






MySQL原理、性能等方面笔记
锁
MySQL官方文档对于锁描述的很清楚,我在这里只补充一些当时有些疑惑或者其他地方补充的知识点或者之类的。
MySQL官方文档:锁
锁的结构

当事务想要加锁时,先生成一个锁结构,如果能够成功获取到锁,那么is_waiting就是false。
当前读与锁
我们知道,当前读会有脏读的问题,即在一个事务运行期间,两次读取可能得到不一样的数据。在innodb中采用了MVCC的方式解决,但是,在某些特殊场景,比如银行,在用户进行存款时需要读取到实时数据,且读取后就不该允许其他事务进行写入了,否则可能导致余额最终结果不符合一致性要求。那么MVCC就无法满足要求了。
因为MVCC采用读视图,属于快照读(一致性读),而快照读无法读取到正在运行中的事务修改的数据。
那么此时,就需要指定用当前读的方式读取数据,为了解决脏读,就需要采用加锁的方式了。加了锁,就可以禁止其他事务写入,也就解决了脏读。
共享锁(S锁)与独占锁(X锁)
实际上就是读写锁
读锁:select ... lock in share mode;
写锁:select ... for update;
表锁
意向锁
-
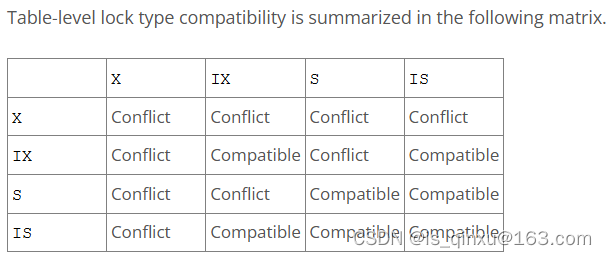
意向锁是表级锁,指示事务稍后需要对表中的行使用哪种类型的锁(共享锁或排他锁)
-
意向锁不会阻塞除全表请求(例如LOCK TABLES … WRITE)之外的任何内容(如下图兼容关系)。意向锁的主要目的是表明某人正在锁定表中的某一行,或者将要锁定表中的某一行。
-
行锁
行锁实际是索引记录锁,即加在索引上而不是加在记录上,同样的,所谓next-key等锁实际对象都是索引。
record-lock
记录锁始终锁定索引记录,即使表未定义索引也是如此。对于此类情况, InnoDB请创建一个隐藏的聚簇索引并使用此索引进行记录锁定
Gap-lock
对于使用唯一索引锁定行以搜索唯一行的语句,不需要间隙锁定。这是因为唯一索引能够直接定位到具体的行,从而避免了锁定范围中的其他行或间隙。然而,有一种情况例外,即当搜索条件仅包含多列唯一索引的某些列时,间隙锁定会发生。
插入意向锁
(注意不是表锁里的意向锁)
这是一种在行插入之前设置的间隙锁
在MySQL官方文档中,有这么一段话,当时不是很理解

这里做出解释:
具体来说,插入意向锁就是一种解决在多事务环境下处理插入操作而避免阻塞的机制。只要不在同一个位置(即同一条索引)插入,那么就不阻塞其它事务获取插入意向锁和独占锁
-
插入意向锁的定义:插入意向锁是一种特殊的间隙锁,在事务尝试在某个位置插入行之前设置。这种锁发出一个信号,表明该事务有插入数据的意图,但并不阻止其他事务在不同位置进行插入操作。
-
多事务插入示例:
- 假设有一个索引记录,其中已经存在的值为 4 和 7。
- 有两个独立的事务:事务 A 试图插入值 5,事务 B 试图插入值 6。
-
插入意向锁的作用:
- 事务 A 在尝试插入值 5 之前,会在 4 和 7 之间的间隙设置插入意向锁。
- 事务 B 在尝试插入值 6 之前,也会在 4 和 7 之间的间隙设置插入意向锁。
- 因为 5 和 6 是不同的位置,这两个插入意向锁不会相互阻塞。也就是说,事务 A 和事务 B 都可以获得插入意向锁,而无需等待对方完成。
-
独占锁的获取:
- 当插入操作实际进行时,每个事务会尝试获得插入位置的独占锁(Exclusive Lock)。
- 因为插入的具体位置不同(5 和 6),这些独占锁也不会相互冲突。
关键点总结:
- 插入意向锁不会相互阻塞:即使多个事务在同一个间隙内插入数据,因为插入位置不同,插入意向锁不会导致阻塞。
- 独占锁不会相互阻塞:由于插入的具体位置(值 5 和值 6)不同,这些独占锁不会发生冲突,因此也不会阻塞。
- 所以
这句话的意思是说获取插入意向锁不会阻塞。这是因为插入意向锁的设计就是为了允许多个事务在不同位置进行插入操作而不需要相互等待。具体来说,多个事务在同一个索引间隙内插入数据时,只要插入位置不同,插入意向锁和随后的独占锁都不会相互阻塞。
各个语句如何设置锁
MySQL官网写了,直接看官网
索引
很多建表规范中说,要求建表都建议一定要有自增主键索引,那么真的一定要这样吗
- 首先介绍不过不使用自增主键会怎么样
当前索引页有记录10以及后面的一大堆记录,此时来了个记录是9,那么后面所有的记录都要往后移动空出位置给记录9。而如果此时正好9就是压死骆驼的最后一根稻草,当前页面满了,那B+树就得多开一个索引页,把部分数据移到新的索引页中(这种情况叫做页分裂)。并且由于数据并不是紧凑的放在一个数据页中,查询性能也降低了。 - 那么自增主键索引有什么好处?
- 从性能上看,每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
- 从存储的角度看,如果使用业务字段作为主键索引,可能会导致主键过大,而二级索引的叶子结点存的是主键值,所以建议使用自增主键,能够比业务字段有效节省空间
- 那么有没有场景不需要自增主键哩,即有没有场景适合业务字段作主键?
- 只有一个索引的时候。
- 为什么呢?因为只有一个索引,那么MySQL会自动给一个隐藏的主键创建主键索引,你不拿业务字段作主键索引你就需要回表,这个就很没必要了。
联合索引应该如何安排索引内的字段顺序
- 评估标准:索引的复用能力
- 原则就是如果通过调整顺序可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的
- 如:(a,b)如果已经有该索引,那么就不需要再单独维护a字段索引了。因为联合索引有最左匹配原则。
- 而如果既有联合查询又有关于a、b的单字段查询呢?
- 从空间上考量:
比如a字段比b字段大,此时就应该选择b单独建索引,在联合索引中把a字段放在前面。这样在查询a时使用联合索引,单字段查询b时使用b的单字段索引。
- 从空间上考量:
索引下推
用于联合索引。
如查询条件:比如a>1 and b=2,其中(a,b)是联合索引。
只用到单个字段的时候,如果没有索引下推,会导致MySQL在找到每一个a>1的记录时都会进行一次回表。
而在MySQL5.6出现索引下推机制后,因为a是范围查询,所以b用不到联合查询索引,innodb直接就在索引中判断剩下的字段是否符合b=2,不会返回server再去主键索引中判断。
所以,使用了索引下推后,虽然 b 列无法使用到联合索引,但是因为它包含在联合索引(a,b)里,所以直接在存储引擎过滤出满足 b=2 的记录后,才去执行回表操作获取整个记录。相比于没有使用索引下推,节省了很多回表操作。
删主键?
无论删除主键还是创建主键都会对整个表进行重建,所有的二级索引都依赖于主键
MySQL连接
长连接的问题
- MySQL中,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。而建立连接开销大,所以要尽量使用长连接。
- 但是全部使用长连接后,你可能会发现,有些时候MySQL占用内存涨得特别快,这是因为MySQL在执行过程中临时使用的内存是管理在连接对象里面的(类似于QT中的new了对象就把对象挂在对象树中)。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是MySQL异常重启了。
- 怎么解决这个问题呢?你可以考虑以下两种方案。
- 定期断开长连接。使用一段时间,或者程序里面判断执行过一个
占用内存的大查询后,断开连接,之后要查询再重连。 - 如果你用的是MySQL 5.7或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
SQL语句使用笔记
关键字
distinct
对于单字段查询,distinct对单字段进行去重
select distinct name from stu;
对于多字段,distinct对多字段组合结果进行去重,即所有字段相同才被认为是重复的
select distinct name,id from stu;
select distinct (name),id from stu;# 尽管这样写,也是当name和id有关记录都相同时才被认为是重复记录
另外,distinct只能放在第一个查询字段前,否则会报错。因为多字段去重,是所有字段都相同才被认为重复
group by
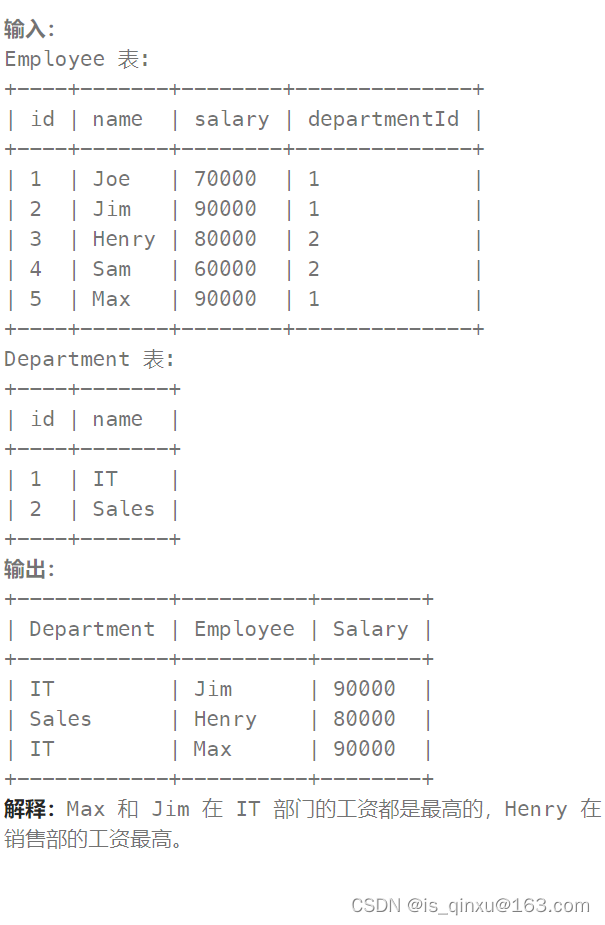
查找出每个部门中薪资最高的员工。按 任意顺序 返回结果表。
这里注意的是,第一个select中的where字句,使用括号:(departmentId,Employee.salary)可以把两个字段作为一个组合成为筛选条件
# 子查询
select Department.name as Department, Employee.name as Employee, Employee.salary as Salary
from Employee,Department where (departmentId,Employee.salary)
#(departmentId和salary作为一个条件)
in (select departmentId, max(Salary) from Employee group by departmentId)
and Employee.departmentId=Department.id;
# 左外连接 子查询
-- select Department.name as Department,Employee.name as Employee,Salary
-- from Employee
-- left join Department on Employee.DepartmentId = Department.Id
-- where (departmentId, Salary) in
-- (select departmentId, max(Salary) from Employee group by DepartmentId);
函数
聚合函数
avg
avg的参数如果是bool值时,则得到的结果就会转换为0,1。那么可以通过avg函数求概率,1或者0的数量就是所需查找的列的概率。
avg(Status!='completed')
当status不为completed时,为true,则为1。那么1的数量除以总的数据数量就是status不为complete的概率
日期函数
adddate
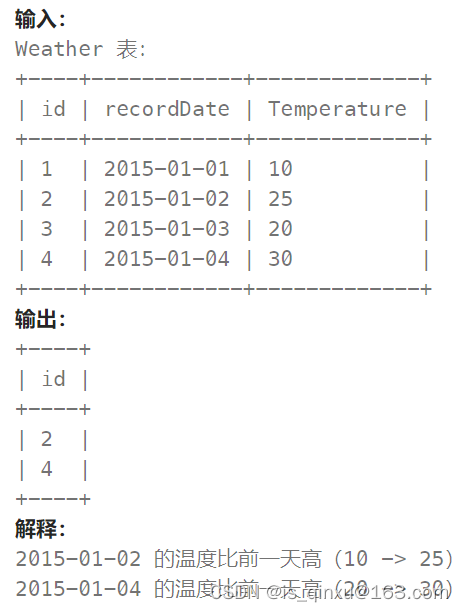
编写解决方案,找出与之前(昨天的)日期相比温度更高的所有日期的 id 。
这里主要注意日期函数的用法
SELECT b.Id
FROM Weather as a,Weather as b
WHERE a.Temperature < b.Temperature and DATEDIFF(a.RecordDate,b.RecordDate) = -1;
-- SELECT w2.id
-- FROM Weather w1, Weather w2
-- WHERE w2.recordDate = ADDDATE( w1.recordDate, INTERVAL 1 DAY )
-- AND w2.temperature > w1.temperature
#adddate用法可以看看这篇文章https://www.cnblogs.com/jpfss/p/11131540.html
注意事项
- MySQL不允许在DELETE语句的WHERE子句中直接使用正在被更新的表。
力扣196. 删除重复的电子邮箱
# 子查询
delete from Person where id not in (
select a.id from (# 不能只使用下面的那个select
select min(id) as id from Person group by email
) as a
)
或者使用自连接的方式
# 自连接
DELETE p1
FROM Person p1 JOIN Person p2
ON
p1.Email = p2.Email
AND
p1.Id > p2.Id
-
JOIN
如果有多个JOIN,后面的JOIN依赖于前面的JOIN结果集进行筛选 -
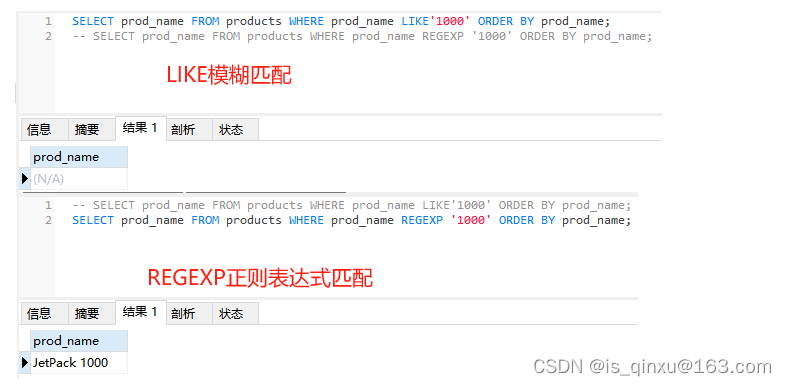
LIKE 和 REGEXP的区别
LIKE指定后面跟的表达式是通配符匹配,而不是直接相等匹配,就算记录中存在于LIKE后面的表达式完全相等的列,也不会返回任何东西。如
products表

查询:
-
where 和 having的区别
where作用于一行记录,作用于group by之前,筛选出符合条件的记录。
而having作用于group by之后,作用于分组后的结果,筛选出符合条件的组
参考资料
- 《高性能MySQL》
- 《极客时间:MySQL实战45讲》
- 《MySQL是怎样运行的-从根上理解MySQL》















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









