







参考网站 http://blog.csdn.net/shenziheng1/article/details/54178685
1. >>help svmtrain
SVMSTRUCT = svmtrain(TRAINING, Y)trains a support vector machine (SVM) classifier on data taken from two groups. TRAINING is a numeric matrix of predictor data(TRAINING是预测数据的一个数阵). Rows of TRAINING correspond to observations(TRAINING的行数代表样本数); columns correspond to features(列数代表特征的维数). Y is a column vector that contains the known class labels for TRAINING(Y是列向量,里面存着TRAINING的分类标签). Y is a grouping variable, i.e., it can be a categorical, numeric, or logical vector; a cell vector of strings; or a character matrix with each row representing a class label (see help for groupingvariable). Each element of Y specifies the group the corresponding row of TRAINING belongs to. TRAINING and Y must have the same number of rows. SVMSTRUCT contains information about the trained classifier, including the support vectors, that is used by SVMCLASSIFY for classification(SVMSTRUCT结构体中包含了训练好的分类器的所有参数,包括支持向量,这些支持向量也用于对测试集进行分类). svmtrain treats NaNs, empty strings or 'undefined'values as missing values and ignores the corresponding rows in TRAINING and Y.
2.分类机的参量选择svmtrain
********************************************************************************************
'kernel_function' A string or a function handle specifying the kernel function used to represent the dot product in a new space. The value can be one of the following:
**************************************************************************************************************************'linear' - Linear kernel or dot product (default). In this case, svmtrain finds the optimal separating plane in the original space.'quadratic' - Quadratic kernel(二次核函数)'polynomial' - Polynomial kernel with default order 3. To specify another order, use the 'polyorder' argument.(多项式核函数,默认是3阶,如果需要提升,在‘polyorder’进行参数设置)'rbf' - Gaussian Radial Basis Function with default scaling factor 1. To specify another scaling factor, use the 'rbf_sigma' argument.(高斯径向核函数,默认核宽为1,在‘rbf_sigma’可以进行参数设置)'mlp' - Multilayer Perceptron kernel (MLP) with default weight 1 and default bias -1. To specify another weight or bias, use the 'mlp_params' argument.(多层感知核函数,默认权重1,偏好-1)
'rbf_sigma' A positive number specifying the scaling factor in the Gaussian radial basis function kernel. Default is 1.(设置高斯径向核函数的核宽)**************************************************************************************************************************'polyorder' A positive integer specifying the order of the polynomial kernel. Default is 3.(设置多项式核函数的阶数)**************************************************************************************************************************'mlp_params' A vector [P1 P2] specifying the parameters of MLP kernel. The MLP kernel takes the form: K = tanh(P1*U*V' + P2), where P1 > 0 and P2 < 0. Default is [1,-1]. (设置多层感知核函数的权重和偏好)***************************************************************************************************************************'method' A string specifying the method used to find the separating hyperplane. Choices are:(采用指定的方法寻找分类超平面)
'SMO' - Sequential Minimal Optimization (SMO) method (default). It implements the L1 soft-margin SVM classifier.(序列最小优化算法)
'QP' - Quadratic programming (requires an Optimization Toolbox license). It implements the L2 soft-margin SVM classifier. Method 'QP' doesn't scale well for TRAINING with large number of observations.(二次规划)
***************************************************************************************************************************'LS' - Least-squares method. It implements the L2 soft-margin SVM classifier.(最小平方方法)
'options' Options structure created using either STATSET or OPTIMSET. * When you set 'method' to 'SMO' (default), create the options structure using STATSET. Applicable options:
'Display' Level of display output. Choices are 'off' (the default), 'iter', and 'final'. Value 'iter' reports every 500 iterations.'MaxIter' A positive integer specifying the maximum number of iterations allowed. Default is 15000 for method 'SMO'.
* When you set method to 'QP', create the options structure using OPTIMSET. For details of applicable options choices, see QUADPROG options. SVM uses a convex quadratic program, so you can choose the 'interior-point-convex' algorithm in QUADPROG.**************************************************************************************************************************'tolkkt' A positive scalar that specifies the tolerance with which the Karush-Kuhn-Tucker (KKT) conditions are checked for method 'SMO'. Default is 1.0000e-003. (‘method’='SMO'时;KKT迭代收敛条件) .**************************************************************************************************************************'kktviolationlevel' A scalar specifying the fraction of observations that are allowed to violate the KKT conditions for method 'SMO'. Setting this value to be positive helps the algorithm to converge faster if it is fluctuating near a good solution. Default is 0.**************************************************************************************************************************'kernelcachelimit' A positive scalar S specifying the size of the kernel matrix cache for method 'SMO'. Thealgorithm keeps a matrix with up to S * S double-precision numbers in memory. Default is 5000. When the number of points in TRAINING exceeds S, the SMO method slows down. It's recommended to set S as large as your system permits.(核函数内存空间设置).**************************************************************************************************************************'boxconstraint' The box constraint C for the soft margin. C can be a positive numeric scalar or a vector of positive numbers with the number of elements equal to the number of rows in TRAINING. Default is 1.
* If C is a scalar, it is automatically rescaled by N/(2*N1) for the observations of group one, and by N/(2*N2) for the observations of group two, where N1 is the number of observations in group one, N2 is the number of observations in group two. The rescaling is done to take into account unbalanced groups, i.e., when N1 and N2 are different.
* If C is a vector, then each element of C specifies the box constraint for the corresponding observation.
**************************************************************************************************************************'autoscale' A logical value specifying whether or not to shift and scale the data points before training. When the value is true, the columns of TRAINING are shifted and scaled to have zero mean unit variance. Default is true(数据归一化。默认是打开的).**************************************************************************************************************************
'showplot' A logical value specifying whether or not to show a plot. When the value is true, svmtrain creates a plot of the grouped data and the separating line for the classifier, when using data with 2 features (columns). Default is false(分类结果显示,仅适用于特征空间是两维情况).********************************************************************************************
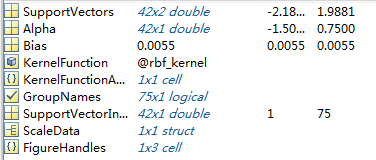
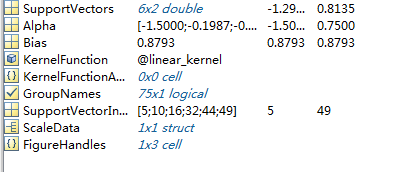
3.SVMSTRUCT中包含哪些信息?
SupportVectors Matrix of data points with each row corresponding to a support vector(支持向量).
Note: when 'autoscale' is false, this field contains original support vectors in TRAINING. When 'autoscale' is true, this field contains shifted and scaled vectors from TRAINING.
Alpha Vector of Lagrange multipliers for the support vectors. The sign is positive for support vectors belonging to the first group and negative for support vectors belonging to the second group(拉格朗日向量).Bias Intercept of the hyperplane that separates the two groups(超平面截距).
Note: when 'autoscale' is false, this field corresponds to the original data points in TRAINING. When 'autoscale' is true, this field corresponds to shifted and scaled data points.
KernelFunction The function handle of kernel function used(核函数).KernelFunctionArgs Cell array containing the additional arguments for the kernel function (核函数参量) .GroupNames A column vector that contains the known class labels for TRAINING. Y is a grouping variable (see help for groupingvariable).SupportVectorIndices A column vector indicating the indices of support vectors.ScaleData This field contains information about auto-scale. When 'autoscale' is false, it is empty. When 'autoscale' is set to true, it is a structure containing two fields:shift - A row vector containing the negativeof the mean across all observationsin TRAINING.scaleFactor - A row vector whose value is1./STD(TRAINING).FigureHandles A vector of figure handles created by svmtrain when 'showplot' argument is TRUE.
4.默认形式&参数设置对比
默认形式:参数选择形式:
注意:参数名称和后面的修改值必须要一一对应!















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









