







 本文介绍了如何使用Tampermonkey(油猴)插件免费下载百度文库的文档。首先,你需要在浏览器上安装油猴插件,然后从GreasyFork网站挑选并安装适合的脚本。一旦安装完成,打开百度文库搜索所需文档,点击下载按钮并输入验证码,即可直接下载。若脚本失效,可尝试更新或安装其他可用脚本。
本文介绍了如何使用Tampermonkey(油猴)插件免费下载百度文库的文档。首先,你需要在浏览器上安装油猴插件,然后从GreasyFork网站挑选并安装适合的脚本。一旦安装完成,打开百度文库搜索所需文档,点击下载按钮并输入验证码,即可直接下载。若脚本失效,可尝试更新或安装其他可用脚本。
某度文库太贵了 找了个浏览器插件可以下载文章~分享给大家 欢迎收藏
前言
话不多说直接上干货,只需要准备好浏览器,各大主流浏览器都可
一、安装油猴
Tampermonkey (油猴)是一款免费的浏览器扩展和最为流行的用户脚本管理器
对于不了解用户脚本的同学也不必在意,通俗来讲就是在你打开网页时会自动执行的一系列代码

各位可根据各自的浏览器选择对应的油猴安装
二、挑选脚本
一般来说可以从Greasy Fork右上角的脚本列表中挑选自己需要的脚本,这里我们直接搜索某度文库
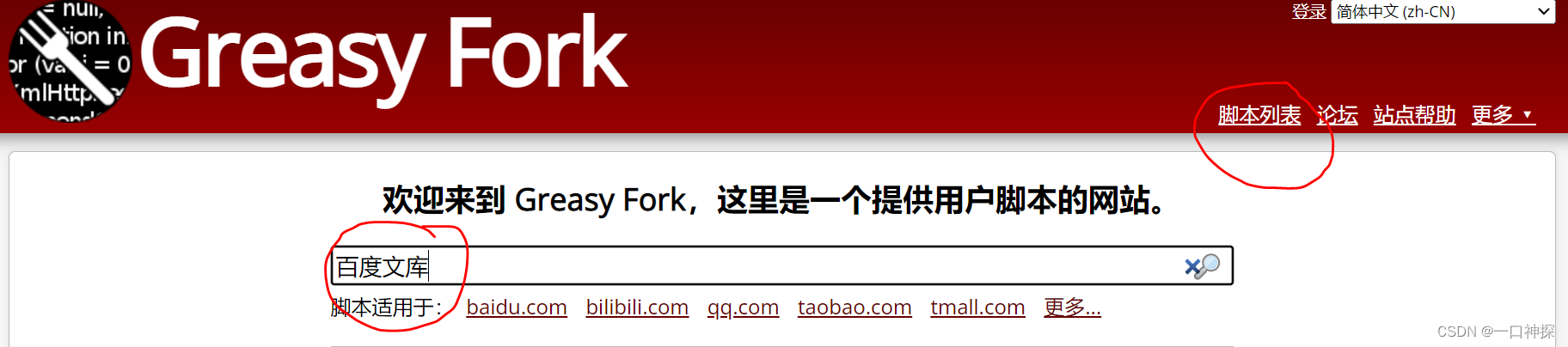
在结果列表中选择合适的脚本
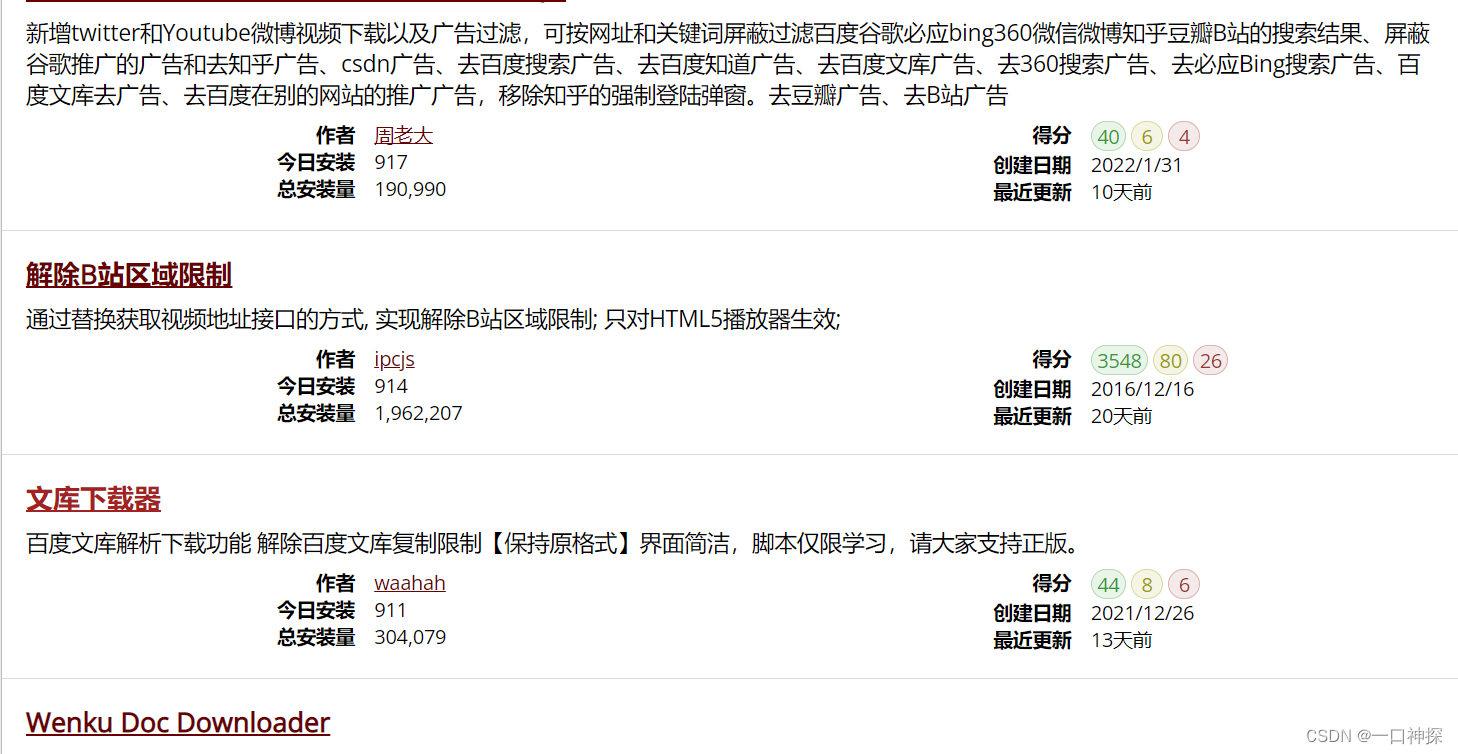
点击安装按钮即可自动安装
安装完成后不需要其他操作,重启浏览器后脚本会自动启用
三、使用脚本下载文档
打开百度文库搜索自己需要的文档
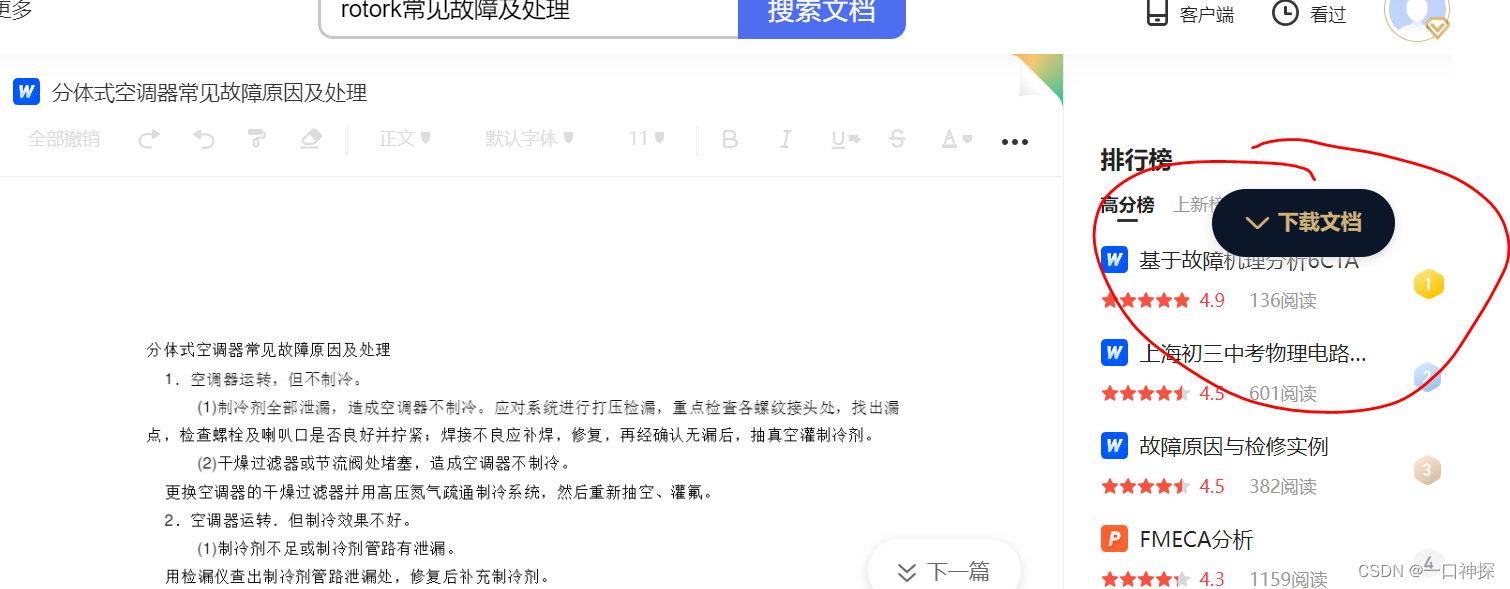
点击右方悬浮的下载文档按钮,按照提示输入验证码即可直接下载文档
总结
如遇脚本失效,可自行去脚本市场安装其他脚本使用,过程和上述类似


















 4031
4031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











