







此博客的很多内容均来自 博客园 Alexander 博主的文章,我只做了整理方便今后自己回顾,同时很感谢博主的分享
2017年11月27日
NSGA :Non-Dominated Sorting Genetic Algorithm,非支配排序遗传算法
NSGA和NSGA-ll都是基于遗传算法的多目标优化算法,都是基于Pareto(帕累托)最优解讨论的多目标优化
Pareto支配关系
对于最小化多目标问题,n个目标分量
fi
(i=1,…,n)组成的向量
f¯(X¯)=(f1(X¯),f2(X¯),...,fn(X¯))
,任意给定两个决策变量
X¯u,X¯v∈U
:
当且仅当,对于
∀i∈{1,...,n}
,都有
fi(X¯u)<fi(X¯v)
,则称
X¯u
支配
X¯v
。
当且仅当,对于
∀i∈{1,...,n}
,都有
fi(X¯u)≤fi(X¯v)
,且至少存在一个
j∈{1,...,n}
使得
fj(X¯u)<fj(X¯v)
则称
X¯u
弱支配
X¯v
。
当且仅当,
∃i∈{1,...n}
,使得
fi(X¯u)<fi(X¯v)
,且
∃j∈{1,...n}
,使得
fj(X¯u)>fj(X¯v)
,则称
X¯u
与
X¯v
互不支配。
简单来说,就是 若方案A在所有的目标上都优于方案B,则称方案A支配方案B。
例 同样举0/1背包问题作例子。
由于是多目标问题,所以得对最简单的背包问题做修改,改为:
现有一个最大承受体积为Volume的背包,以及N个物品,每个物品的重量为Wi,价值为Vi,体积为Ti,求给出一个方案,使得在背包的承受体积范围内,背包内物品的总价值最大,且总质量最小。
若方案A使得背包内物品的总价值为40,总重量为50;方案B使得背包内物品的总价值为30,总重量为60。因为方案A在两个目标上(价值大,重量小)都优于方案B,所以方案A支配方案B;若方案B的总重量为50,则方案A弱支配方案B;若方案B的总价值为50,则方案A和方案B互不支配。
Pareto最优解定义
多目标优化问题与单目标优化问题有很大差异。当只有一个目标函数时,人们寻找最好的解,这个解优于其他所有解,通常是全局最大或最小,即全局最优解。而当存在多个目标时,由于目标之间存在冲突无法比较,所以很难找到一个解使得所有的目标函数同时最优,也就是说,一个解可能对于某个目标函数是最好的,但对于其他的目标函数却不是最好的,甚至是最差的。因此,对于多目标优化问题,通常存在一个解集,这些解之间就全体目标函数而言是无法比较优劣的,其特点是:无法在改进任何目标函数的同时不削弱至少一个其他目标函数。这种解称作非支配解(non-dominated solutions)或Pareto最优解(Pareto optimal Solutions),定义如下:
对于最小化多目标问题,n个目标分量
fi
(i=1,…,n)组成的向量
f¯(X¯)=(f1(X¯),f2(X¯),...,fn(X¯))
,
X¯u∈U
为决策变量,若
X¯u
为Perato最优解,则需满足:
当且仅当,不存在决策变量
X¯v∈U,v=f(X¯v)=(v1,...,vn)
支配
u=f(X¯u)=(u1,...,un)
即不存在
X¯v∈U
使得下式成立:
(∀v∈{1,...,n},vi≤ui)∧(∃i∈{1,...,n},vi<ui)
简单来说,就是Pareto最优解 X¯u 不被任何其他决策变量所支配。
NSGA的一般流程
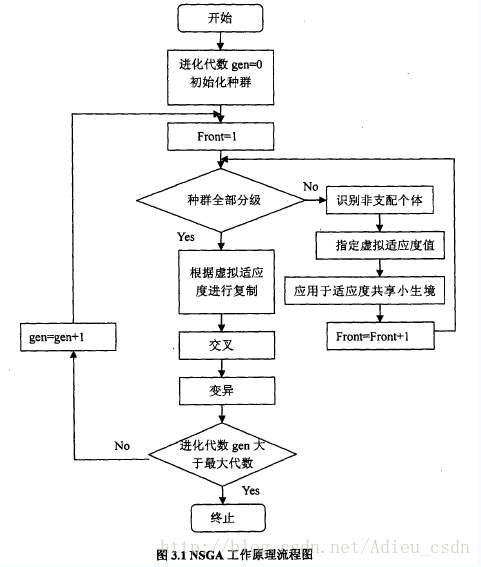
NSGA使用了非支配分层方法和适应度共享策略。非支配分层方法可以使好的个体有更大的机会遗传到下一代;适应度共享策略则使得准Pareto面上的个体均匀分布,保持了群体多样性,克服了超级个体的过度繁殖,防止了早熟收敛。
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
非支配分层
非支配排序算法
考虑一个目标函数个数为K(K>1)、规模大小为N的种群,通过非支配排序算法可以对该种群进行分层,具体的步骤如下:
1. 设j=1;
2. 对于所有的
g=1,2,...,N
且
g≠j
,基于适应度函数比较个体
Xg
和个体
Xj
之间的支配和非支配关系;
3. 如果不存在任何一个个体
Xg
优于
Xj
,则标记
Xj
为非支配个体;
4. 令j=j+1,转到步骤2,直到找到所有的非支配个体。
通过上述步骤得到的非支配个体集是种群的第一级非支配层;然后,忽略这些标记的非支配个体,再遵循步骤1-4,就会得到第二级非支配;依此类推,直到整个种群被分层。
虚拟适应度值的确定
在对种群进行非支配排序的过程中,需要给每一个非支配层指定一个虚拟适应度值。级数越大,虚拟适应度值越小;反之,级数越小,虚拟适应度值越大。这样可以保证在选择操作中等级较低的非支配个体有更多的机会被选择进入下一代,使得算法以最快的速度收敛于最优区域。另一方面,为了得到分布均匀的Pareto最优解集,就要保证当前非支配层上的个体具有多样性。NSGA中引入了基于拥挤策略的小生境(Niche)技术,即通过适应度共享函数的方法对原先指定的虚拟适应度值进行重新指定。
计算步骤
假设m非支配层上
nm
个个体,每个个体的虚拟适应度值
fm
,且令
i,j=1,2,...,nm
,则具体的实现步骤如下:
1. 计算出同属于一个非支配层的个体i和个体j的欧几里得距离:
其中,L为问题空间的变量个数, xal 和 xdl 为 xl 的上界和下界。
2. 共享函数s表示个体 xi 和小生境群体中其他个体的关系:
其中, σshare 为共享半径, α 为常数。
这里补充一下共享函数的概念和意义:
共享函数(Sharing Function)是表示群体中两个个体之间密切关系程度的一个函数,可记为s(d(i,j)),表示个体i和j之间的关系。例如,个体基因型之间的海明距离就可以为一种共享函数。这里,个体之间的密切程度主要体现为个体基因型的相似性或个体表现型的相似性上。当个体之间比较相似时,其共享函数值就比较大;反之,当个体之间不太相似时,其共享函数值比较小。
3.
j=j+1
,如果
j≤nm
转到步骤1,否则计算出个体
xi
的小生境数量为:
4. 计算出个体 xi 的共享适应度值:
反复执行以上的四步可以得到每一个个体的共享适应度值。
之后的交叉、变异等操作就跟SGA(简单遗传算法)没什么不同了。
参考资料
1. 博客园博主Alexander的博客(从NSGA到NSGA-ll),链接如下: https://www.cnblogs.com/bnuvincent/p/5268786.html
2. 遗传算法小生境技术的简介,博主博客:
http://www.blogjava.net/weidagang2046/articles/84798.html#Post

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









