






结合数据结构系统细节Java集合框架——上
常见集合框架图
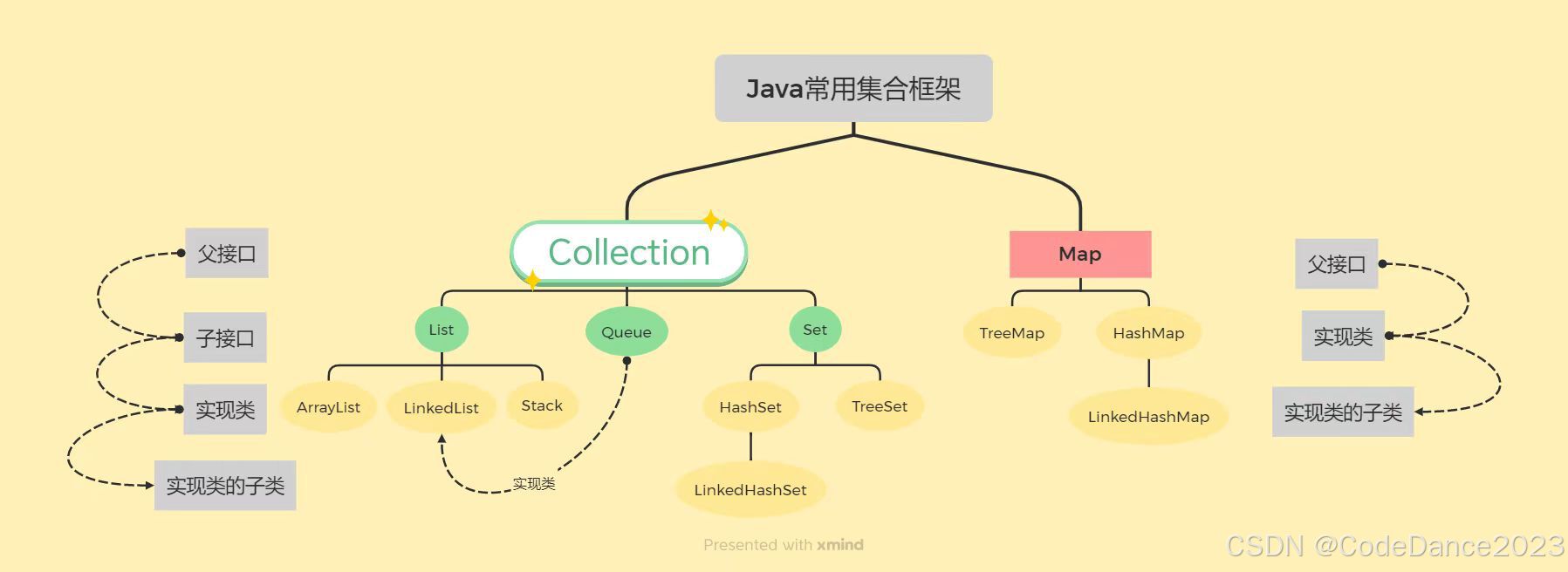
-
观察上图,我们可以清楚地发现Java中的集合框架大体分成Collection(单列集合)和Map(双列集合)两类,它们是顶层的父接口。
-
对于Collection集合,下面常见的分成三个子接口:List、Queue、Set。这三个是Collection的子接口,还不能被实例化
-
List的实现类常见的有:ArrayList、LinkedList、Stack,这三个可以是普通的类,因此可以被实例化。
-
Queue的实现类常见的有:LinkedList, 利用了其对于数据增删操作比较快的特征
-
Set的实现类常见的有:HashSet、LinkedHashSet(HashSet的子类)、TreeSet
-
本期主要介绍Collection集合
Collection集合框架图
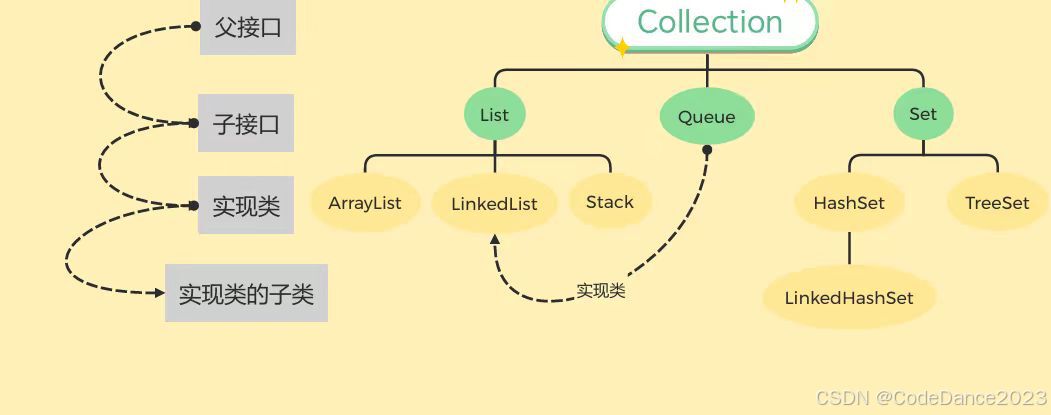
Collection集合的特点
-
Collection被称为单列集合,顾名思义,就是集合里面每一个空间储存的数据是单一的一个值。
-
List类集合的特点
-
有序性:这里的有序指的是添加数据时的顺序和获取数据时的顺序是一致的,而不是指的是从小到大的那种排序
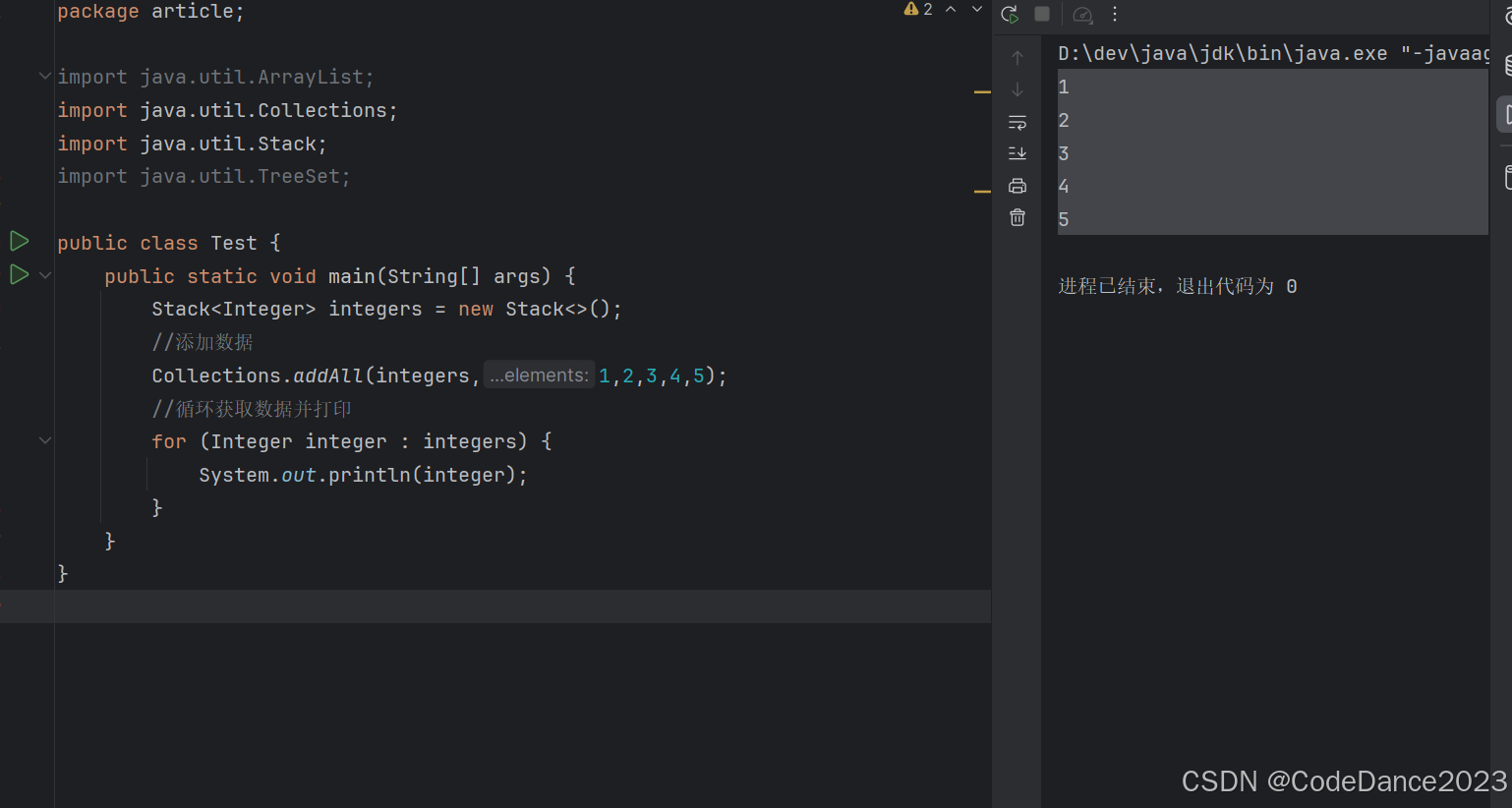
通过上图可以发现,利用Stack集合添加数据时的顺序是1,2,3,4,5,获取并打印时也是1,2,3,4,5
-
可重复性:List类的集合里面可以存储多个值相同的数据
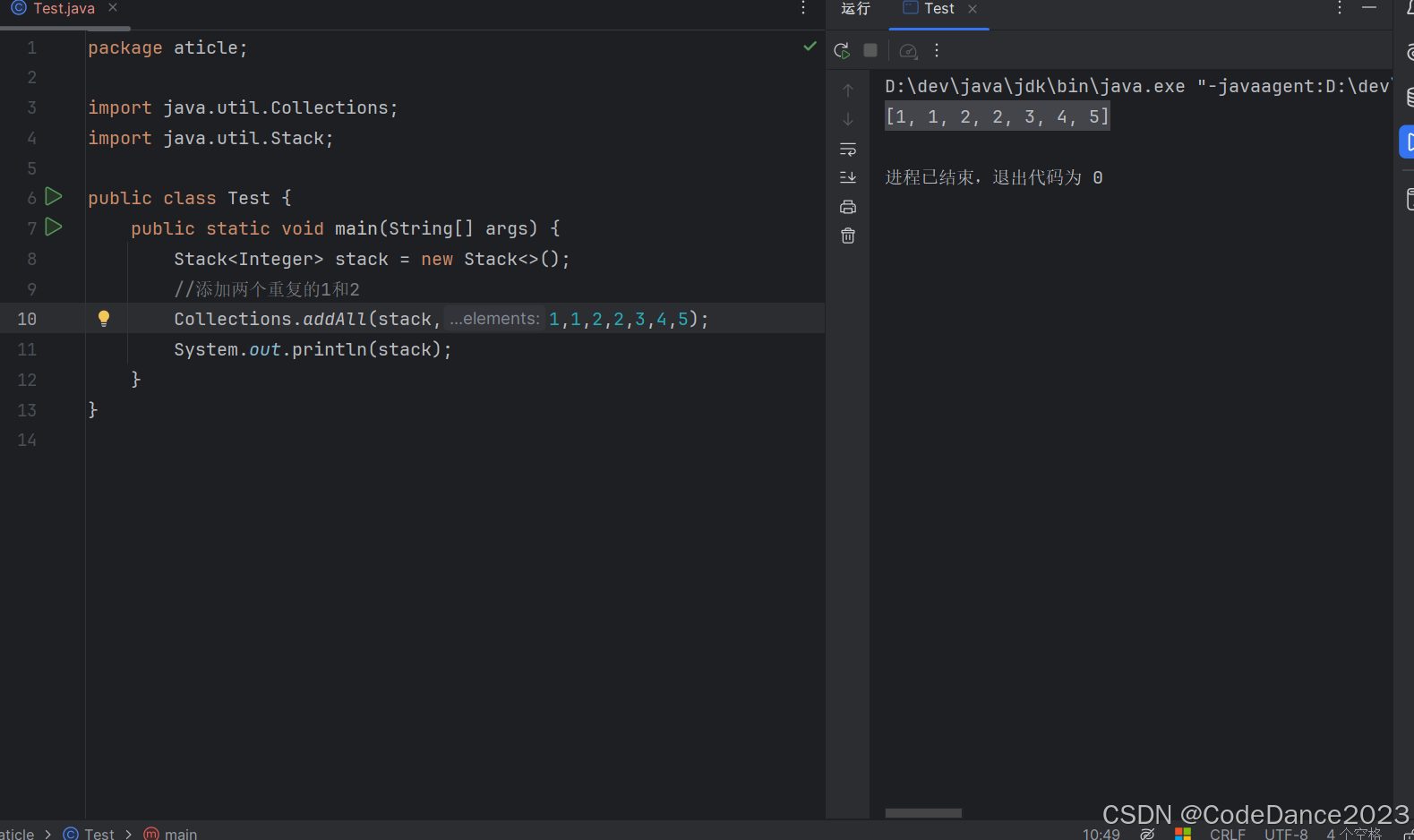
观察上图,我们添加了两个重复的1和2,打印发现集合里面会存储两个1和2。这说明List集合具有重复性
-
元素具有索引: List集合就像一个序列一样,里面的元素都提供索引方法,最先添加进集合的元素索引为0,以此类推依次增加
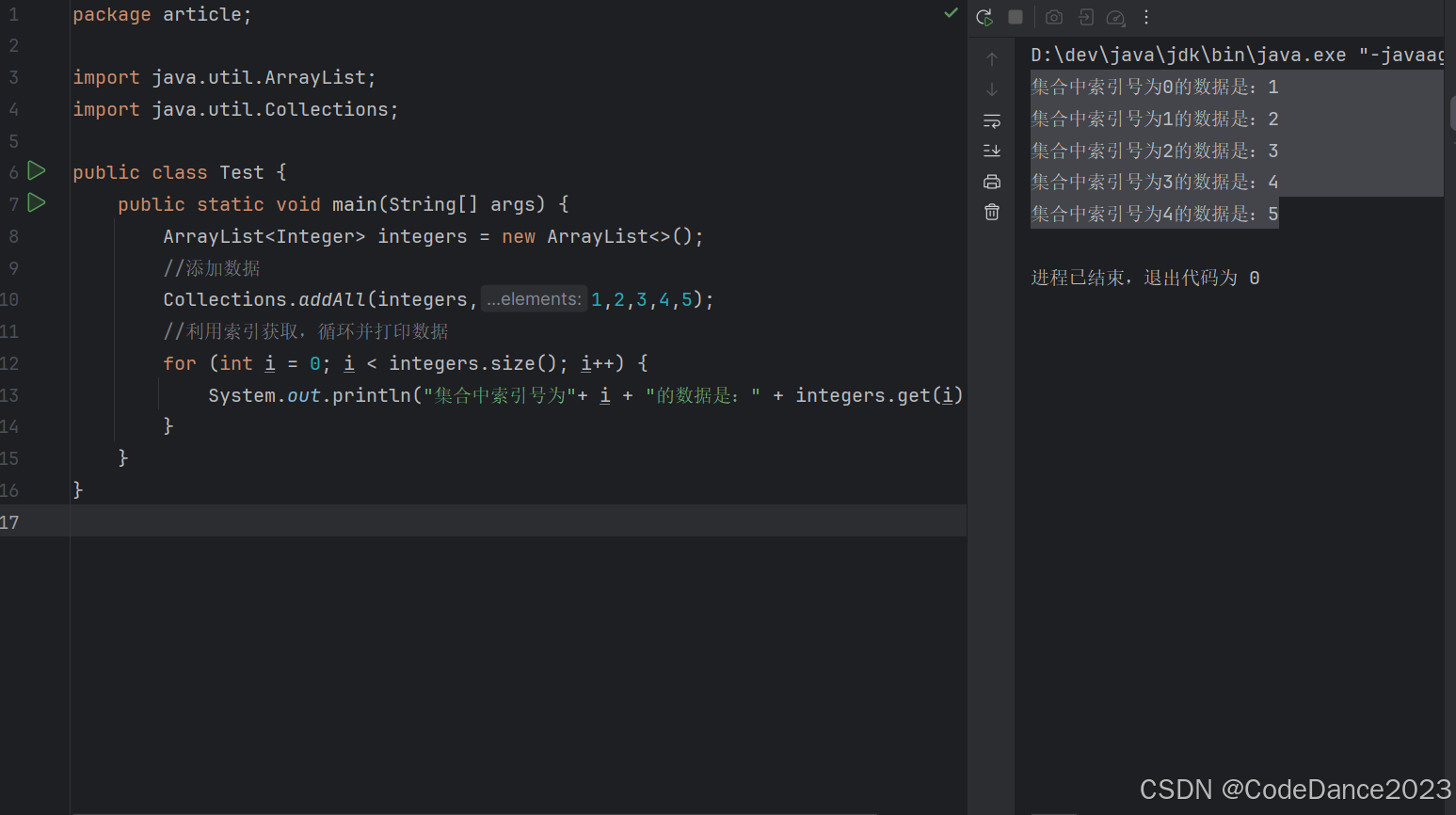
-
通过上图,我们可以发现,集合中的每一个数据都是具有索引,并且第一个添加进集合的数据的索引就是0, 但是与数组通过索引获取数据的方法不同,集合必须通过特定的方法才可以获取(这里是get(int index))方 法,而不是integers[ i ], 这种方式是错误的!
-
Queue集合的特点
Queue集合这里只介绍了一个实现类LinkedList,而它是List的实现类,因此也具有List的特点,这里就不在赘述了
-
Set集合的特点
- 是否具有有序性
- HashSet:无序
- LinkedHashSet:有序
- TreeSet: 无序
- 不重复性:Set集合里面是不允许添加重复的数据的
- 无索引性:Set集合不提供索引的方法,因此不能够通过索引来获取到数据
- 是否具有有序性
Collection集合的底层数据结构
-
List
-
ArrayList: ArrayList的底层数据结构是数组。首次创建ArrayList的对象,会生成一个长度为0的数组。当添加第一个元素时,会创建一个新的数组,长度为10。当数组装满时,会自动扩容为原来长度的1.5倍率。如果依次添加多个元素,大于扩容的1.5倍率,就会以实际的长度为准。因为数组这种数据结构是从索引0开始存储并且以此类推索引依次增加,通过索引天然地保存了添加时候数据的顺序,因此Java将ArrayList设计为有序集合。数组可以存储重复的元素,因此ArrayList也可以,因此具有可重复性。因为数组具有索引,因此ArrayList也具有索引。
-
LinkedList: LinkedList的底层数据结构是双向链表
-
链表:是一种通过连接数据在内存的地址而形成的一种数据结构,它和数组最大的的区别就是:数组是内存中的一片连续的内存空间,而链表因为可以地址找到这个数据,因此它不需要开辟一块连续的内存空间。每一个节点都会存储自己的值和后一个元素的地址。
-
双向链表:普通的链表,也成为**”单向链表“**,每一个节点存储值和后一个节点的地址,然而双向链表每一个节点还会存储前一个节点地址,形成两个方向都可以连接起来的链表。
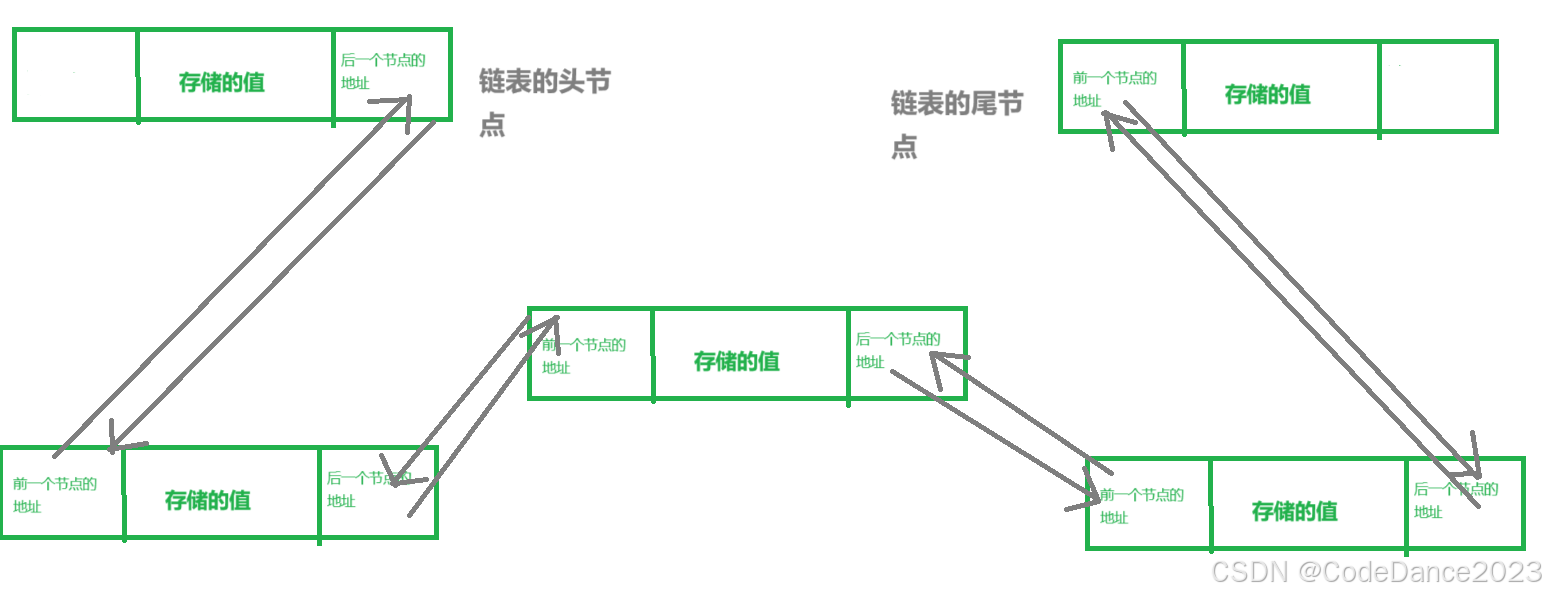
-
了解到LinkedList底层数据结构后,我们就可以理解其有序性,因为链表是从头节点开始添加,后面的每一个节点都通过地址记录了下一个元素的位置,所以天然地保存了添加数据时候的顺序,因此Java将其设计为有序集合。因为链表元素具有可重复性,因此LinkedList集合元素也具有可重复性。LinkedList的每一个元素具有索引(利用这个索引获取数据,要先判断离头节点近还是尾节点进再从头节点或者尾节点开始依次寻找该索引所要的数据,因此可以说是一个”假索引“,只是Java提供的索引方法,其查找元素的效率远低于ArrayList的数组的索引)。
-
-
Stack: Stack的底层数据结构是我们熟悉的栈,栈是一个一端开口,一端封闭的数据结构,具有先进后出,后进先出的特点。只能从栈顶进栈,从栈顶出栈。但是在Java中Stack类中的栈是用数组来实现的(父类是Vector)
-
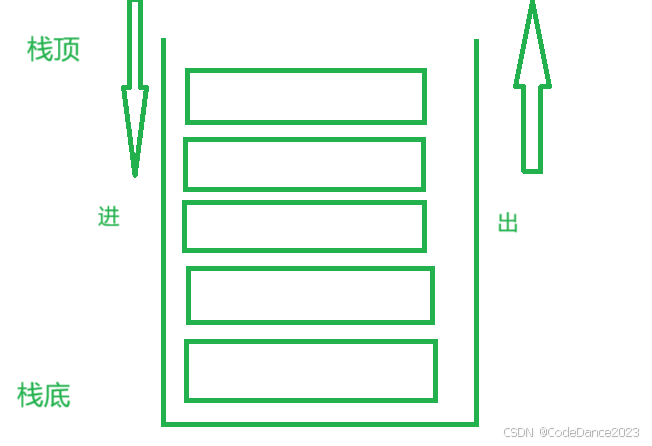
-
Java提供的对栈操作的常用方法

-
压栈(进栈):push( )
-
弹栈(出栈):pop( )
-
查看栈顶元素:peek( )
这些方法都是非静态方法,需要创建对象方可使用。
-
-
Java中的Stack集合的底层实现是数组,因此利用数组的添加规则,通过索引号就可以天然地保存添加数据时候的顺序,因此Java将其设计为有序集合;因为数据允许数据重复,因此Stack集合也允许数据重复,具有可重复性**;因为数组具有索引,因此Stack集合也具有索引。
-
-
-
Queue
-
Queue的队列的意思,队列是两端开口的数据结构,其基本特点是先进先出,后进后出。这里介绍简单且常见的**“单向队列”**。
-
单向队列:所谓单向,其实就是说明这个队列只有一个方向可以添加和删除数据。添加数据的一端称为队尾,删除数据的一端称为队首。这个队列就可以类比为:“平时我们排队买东西,只能从队尾进,队首出,不能插队”。
-
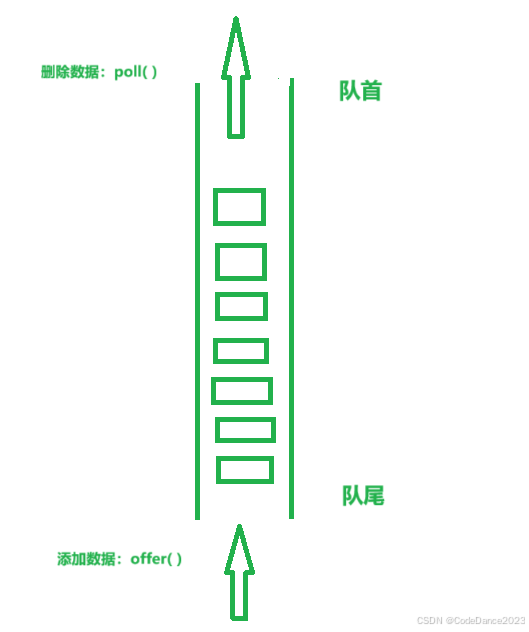
-
我们可以发现队列是一个增删操作比较频繁的数据结构,因此,我们可以利用LinkedList作为Queue的实现类。相比数组,链表具有更好的增删性能。因为数组想要删除一个数据,需要将其前面或者后面的所有数据依次向前移动,而链表只有分别删除两个节点中旧的“前面一个元素”的地址和“后面一个元素的”的地址,然后将这两个位置换成新的就可以了。
-
Java提供的对队列操作的常见方法
boolean offer( E e) 从队尾添加一个数据进队列 E poll( ) 从队首删除一个数据 E peek( ) 返回队首的元素 -
-
Set
-
HashSet
HashSet的底层是HashMap,而HashMap的底层数据结构是哈希表。
-
哈希表:说到哈希表,首先让我们先回顾一下数组。我们都知道,数组是通过索引号确认数据应该存进去的位置的,而哈希表也是。数组添加数据前,应该存入的位置是已经确定的,例如:0,1,2…而哈希表则要通过哈希函数和其他操作计算出数据应该存入哈希表的位置。在jdk8开始,哈希表由数组、链表、红黑树(下期会介绍红黑树是什么,这里只要知道有这个东西就可以)三部分组成,但并不是任何时候哈希表都会由这三部分组成,下面会具体介绍。
-
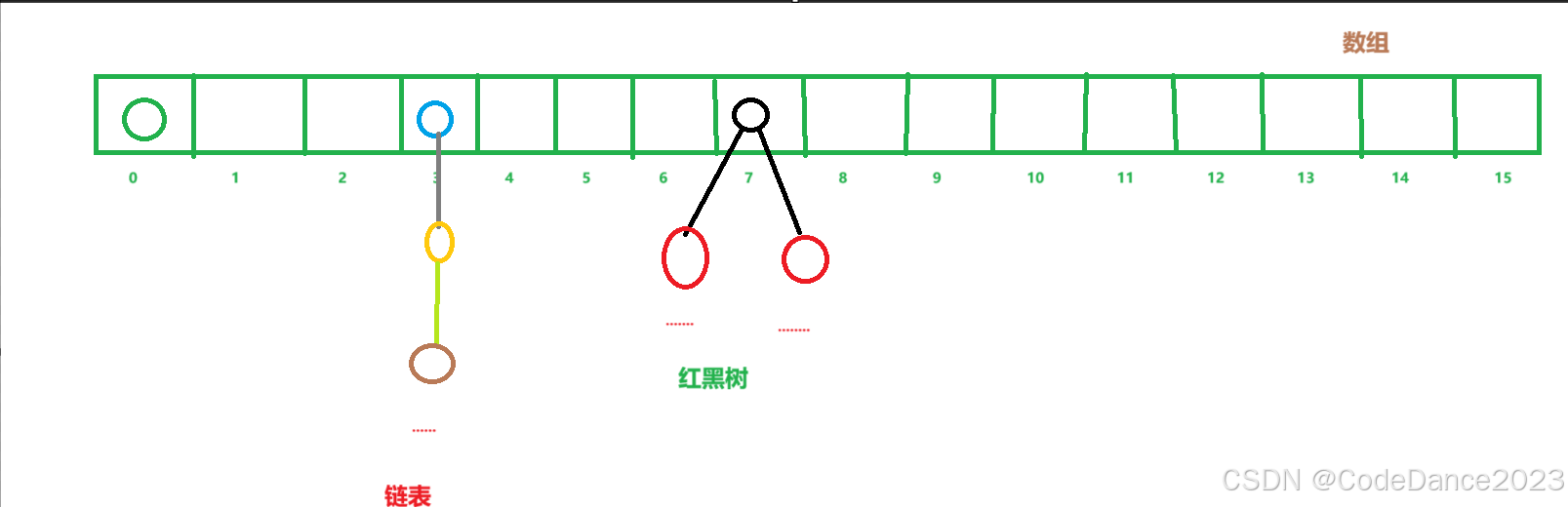
-
哈希函数:在Java中,哈希函数hashCode( )返回的是一个整形,是Object( )类里面的方法,默认是通过对象的地址值计算并返回哈希值。Java提供的类,例如:Integer、String等,它们都已经重写过了hashCode( )方法,例如Integer类的比较简单,返回的就是value——利用数据本身的值作为哈希值。而String类就相对复杂,这里不作介绍。注意:自定义的类型如果不重写,默认就是利用对象的地址值进行计算。
-
equals( )方法:利用这个方法,可以比较两个对象是否相同,也是Object类的方法,如果不进行重写,默认还是会利用地址值比较。
-
当我们先HashSet添加元素时,就会通过哈希值&数组长度-1(其中&是位运算符)计算出数据应该存入的位置。这个计算出来的位置可能后面添加的元素会大于或者小于或者等于前面的,因此无法天然的保存添加数据时的顺序,因此Java设计为无序集合。
-
添加数据的原理:如果这个位置没有元素,就会直接添加进入;如果这个位置已经有元素了,就会利用equals( )方法比较两个值是否一致。如果一致直接不存这个数据,这里解释了HashSet的不重复性;如果不一致,就是在这个数据下方利用链表将这两个数据连接起来,这时候才会形成数组+链表组成的哈希表。当链表的长度>8并且数组的长度>=64,这个链表就会自动转化成红黑树。这时才有可能形成数组+链表+红黑树的哈希表。因为一个位置可能不仅仅有一个数据,可能是一个红黑树,一个索引号对应这么多的数据是不现实的,因此Java不对Set集合提供索引方法,不具有索引。
-
-
-
LinkedHashSet
-
LinkedHashSet和HashSet的区别:LinkedHashSet是有序的,因为它在添加元素的时候,每一个元素中间利用双向链表连接起来维护了添加时候的顺序。
-
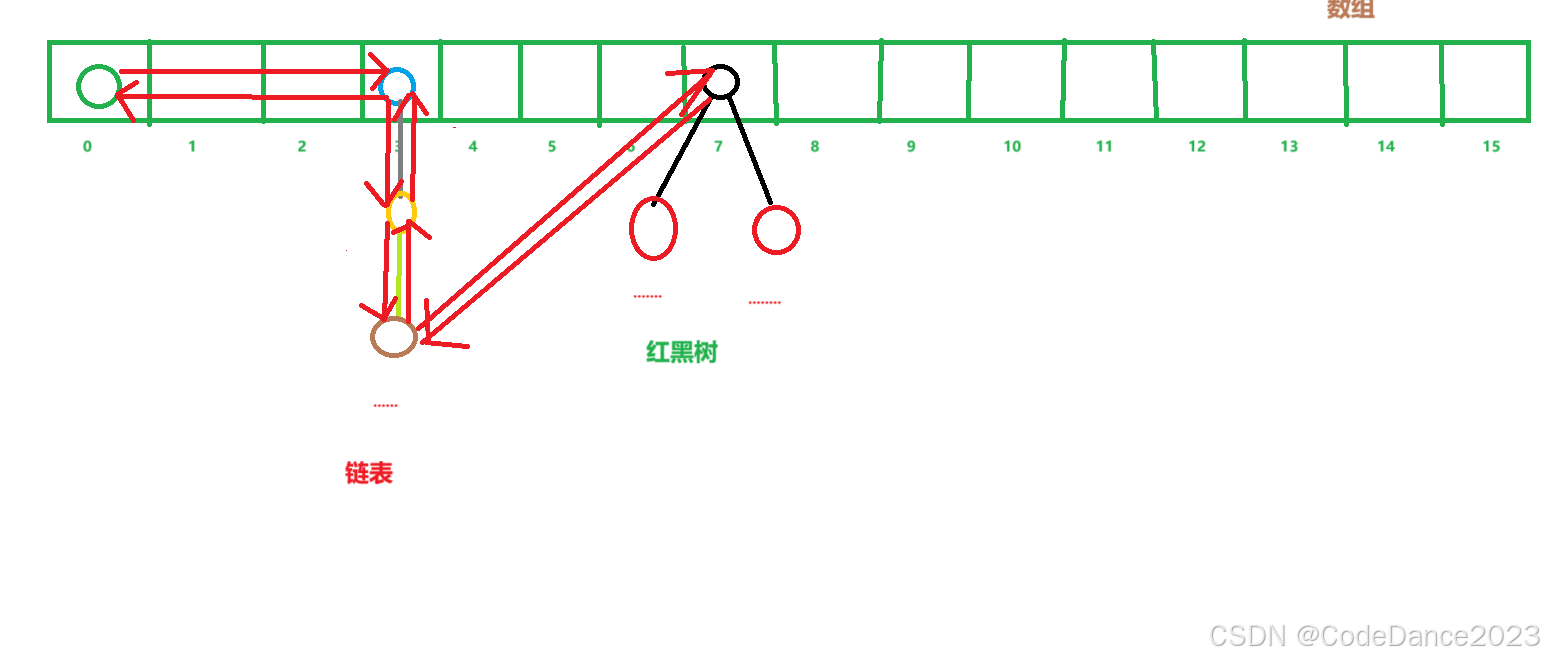
-
上图的红色双箭头就是双向链表维护的添加顺序,获取时只要按照这个顺序就可以保证添加和获取的顺序是一致的了。
-
思考题
对于TreeSet集合,它的底层数据结构是什么,又是怎样储存数据的呢?还有神秘的Map集合,它又是怎样的呢?

















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









