







String类
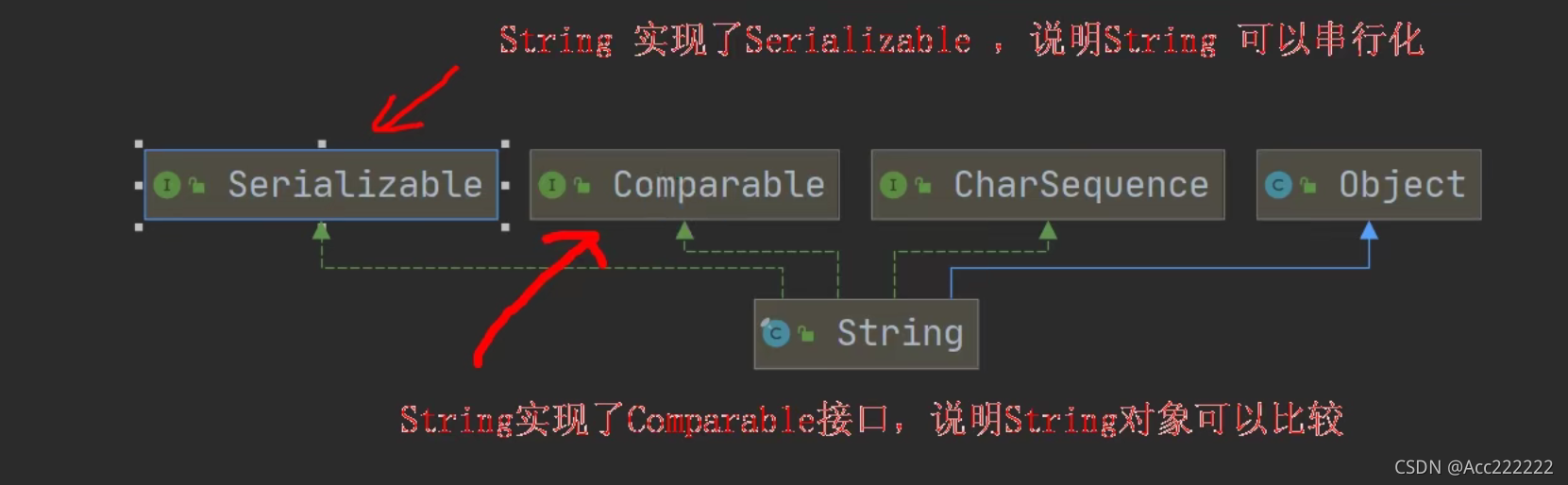
串行化:可以在网络传输。
基本信息
1. String 对象用于保存字符串,也就是一组字符序列。
2. 字符串常量就是双引号括起的字符序列,比如 "jack"。
3. 字符串的字符使用Unicode字符编码,一个字符(不区分字母还是汉字)占两个字节。
4. String 类有很多构造器。

String s5 = new String(byte[] b);5. String是final类,不能被其他的类继承。
6. String 有属性 private final char value[] 用于存放字符串内容(所以本质还是字符数组)。注意value是final类型,由于数组名相当于数组首地址,因此value不能指向新的地址,但是单个字符内容是可以变化的。
创建方式

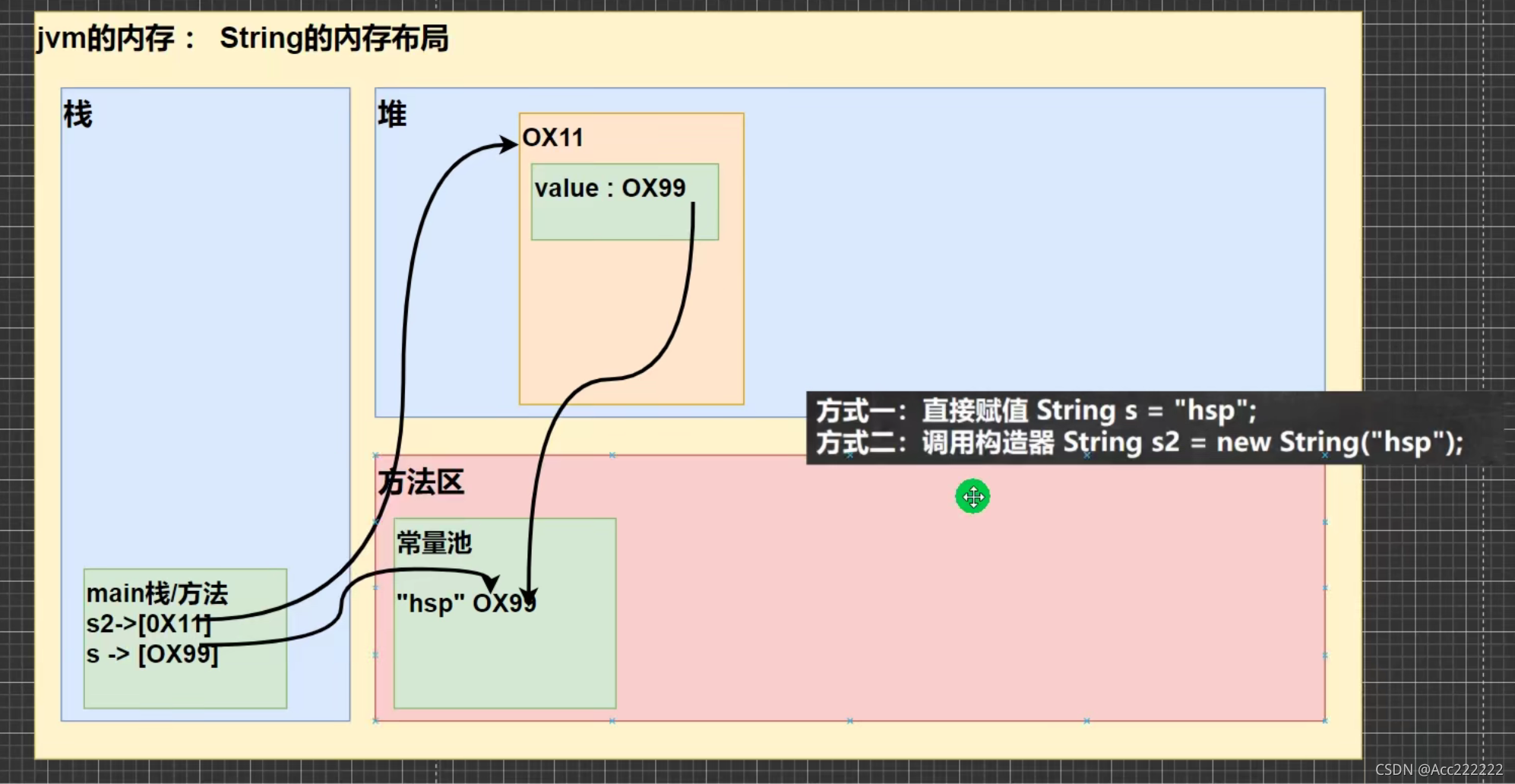
方式一:先从常量池查看是否有 "hsp" 数据空间,如果有,字符串直接指向该空间。如果没有则重新创建,然后指向。s最终指向的是常量池的空间地址。
方式二:先在堆中创建空间,里面维护了value属性,如果常量池里有 "hsp",value指向常量池的"hsp"地址。如果常量池没有 "hsp",重新创建,然后再指向。s2 最终指向的是堆中的空间地址。
综合训练 P497
String 对象特性
String s1 = "hello";
s1 = "haha";一共创建了两个对象,"hello"与"haha",值得注意的是,上面说的String的value属性是final类型,不能更换地址,指的是"hello"与"haha"不能更换地址。这两个才是String对象,而s1只是一个指向String对象的指针罢了,因此s1可以指向不同的对象,而"hello"和"haha"并不能更换地址。

String a = "hello" + "abc"; // 字符串常量相加创建了一个对象。String a = "hello" + "abc" 会被优化等价于 String a = "helloabc"。对于这种字符串常量相加的情况,编译器会自动优化,然后就等价于一个新的字符串常量对象赋给指针。
当将一个字符串与一个非字符串的值进行拼接时,后者会转换为字符串。
String a = "hello";
String b = "abc";
String c = a + b; //字符串对象相加对于字符串对象相加,最关键的问题就是分析出 String c = a + b是怎么执行的。
// 底层是
StringBuilder s = new StringBuilder();
s.append(a);
s.append(b);
c = s.toString(); public String toString() {
return new String(value, 0, count); //截取 0~count-1
}  底层是创建了一个 StringBuilder类,调用append方法把几个字符串对象相加,然后再调用toString方法返回一个新的字符串对象给c。
底层是创建了一个 StringBuilder类,调用append方法把几个字符串对象相加,然后再调用toString方法返回一个新的字符串对象给c。
重要规则:String c1 = "ab" + "cd"; 常量相加,c1指向的是常量池中的地址。 String c2 = a + b; 对象相加,c2指向的是堆中的地址(对象地址)。
因此总共创建了三个对象(a,b,c分别对应的String,StringBuilder类调用后就销毁了)
public class Test {
String str = new String("hsp");
final char[] ch = {'j','a','v','a'};
public void change(String str,char ch[]){ //注意str是形参,不同于真正的str
str = "java";
ch[0] = 'h';
}
public static void main(String[] args) {
Test ex = new Test();
ex.change(a.str,a.ch);
System.out.println(ex.str + " " + ex.ch);
}
}分析: 主方法创建了一个Test对象,ex为对象指针,在栈中。对象实体在堆中。而在对象实体里,str为String类指针,指向String类的value属性,而value又指向常量池中的 "hsp"。ch是一个数组指针,指向堆中的数组。
然后调用ex的change方法,会在栈中开辟一个方法区,在方法区中,str和ch都是形参(当然也可以改名), str本来指向value, 更改后指向常量池中的"java"(但原先的str没变化!仍然指向value),但ch因为也指向字符数组,因此修改之后保持同步。调用完方法后,形参被销毁。
最终输出 hsp hava

String类常用方法







String format = String.format("%s,%s .%c",name,job,id);
System.out.println(format);注:如果想对String进行操作,应该先用 toCharArray 方法把String转化成一个字符数组,对这个字符数组进行操作后再转换为String。
String str = "abcdef";
char[] chars = str.toCharArray(); //字符串转换为字符数组
...... // 对字符数组进行一系列操作
String str1 = new String(chars); // 由字符数组建立一个新数组空串与null串
空串是一个Java对象,有自己的串长度(0)和内容(空),null串是指一个字符串中放入的特殊值null,表示目前没有任何对象与该变量关联(注意这两个是不同的概念!)。
if(str == null) //判断是否为null串
if(str.length()==0) //判断是否为空串
if(str.equals("") //判断是否为空串码点与代码单元
char数据类型是一个采用UTF-16编码表示Unicode码点的代码单元。最常用的Unicode字符使用一个代码单元就可以表示(a,b,c等),而辅助字符(𝕆等)需要两个代码单元表示。
码点:是指一个编码表中的某个字符对应的代码值。(也就是字符在Unicode表中的位置)
在Java中一个Unicode占2个字节(byte),一个字节等于8比特位(bit),因此,每个Unicode码占用16个比特位。若一个字符的代码长度为16位,则为一个代码单元。若一个字符的代码长度有两个16的代码长度编码,则该字符有两个代码单元。
获取方法:
String.length():返回字符串代码单元的个数。
String.codePointCount(int startIndex,int endIndex):返回startInde到endIndex-1之间的码点个数。(也就是有多少个字符,因为一个字符对应一个位置(代码值))
String.charAt(int index):返回给定位置的代码单元,尽可能不要调用这个方法。
String.codePointAt(int index):返回给定位置的码点(也就是该字符在Unicode中的位置)
String.offsetByCodePoints(int startIndex,int cpCount):返回从stratIndex码点开始,cpCount个码点后的码点索引。
举例:hi𝕆 这个字符串实际上有三个码点,四个代码单元。
1.测试length函数和codePointCount函数
public class HelloJava {
public static void main(String[] args) {
String greeting="hi𝕆";
int t=greeting.length();
int h=greeting.codePointCount(0, t);
System.out.println(t);
System.out.println(h);
}
}
首先测试的是测量字符串长度的两种方法——用length方法得出字符串代码单元个数为4,因为𝕆这个符号是由两个代码单元得到的。而用count方法得出字符串码点个数为3,也就是有多少个字符。
2.测试charAt函数
public class HelloJava {
public static void main(String[] args) {
String greeting="hi𝕆";
char a=greeting.charAt(0);
char b=greeting.charAt(1);
char c=greeting.charAt(2);
char d=greeting.charAt(3);
System.out.println(a);
System.out.println(b);
System.out.println(c);
System.out.println(d);
}
}
由于charAt函数是返回给定位置的代码单元,因此在第2个和第三个位置返回的是相同的代码单元。charAt可以在没有辅助元素的字符串中使用。
3.测试codePointAt函数
public class HelloJava {
public static void main(String[] args) {
String greeting="hi𝕆";
int a=greeting.codePointAt(0);
int b=greeting.codePointAt(1);
int c=greeting.codePointAt(2);
int d=greeting.codePointAt(3);
System.out.println(a);
System.out.println(b);
System.out.println(c);
System.out.println(d);
}
}
codePointAt函数返回的是序号对应的字符在Unicode表中的位置,可以看出h和i位置是挨在一起的,并且𝕆符号是由两个不同代码单元组成的。
4.测试offsetByCodePoints函数
public class HelloJava {
public static void main(String[] args) {
String greeting="hi𝕆";
int a=greeting.offsetByCodePoints(0, 0);
int b=greeting.offsetByCodePoints(0, 1);
int c=greeting.offsetByCodePoints(0, 2);
System.out.println(a);
System.out.println(b);
System.out.println(c);
}
}
经过的是码点数而不是代码单元,因此这个就可以看作是从序号为startIndex开始,经过cpCount个位置,对应的码点的序号。与代码单元就没有关系了。
总结:
String.codePointCount(int startIndex,int endIndex) 是最标准的求字符串长度的函数
int cpCount = String.codePointCount(0,String.length());String.codePointAt(int index) 是最标准的求码点在Unicode位置的函数
String.offsetByCodePoints(int startIndex,int cpCount) 是最标准的求码点对应序号的函数
想要得到第i个码点,应该使用下列语句
int index = String.offsetByCodePoints(0,i);
int cp = String.codePointAt(index); 













 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









