






实践题目:CFI-CTF 2018 Automated Reversing
代码与附件地址:https://github.com/Airrcat/unicorn_loader
目标附件如:

每份附件的代码大致如下:
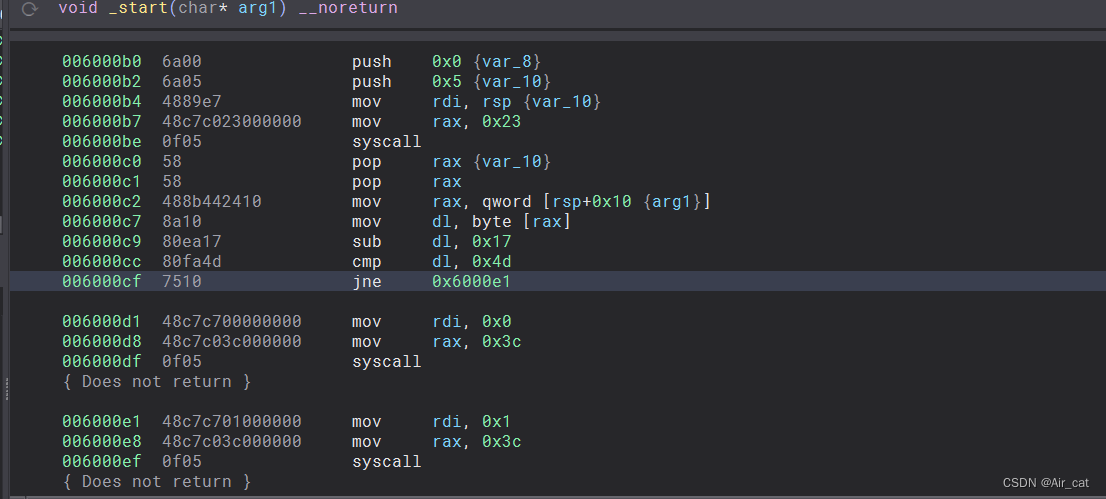
简单来说,程序会接收命令行参数并作一个字节的运算后与一固定值的字节变量进行比较,若匹配则返回0,不同程序进行的运算、比较值不同,由此可得逆推出不同的命令行参数。
但此题因为附件甚多,共有1009个附件,手动不好做,官方题解是提取运算的操作码、操作数来计算是什么结果。
而我觉得这题格式简单且批量,很适合来做Unicorn批量模拟执行的实践。
两部分
- 单步trace,根据当前ip做操作:
def trace(mu: Uc, address, size, data):
global check
global boom
EIP = mu.reg_read(unicorn.x86_const.UC_X86_REG_EIP)
if EIP == 0x19:
mu.reg_write(unicorn.x86_const.UC_X86_REG_DL,boom) # 写入爆破值
if EIP == 0x1f:
if mu.reg_read(unicorn.x86_const.UC_X86_REG_FLAGS)&(2**6)==(2**6): # check zf
check = 1
mu.emu_stop()
return
if EIP > 0x30:
mu.emu_stop()
- 遍历文件与值爆破
from pe_loader.pe_loader import *
from unicorn import *
check = 0
boom = 0
anwsers = []
for suffix in range(0,1009):
path = "attachment/binaries/"
prefix = "binary"
if suffix == 993:
continue
# 正常来说,这里能从pe信息里获取实地址、虚拟地址、大小等信息,但是我的elf结构体没做完。
loader = pe_loader(path + prefix+ str(suffix),UC_MODE_32)
vaddr = 0
vsize = 0xdf - 0xb0
raddr = 0xb0
rsize = 0xdf - 0xb0
content = loader.image[raddr:raddr + rsize]
CODE = content
BASE_ADDR = vaddr
CODE_LEN = vsize
uc = unicorn.Uc(UC_ARCH_X86,UC_MODE_32)
# 整体内存空间的初始化
uc.mem_map(BASE_ADDR,32*1024)
uc.mem_write(BASE_ADDR,b'\x00'*32*1024)
# 栈空间初始化,因为内存刚刚整体写了,这里其实可以不用。
STACK = b'\x00' * 1024
STACK_POINT = 30 * 1024
uc.reg_write(unicorn.x86_const.UC_X86_REG_SP,STACK_POINT)
# 代码段初始化
uc.mem_write(BASE_ADDR,CODE)
# 添加hook点,trace
uc.hook_add(UC_HOOK_CODE, trace)
for i in range(0,0xff):
# 对应程序return 1
if check == 1:
anwsers.append(boom)
check = 0
break
try:
boom = i
uc.emu_start(BASE_ADDR, rsize)
except UcError as e:
print("ERROR ", e)
uc.mem_unmap(BASE_ADDR,32*1024)
# clear,防止因为开了过多的模拟进程出现qemu的Could not allocate dynamic translator 错误
import gc
del uc
gc.collect()
with open("attachment/binaries/anwser.txt","wb") as f:
f.write(bytes(anwsers))
注意最后一个点:
# clear,防止因为开了过多的模拟进程出现qemu的Could not allocate dynamic translator 错误
import gc
del uc
gc.collect()
根据https://github.com/unicorn-engine/unicorn/issues/508这个issue以及我们一般能检索到的说法,这个错误是由qemu、unicorn以及python本身的资源管理问题。emu在stop后似乎无法自动,良好地释放资源,于是在过多的批量启动时就出现了资源分配错误。而我在尝试了手动gc后发现此问题能得到良好的解决。















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









