






基础关
讲第七题之前先说一下第一题
第一题

直接访问网址,F12查看网页源代码,可以就在注释里

第七题
是第一题的延伸,按照第一题的思路看不到key在哪里


思考应该是发生在通信的过程中,访问地址,wireshark抓包,找到完整的一条流,key就在响应头里

第八题

像第七题一样开启抓包,访问地址,查看返回的响应,在重定向后的响应里找到了一个新的地址
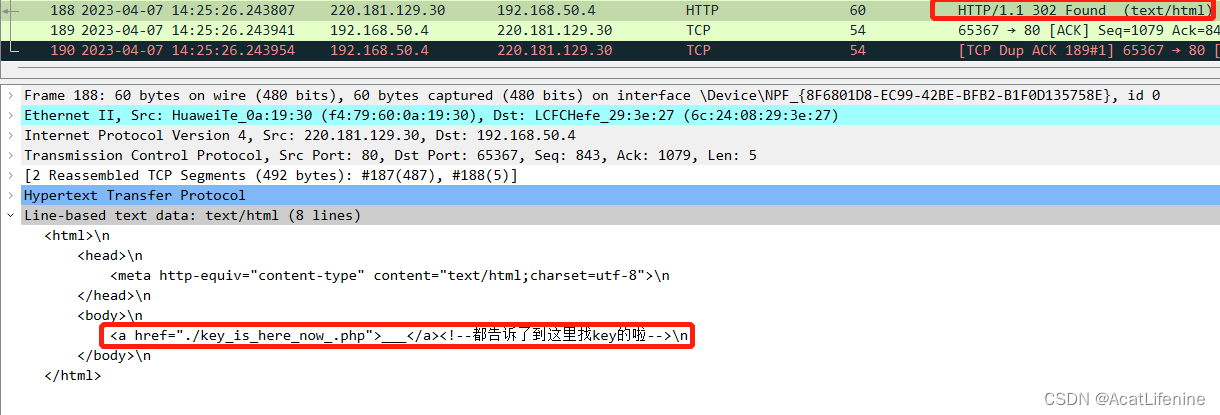
在浏览器中把链接改成新的,得到key

第十二题

这题是真不会了,看了别人的攻略才解出来的,先说一下我的思路
老规矩
源代码、抓包、cookie统统看一遍,什么也没有

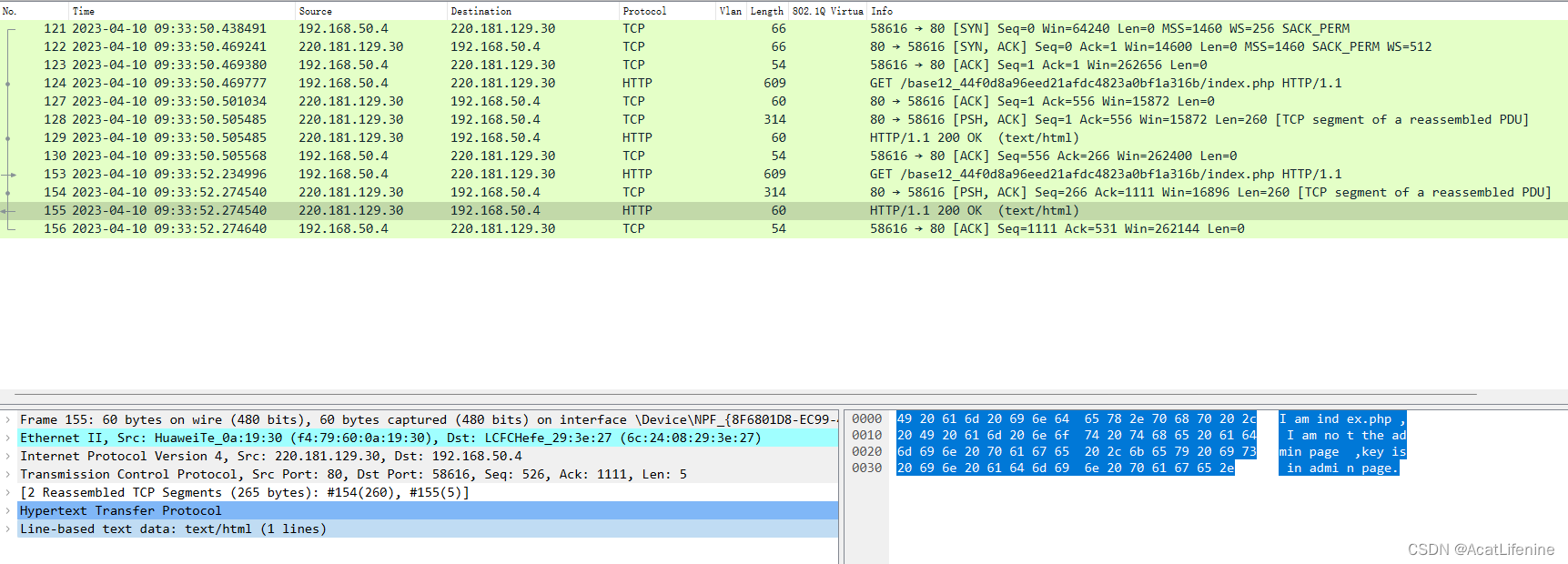

然后找了一下攻略,接下来我们看后台robots协议,试试robots.txt
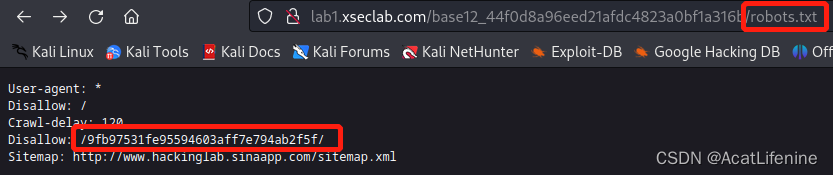
在这里发现了信息,这里学习一下robots协议
robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
文件写法
User-agent: * 这里的代表的所有的搜索引擎种类,是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow: /?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
Crawl-delay: 120 //本次抓取后下一次抓取前需要等待120秒
上图可以看到Disallow: /9fb97531fe95594603aff7e794ab2f5f/是被禁止的,题目的提示又说key在admin page,所以尝试index.php、admin.php、login.php,最后是login.php找到了key
















 1458
1458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









