






作者:郑增权,爱可生 DBA 团队成员,OceanBase 和 MySQL 数据库技术爱好者。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 1500 字,预计阅读需要 5 分钟。
背景
对于分布式数据库来说,当多个数据副本间发生半数异常时(一半副本故障或与另一半网络隔离),可以通过集群之外的仲裁服务来参与变更决策(选主/成员组变更),进而恢复服务。OceanBase 数据库 V4.1.0 版本开始支持 仲裁服务(Arbitratrion Service)。
某客户基于节约成本的想法,欲使用 OceanBase 仲裁服务功能,架构副本类型如下:
- 集群架构:1-1-1
- 副本类型为:2F1A(2 个全能型副本 + 1 个仲裁服务节点)
存在的疑虑:
- 1 个全能型副本(Leader)发生故障后租户能否正常读写?
- 2 个全能型副本发生可恢复的故障,均触发永久下线,后续启动 OBServer 后集群能否恢复正常?
本文基于如上 2 个问题展开实验,记录相关过程和结果,为类似需求评估提供参考。
相关术语
OceanBase 数据库仲裁服务
OceanBase 数据库仲裁服务(Arbitratrion Service)是一种基于 Paxos 多副本容灾方案提出的新型高可用方案。
仲裁服务独立于 OceanBase 集群部署,是一个以特殊模式启动的轻量级 observer 进程,它承载着日志流级别的仲裁成员。
仲裁成员具备如下特征:
- 仅参与选举、成员变更投票,不参与日志同步投票。
- 不存储日志,无 MemTable 和 SStable,资源开销极小。
- 不能当选为主提供服务。
当半数全功能副本故障导致日志同步失败并且达到日志流降级控制时间时,仲裁服务会自动执行日志流降级流程,将故障副本从成员列表中剔除,从而恢复服务,且能做到 RPO = 0。待故障的全功能副本恢复时,仲裁服务又会执行日志流升级流程,将被降级的副本重新加入成员列表,提供更高的可用性保证。
日志流
OceanBase 数据库参考传统数据库分区表的概念,把一张表格的数据划分成不同的分区(Partition)。在 V4.0.0 版本,分区是用户创建的逻辑对象,是划分和管理表数据的一种机制。
每个分区都有其对应的数据存储对象,称之为分片(Tablet),它具备存储数据的能力,支持在机器之间迁移(transfer),是数据均衡的最小单位。
日志流是由 OceanBase 数据库自动创建和管理的实体,它代表了一批数据的集合,包括若干 Tablet 和有序的 Redo 日志流。它通过 Paxos 协议实现了多副本日志同步,保证副本间数据的一致性,实现了数据的高可用。
日志流降级
日志流 Leader 上运行的仲裁服务发现一些副本在 arbitration_timeout(默认值为 5s)内没有向 Leader 回复日志确认消息,仲裁服务将执行进一步检查,准备对日志不同步的副本进行日志流降级操作。
仲裁服务通过周期性探测,检查日志不同步的副本是否存在降级策略中所列的异常,如果存在异常,则执行日志流降级操作。
注意: 仅当故障副本(包括已降级的副本)总数等于全功能副本总数的一半时,仲裁服务才会执行日志流降级操作。例如,4F1A 部署场景下:
- 如果只有 1 个 F 副本出现异常,仲裁服务不会执行日志流降级,因为此时 4F 的多数派 3F 依然存活,可以正常同步日志。
- 如果有 2 个 F 副本出现异常(例如:2 个 F 副本网络中断,或者一个 F 副本 Rebuild,一个 F 副本所在 Server 宕机),仲裁服务会执行日志流降级。
- 如果有 3 个及以上 F 副本出现异常,此时仅存活一个 F 副本和仲裁服务,不满足多数派,日志流将会无主,无法执行日志流降级。
环境信息
- CentOS Linux release 7.5.1804 (Core)
- OCP 云平台:4.2.0
- OceanBase:4.2.1.4
- 测试租户:mysql_ob
- 租户模式:MySQL
- 租户规格:1.5C6G
实验过程
故障前
- 查看
mysql_ob租户日志流,可以看到有 3 个日志流。
select tenant_id,ls_id from oceanbase.CDB_OB_TABLET_TO_LS where tenant_id = 1002 group by LS_ID;
查看集群普通副本节点状态。
SELECT * FROM oceanbase.DBA_OB_SERVERS;
查看业务租户
mysql_ob的leader/follower角色信息。
- 161 节点为 leader
- 163 节点为 follower
select b.tenant_name,a.tenant_id,a.ls_id,a.zone,a.svr_ip,a.role from cdb_ob_table_locations a join __all_tenant b on a.tenant_id = b.tenant_id where a.tenant_id = 1002 group by role;

- 查看仲裁服务节点
- 164 节点为仲裁服务节点
select * from DBA_OB_ARBITRATION_SERVICE;
- 租户
mysql_ob为 2F1A 架构(2F:10.186.64.161/163 , 1A:10.186.64.164)。
- 查看仲裁节点与其他节点联通性。
- ACTIVE: 表示仲裁服务与该节点通信正常。所有节点均通信正常才可以为租户开启仲裁服务。
- INACTIVE: 表示仲裁服务与该节点无法通信。无法为租户开启仲裁服务,需要排查节点与仲裁服务之间的网络通信情况。
SELECT * FROM oceanbase.GV$OB_ARBITRATION_SERVICE_STATUS;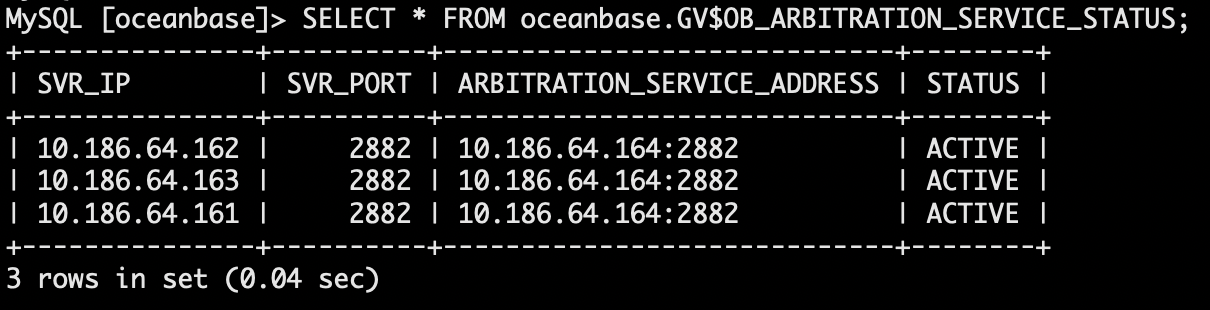
- 查看租户的仲裁服务状态
- ENABLED: 表示租户已开启仲裁服务。
- DISABLED: 表示租户已关闭仲裁服务。
- ENABLING: 表示租户正在开启仲裁服务。
- DISABLING: 表示租户正在关闭仲裁服务。
select TENANT_ID,TENANT_NAME,PRIMARY_ZONE,STATUS,TENANT_ROLE,SWITCHOVER_STATUS,ARBITRATION_SERVICE_STATUS from DBA_OB_TENANTS;
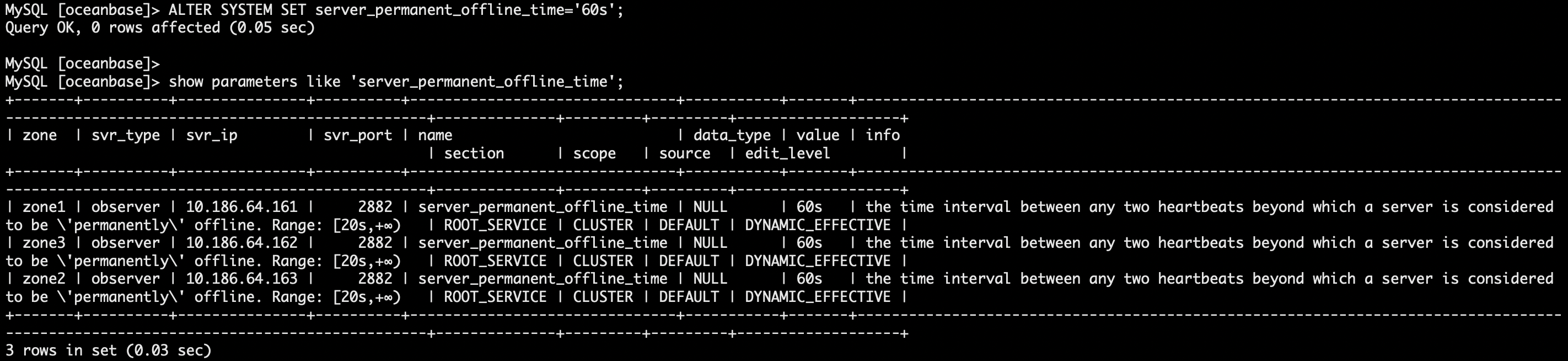
查看永久下线时间参数。
show parameters like 'server_permanent_offline_time';
永久下线时间调整为 60s。
ALTER SYSTEM SET server_permanent_offline_time='60s'; show parameters like 'server_permanent_offline_time';
- 启动脚本,持续往
evan.time_table表写入数据。

- 启动另一个脚本,持续
select evan.time_table表的最新数据。
4.2 施加故障
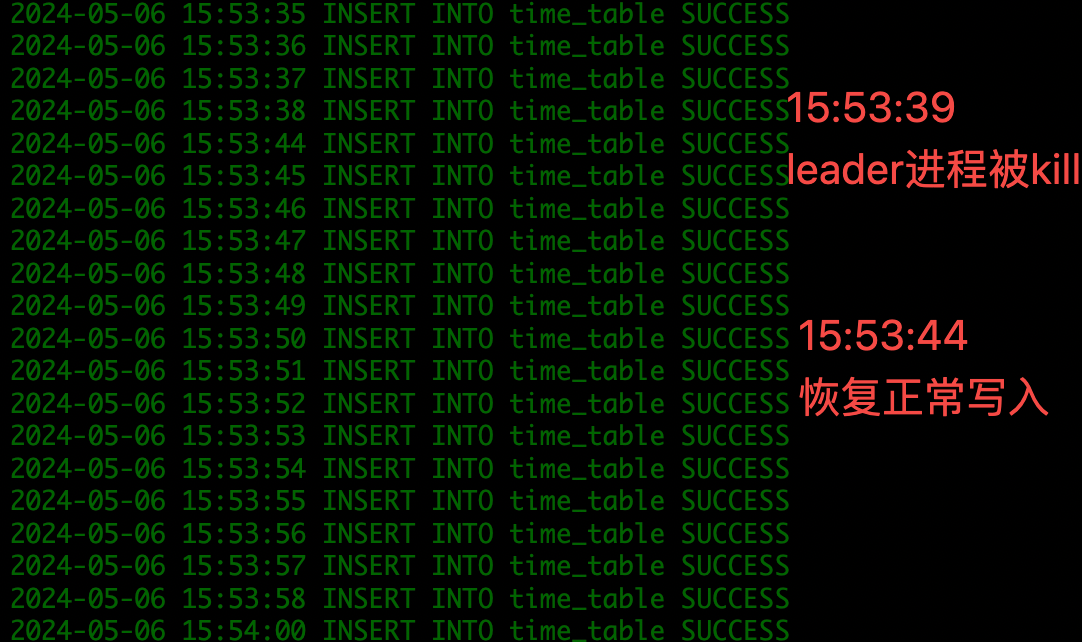
模拟故障:kill 掉第 1 个全能型副本
业务租户 leader 节点执行。
ps -ef | grep observer | grep -v "grep"
date && kill -9 $(ps aux | grep "observer" | grep -v "grep" | awk '{print $2}') && ps -ef | grep observer | grep -v grep && date
4.3 故障后观察
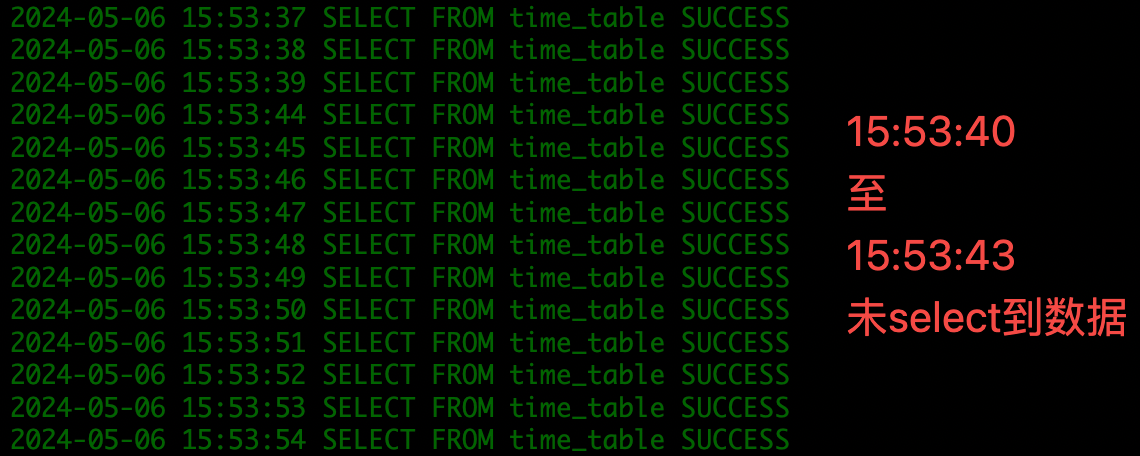
- 查看脚本写入状态是否正常。
- 查看脚本 select 是否正常。
- 查看业务租户 leader/follower 角色信息。

- 确认触发日志流降级。
当故障副本(包括已降级的副本)总数等于全功能副本总数的一半时,仲裁服务才会执行日志流降级操作。
SELECT * FROM oceanbase.DBA_OB_SERVER_EVENT_HISTORY WHERE EVENT LIKE "%DEGRADE%" AND VALUE1 = 1002 AND TIMESTAMP >= '2024-05-06 15:53%' ORDER BY 1 ;
确认节点状态变成 INACTIVE。
SELECT * FROM oceanbase.DBA_OB_SERVERS;
查看仲裁节点与其他节点联通性。
无法与 161 节点联通。
SELECT * FROM oceanbase.GV$OB_ARBITRATION_SERVICE_STATUS;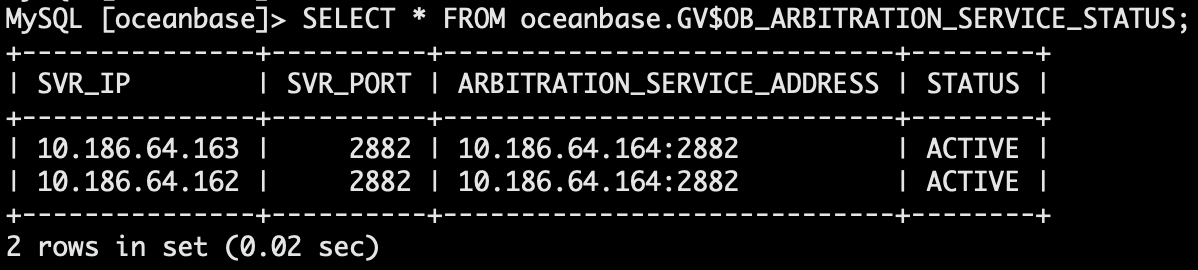
- 确认旧 leader 161 节点触发永久下线(预期 60s 后永久下线)。
select * from __all_rootservice_event_history where event='permanent_offline' and gmt_create like '2024-05-06%' \G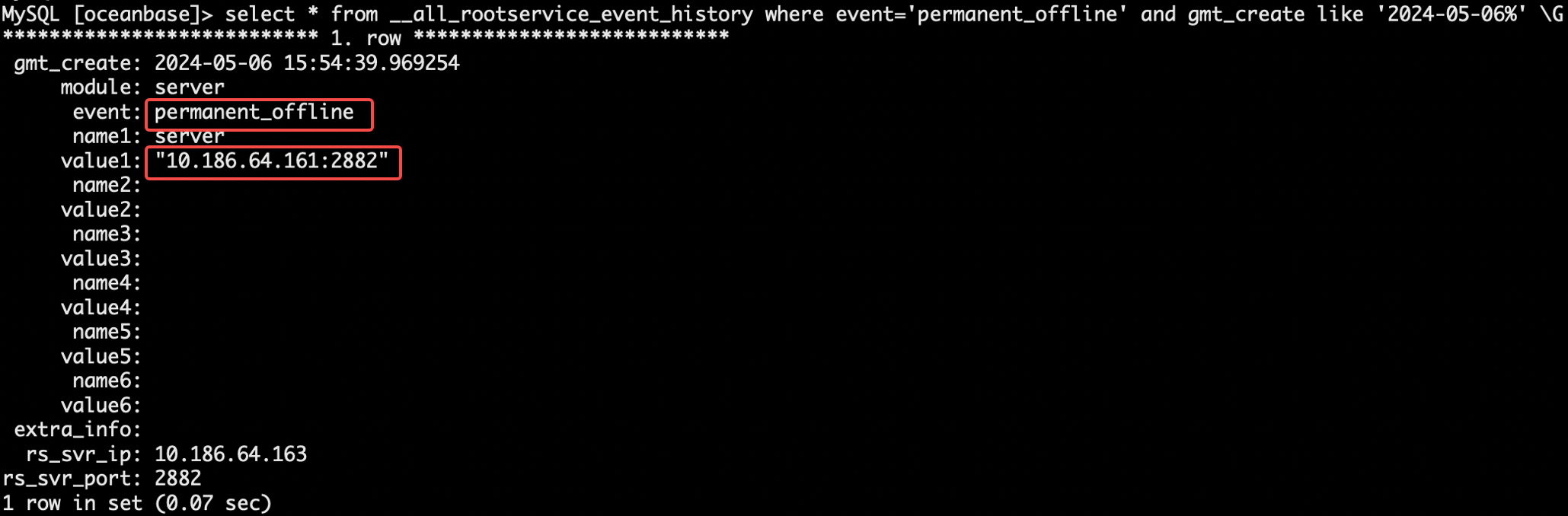
- 查询 kill 掉第 1 个 observer 时间点前后,业务表
time_table实际是否有数据插入失败。
select * from evan.time_table where time >= '2024-05-06 15:53:37' order by time limit 20;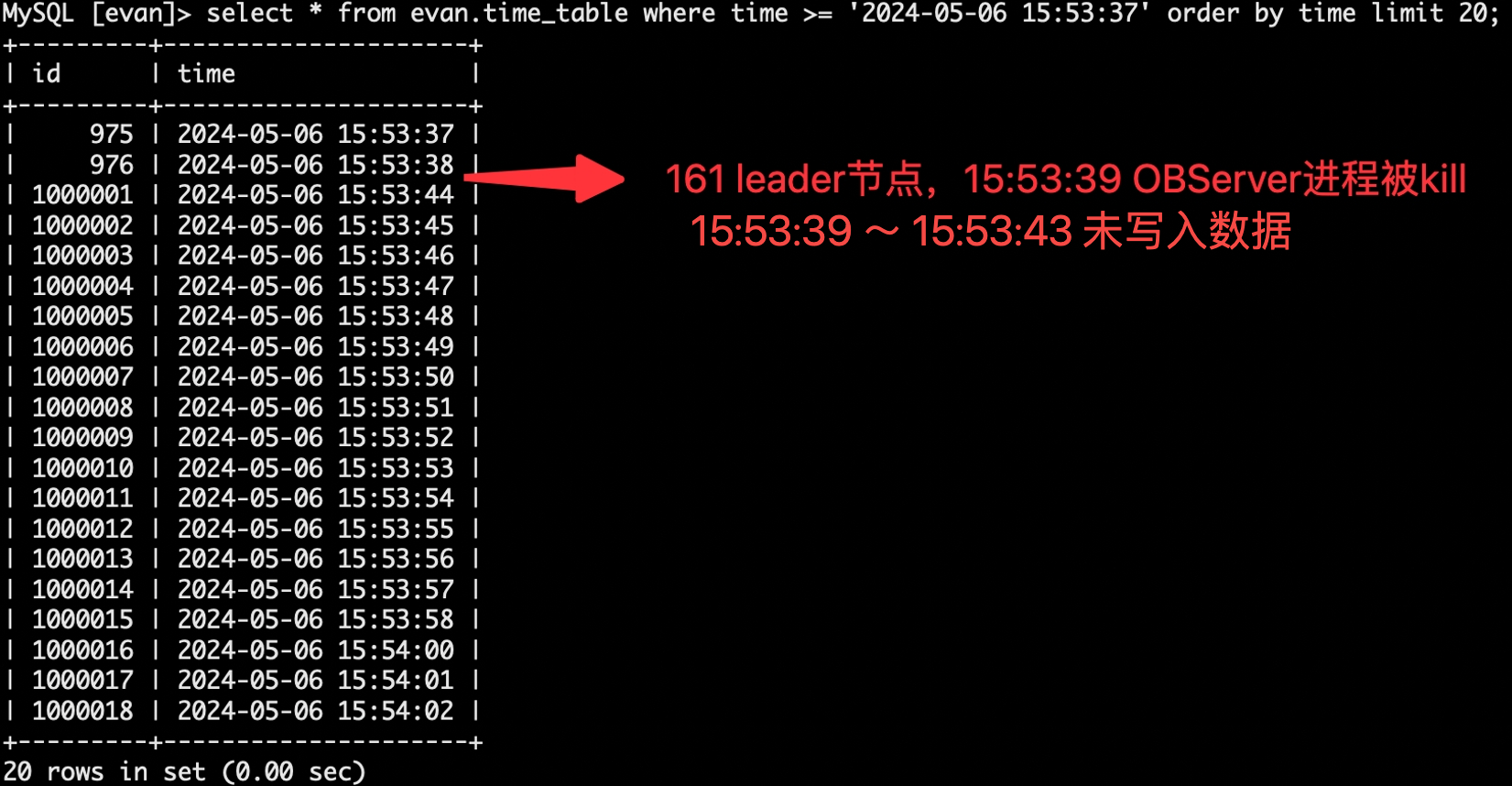
施加故障
故障模拟:kill 掉第 2 个全能型副本。
- 业务租户 follower 节点执行。
ps -ef | grep observer | grep -v "grep"
date && kill -9 $(ps aux | grep "observer" | grep -v "grep" | awk '{print $2}') && ps -ef | grep observer | grep -v grep && date
故障后观察
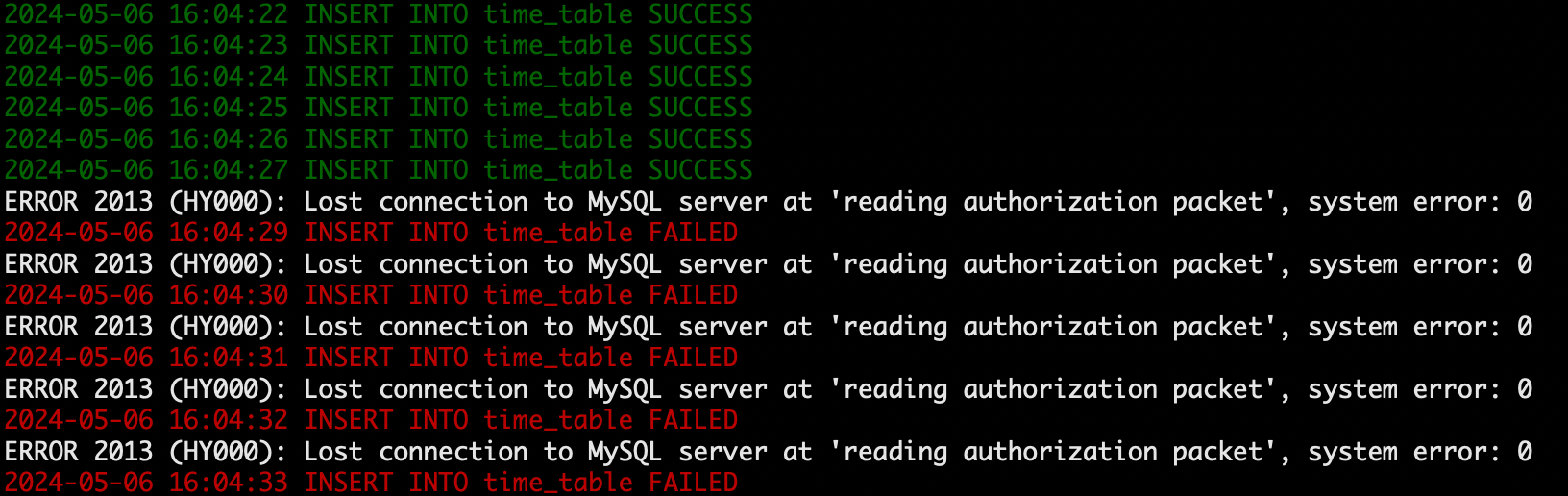
- 查看脚本 insert 数据是否正常。
处于异常状态。
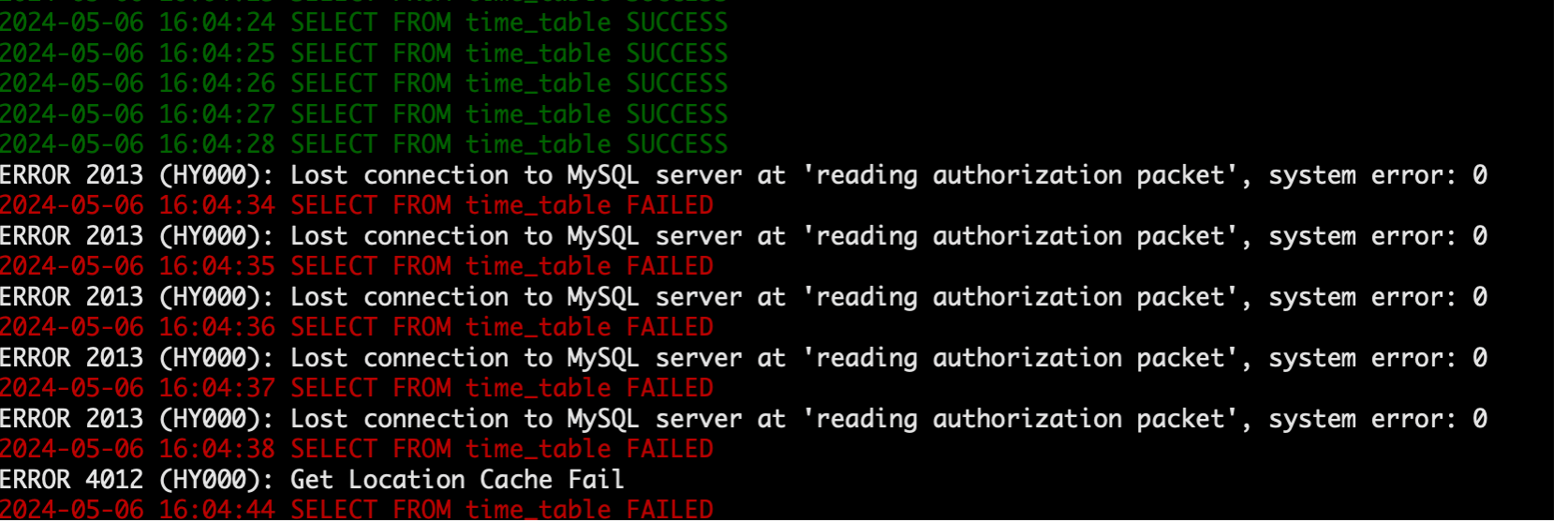
- 查看脚本 select 数据是否正常。
处于异常状态。
- 查看业务租户 leader/follower 角色信息。
无主状态,执行 SQL 超时。
select b.tenant_name,a.tenant_id,a.ls_id,a.zone,a.svr_ip,a.role from cdb_ob_table_locations a join __all_tenant b on a.tenant_id = b.tenant_id where a.tenant_id = 1002 group by role;
- 确认日志流降级。
SELECT * FROM oceanbase.DBA_OB_SERVER_EVENT_HISTORY WHERE EVENT LIKE "%DEGRADE%" AND VALUE1 = 1002 AND TIMESTAMP >= '2024-05-06 16%' ORDER BY 1 ;

- 确认节点状态变成 INACTIVE。
SELECT * FROM oceanbase.DBA_OB_SERVERS;

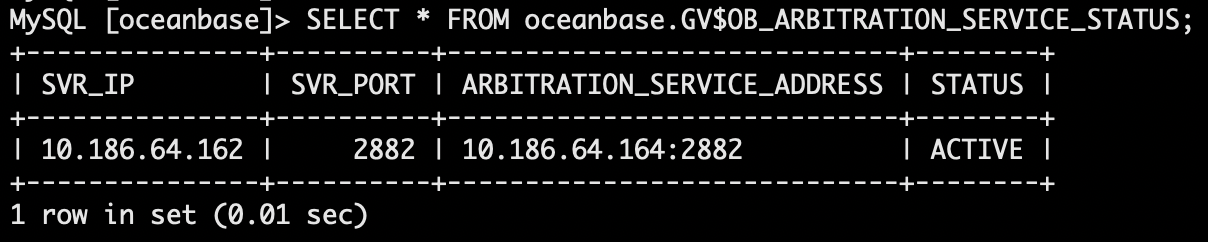
- 查看仲裁节点与其他节点联通性。
161 和 163 节点均无法联通。
- 确认节点触发永久下线(预期 60s 后永久下线)。
161 和 163 节点均被标记永久下线。
select * from __all_rootservice_event_history where event='permanent_offline' and gmt_create like '2024-05-06%' \G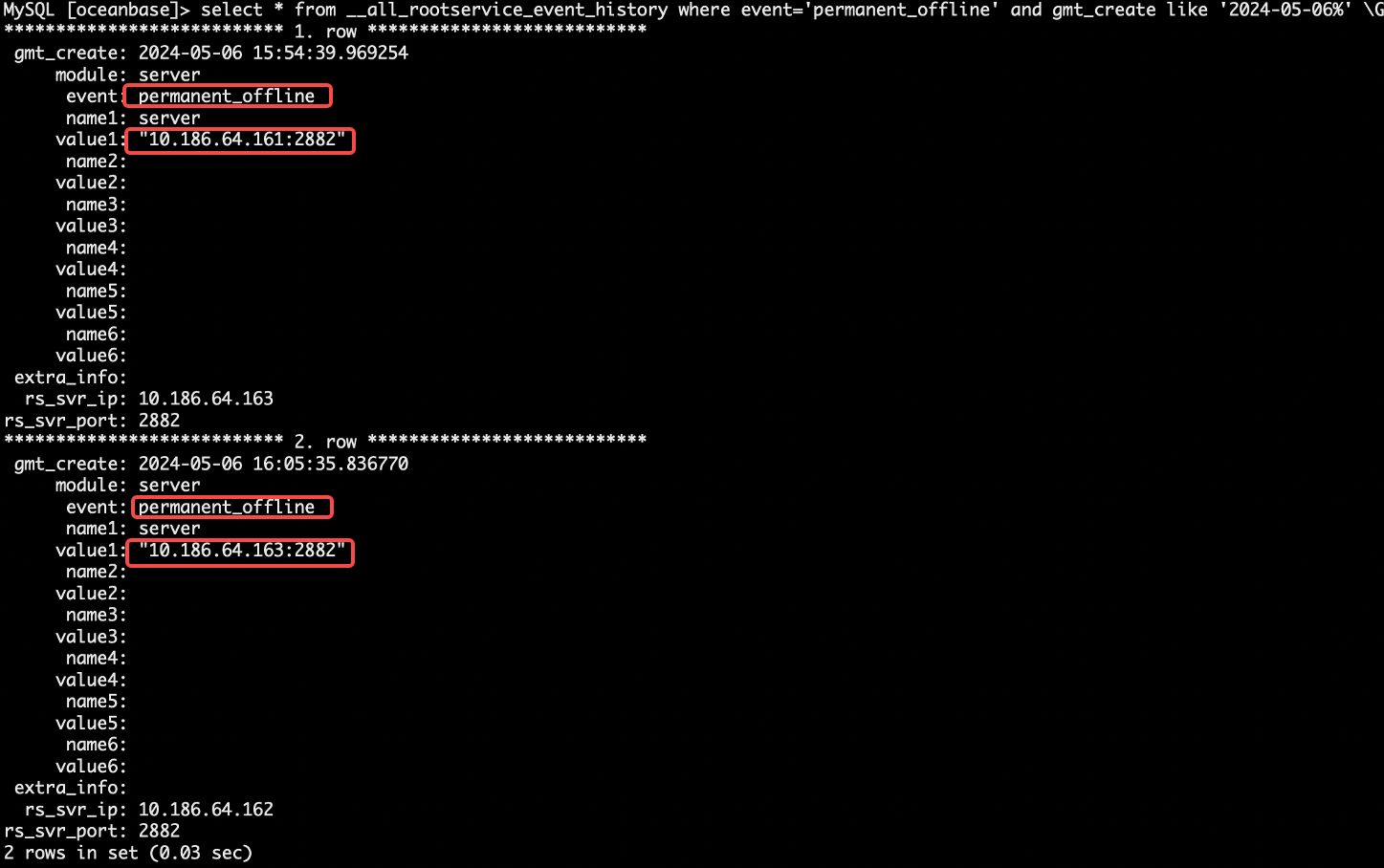
- 查询 kill 掉第 2 个 observer 时间点前后,业务表
time_table实际是否有数据插入失败。
租户故障期间无法查询,恢复正常后补图。
select * from evan.time_table where time >= '2024-05-06 16:04:25' order by time limit 20;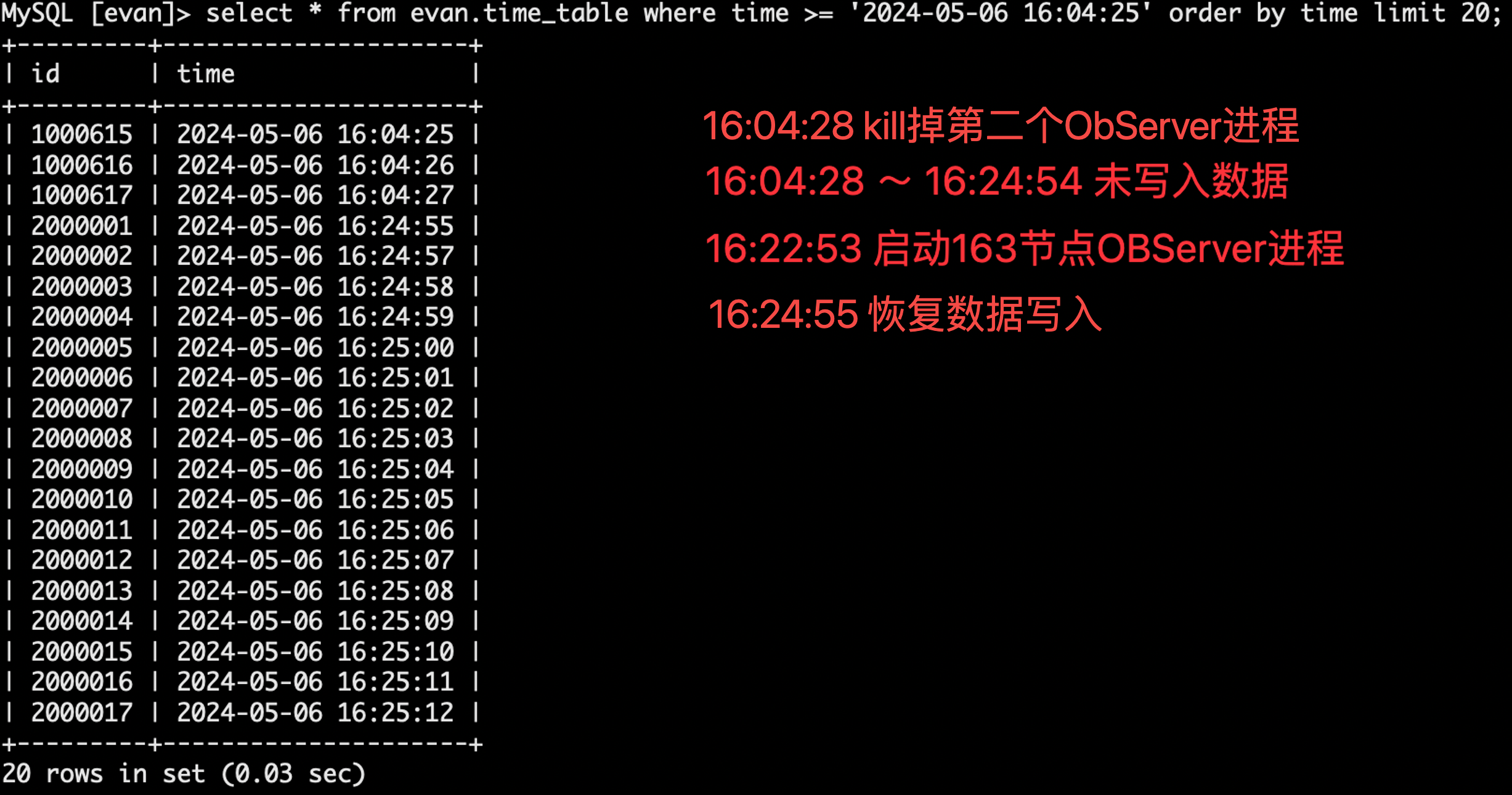
- 确认租户处于无主状态。
- 查看最近 30 分钟是否有原主租约过期的情况。
161 和 163 节点均存在租约过期记录。
SELECT * FROM __all_rootservice_event_history WHERE module = 'server' AND event = 'lease_expire' AND gmt_create > usec_to_time(time_to_usec(now())-3600*1000000) ORDER BY gmt_create;
- 在 observer 全能型副本的主机上确认日志打印信息存在 4038 错误码。

cd /home/admin/oceanbase/log && grep "ret=-4038" observer.log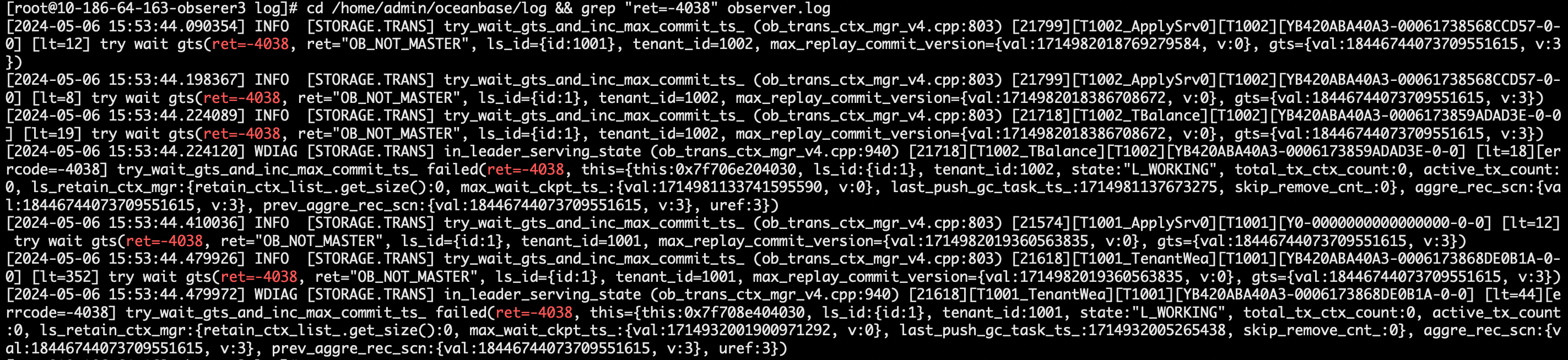
修复故障
- 辨别启动 OBServer 节点的先后顺序。
由于此时租户已经不满足多数派,处于故障状态,我们应该先启动故障时间较晚的 OBServer 节点,再启动故障时间较早的 OBServer 节点。(通过 observer.log 最后写入的时间点做判断)
tail -1 /home/admin/oceanbase/log/observer.log

- 启动 163 节点。
根据上一步骤判断 163 节点 observer.log 较新。
su - admin
cd /home/admin/oceanbase
date && ./bin/observer
ps -ef | grep observer | grep -v "grep"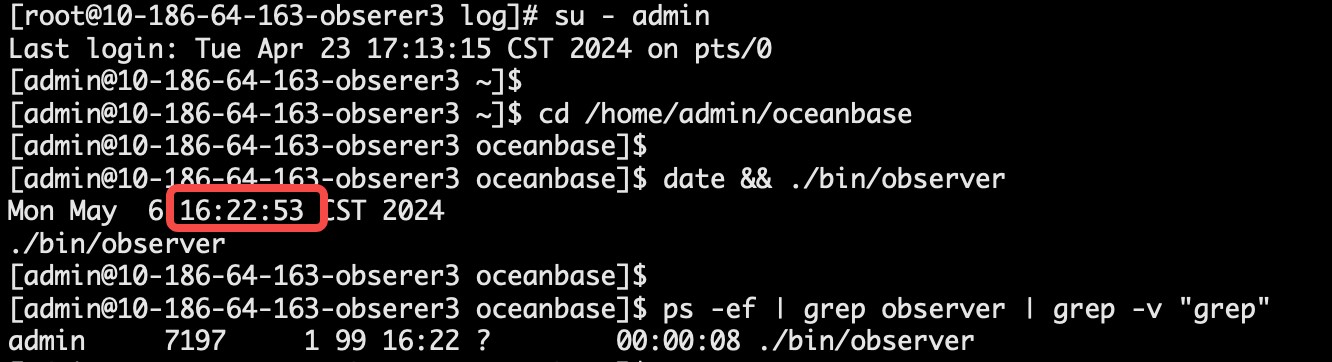
- 确认 insert 脚本状态。
16:24:56 写入数据成功。
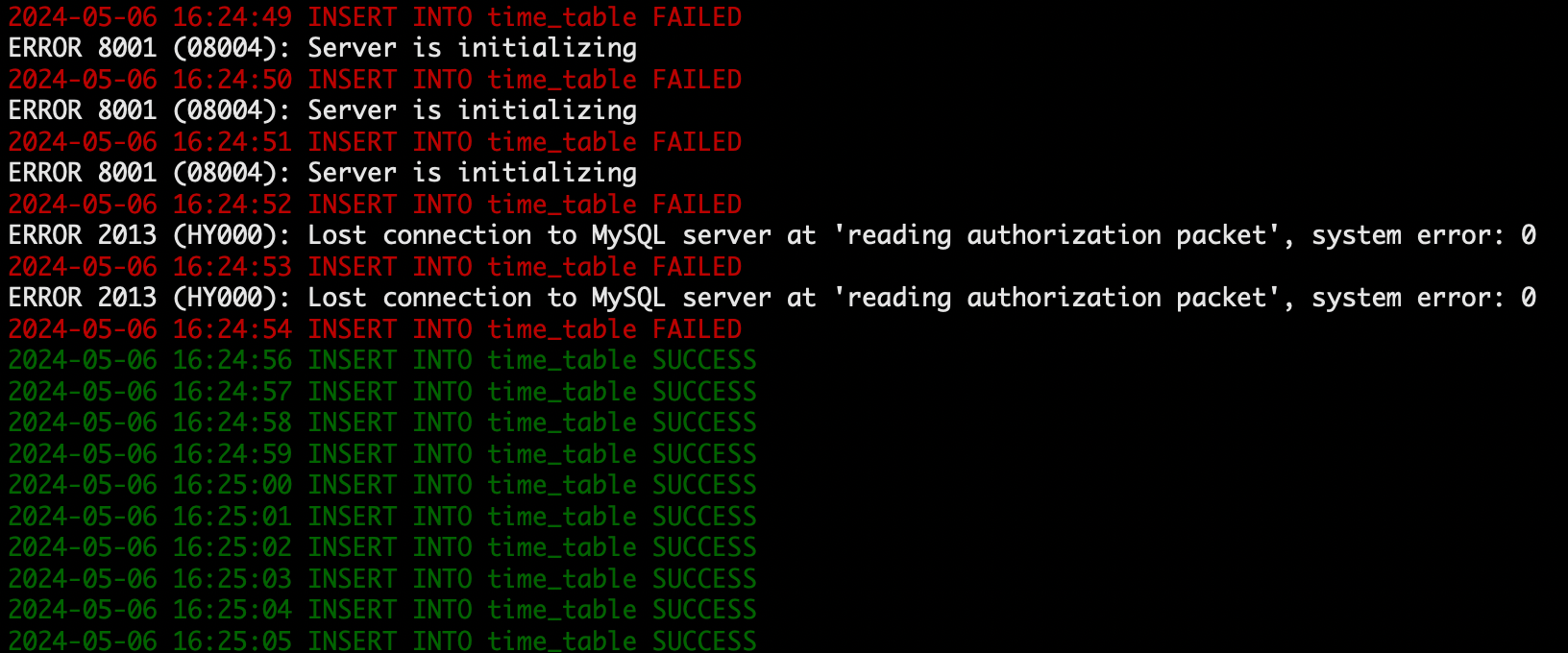
- 确认 select 脚本状态。
16:24:55 读取数据成功(脚本打印时间每隔1秒打印一次,存在细微误差属正常情况)。
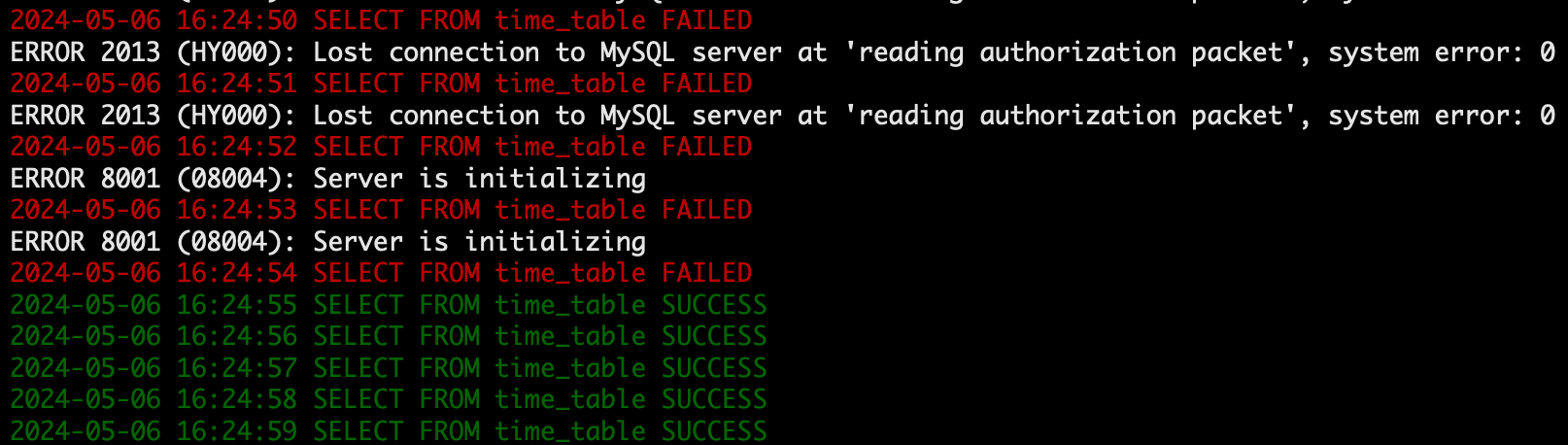
- 确认 163 节点状态变成 ACTIVE。
SELECT * FROM oceanbase.DBA_OB_SERVERS;
- 启动 161 节点。
根据之前的步骤判断 161 节点 observer.log 较旧,后启动。
su - admin
cd /home/admin/oceanbase
date && ./bin/observer
ps -ef | grep observer | grep -v "grep"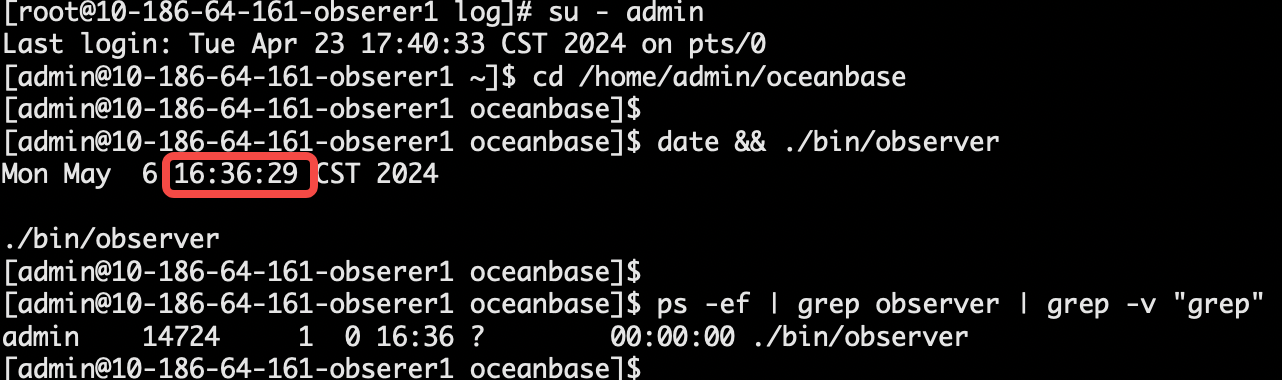
确认 161 节点 OBServer 状态变成 ACTIVE。
SELECT * FROM oceanbase.DBA_OB_SERVERS;
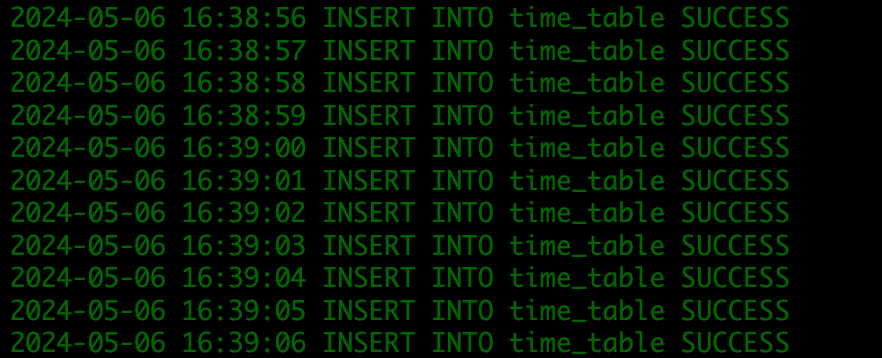
- 确认 insert 脚本状态。
正常写入。
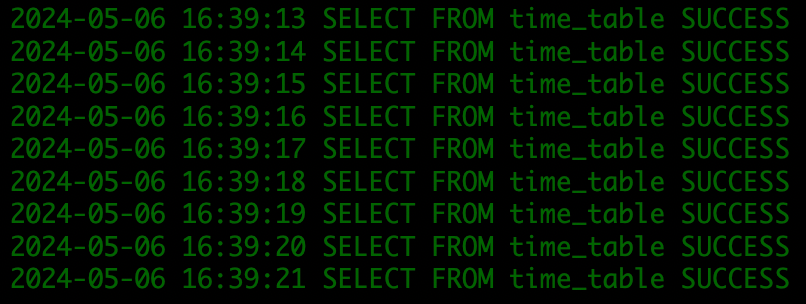
- 确认 select 脚本状态。
正常读取。
- 通过
oceanbase.DBA_OB_UNIT_JOBS视图查看数据补全进度。
如果查询结果为空,则表示 Unit 迁移完成,数据补全成功。
SELECT * FROM oceanbase.DBA_OB_UNIT_JOBS WHERE JOB_TYPE = 'MIGRATE_UNIT';
查看测试表
time_table的tenant_id和ls_id(日志流 ID)。SELECT TENANT_ID, LS_ID FROM oceanbase.CDB_OB_TABLET_TO_LS WHERE TABLET_ID = (SELECT DATA_OBJECT_ID FROM oceanbase.CDB_OBJECTS WHERE OBJECT_NAME ='time_table' AND OBJECT_TYPE='TABLE');
查看测试表
time_table对应日志流的选举记录。
lease_time:当 Root Service 累计超过 lease_time 时间没有收到过某节点的任意心跳数据包时,Root Service 认为该 observer 进程短暂断线,Root Service 会标记该节点的心跳状为 lease_expired。
SELECT * FROM DBA_OB_SERVER_EVENT_HISTORY WHERE MODULE LIKE '%ELECTION%' and TIMESTAMP >= '2024-05-06 15:53:37' AND NAME1 = 'TENANT_ID' AND VALUE1 = '1002' AND NAME2 = 'LS_ID' AND VALUE2 =1001 ORDER BY TIMESTAMP;
- 永久下线时间改回原值并确认生效。
ALTER SYSTEM SET server_permanent_offline_time='3600s';
show parameters like 'server_permanent_offline_time';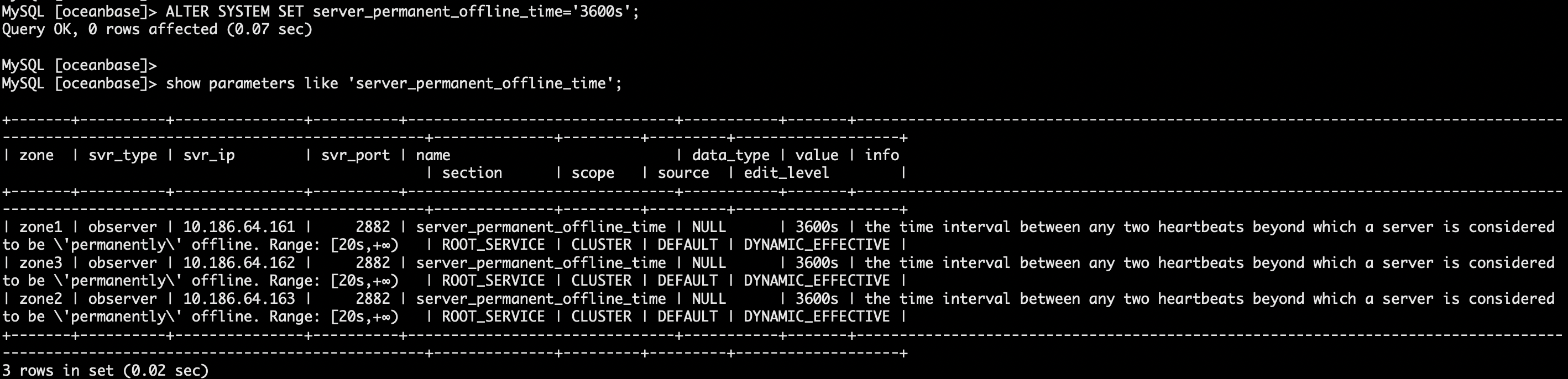
时间线梳理
时间线
- 将永久下线时间参数
server_permanent_offline_time调成 60s - 2024-05-06 15:53:39 kill 掉 161 节点全能型副本节点(leader)
- 2024-05-06 15:53:39 ~ 15:53:43 约持续 5s,insert 脚本未写入数据,select 脚本未读到数据
- leader 节点由 161 切至 163
- 2024-05-06 15:53:43 161节点触发日志流降级,原因:CRASHED_OR_BROKEN_NETWORK
- 2024-05-06 15:54:39 161 节点被标记永久下线
- 2024-05-06 16:04:28 kill 掉 163 节点全能型副本节点(新 leader)
- 2024-05-06 16:04:28 租户开始进入读写异常状态
- 确认两个全能型副本状态都为:INACTIVE
- 仲裁服务节点与 2 个异常节点联通异常
- 2024-05-06 16:05:35 163 节点被标记永久下线
- 租户处于无主状态
- 2024-05-06 16:22:53 启动 163 节点全能型副本节点(后被 kill,先启动)
- 2024-05-06 16:24:55 租户恢复正常读写
- 2024-05-06 16:36:29 启动 161 节点全能型副本节点
- 将永久下线时间参数
server_permanent_offline_time调回3600s
小结
- kill 掉 1 个全能型副本节点后(leader),租户存在约5s读写异常,后续恢复正常。
- kill 掉 2 个全能型副本节点后,租户进入无主状态,读写状态异常。
- 启动 163 节点全能型副本节点,可正常加回集群,约 117s 后租户读写恢复正常。
- 启动 161 节点全能型副本节点后,可正常加回集群。
结论
- 1 个全能型副本(leader)发生故障后租户能否正常读写?
结论:租户切主期间短暂读写异常,后续恢复正常读写。
- 2 个全能型副本发生可恢复的故障,均触发永久下线,后续启动OBServer后集群能否恢复正常?
结论:可恢复正常。
需注意的点:极端情况下如果第二个全能型副本也发生故障且无法恢复,之后即使第一个 全能型副本恢复了,也会有数据丢失,原因是仲裁成员不存储 Redo 日志。
综上,成本敏感或预算有限且能承受可能丢失数据的情况可以选择 OceanBase 2F1A 仲裁高可用方案,若期望数据不丢失建议选择全功能型副本高可用方案。
后记
仲裁服务两个典型的应用场景在于 “自动选主提升同城自动容灾能力” 和 “降低跨城带宽提升两地三中心稳定性”,感兴趣的读者可查看《OceanBase 助力企业应对数据库转型深水区挑战》 中关于仲裁服务章节的内容。
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
✨ Github:https://github.com/actiontech/sqle
📚 文档:https://actiontech.github.io/sqle-docs/
💻 官网:https://opensource.actionsky.com/sqle/
👥 微信群:请添加小助手加入 ActionOpenSource















 1760
1760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









