







1、Confluent基本概念
1.1、Confluent组成
Confluent目前提供了社区版和商业版两个版本,社区版永久免费,商业版面向企业收费。社区版提供了Connectors、REST Proxy、KSQL、Schema-Registry等基础服务。商业版为企业提供了控制面板、负载均衡,跨中心数据备份、安全防护等高级特性。
1.1.1、Zookeeper
Zookeeper是一个开源的分布式协调服务,是Google的Chubby一个开源的实现,是Hadoop、Hbase、Storm的重要组件。
Zookeeper主要功能包含:维护配置信息、命名、提供分布式同步、组管理等集中式服务 。
Kafka使用ZooKeeper对集群元数据进行持久化存储,是Confluent平台部署的关键组件。
如果ZooKeeper丢失了Kafka数据,集群的副本映射关系以及topic等配置信息都会丢失,最终导致Kafka集群不再正常工作,造成数据丢失的后果。
想要了解更多Zookeeper信息,可以查看官方链接:官网 https://zookeeper.apache.org/ 。
注意: 随着kafka的逐渐发展,zookeeper在kafka中的作用越来越小,在kafka 0.9 版本之前,kafka消费者的偏移量信息记录在zookeeper中,但是在kafka 0.9版本之后,kafka消费者的偏移量信息就记录在kafka自身的一个主题中(_consumer_offsets),而在最近的kafka 2.8 版本中,kafka已经可以完全不需要zookeeper了。
消息系统兴起二次革命:Kafka不需要ZooKeeper - 云+社区 - 腾讯云 (tencent.com)
1.1.2、Kafka
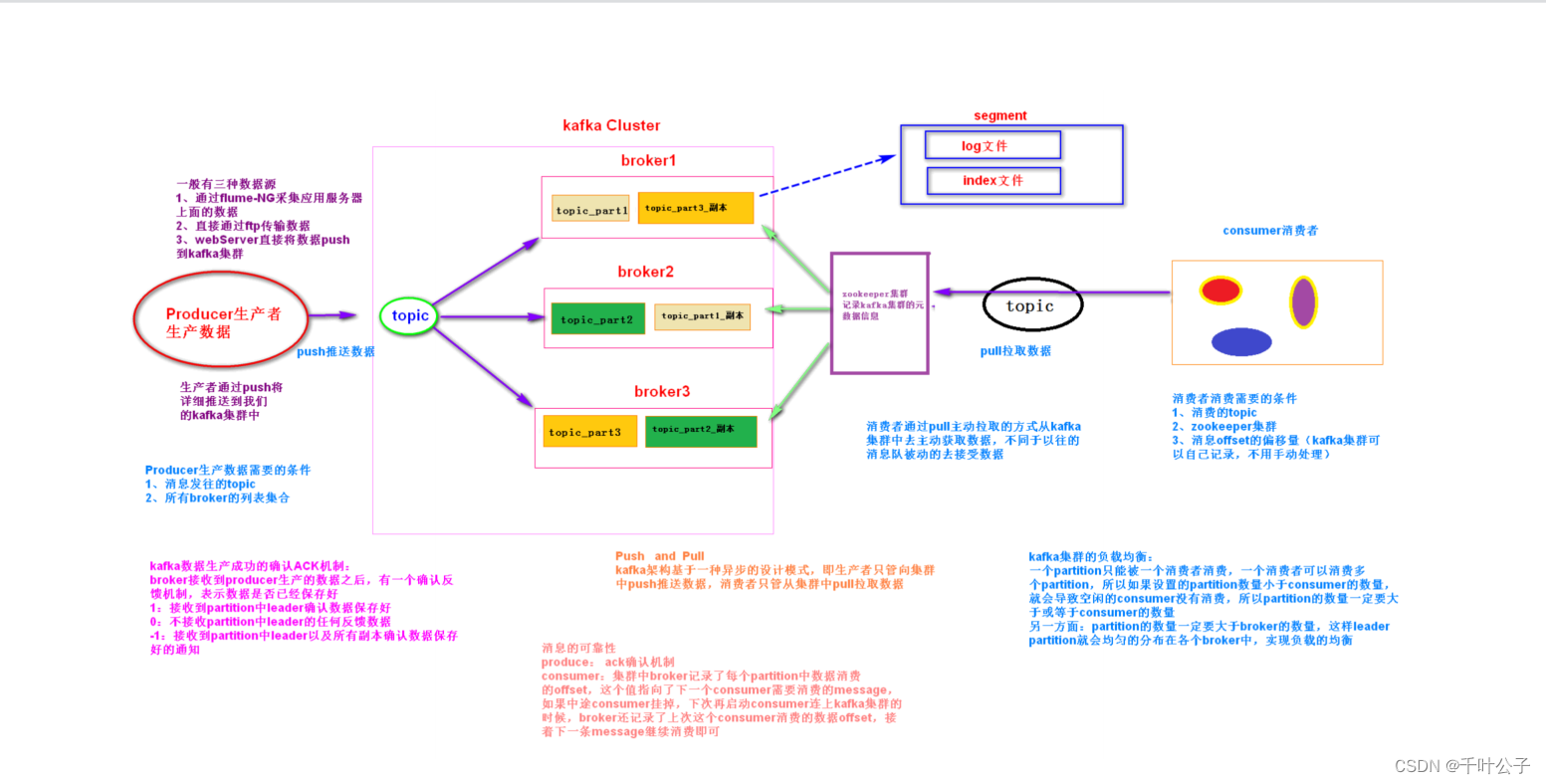
Kafka是一个分布式流处理平台,最初由Linkedin公司开发,是一个基于zookeeper协调并支持分区和多副本的分布式消息发布订阅系统。
Kafka最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎、web/nginx日志、访问日志、消息服务等等。Kafka工作原理是一种高吞吐量的分布式发布订阅消息系统,消息队列中间件,主要功能是负责消息传输,Confluent就是依赖Kafka来进行消息传输。
Kafka的核心组成部分可以分为三个:生产者(producer)、主题(topic)、消费者(consumer)除此之外还有broker、zookeeper
1.1.3、Schema-Registry
Confluent 公司为了能让 Kafka 支持 Avro 序列化,创建了 Kafka Schema Registry 项目,项目地址为https://github.com/confluentinc/schema-registry 。对于存储大量数据的 kafka 来说,使用 Avro 序列化,可以减少数据的存储空间提高了存储量,减少了序列化时间提高了性能。
Kafka 有多个topic,里面存储了不同种类的数据,每种数据都对应着一个 Avro schema 来描述这种格式。Registry 服务支持方便的管理这些 topic 的schema,它还对外提供了多个 restful 接口,用于存储和查找。
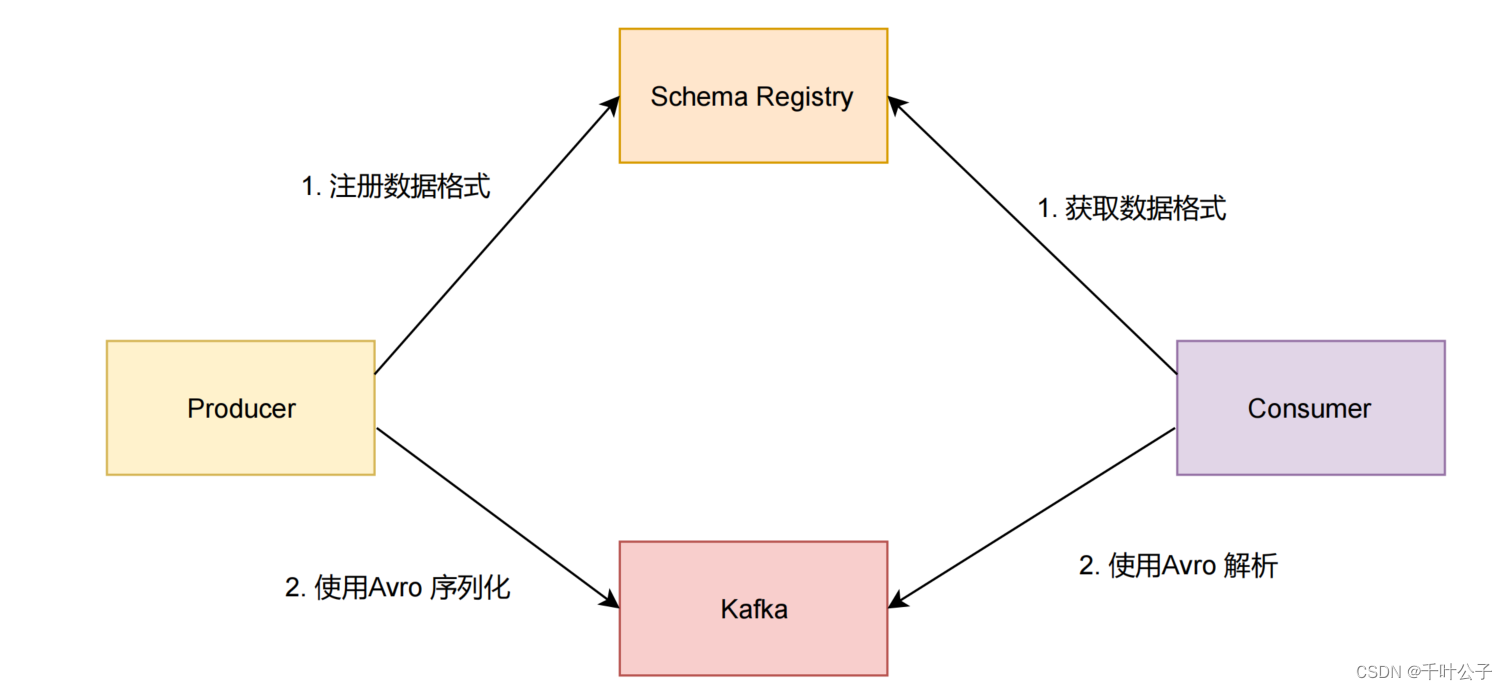
我们向 kafka 发送数据时,需要先向 Schema Registry 注册 schema,然后序列化发送到 kafka 里。当我们需要从 kafka 消费数据时,也需要先从 Schema Registry 获取 schema,然后才能解析数据。
Kafka Schema Registry 原理
学习笔记
更多Apache Avro 用法可以参见官方文档
1.1.4、Kafka-Connect
Kafka Connect是 Kafka的一个开源组件,是用来将Kafka与数据库、key-value存储系统、搜索系统、文件系统等外部系统连接起来的基础框架。
通过使用Kafka Connect框架以及现有的Connector可以实现从源数据读入消息到Kafka,再从Kafka读出消息到目的地的功能。
Confluent 在Kafka connect基础上实现了多种常用系统的connector免费让大家使用。有开源的,有商用的。
更多的支持可以查看:Confluent Connector Portfolio
1.1.5、Kafka-connect-Rest
Kafka Connect 作为 service 提供了 REST API 服务,用来:
- 获取 Kafka Connect 状态
- 管理 Kafka Connect 配置
- Kafka Connect 集群内部通信
常用命令如下:
# 获取 Connect Worker 信息
`curl -s <Kafka Connect Worker URL>:8083/ | jq`
# 列出 Connect Worker 上所有 Connector
`curl -s <Kafka Connect Worker URL>:8083/connector-plugins | jq`
# 获取 Connector 上 Task 以及相关配置的信息
`curl -s <Kafka Connect Worker URL>:8083/connectors/<Connector名字>/tasks | jq`
# 获取 Connector 状态信息
`curl -s <Kafka Connect Worker URL>:8083/connectors/<Connector名字>/status | jq`
# 获取 Connector 配置信息
`curl -s <Kafka Connect Worker URL>:8083/connectors/<Connector名字>/config | jq`
# 暂停 Connector
`curl -s -X PUT <Kafka Connect Worker URL>:8083/connectors/<Connector名字>/pause`
# 重启 Connector
`curl -s -X PUT <Kafka Connect Worker URL>:8083/connectors/<Connector名字 >/resume`
# 删除 Connector
`curl -s -X DELETE <Kafka Connect Worker URL>:8083/connectors/<Connector名字>`
# 创建新 Connector (以FileStreamSourceConnector举例)
curl -s -X POST -H "Content-Type: application/json" --data '{"name": "<Connector名字>", "config": {"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector", "key.converter.schemas.enable":"true", "file":"demo-file.txt", "tasks.max":"1", "value.converter.schemas.enable":"true", "name":"file-stream-demo-distributed", "topic":"demo-distributed", "value.converter":"org.apache.kafka.connect.json.JsonConverter", "key.converter":"org.apache.kafka.connect.json.JsonConverter"} }'
http://<Kafka Connect Worker URL>:8083/connectors | jq
# 更新 Connector配置 (以FileStreamSourceConnector举例)
curl -s -X PUT -H "Content-Type: application/json" --data '{"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector", "key.converter.schemas.enable":"true", "file":"demo-file.txt", "tasks.max":"2", "value.converter.schemas.enable":"true", "name":"file-stream-demo-distributed", "topic":"demo-2-distributed", "value.converter":"org.apache.kafka.connect.json.JsonConverter", "key.converter":"org.apache.kafka.connect.json.JsonConverter" }'
<Kafka Connect Worker URL>:8083/connectors/file-stream-demo-distributed/config | jq
上面5个服务启动之后,会存在6个对应的进程:
QuorumPeerMain # zookeeper
ConnectStandalone # kafka-connect
KafkaRestMain # kafka-rest
SchemaRegistryMain # schema-registry
SupportedKafka # kafka
1.2、kafka-connect架构
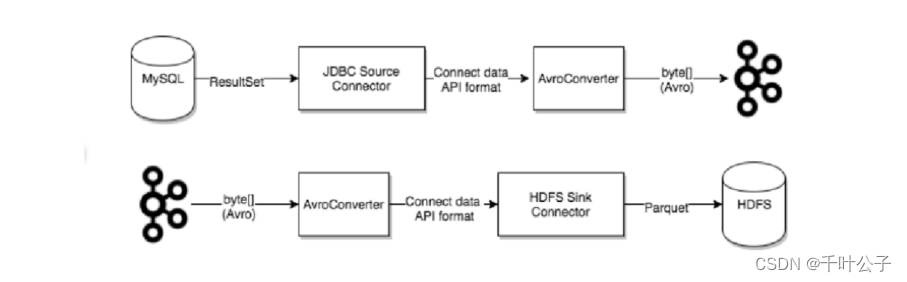
Kafka Connect是 Kafka的一个开源组件,是用来将Kafka与数据库、key-value存储系统、搜索系统、文件系统等外部系统连接起来的基础框架。通过使用Kafka Connect框架以及现有的Connector可以实现从源数据读入消息到Kafka,再从Kafka读出消息到目的地的功能。
下图是一个简单数据从MySQL中采集然后写入到HDFS中的数据在confluent中传输过程
1.2.1、开发connector
2、基于confluent的采集共享
2.1、功能需求
需求1:支持全量和增量的批数据传输
需求2:支持可周期性执行
需求3:支持不同类型的数据源
2.2、方案设计
2.2.1、设置消息格式
消息分为消息头和消息体
消息头:保存描述消息的相关信息,每个消息头中新增的字段信息
| 字段 | 描述 |
|---|---|
| taskId | 任务ID,由调度器在创建connector时传入(对应connector创建时的pkuse.task.id属性)。必填,无默认值。 |
| predictedTotal | 预计此次发送的消息总数,由source connector在开始一次任务时根据要传输的数据量计算确定。必填,无默认值。 |
| currentIndex | 当前发送的消息索引号,从1开始,用来计数一次任务的消息位置。必填,无默认值。 |
| isEnd | 是否此次任务的最后一条消息。可选,默认为false。 |
在source-connector中添加消息头的描述,在sink-connector中获取消息头的描述,并以此判断本次任务消费的数据是否结束,从而是否结束任务。消息中保存真正的数据。
2.2.2、监控任务状态
对执行中任务状态的监控方案设计是:在kafka-connect生产和消费数据的不同阶段发送消息到pkuse_status 主题中,调度执行器消费 pkuse_status 中的消息,由此确定任务执行的状态。
pkuse_status 主题中的消息格式是:
| 字段 | 描述 |
|---|---|
| connectorName | 产生状态消息的connector名称(对应于connector创建时的pkuse.connector.name属性) |
| taskId | 任务ID,由调度器在创建connector时传入(对应connector创建时的pkuse.task.id属性)。必填,无默认值 |
| dataTopicName | 此状态消息对应的数据主题名称。可选。 |
| stage | (start/processing/end/error),处理的所处阶段:开始/处理中/完成/失败,必填。每次生产或消息消息必须有start、end或error中的一个,用以表示一个完整的处理周期。 |
| description | 开始:预估总数,完成:准确总数,失败:报错堆栈信息 |
2.3、编码实现
2.3.1、HBaseConnector实现
开发HBaseSourceConnector、HBaseSinkConnector
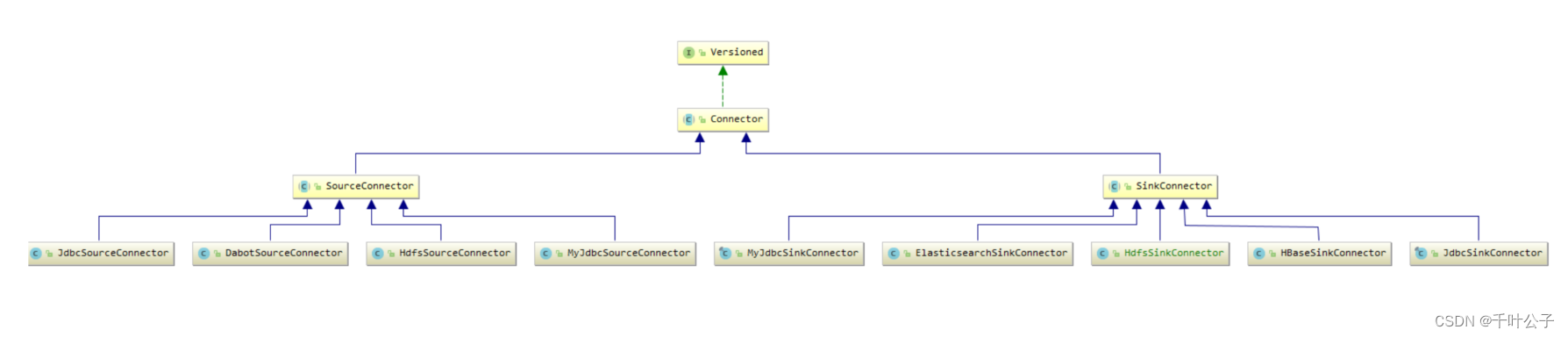
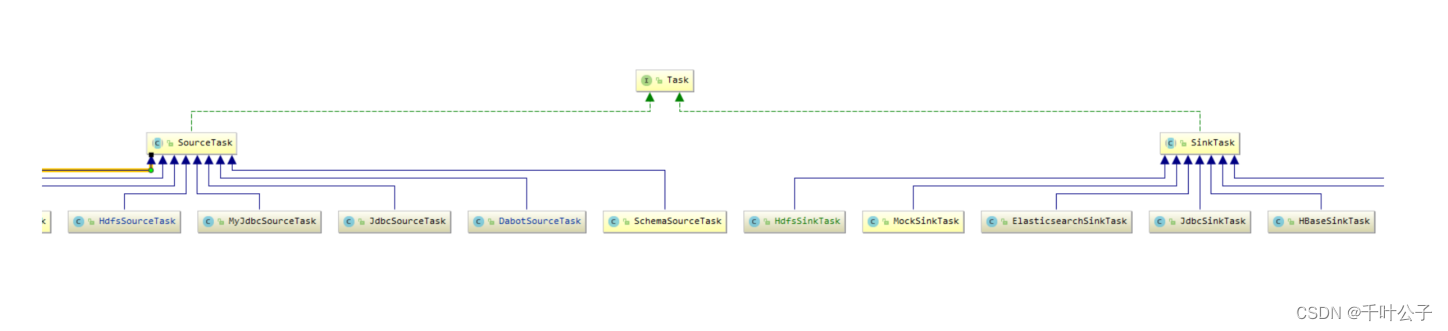
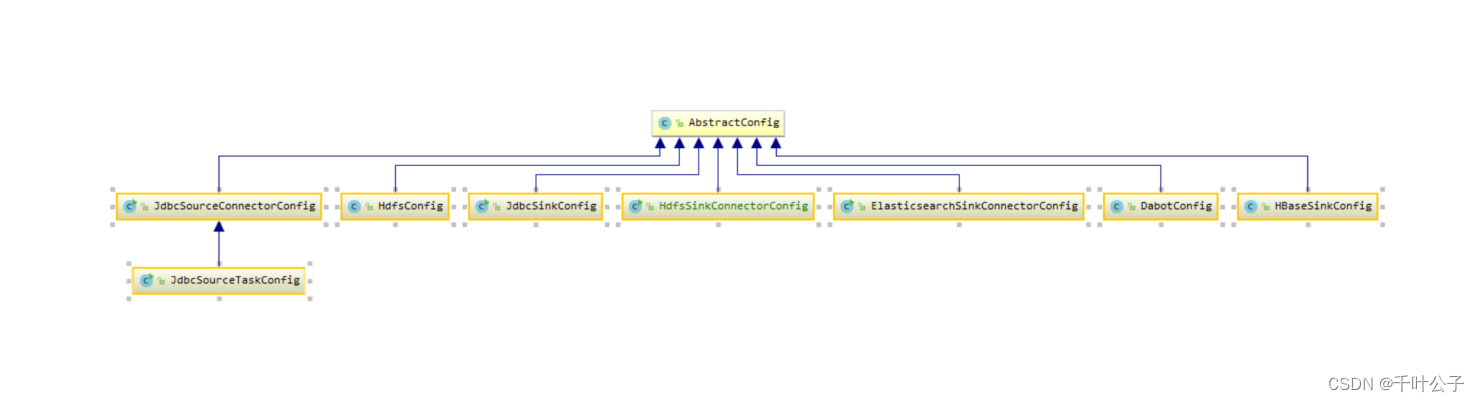
开发一个Connector,只需要实现三个接口或抽象类:Connector、Task、AbstractConfig。
- Connector: 通过管理任务协调数据流的高级抽象
- Task:具体实现如何将数据写入到Kafka或从Kafka读取数据
- AbstractConfig:创建一个Connector需要的配置参数
Connector的UML类图:
Task的UML类图:
AbstractConfigUML类图:
在HBaseSourceTask的poll()方法中,读取HBase中的数据并写入到Kafka; 在HBaseSinkTask的put(Collection records) 方法中,从Kafka中读取数据并写入到HBase中分别在 poll() 和 put(Collection records) 方法中实现具体的业务逻辑代码。
2.4、功能测试
Kafka-Rest,对外提供了Rest API的接口,满足Connector任务的管理,包括,创建、查看、删除等以数据采集为例,进行共享任务的测试:
# 从HBase中获取数据,写入到Kafka中
{ "name": "hbasesource_connector_001", "config": { "connector.class": "org.pkuse.source.connector.hbase.DabotSourceConnector", "pkuse.connector.name": "hbasesource_connector_001", "pkuse.kafka.topic.prefix": "", "pkuse.hbase.ip": "192.168.130.247,192.168.130.246,192.168.130.238", "pkuse.hbase.port": "2181", "pkuse.hbase.table.name": "test_employee01_2021_06_17", "pkuse.hbase.namespace": "default", "pkuse.kafka.batch.size": "200", "pkuse.hbase.filed.mapping":" [{\"sourceFiled\":\"id\",\"targetFiled\":\"id\", \"fieldType\":\"int\",\"mark\":\"0\",\"ispk\":\"1\",\"limitcondition\":\"\",\"ma prule\":\" \",\"columnId\":\"adb362c70ab54260a5ca8e3cd562a62c\",\"description\":\"主键\"}, {\"sourceFiled\":\"name\",\"targetFiled\":\"name\", \"fieldType\":\"string\",\"mark\":\"0\",\"ispk\":\"0\",\"limitcondition\":\"\",\ "maprule\":\" \",\"columnId\":\"fe9aa1f7828a428e926bb76a675f7d78\",\"description\":\"NAME\"}, {\"sourceFiled\":\"sex\",\"targetFiled\":\"sex\", \"fieldType\":\"string\",\"mark\":\"0\",\"ispk\":\"0\",\"limitcondition\":\"\",\ "maprule\":\" \",\"columnId\":\"fe9aa1f7828a428e926bb76a675f7d78\",\"description\":\"sex\"}, {\"sourceFiled\":\"salary\",\"targetFiled\":\"salary\", \"fieldType\":\"bigint\",\"mark\":\"0\",\"ispk\":\"0\",\"limitcondition\":\"\",\ "maprule\":\" \",\"columnId\":\"fe9aa1f7828a428e926bb76a675f7d78\",\"description\":\"salary\"} ]", "pkuse.isftpfile":"", "pkuse.daboturl":"192.168.1.176:8181", "pkuse.datasyntype":"1", "pkuse.incrementreadfields":"", "pkuse.lastincrementvalue":"", "pkuse.hbase.filed.columnsKey":"id", "pkuse.hasbigfield":"[]bdsoft", "org.pkuse.kafka.broker": "192.168.1.176:9092", "pkuse.task.id": "100003"} }
# 数据从kafka写入到mysql中
{ "name":"jdbcsink_connector_001", "config":{ "connector.class":"io.confluent.connect.jdbc.MyJdbcSinkConnector", "tasks.max":"1", "topics":"default_test_employee01_2021_06_17", "connection.url":"jdbc:mysql://192.168.130.247:3306/test03? autoReconnect=true&useUnicode=true&characterEncoding=utf-8&useSSL=false", "connection.user":"root", "connection.password":"root", "table.name.format":"test03.employee01_2021_06_17", "auto.create":"true", "pk.fields":"id", "pk.mode":"record_value", "insert.mode":"upsert", "write.mode":"1", "batch.size":"3000", "org.pkuse.kafka.broker":"192.168.1.176:9092", "pkuse.task.id":"100003" } }
3、不同版本的confluent服务
confluent是对应后端数据传输的服务,针对不同业务场景可选择不同的数据源,同时基于不同的业务需求,可以进行相应的代码实现。
对于confluent服务支撑的采集共享功能,mz和zh项目不同的版本为例,从项目工程结构、功能点支撑、部署启动方式三个部分进行对比。
3.1、confluent的使用
mz系统架构图
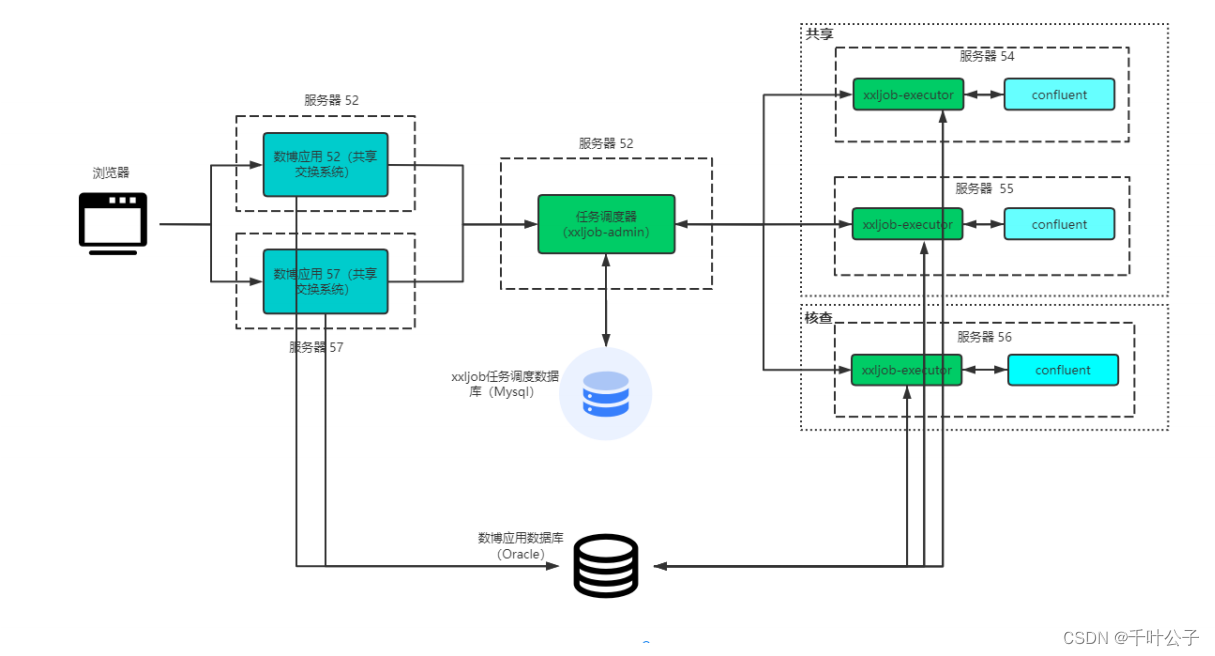
后台共享交换任务的调度涉及定时任务调度器(xxl-job)和数据传输服务(confluent)两部分。调度中心(xxl-job)通过定时触发形式,将定时任务发送给具体的执行器执行,执行器通过Http请求Confluent提供的RestAPI接口,完成整个共享交换任务的执行。
zh系统架构图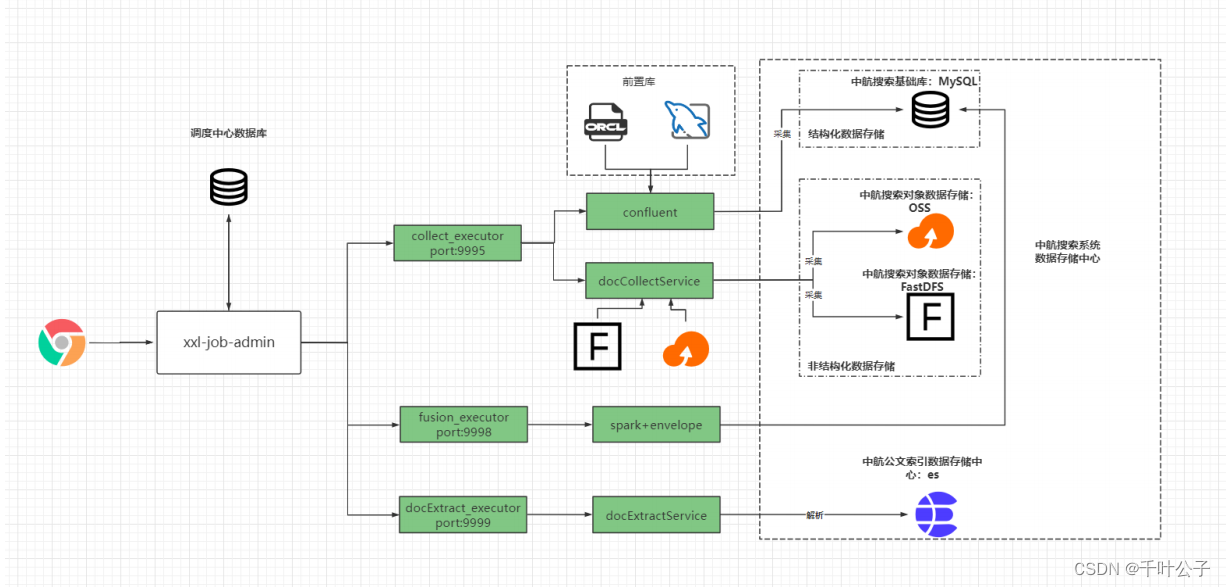
后台数据传输的调度涉及定时任务调度执行器(xxl-job)和数据传输服务(confluent)两部分。
















 3127
3127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









