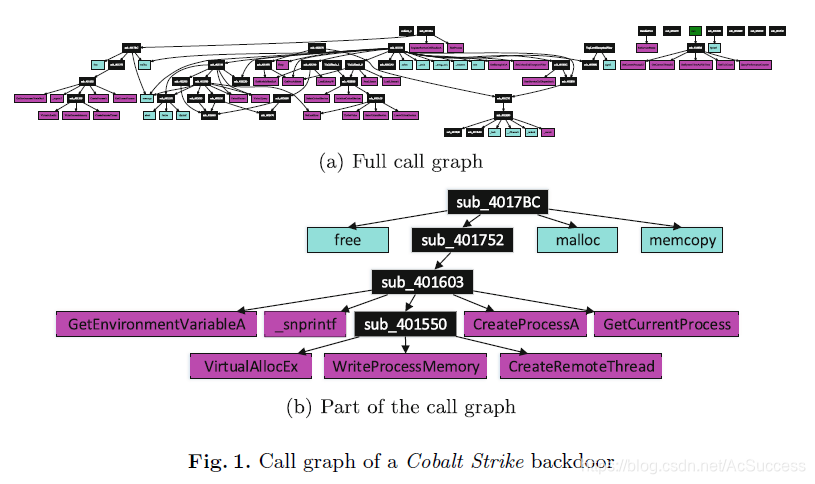
- 可使用graphviz [9] 和 Graph Easy from CPAN (Comprehensive Perl Archive Network) [14]将两种GDL转化为图
混淆
变种恶意软件使用代码混淆技术自动更改可执行代码,因此操作码序列和字节码之类的碎片化功能可能会发生巨大变化
常用的混淆技术包括:
- 指令替换
- 指令置换
- 寄存器或变量替换
- 死代码插入
- 代码转置
- 子例程重新排序

- 图a是原始代码
- 图b是经过混淆后的代码
- 图c是插入死函数后的混淆代码(死函数为添加某些叶节点到随机局部函数节点)
使用调用图特征
- 生成GDL文件
- 使用graph easy生成256 * 256 * 3的彩图
- cnn分类
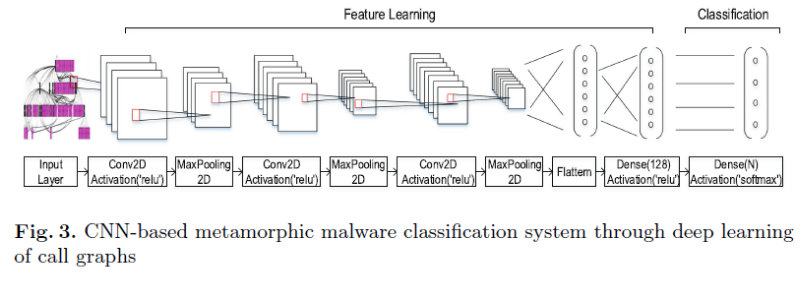
增强训练数据
数据标准化
基于加权排序的调用图归一化方法,其中根据节点的子节点数和标签名称(当子节点数相等时)对节点进行重新排序

数据扩充
提出一种基于随机函数插入的调用图扩充方法,用于模拟恶意软件的变种行为(随即插入叶结点),将训练数据集扩大数十倍

Malware Visualization for Fine-Grained Classification
IEEE 2018.1
作者单位:北理工
method
总框架图:
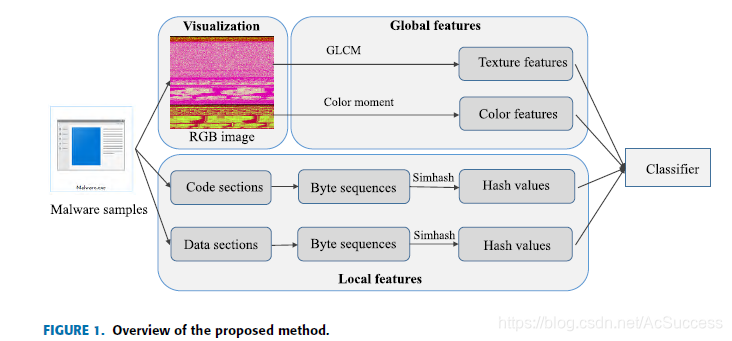
全局特征:
-
利用熵、byte、相对大小将二进制样本转为RGB图片
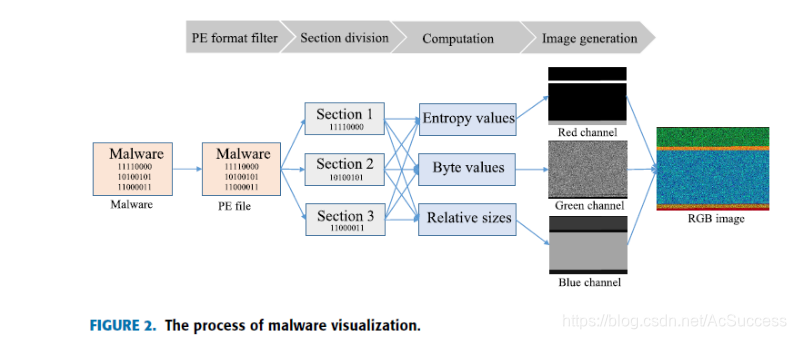
-
再利用权值公式,将RGB图片转为灰度图
G r a y = R ∗ 0.299 + G ∗ 0.587 + B ∗ 0.114 Gray = R * 0.299 + G * 0.587 + B * 0.114 Gray=R∗0.299+G∗0.587+B∗0.114 -
提取灰度图的灰度共生矩阵和颜色矩
局部特征
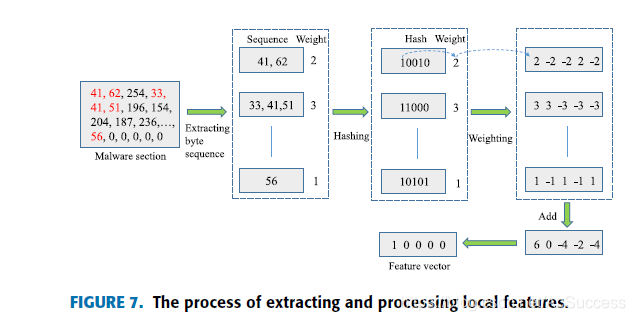
- 在code段和data段提取大于6个字节的可显示ASCII码值,并将其可视化表示
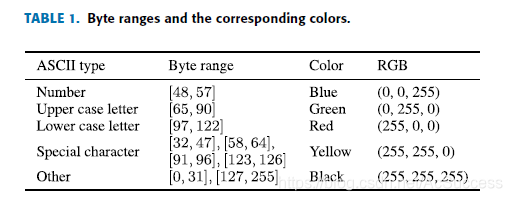
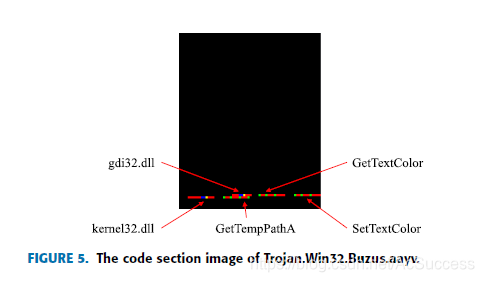
- Simhash算法处理为特征向量
expriment
data
- 15个家族7087个样本
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t5Urswsu-1600393410119)(A2C01692F871436789C7D20AE9D0A2F4)]](https://i-blog.csdnimg.cn/blog_migrate/67273ad4d5c2ed6f749543a3485c0579.png#pic_center)
result
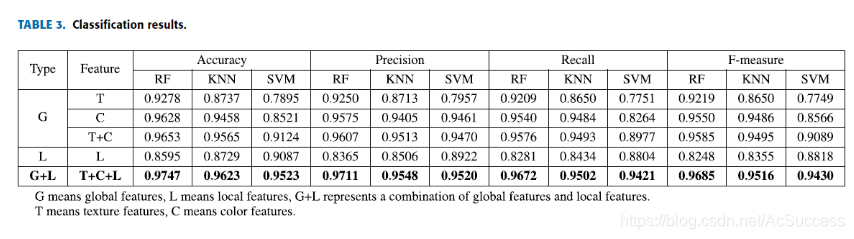
评价
- 感觉没什么出彩的地方,大量工作用在了RGB转换和特征提取方面
- 而且感觉特征提取方面工作做的也不是很充实,但文章篇幅却很长


















 3355
3355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











