







面向对象编程OOP非常流行。但是可能会遇到很多问题。例如继承可以是单一继承或多重继承,每个继承连接可以是public,protected、private,也可以是Virtual或者non-virtual。然后是成员函数的各个选项:Virtual?non-virtual? pure virtual?以及成员函数和其他语言特性的交互营销:缺省参数值与Virtual函数有什么交互影响?继承如何影响C++的名称查找规则?设计选项有哪些?如果class的行为需要修改,Virtual函数时最佳选择吗?本章主要解决上诉问题。
条款32:确定你的public继承塑模出is-a关系
public继承意味着“is-a”关系。它的意思是:如果B以public形式继承自A,那么B类型对象肯定是一个A对象,反之不成立。A是B的一种抽象,B是A的特例。任何使用A的地方,都能使用B。
但是,有时候会犯认识上的错误:比如为类bird定义了函数“fly”,但是当我们从bird派生出企鹅Penguin时,却发现企鹅应该是不会飞的。这该怎么办呢?
第一,我们可以修改我们的设计:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
class Bird
{ }; class CanFly: public Bird { public: virtual void fly() ; }; class CannotFly: public Bird { }; class Penguin: public CannotFly { }; |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 |
class Bird
{ public: virtual void fly() {} }; class Penguin { public: void fly() { throw runtime_error( "attempt to make a penguin fly"); } }; |
|
1
2 3 4 5 6 7 8 9 |
Penguin p;
try { p.fly(); } catch( const runtime_error &e) { cerr << e.what() << endl; } |
和第一种相比,这是运行时错误,只有当程序运行时才能检测出来;而第一种是编译时错误,p.fly()本身就不能被调用。
第三种做法,就是对penguin不定义fly函数,这样当你试图调用时也会出错。
is-a 并非是唯一存在于calsses之间的关系,另两个常见关系是has-a和is-implemented-in-terms-of(根据某物实现出来)。将上诉这些重要的相互关系中的任何一个误塑为is-a并不常见,需要理解清楚。
请记住:
public继承意味is-a。适用于base classes 身上的每一件事情一定也适用于derived classes 身上,因为每一个derived class 对象也都是一个base classes。
条款33:避免掩盖继承而来的名称
这其实是一个作用域带来的问题:局部变量会掩盖同名的外围变量。注意,只要同名就会被掩盖,与类型无关:
|
1
2 3 4 5 6 7 8 9 10 |
void main()
{ int a = 10; { double a = 0. 1; cout << a << endl; //结果为0.1 } cout << a << endl; //结果为10 } |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class Base
{ public: virtual void f1() = 0; virtual void f2() { cout << "Base f2" << endl; } }; class Drived: public Base { public: void f1() { f2(); } void f2() { cout << "Drived f2" << endl; } }; //main.cpp Drived d; d.f1(); |
|
1
2 3 4 |
void f1()
{ Base::f2(); } |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
class Base
{ public: virtual void f1() = 0; virtual void f2() { cout << "Base f2" << endl; } void f3() { cout << "Base f3" << endl; } void f3( double d) { cout << "Base f3 double" << endl; //重载 } }; class Drived: public Base { public: void f1() { cout << "Drived f1" << endl; } void f2( int i) { cout << "Drived f2" << endl; } void f3() { cout << "Base f3 int" << endl; } }; |
|
1
2 3 |
Drived d;
d.f2( 1); //正确 //错误d.f2(); |
总之,我们发现基类的函数在这里不能使用了:即is-a关系不再成立了!为了让is-a关系继续满足,你可以通过声明来实现:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public:
using Base::f2; using Base::f3; void f1() { cout << "Drived f1" << endl; } int f2( int i) { cout << "Drived f2" << endl; return 1; } void f3( int i) { cout << "Drived f3" << endl; } |
|
1
2 3 |
d.f3();
d.f3( 1); d.f3( 1. 1); |
但是,using声明带来的问题是:假如我只想使用基类的f3的某个特定版本,但是这里会把f3的所有版本暴漏给派生类。怎么办呢?有一种称为转交函数的办法,在派生类中定义:
|
1
2 3 4 |
void f3(
double i)
{ Base::f3(i); } |
总之,派生类内的名称会掩盖基类中的名称,如果不想让这些名称被掩盖,可以使用using声明或者使用转交函数。
条款34:区分接口继承和实现继承
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
class Animal
{ public: virtual void eat() = 0; virtual void move(); void mad(); }; class Bird: public Animal { public: void eat(); void move(); }; void Animal::mad() { cout << "mad" << endl; } void Animal::move() { cout << "move from A to B" << endl; } void Bird::eat() { cout << "eat worm" << endl; } void Bird::move() { cout << "fly from A to B" << endl; } |
当然,事情总有一些特例,比如,我们可以对基类的纯虚函数eat给出定义。
|
1
2 3 4 |
void Animal::eat()
{ cout << " eat everything" << endl; } |
|
1
2 |
Bird b;
b.Animal::eat(); |
不过这种用法并不常见。
对于虚函数,如果派生类定义了自己的版本,那么派生类的对象就会调用自己的;如果没有,就会调用基类。这本来是一件多么美好而方便的事啊!可是,它有可能让程序员忘掉了这个函数的行为不是这个类中定义的,而是一种默认的行为。我们希望的结果是告诉编译器我要用默认行为了,再用默认行为;如果我没说,请编译器提醒我这样做不对:
- class Animal
- {
- public:
- virtual void eat() = 0;
- virtual void move() = 0;
- void mad();
- protected:
- void defaultMove();
- };
- void Animal::defaultMove()
- {
- cout<<"move from A to B"<<endl;
- }
- void Bird::move()
- {
- defaultMove();
- // cout<<"fly from A to B"<<endl;
- }
|
1
2 3 4 5 6 7 8 9 10 11 |
void Animal::move()
//纯虚函数的实现 { cout << "move from A to B" << endl; } void Bird::move() { //调用纯虚函数的实现 Animal::move(); // cout<<"fly from A to B"<<endl; } |
按照前面的论述,则可以避免两种常见的错误:
1.把基类中的所有函数都声明为非虚函数—这就意味着你不打算给派生类一点自我发挥的空间。而且如果析构函数不声明为虚函数,可能会带来各种问题。
2.将所有函数都声明为虚函数,但这也表明了你对自己的设计的基类很没有信心,基本没有什么东西是确定的。
总而言之,纯虚函数使得派生类只继承基类的接口;虚函数让派生类可以自我发挥,但是如果不想发挥,也可以提供默认版本;而非虚函数则要求你必须继承它,没有自由空间。
条款35:考虑Virtual函数以外的其他选择
|
1
2 3 4 5 |
class GameCharacter
{ public: virtual int healthValue() const; }; |
就是说基类里定义了一个计算生命值的函数,派生类通过重新定义这个函数来完成不同类型的角色的生命值的计算。
假如生命值的计算分为如下几步:
1.获得生命值。
2.通过一个函数计算生命值。
3.将生命值返回。
那么每个派生类的healthValue函数都需要完成这几步,我们能不能重构这个代码呢?先看一下重构的结果:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
class GameCharacter
{ public: int healthValue() { int val = getInitialVal(); val = calcVal(val); return val; } protected: virtual int getInitialVal() = 0; virtual int calcVal( int ) = 0; }; class Soldier: public GameCharacter { private: int getInitialVal(); int calcVal( int ); }; class Patient: public GameCharacter { private: int getInitialVal(); int calcVal( int ); }; //战士的初始生命值较高 int Soldier::getInitialVal() { return 50; } //但是生命值会减半 int Soldier::calcVal( int val) { return val = val / 2; } //病人的声明值较低 int Patient::getInitialVal() { return 10; } //但是生命值会翻倍 int Patient::calcVal( int val) { return val = val * 2; } |
1.它在基类中声明了2个不会被继承的虚函数getInitialVal()和calcVal(int val)。但是在基类的可以被继承的(且不希望被修改的)healthValue函数中调用了。
2.在派生类中定义了healthValue所要调用的函数。
他这样做的好处是:在基类中,限定了先做什么,后做什么。但是具体怎样做,把权力移交给了派生类。
这种思路,称为 模板方法模式 ,它的定义为: 定义一个操作中的算法的骨架,而将一些方法实现延迟到子类。模板方法使得子类可以不改变一个算法的结构即可以重定义该算法的某些特定步骤。
但是这样做其实并不灵活,假如我希望同一个类型的不同对象有不同的计算生命值的方法,就麻烦了。换个角度思考,人物健康指数的计算,其实,不一定与人物的特定类型有关,对于同一个类型,也可以有不同的计算方法。由此我们想到, 不能让每个类型的声明计算与一个函数相关,而对于不同的对象,可以调用不同的函数来完成这件事 。依照这个思路,我们可以这么写:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
//人物健康指数的计算与人物类型无关 //要求每个人物的构造函数接受一个指针,指向一个健康计算函数 class GameCharacter; int defaultHealthCalc( const GameCharacter &gc); class GameCharacter { public: typedef int (*HealthCalcFunc)( const GameCharacter &); explicit GameCharacter(HealthCalcFunc hcf = defaultHealthCalc ): healthFunc(hcf) {} int healthValue() const { return healthFunc(* this); } virtual int getInitHealth() const = 0; private: HealthCalcFunc healthFunc; }; class Soldier: public GameCharacter { public: explicit Soldier(HealthCalcFunc hcf = defaultHealthCalc): GameCharacter(hcf) {} int getInitHealth() const; }; class Patient: public GameCharacter { public: explicit Patient(HealthCalcFunc hcf = defaultHealthCalc): GameCharacter(hcf) {} int getInitHealth() const; }; int loseHealthQuickly( const GameCharacter &); int loseHealthSlowly( const GameCharacter &); int recoverHealth( const GameCharacter &); int Soldier::getInitHealth() const { return 50; } int Patient::getInitHealth() const { return 10; } int defaultHealthCalc( const GameCharacter &gc) { int health = gc.getInitHealth(); health = health / 2; return health; } int loseHealthQuickly( const GameCharacter &gc) { int health = gc.getInitHealth(); health = health / 4; return health; } int loseHealthSlowly( const GameCharacter &gc) { int health = gc.getInitHealth(); health = health / 1. 6; return health; } int recoverHealth( const GameCharacter &gc) { int health = gc.getInitHealth(); health = health * 2; return health; } |
此时,人物类型与计算声明的方法就无关了:
|
1
2 3 4 5 6 7 8 9 10 11 |
int main()
{ Soldier s1; cout << loseHealthQuickly(s1) << endl; Soldier s2(recoverHealth); cout << recoverHealth(s2) << endl; Patient p1; cout << loseHealthSlowly(p1) << endl; return 0; } |
这个例子一下子拓宽了我们的眼界:为什么非得使用某个函数去计算生命值,能不能使用某个类似函数的,可以被调用的东西来计算呢?比如函数对象、类的成员函数等等。通过tr1中的function可以帮你完成这样的设想:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
//.h //前置声明 class GameCharacter; int defaultHealthCalc( const GameCharacter &gc); class GameCharacter { public: //std::tr1::function相当于一个泛化的函数指针 typedef std::tr1::function< int ( const GameCharacter &)> HealthCalcFunc; explicit GameCharacter( HealthCalcFunc hcf = defaultHealthCalc ): healthFunc(hcf) {} int healthVaule() const { return healthFunc(* this); } virtual int getInitHealth() const = 0; private: HealthCalcFunc healthFunc; }; class Soldier: public GameCharacter { public: explicit Soldier(HealthCalcFunc hcf = defaultHealthCalc): GameCharacter(hcf) {} int getInitHealth() const; }; //可以采取以下3种措施调用计算健康值的函数 //计算健康值的函数,其返回类型为short short HalfHealth( const GameCharacter &); //计算健康值的函数对象 struct AddHealth { int operator()( const GameCharacter &gc) const { int health = gc.getInitHealth(); health = health + 10; cout << "生命值加10" << endl; return health; } }; //类成员函数 class GameLevel { public: float hard( const GameCharacter &) const; float easy( const GameCharacter &) const; }; //cpp int Soldier::getInitHealth() const { return 50; } int defaultHealthCalc( const GameCharacter &gc) { int health = gc.getInitHealth(); health = health * 2; cout << "默认计算生命值,为初始值的2倍" << endl; return health; } short HalfHealth( const GameCharacter &gc) { short health = gc.getInitHealth(); health = health / 2; cout << "生命值减半" << endl; return health; } float GameLevel::hard( const GameCharacter &gc) const { float health = gc.getInitHealth(); cout << "困难模式,生命值为初始值的四分之一" << endl; return health / 4; } float GameLevel::easy( const GameCharacter &gc) const { float health = gc.getInitHealth(); cout << "简单模式,生命值为初始值的四倍" << endl; return health * 4; } //main int main() { //调用默认函数生命值翻倍 Soldier s1; cout << s1.healthVaule() << endl; //生命值减半 Soldier s2(HalfHealth); cout << s2.healthVaule() << endl; //生命值加10 AddHealth add; Soldier s3(add); cout << s3.healthVaule() << endl; GameLevel level; //对非静态成员函数,需要通过bind绑定 //easy函数有一个参数,所以需要一个占位符 Soldier s4(std::tr1::bind(&GameLevel::easy, level, std::tr1::placeholders::_1)); cout << s4.healthVaule() << endl; Soldier s5(std::tr1::bind(&GameLevel::hard, level, std::tr1::placeholders::_1)); cout << s5.healthVaule() << endl; return 0; } |
这个例子跟前面的很类似,但是又有所区别:我们没有定义类型确定的函数指针,而是定义了一个“泛化的”函数指针:HealthCalcFunc,它的返回值为int(或可以转化为int),输入参数为GameCharacter引用(或可以转化为GameCharacter)的可调用物:可以是一般函数、可以是函数对象,也可以是成员函数。
对于普通函数,和函数对象,可以直接用来给HealthCalcFunc赋值。对非静态成员函数,需要通过bind绑定:为了计算s4的健康函数,需要使用GameLevel里面的easy函数,这个函数实际上有两个参数:*this(GameLevel类型)和GameCharacter&,HealthCalcFunc只接受一个参数:GameCharacter&。需要将GameLevel类型中的easy函数与调用它的对象绑定起来,此后每次调用easy函数,都是调用绑定的那个对象(level)的这个函数。其中_1是占位符,表示的是这个函数的第一个参数。
经过上一个想法的洗礼,尤其是调用类成员函数,使我们不禁想到了为什么不把所有的计算生命函数设成一个基类,然后从中派生出各个子类方法,然后让GameCharacter调用这些方法呢?下面是实现的程序:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
//healthCalcFunc.h //前置声明 class GameCharacter; class HealthCalcFunc { public: virtual int calc( const GameCharacter &gc) const; }; //计算生命值方法派生类 class AddHealth: public HealthCalcFunc { public: int calc( const GameCharacter &gc) const; }; //计算生命值方法派生类 class DoubleHealth: public HealthCalcFunc { public: int calc( const GameCharacter &gc) const; }; //头文件中声明 extern HealthCalcFunc defaultHealthCalc; //healthCalcFunc.cpp #include "healthCalcFunc.h" #include "gameCharacter.h" int HealthCalcFunc::calc( const GameCharacter &gc) const { cout << "返回原始生命值" << endl; return gc.getInitHealth(); } int AddHealth::calc( const GameCharacter &gc) const { cout << "生命值+10" << endl; return gc.getInitHealth() + 10; } int DoubleHealth::calc( const GameCharacter &gc) const { cout << "生命值翻倍" << endl; return gc.getInitHealth() * 2; } //源文件中定义 HealthCalcFunc defaultHealthCalc; //gameCharacter.h #include "healthCalcFunc.h" class GameCharacter { public: explicit GameCharacter(HealthCalcFunc *phcf = &defaultHealthCalc): pHealthCalc(phcf) {} int healthVaule() const; int getInitHealth() const ; private: HealthCalcFunc *pHealthCalc; }; //gameCharacter.cpp #include "gameCharacter.h" int GameCharacter::healthVaule() const { return pHealthCalc->calc(* this); } int GameCharacter::getInitHealth() const { return 50; } //main.cpp int main() { GameCharacter gc0; cout << gc0.healthVaule() << endl; GameCharacter gc1(&AddHealth()); cout << gc1.healthVaule() << endl; GameCharacter gc2(&DoubleHealth()); cout << gc2.healthVaule() << endl; return 0; } |
这个方法称为strategy模式,它的定义如下:Strategy模式定义了一系列的算法,将它们每一个进行封装,并使它们可以相互交换。Strategy模式使得算法不依赖于使用它的客户端。
这个条款略微有些长,但总结起来,无非是这样对于虚函数,有如下几种替代方案:
1.模版方法模式。在类中确定派生类要做的事情的顺序,然后让派生类自己实现它们。
2.使用函数指针。将虚函数移到类的外部,但是它不能访问类的private成分。
3.使用tr1::function指定“泛型”函数指针,是得我们可以通过函数、函数对象、成员函数来替代虚函数。
4.使用策略模式,将虚函数所要完成的事情封装成类,以便于扩展。
条款36:绝不重新定义继承而来的non-Virtual函数
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
class Base
{ public: void func() { cout << "base function" << endl; } }; class Drived : public Base { public: void func() { cout << "drived function" << endl; } }; int main() { Drived d; Base *pb = &d; pb->func(); Drived *pd = &d; pd->func(); return 0; } |
对于一件事情如果Base能做,那么Drived也能做。但是当你重新定义了派生类的非虚函数时,那么在使用指针或者引用时,从直观上看,派生类做的事情就可以与基类做的大不相同。
总之,绝不重定义继承而来的non-virtual函数。
条款37:绝不重新定义继承而来的缺省参数值
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#include<iostream>
using namespace std; class Base { public: virtual int getVal( int i = 0) { cout << "基类函数" << endl; return i; } }; class Derived: public Base { public: int getVal( int i = 1) { cout << "派生类函数" << endl; return i; } }; int main() { Derived d; Base *pb = &d; cout << pb->getVal() << endl; system( "pause"); return 0; } |
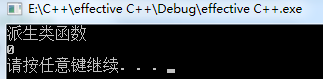
这是多么容易出错的一件事啊!调用派生类的函数,但是他的参数的默认值却是基类提供的。但编译器也有自己的苦衷:运行期效率。
那么我们似乎应该将派生类的默认参数改成与基类相同,但是这又带来其他的问题,其中最严重的是:如果基类的默认参数需要修改,那你不得不修改所有派生类的默认参数!
一种比较好的替代方案是前面介绍的NVI(non-virtual interface)手法:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
class Base
{ public: int getVal( int i = 0) { doGetVal(i); return i; } private: virtual int doGetVal( int i) { cout << "基类函数" << endl; return i; } }; class Derived: public Base { private: virtual int doGetVal( int i) { cout << "派生类函数" << endl; return i; } }; |
总之,virtual函数是动态绑定,但是函数的默认参数是静态绑定的。所以绝不要重新定义派生类的函数的默认参数值,而且最好使用NVI手法。
条款38:通过复合塑模出has-a或“根据某物实现出”
比如,定义一个“人”类,而人又有地址,那么你应该这么写:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 |
class Address
{ public: string country; string province; string city; }; class Person { string name; Address address; }; |
下面就用这个例子来说明:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
template<
typename T>
class Set { public: bool member( const T &item) const { return find(rep.begin(), rep.end(), item) != rep.end(); } void insert( const T &item) { if(!member(item)) rep.push_back(item); } void remove( const T &item) { typename list<T>::iterator it = find(rep.begin(), rep.end(), item); if(it != rep.end()) rep.erase(it); } size_t size() const { return rep.size(); } void print() { list<T>::iterator it = rep.begin(); for(; it != rep.end(); ++it) cout << *it << "\t" << endl; } private: list<T> rep; }; |
总之,复合与public继承完全不同,它意味着has-a或者通过XX实现。
条款39:明智而审慎地使用private继承
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class Person
{ protected: string name; }; class Student: private Person { private: string schoolNumber; }; void eat( const Person &p) { cout << "eat" << endl; } void study( const Student &s) { cout << "study" << endl; } int main() { Person p1; eat(p1); Student s1; study(s1); // eat(s1);错误 return 0; } |
因此,private继承意味着:根据某物实现。这与前面条款介绍的复合很类似。在大多数时候,我们应该使用复合,而不是private继承来实现这种功能。但是当有protected成员和虚函数牵扯进来的时候,我们又不得不用private继承。
其次,与复合相比,private可以使空基类的最优化。先看一个例子:
|
1
2 3 4 5 6 7 8 9 10 |
//定义一个空基类 class Empty {}; class HoldsAnInt { private: int x; Empty e; //复合 }; |
|
1
2 3 4 5 6 7 8 9 |
//定义一个空基类 class Empty {}; class HoldsAnInt: private Empty { private: int x; }; |
但是,如果使用的是private继承来实现,就不存在这种问题了:sizeof(HoldsAnInt)只有一个int的大小:4.
总之,private继承意味着根据某物实现。当派生类需要访问基类的的受保护成员或者重新定义虚函数时,我们才使用它。而且private继承可以是得空基类最优化,如果在开发中需要是得对象尺寸最小,那么也用得着它。
条款40:明智而审慎地使用多重继承
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
class Base1
{ public: void func() { cout << "base1 func" << endl; } }; class Base2 { private: bool func() { cout << "base2 func" << endl; return true; } }; class Derived: public Base1, public Base2 { }; int main() { Derived d; //d.func();二义性 return 0; } |
这还不是最可怕的情况,最可怕的是出现“钻石型多重继承”:B和C继承自A,而且D继承自B和C。此时,理论上讲,D中会有两份A的public成员(这里假定是public继承),但实际上,大多数时候,我们只希望有一份,此时只能通过虚继承来避免这种现象。
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class Base
{ public: void print() { cout << "base" << endl; } }; class Middle1: public Base { }; class Middle2: public Base { }; class Derived: public Middle1, public Middle2 { }; |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class Base
{ public: void print() { cout << "base" << endl; } }; class Middle1: public virtual Base { }; class Middle2: public virtual Base { }; class Derived: public Middle1, public Middle2 { }; |
因此,不到万不得以,不要使用虚基类,在使用时,尽量避免在其中放置数据,因为它的初始化规则跟一般情况不同。
然后书中给出了一个使用的多重继承的例子: 有一个接口类,我们需要实现它;恰巧我们有一个现成的类,这个类的功能跟我们要实现的类相似,但是我们需要对它的虚函数进行重写,已达到我们希望的功能,于是我们public继承了这接口,又private继承了它的实现,并对其中的某些实现重定义了。这时候,多重继承真的就派上了用场。
总的来说,多重继承可能会引起很多问题:二义性、构造、析构函数的顺序,类的大小、访问速度等等。但有时的确也会使用到它。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









