







目录
冒泡排序
- 特点:运行非常慢,但它的概念是最简单的。
- 基本流程:每一轮从头开始两两比较,将较大的项放在较小项的右边,这样每轮下来保证该轮最大的数在最右边。
- 算法实现:(交换出最大,放在后面)
private static void bubbleSort(int[] data) {
System.out.println(Arrays.toString(data));
boolean exchange;
for (int i = 0; i < data.length - 1; i++) {
exchange = false;
for (int j = 0; j < data.length - 1 - i; j++) {
if (data[j] > data[j + 1]) {
swap(data, j, j + 1);
exchange = true;
}
}
if(!exchange) break;
}
System.out.println(Arrays.toString(data));
}- 算法分析:
- 时间复杂度:最好的情况是初始状态是正序的,一次扫描即可完成排序,时间复杂度为 O(N);最坏的情况是反序的,此时最坏的时间复杂度为 O(N^2);平均情况,每轮 N/2 次循环,N 轮时间复杂度为 O(N^2)。
- 空间复杂度:空间复杂度为 O(1),不需要额外空间。
- 算法稳定性:算法是稳定的,因为当 a=b 时,由于只有大于才做交换,故 a 和 b 的位置没有机会交换,所以算法稳定。
选择排序
- 特点:改进了冒泡排序,将必要的交换次数从 O(n^2) 减少到 O(n),但是比较次数仍保持为 O(n^2)。
- 基本流程:将一轮比较完后,把最小的放到最前的位置(或者把最大的放到最后)。
- 算法实现:(比较出最小,放在前面)
private static void selectSort(int[] data) {
System.out.println(Arrays.toString(data));
int minPosition; // 把最小的放到最前的位置
for (int i = 0; i < data.length - 1; i++) {
minPosition = i;
for (int j = i + 1; j < data.length; j++) {
if (data[j] < data[minPosition])
minPosition = j;
}
if (minPosition > i) // 加一个判断
swap(data, i, minPosition);
}
System.out.println(Arrays.toString(data));
}- 算法分析:
- 时间复杂度:最好和最坏的情况一样运行了 O(N^2) 时间,但是选择排序比冒泡更快,因为它进行的交换少得多,当 N 值较小时,特别是如果交换时间比比较时间大得多时,选择排序实际上是相当快的。平均复杂度也是 O(N^2)。
- 空间复杂度:空间复杂度为 O(1),不需要额外空间。
- 算法稳定性:算法是不稳定的,假设 a=b,且 a 在 b 前面,而某轮循环中最小值在 b 后面,而次最小值需要跟 a 交换,这时候 b 就在 a 前面了,所以选择排序是不稳定的。
插入排序
- 特点:改进了冒泡排序,将必要的交换次数从 O(n^2) 减少到 O(n),但是比较次数仍保持为 O(n^2)。
- 基本流程:(从后向前,插入位置)
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素小于前一个元素,则将两者调换,再与前一个元素比较
- 重复第三步,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置中
- 重复第二步
- 算法实现:
private static void insertSort(int[] data){
System.out.println(Arrays.toString(data));
for(int i = 1; i < data.length; i++) {
for(int j = i; (j > 0) && (data[j] < data[j-1]); j--) {
swap(data,j, j-1);
}
}
System.out.println(Arrays.toString(data));
}- 算法分析:
- 时间复杂度:插入排序最好的情况是序列已经是升序排列了,在这种情况下,需要进行 N-1 次比较即可,时间复杂度为 O(N),最坏的情况是序列降序排列,这时候时间复杂度为 O(N^2)。插入排序平均时间复杂度为 O(N^2)。
- 空间复杂度:空间复杂度为 O(1),不需要额外空间。
- 算法稳定性:算法是稳定的,假设 a=b,且 a 在 b 的前面,其排序位置必然比 b 先确定,而后面再插入 b 时,必然在 a 的后面,所以是稳定的。
快速排序
- 特点:分治思想,即分治法。
- 基本流程:首先从数列的右边开始往左边找,我们设这个下标为 end,也就是进行减减操作(end--),找到第 1 个比基准数小的值,让它与基准值交换;接着从左边开始往右边找,设这个下标为 start,然后执行加加操作(start++),找到第 1 个比基准数大的值,让它与基准值交换;然后继续寻找,直到 start 与 start 相遇时结束,最后基准值所在的位置即 key 的位置,也就是说 key 左边的值均比 key 上的值小,而 key 右边的值都比 key 上的值大。
- 算法实现:(左小右大)
public class QuickSortTest {
@Test
public void test() {
int[] data = {12, 20, 5, 16, 15, 1, 30, 45, 23, 9};
System.out.println(Arrays.toString(data));
QuickSort.quickSort(data, 0, data.length - 1);
System.out.println(Arrays.toString(data));
}
}
// [12, 20, 5, 16, 15, 1, 30, 45, 23, 9]
// [1, 5, 9, 12, 15, 16, 20, 23, 30, 45]
public class QuickSort {
public static void quickSort(int[] data, int low, int high) {
int start = low;
int end = high;
int key = data[low];
while (end > start) {
//从后往前比较
while (end > start && data[end] >= key) //如果没有比关键值小的,比较下一个,直到有比关键值小的交换位置,然后又从前往后比较
end--;
if (data[end] <= key) {
int temp = data[end];
data[end] = data[start];
data[start] = temp;
}
//从前往后比较
while (end > start && data[start] <= key)//如果没有比关键值大的,比较下一个,直到有比关键值大的交换位置
start++;
if (data[start] >= key) {
int temp = data[start];
data[start] = data[end];
data[end] = temp;
}
//此时第一次循环比较结束,关键值的位置已经确定了。左边的值都比关键值小,右边的值都比关键值大,但是两边的顺序还有可能是不一样的,进行下面的递归调用
}
//递归
if (start > low) quickSort(data, low, start - 1);//左边序列。第一个索引位置到关键值索引-1
if (end < high) quickSort(data, end + 1, high);//右边序列。从关键值索引+1到最后一个
}
}
- 算法分析:
- 时间复杂度:对冒泡排序的改进。最佳情况:T(n) = O(nlogn);最差情况:T(n) = O(n2);平均情况:T(n) = O(nlogn)。
- 空间复杂度:空间复杂度为 O(logn)。
- 算法稳定性:算法是不稳定的,在经过排序之后,可能会对相同值的元素的相对位置造成改变。

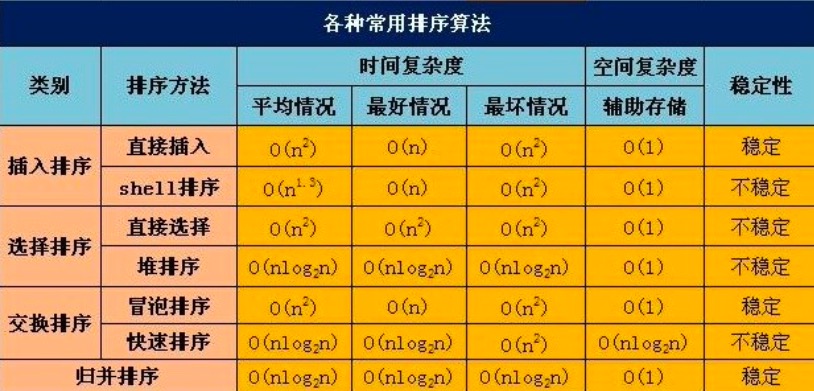
算法比较
后记
后记1:希尔排序(改进插入排序)、归并排序(额外空间)、堆排序(堆数据结构)、计数排序、桶排序、基数排序。
后记2:JDK的提供的Arrays.sort()方式使用的插入排序和快速排序。
后记3:测试数据
public static void main(String[] args) {
bubbleSort(new int[]{9, 0, 5, 1, 2, 8, 4});
}后记4:交换的逻辑(可参考我的这篇文章——三种方式交换两个数字的值)
private static void swap(int[] data, int a, int b) {
data[a] = data[a] ^ data[b];
data[b] = data[a] ^ data[b];
data[a] = data[a] ^ data[b];
}














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









