







先来张原理图吧 !
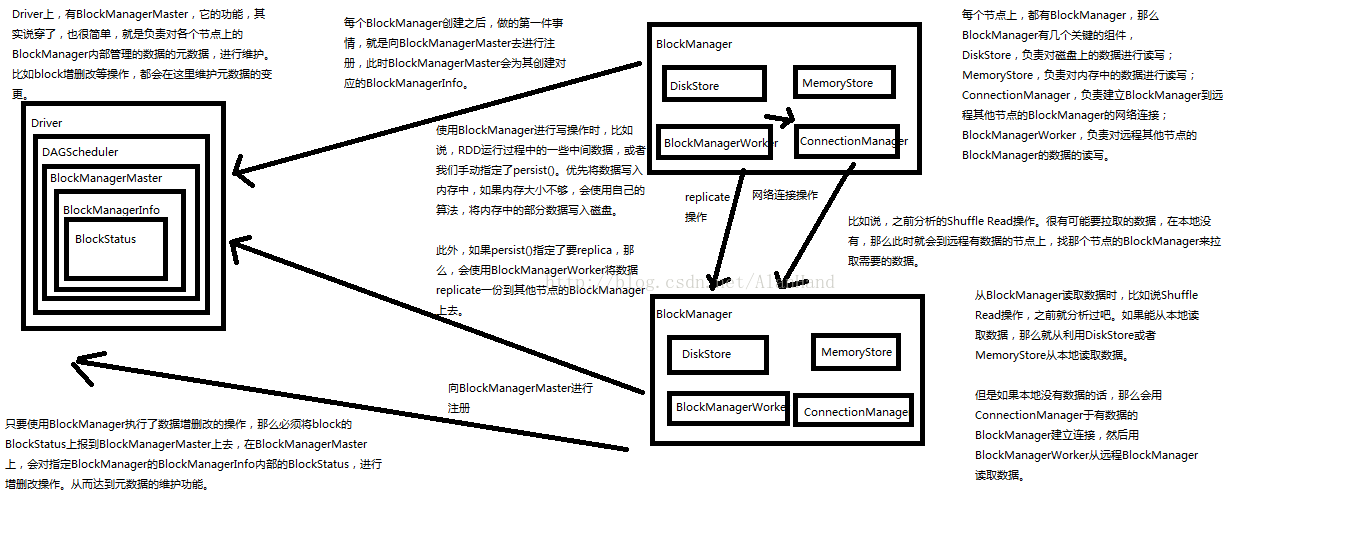
上面的BlockManagerWorker是在1.3之前的版本中才有的 , 从1.3开始BlockManagerWorker由BlockTransferService替代 .
其实BlockManagerMaster的主要工作是交于BlockManagerMasterActor来处理的:
/*** BlockManagerMasterActor is an actor on the master node to track statuses of* all slaves' block managers.** 其实BlockManagerMasterActor就是负责维护各个executor的BlockManager的元数据* BlockManagerInfo , BlockStatus*/private[spark]class BlockManagerMasterActor(val isLocal: Boolean, conf: SparkConf, listenerBus: LiveListenerBus)extends Actor with ActorLogReceive with Logging {
该类中有一个内部类就是BlockManagerInfo , 负责存放每一BlockManager的信息并更新和删除block状态的改变:
/*** 每一个BlockManager的BlockManagerInfo*/private[spark] class BlockManagerInfo(val blockManagerId: BlockManagerId,timeMs: Long,val maxMem: Long,val slaveActor: ActorRef)extends Logging {private var _lastSeenMs: Long = timeMsprivate var _remainingMem: Long = maxMem// Mapping from block id to its status.private val _blocks = new JHashMap[BlockId, BlockStatus]def getStatus(blockId: BlockId) = Option(_blocks.get(blockId))def updateLastSeenMs() {_lastSeenMs = System.currentTimeMillis()}def updateBlockInfo(blockId: BlockId,storageLevel: StorageLevel,memSize: Long,diskSize: Long,tachyonSize: Long) {updateLastSeenMs()/*** 判断如果内部有这个block*/if (_blocks.containsKey(blockId)) {// The block exists on the slave already.val blockStatus: BlockStatus = _blocks.get(blockId)val originalLevel: StorageLevel = blockStatus.storageLevelval originalMemSize: Long = blockStatus.memSize// 判断如果storagelevel是使用内存那么就给剩余内存数量加上当前的内存量if (originalLevel.useMemory) {_remainingMem += originalMemSize}}// 给Block创建一份BlockStatus,然后根据其持久化级别对相应的内存资源进行计算if (storageLevel.isValid) {/* isValid means it is either stored in-memory, on-disk or on-Tachyon.* The memSize here indicates the data size in or dropped from memory,* tachyonSize here indicates the data size in or dropped from Tachyon,* and the diskSize here indicates the data size in or dropped to disk.* They can be both larger than 0, when a block is dropped from memory to disk.* Therefore, a safe way to set BlockStatus is to set its info in accurate modes. */if (storageLevel.useMemory) {_blocks.put(blockId, BlockStatus(storageLevel, memSize, 0, 0))_remainingMem -= memSizelogInfo("Added %s in memory on %s (size: %s, free: %s)".format(blockId, blockManagerId.hostPort, Utils.bytesToString(memSize),Utils.bytesToString(_remainingMem)))}if (storageLevel.useDisk) {_blocks.put(blockId, BlockStatus(storageLevel, 0, diskSize, 0))logInfo("Added %s on disk on %s (size: %s)".format(blockId, blockManagerId.hostPort, Utils.bytesToString(diskSize)))}if (storageLevel.useOffHeap) {_blocks.put(blockId, BlockStatus(storageLevel, 0, 0, tachyonSize))logInfo("Added %s on tachyon on %s (size: %s)".format(blockId, blockManagerId.hostPort, Utils.bytesToString(tachyonSize)))}// 如果StorageLevel是非法的而且之前保存过这个blockId那么就将blockId从内存中删除} else if (_blocks.containsKey(blockId)) {// If isValid is not true, drop the block.val blockStatus: BlockStatus = _blocks.get(blockId)_blocks.remove(blockId)if (blockStatus.storageLevel.useMemory) {logInfo("Removed %s on %s in memory (size: %s, free: %s)".format(blockId, blockManagerId.hostPort, Utils.bytesToString(blockStatus.memSize),Utils.bytesToString(_remainingMem)))}if (blockStatus.storageLevel.useDisk) {logInfo("Removed %s on %s on disk (size: %s)".format(blockId, blockManagerId.hostPort, Utils.bytesToString(blockStatus.diskSize)))}if (blockStatus.storageLevel.useOffHeap) {logInfo("Removed %s on %s on tachyon (size: %s)".format(blockId, blockManagerId.hostPort, Utils.bytesToString(blockStatus.tachyonSize)))}}}
每一个BlockManager刚开始的时候都会向BlockManagerMasterActor发送 "
RegisterBlockManager
"消息进行注册 , BlockManagerMasterActor接收到消息之后的注册代码如下:
/*** 接收消息处理的方法*/override def receiveWithLogging = {/*** 首先BlockManagerMaster需要接收到其它节点的BlockManager注册的消息*/case RegisterBlockManager(blockManagerId, maxMemSize, slaveActor) =>// 调用注册方法register(blockManagerId, maxMemSize, slaveActor)// 发送注册成功的消息sender ! true/*** 发送Block信息更改*/case UpdateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size, tachyonSize) =>sender ! updateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size, tachyonSize)
里面会调用register方法 , Block状态更改的消息下面会分析 , 源码如下:
/** * BlockManager注册的方法 */ private def register(id: BlockManagerId, maxMemSize: Long, slaveActor: ActorRef) { val time = System.currentTimeMillis() // 首先判断一下HashMap中没有指定的BlockManagerId, 说明从来没有注册过那么才会继续往下走去注册这个BlockManager if (!blockManagerInfo.contains(id)) { // 根据BlockManager对应的ExecutorId找到对应的BlockManagerInfo // 做一个安全判断 , 如果没有BlockManagerId那么同步到blockManagerIByExecutorId里面 // 如果BlockManagerIdByExecutor有的话就做一下清理 blockManagerIdByExecutor.get(id.executorId) match { case Some(oldId) => // A block manager of the same executor already exists, so remove it (assumed dead) logError("Got two different block manager registrations on same executor - " + s" will replace old one $oldId with new one $id") // 从内存中移除掉executorId相关的blockManagerInfo removeExecutor(id.executorId) case None => } logInfo("Registering block manager %s with %s RAM, %s".format( id.hostPort, Utils.bytesToString(maxMemSize), id)) // 往blockmanagerIdByExecutor map 中保存一份executorid到blockmanagerId的映射 blockManagerIdByExecutor(id.executorId) = id // 为BlockManagerId创建一份BlockManagerInfo // 并往BlockManagerInfo map中保存一份blockmanagerId到blockmanagerInfo的映射 // 到这里注册BlockManager就完咯 blockManagerInfo(id) = new BlockManagerInfo( id, System.currentTimeMillis(), maxMemSize, slaveActor) } listenerBus.post(SparkListenerBlockManagerAdded(time, id, maxMemSize)) }
其实BlockManager的注册就是将BlockManagerId和与这个BlockManager相关联的ExecutorId加入BlockManagerInfo和BlockManagerIdByExecutor中 ,下面的BlockManagerMasterActor的三个成员变量负责存放这些信息:
// 首先这个map 映射了block manager id 到block manager info 之间的映射关系 // BlockManagerMaster要负责维护每个BlockManager的BlockManagerInfo // 而Spark中管理数据的最小单位为Block , 同Hadoop一样 private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo] // Mapping from executor ID to block manager ID. private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId] // Mapping from block id to the set of block managers that have the block. private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
接下来就分析一下BlockManager的源码 , BlockManager运行在每个节点上,包括driver和executor都会有一份,主要提供关联在本地或者远程存取数据的功能 , 并支持内存,磁盘和对外存储
,该类中有一成员变量会对每一个block信息进行缓存,如下:
// 这里还有一个东西就是每个BlockManager自己会维护一个map在内存中存放一个一个的block块 // 这个块是blockId到blcokInfo的映射 // 每个BlockInfo中是不是就封装了Block的数据 // BlockInfo最大的作用是用于作为多线程访问同一个Block的同步监视器 private val blockInfo = new TimeStampedHashMap[BlockId, BlockInfo]
最先调用BlockManager的initialize方法对一些组件进行初始化:
def initialize(appId: String): Unit = { // 在1.3版本之前BlockManager是使用BlockManagerWorker来进行通信的 , 但1.3版本已经改为BlockTransfer // 所以首先初始化用于block数据传输的BlockTransferService blockTransferService.init(this) shuffleClient.init(appId) //为当前这个BlockManager创建一个唯一的BlockManagerId,使用到了executorId(每个BlockManager都关联一个executor,BlockTransferService的hostname以及port) // 所以 , 从这个BlockManagerId的初始化即可看出一个BlockManager是通过一个节点上的executor来唯一标识的 blockManagerId = BlockManagerId( executorId, blockTransferService.hostName, blockTransferService.port) shuffleServerId = if (externalShuffleServiceEnabled) { BlockManagerId(executorId, blockTransferService.hostName, externalShuffleServicePort) } else { blockManagerId } // 使用BlockManagerMasterActor引用进行BlockManager的注册 , 发送消息到BlockManagerMasterActor master.registerBlockManager(blockManagerId, maxMemory, slaveActor) // Register Executors' configuration with the local shuffle service, if one should exist. if (externalShuffleServiceEnabled && !blockManagerId.isDriver) { registerWithExternalShuffleServer() } }
上面的代码中调用registerBlockManager方法使用BlockManagerMasterActor的引用进行BlockManager进行注册,发送消息到BlockManagerMasterActor , 后面就是调用
BlockManagerMasterActor 的register方法了 , 上面已经提到过.
接下来就是数据的获取了 , 分别是从本地获取数据和从远程的节点上获取数据 , 以下是BlockManager从本地获取数据的源码:
/** * 从本地获取数据 */ private def doGetLocal(blockId: BlockId, asBlockResult: Boolean): Option[Any] = { // 首先尝试直接从内存中获取数据 val info = blockInfo.get(blockId).orNull if (info != null) { // 对所有的BlockInfo都会进行多线程并发访问的同步操作 // 所有BlockInfo相当于是对一个Block用于作为多线程并发访问的同步监视器 info.synchronized { // Double check to make sure the block is still there. There is a small chance that the // block has been removed by removeBlock (which also synchronizes on the blockInfo object). // Note that this only checks metadata tracking. If user intentionally deleted the block // on disk or from off heap storage without using removeBlock, this conditional check will // still pass but eventually we will get an exception because we can't find the block. if (blockInfo.get(blockId).isEmpty) { logWarning(s"Block $blockId had been removed") return None } // If another thread is writing the block, wait for it to become ready. // 如果其他线程在操作这个block那么其实会卡住等待后去BlockInfo的排他锁 // 如果始终没有获取到则返回false if (!info.waitForReady()) { // If we get here, the block write failed. logWarning(s"Block $blockId was marked as failure.") return None } val level = info.level logDebug(s"Level for block $blockId is $level") // Look for the block in memory // 判断如果持久化级别使用了内存比如MEMORY_ONLY,MEMORY_AND_DISK_SER // 尝试从MemoryStore中获取数据 if (level.useMemory) { logDebug(s"Getting block $blockId from memory") val result = if (asBlockResult) { memoryStore.getValues( ).map(new BlockResult(_, DataReadMethod.Memory, info.size)) } else { memoryStore.getBytes(blockId) } result match { case Some(values) => return result case None => logDebug(s"Block $blockId not found in memory") } } // Look for the block in Tachyon if (level.useOffHeap) { logDebug(s"Getting block $blockId from tachyon") if (tachyonStore.contains(blockId)) { tachyonStore.getBytes(blockId) match { case Some(bytes) => if (!asBlockResult) { return Some(bytes) } else { return Some(new BlockResult( dataDeserialize(blockId, bytes), DataReadMethod.Memory, info.size)) } case None => logDebug(s"Block $blockId not found in tachyon") } } } // Look for block on disk, potentially storing it back in memory if required // 判断如果持久化级别使用了硬盘持久化 // 尝试从DiskStore中获取数据 if (level.useDisk) { logDebug(s"Getting block $blockId from disk") // 通过DiskStore的getBytes获取数据 val bytes: ByteBuffer = diskStore.getBytes(blockId) match { case Some(b) => b case None => throw new BlockException( blockId, s"Block $blockId not found on disk, though it should be") } assert(0 == bytes.position()) // 如果数据仅仅只是设置了硬盘持久化而没有设置没存持久化存储那么直接将数据封装在BlockResult中返回 if (!level.useMemory) { // If the block shouldn't be stored in memory, we can just return it if (asBlockResult) { return Some(new BlockResult(dataDeserialize(blockId, bytes), DataReadMethod.Disk, info.size)) } else { return Some(bytes) } } else { // Otherwise, we also have to store something in the memory store // 如果数据还设置了内存持久化那么需要将数据通过memoryStore放入内存中 if (!level.deserialized || !asBlockResult) { /* We'll store the bytes in memory if the block's storage level includes * "memory serialized", or if it should be cached as objects in memory * but we only requested its serialized bytes. */ val copyForMemory = ByteBuffer.allocate(bytes.limit) copyForMemory.put(bytes) memoryStore.putBytes(blockId, copyForMemory, level) bytes.rewind() } if (!asBlockResult) { return Some(bytes) } else { val values = dataDeserialize(blockId, bytes) if (level.deserialized) { // Cache the values before returning them val putResult = memoryStore.putIterator( blockId, values, level, returnValues = true, allowPersistToDisk = false) // The put may or may not have succeeded, depending on whether there was enough // space to unroll the block. Either way, the put here should return an iterator. putResult.data match { case Left(it) => return Some(new BlockResult(it, DataReadMethod.Disk, info.size)) case _ => // This only happens if we dropped the values back to disk (which is never) throw new SparkException("Memory store did not return an iterator!") } } else { return Some(new BlockResult(values, DataReadMethod.Disk, info.size)) } } } } } } else { logDebug(s"Block $blockId not registered locally") } None }
代码有点多 , 其实总结下来就两大块 , 从硬盘上获取数据和从内存中获取数据 , 在拿取数据的时候必须是线程安全的 , 防止多个BlockManager来读取同一份数据 ,
首先从内存中获取 , 判断数据是否被内存持久化 , 然后调用MemoryStore的getValues或者getBytes方法获取数据 , 至于调用哪个方法看返回的结果是否为BlockResult ,
而数据若是被硬盘持久化的那么就用DiskStore的getBytes方法获取 , 获取到之后在检查一下是否需要内存持久化 , 是的话还得调用MemoryStore存储在内存中 , 一下是MemoryStore和DiskStore的数据获取方法getVlaues和getBytes :
MemoryStore的:
// MemoryStore中维护的entries map中其实就是真的存放的是每个block的数据了 // 每个block在内存中的数据用MemoryEntry代表 private val entries = new LinkedHashMap[BlockId, MemoryEntry](32, 0.75f, true)
最后其实block的数据其实是存储在一个类型为HashMap的entries成员变量中了
override def getBytes(blockId: BlockId): Option[ByteBuffer] = { // entries也是多线程并发访问同步的 val entry = entries.synchronized { // 尝试从内存中获取block数据 entries.get(blockId) } // 如果没有获取到范湖None if (entry == null) { None // 如果获取到了非序列化的数据 } else if (entry.deserialized) { // 调用BlockManager的数据序列化方法将数据序列化返回 Some(blockManager.dataSerialize(blockId, entry.value.asInstanceOf[Array[Any]].iterator)) } else { // 否则直接返回数据 Some(entry.value.asInstanceOf[ByteBuffer].duplicate()) // Doesn't actually copy the data } } override def getValues(blockId: BlockId): Option[Iterator[Any]] = { val entry = entries.synchronized { entries.get(blockId) } if (entry == null) { None // 如果非序列化直接返回 } else if (entry.deserialized) { Some(entry.value.asInstanceOf[Array[Any]].iterator) // 如果序列化了那么用BlockManager进行反序列化再返回 } else { val buffer = entry.value.asInstanceOf[ByteBuffer].duplicate() // Doesn't actually copy data Some(blockManager.dataDeserialize(blockId, buffer)) } }
DiskStore的:
private def getBytes(file: File, offset: Long, length: Long): Option[ByteBuffer] = { // DiskStore底层使用的是java的nio进行文件的读写操作 val channel = new RandomAccessFile(file, "r").getChannel try { // For small files, directly read rather than memory map if (length < minMemoryMapBytes) { val buf = ByteBuffer.allocate(length.toInt) channel.position(offset) while (buf.remaining() != 0) { if (channel.read(buf) == -1) { throw new IOException("Reached EOF before filling buffer\n" + s"offset=$offset\nfile=${file.getAbsolutePath}\nbuf.remaining=${buf.remaining}") } } buf.flip() Some(buf) } else { Some(channel.map(MapMode.READ_ONLY, offset, length)) } } finally { channel.close() } }
接下来是从别的节点获取数据:
/** * 从别的节点拿取数据 */ private def doGetRemote(blockId: BlockId, asBlockResult: Boolean): Option[Any] = { require(blockId != null, "BlockId is null") // 首先BlockManagerMaster上获取每个blockId对应的BlockManager的信息 // 然后打乱 val locations = Random.shuffle(master.getLocations(blockId)) // 遍历每一个BlockManager for (loc <- locations) { logDebug(s"Getting remote block $blockId from $loc") // 使用BlockTransferService进行异步的远程网络获取 , 将block数据传输回来 // 连接的时候使用的BlockManager的唯一标识,就是host,port,executorId val data = blockTransferService.fetchBlockSync( loc.host, loc.port, loc.executorId, blockId.toString).nioByteBuffer() if (data != null) { if (asBlockResult) { return Some(new BlockResult( dataDeserialize(blockId, data), DataReadMethod.Network, data.limit())) } else { return Some(data) } } logDebug(s"The value of block $blockId is null") } logDebug(s"Block $blockId not found") None }
上面的master.getLocations(blockId)获取到的数据是在BlockManagerMasterActor中的一个成员变量 , 在获取到这些有数据的BlockManagerId之后在进行遍历拉取数据:
// 这个变量存储了一个blockId代表的数据在别的节点上有哪些BlockManager拥有 , 若是做了数据的备份那么本地中一个blockId对应这别的节点上的多个BlockManagerId private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
然后通过blockTransferService的fetchBlockSync异步将数据拉取过来 , 后面再做一些反序列化的操作 , 这就是doGetRemote从远程获取数据 .
那么既然有读数据那么就有写数据 , 有三步骤:
1.写内存不足的处理机制是什么? -> 先将旧的数据硬盘持久化 , 将新的数据放入内存 , 若还是不行的话那么就将新的数据硬盘持久化
2.写完以后汇报BlockManagerMasterActor
3.如果要复用的话随机挑一个BlockManager通过BlockTransferService将数据传输过去
1.写内存不足的处理机制是什么?
先来看看BlockManager中的doPut()方法的部分源码(因为有点多):
// 为需要进行存储的block创建一个BlockInfo对象并放入blockInfo map中 val putBlockInfo = { val tinfo = new BlockInfo(level, tellMaster) // Do atomically ! val oldBlockOpt = blockInfo.putIfAbsent(blockId, tinfo) if (oldBlockOpt.isDefined) { if (oldBlockOpt.get.waitForReady()) { logWarning(s"Block $blockId already exists on this machine; not re-adding it") return updatedBlocks } // TODO: So the block info exists - but previous attempt to load it (?) failed. // What do we do now ? Retry on it ? oldBlockOpt.get } else { tinfo } }
首先创建一个putBlockInfo 函数 , 在函数中创建BlockInfo对象
然后接下来是对putBlockInfo函数进行枷锁操作:
// 尝试对blockInfo枷锁,进行多线程并发访问同步 putBlockInfo.synchronized { logTrace("Put for block %s took %s to get into synchronized block" .format(blockId, Utils.getUsedTimeMs(startTimeMs))) var marked = false try { // returnValues - Whether to return the values put // blockStore - The type of storage to put these values into // 首先根据持久化级别选择一种blockStore,memroyStore,diskStore等 val (returnValues, blockStore: BlockStore) = { if (putLevel.useMemory) { // Put it in memory first, even if it also has useDisk set to true; // We will drop it to disk later if the memory store can't hold it. (true, memoryStore) } else if (putLevel.useOffHeap) { // Use tachyon for off-heap storage (false, tachyonStore) } else if (putLevel.useDisk) { // Don't get back the bytes from put unless we replicate them (putLevel.replication > 1, diskStore) } else { assert(putLevel == StorageLevel.NONE) throw new BlockException( blockId, s"Attempted to put block $blockId without specifying storage level!") } } // Actually put the values // 根据你选择的store , 根据数据的类型将数据放入store中 , 要么是MemoryStore的putBytes要么是DiskStore的putBytes val result = data match { case IteratorValues(iterator) => blockStore.putIterator(blockId, iterator, putLevel, returnValues) case ArrayValues(array) => blockStore.putArray(blockId, array, putLevel, returnValues) case ByteBufferValues(bytes) => bytes.rewind() blockStore.putBytes(blockId, bytes, putLevel) } size = result.size result.data match { case Left (newIterator) if putLevel.useMemory => valuesAfterPut = newIterator case Right (newBytes) => bytesAfterPut = newBytes case _ => } // Keep track of which blocks are dropped from memory if (putLevel.useMemory) { result.droppedBlocks.foreach { updatedBlocks += _ } } // putBlockInfo作为一个函数参数放入getCurrentBlockStatus获取到一个block对应的BlockStatus,putBlockInfo函数的方法会执行 val putBlockStatus = getCurrentBlockStatus(blockId, putBlockInfo) if (putBlockStatus.storageLevel != StorageLevel.NONE) { // Now that the block is in either the memory, tachyon, or disk store, // let other threads read it, and tell the master about it. marked = true putBlockInfo.markReady(size) if (tellMaster) { // 调用reportBlockStatus()方法将新写入的block数据发送到BlockManagerMasterActor以便于进行block元数据的同步和维护 reportBlockStatus(blockId, putBlockInfo, putBlockStatus) } updatedBlocks += ((blockId, putBlockStatus)) } }
加锁的代码中需要根据持久化级别选择存储方式 , 根据不同的存储方式调用MemeoryStore的不同存储方法 , 这里详细看一下存储的具体代码:
MemoryStore中不管是putArray或者是putBytes方法都会调用tryToPut将数据优先放入内存,不行的话则尝试移除部分旧数据再将block存入:
/** * 优先放入内存 , 不行的话尝试移除部分旧数据再讲block存入 */ private def tryToPut( blockId: BlockId, value: Any, size: Long, deserialized: Boolean): ResultWithDroppedBlocks = { /* TODO: Its possible to optimize the locking by locking entries only when selecting blocks * to be dropped. Once the to-be-dropped blocks have been selected, and lock on entries has * been released, it must be ensured that those to-be-dropped blocks are not double counted * for freeing up more space for another block that needs to be put. Only then the actually * dropping of blocks (and writing to disk if necessary) can proceed in parallel. */ var putSuccess = false val droppedBlocks = new ArrayBuffer[(BlockId, BlockStatus)] // 这里必须进行多线程并发同步 // 要是不这样操作的话当你刚判定内存足够放数据的时候但是其它线程也在放那么就OOM了 accountingLock.synchronized { // 调用ensureFreeSpace方法判断内存是否够用,如果不够用此时会将部分数据用dropFromMemory()方法尝试写入磁盘,但是如果持久化不支持磁盘那么数据丢失 val freeSpaceResult = ensureFreeSpace(blockId, size) val enoughFreeSpace = freeSpaceResult.success droppedBlocks ++= freeSpaceResult.droppedBlocks // 将数据写入内存的时候首先调用enoughFreeSpace()方法 , 判断内存是否够放入数据 if (enoughFreeSpace) { val entry = new MemoryEntry(value, size, deserialized) entries.synchronized { entries.put(blockId, entry) currentMemory += size } val valuesOrBytes = if (deserialized) "values" else "bytes" logInfo("Block %s stored as %s in memory (estimated size %s, free %s)".format( blockId, valuesOrBytes, Utils.bytesToString(size), Utils.bytesToString(freeMemory))) putSuccess = true } else { // Tell the block manager that we couldn't put it in memory so that it can drop it to // disk if the block allows disk storage. val data = if (deserialized) { Left(value.asInstanceOf[Array[Any]]) } else { Right(value.asInstanceOf[ByteBuffer].duplicate()) } // 调用dropFromMemory尝试将数据写入磁盘,但是如果block的持久化级别没有说可以写入磁盘那么数据就彻底丢啦 val droppedBlockStatus = blockManager.dropFromMemory(blockId, data) droppedBlockStatus.foreach { status => droppedBlocks += ((blockId, status)) } } } ResultWithDroppedBlocks(putSuccess, droppedBlocks) }
在做数据存入的时候肯定需要判断内存是否够用 , ensureFreeSpace方法就是这个作用 , 源码如下:
blockIdToAdd: BlockId, space: Long): ResultWithDroppedBlocks = { logInfo(s"ensureFreeSpace($space) called with curMem=$currentMemory, maxMem=$maxMemory") val droppedBlocks = new ArrayBuffer[(BlockId, BlockStatus)] if (space > maxMemory) { logInfo(s"Will not store $blockIdToAdd as it is larger than our memory limit") return ResultWithDroppedBlocks(success = false, droppedBlocks) } // Take into account the amount of memory currently occupied by unrolling blocks val actualFreeMemory = freeMemory - currentUnrollMemory // 如果当前内存不足够将这个block放入的话 if (actualFreeMemory < space) { val rddToAdd = getRddId(blockIdToAdd) val selectedBlocks = new ArrayBuffer[BlockId] var selectedMemory = 0L // This is synchronized to ensure that the set of entries is not changed // (because of getValue or getBytes) while traversing the iterator, as that // can lead to exceptions. // 同步entries entries.synchronized { val iterator = entries.entrySet().iterator() // 尝试从entries中移除一部分数据 while (actualFreeMemory + selectedMemory < space && iterator.hasNext) { val pair = iterator.next() val blockId = pair.getKey if (rddToAdd.isEmpty || rddToAdd != getRddId(blockId)) { selectedBlocks += blockId selectedMemory += pair.getValue.size } } } // 判断如果移除一部分数据之后就可以存放新的block了 if (actualFreeMemory + selectedMemory >= space) { logInfo(s"${selectedBlocks.size} blocks selected for dropping") // 将之前选择的要移除的block数据遍历 for (blockId <- selectedBlocks) { val entry = entries.synchronized { entries.get(blockId) } // This should never be null as only one thread should be dropping // blocks and removing entries. However the check is still here for // future safety. if (entry != null) { val data = if (entry.deserialized) { Left(entry.value.asInstanceOf[Array[Any]]) } else { Right(entry.value.asInstanceOf[ByteBuffer].duplicate()) } // 调用dropFromMemory方法将尝试数据写入磁盘 , 但是如果block的持久化级别没有说可以写入磁盘那么这个数据就丢咯 val droppedBlockStatus = blockManager.dropFromMemory(blockId, data) droppedBlockStatus.foreach { status => droppedBlocks += ((blockId, status)) } } } return ResultWithDroppedBlocks(success = true, droppedBlocks) } else { logInfo(s"Will not store $blockIdToAdd as it would require dropping another block " + "from the same RDD") return ResultWithDroppedBlocks(success = false, droppedBlocks) } } ResultWithDroppedBlocks(success = true, droppedBlocks) }
上面在删除一些内存中的老数据时不是真正的删掉 , 而是将数据进行硬盘持久化 , 若是一个block的数据没有设置成硬盘持久化的话那么这份数据就会丢掉
而对于硬盘的数据存储就比较简单了 , 源码如下:
override def putBytes(blockId: BlockId, _bytes: ByteBuffer, level: StorageLevel): PutResult = { // So that we do not modify the input offsets ! // duplicate does not copy buffer, so inexpensive // 使用Java NIO 将数据写入磁盘文件 val bytes = _bytes.duplicate() logDebug(s"Attempting to put block $blockId") val startTime = System.currentTimeMillis val file = diskManager.getFile(blockId) val channel = new FileOutputStream(file).getChannel while (bytes.remaining > 0) { channel.write(bytes) } channel.close() val finishTime = System.currentTimeMillis logDebug("Block %s stored as %s file on disk in %d ms".format( file.getName, Utils.bytesToString(bytes.limit), finishTime - startTime)) PutResult(bytes.limit(), Right(bytes.duplicate())) }
写完数据之后就是报告BlockManagerMasterActor了 , 其实就一行代码:
// 调用reportBlockStatus()方法将新写入的block数据发送到BlockManagerMasterActor以便于进行block元数据的同步和维护reportBlockStatus(blockId, putBlockInfo, putBlockStatus)
可以深入一下reportBlockStatus这个方法 :
private def reportBlockStatus(blockId: BlockId,info: BlockInfo,status: BlockStatus,droppedMemorySize: Long = 0L): Unit = {val needReregister = !tryToReportBlockStatus(blockId, info, status, droppedMemorySize)if (needReregister) {logInfo(s"Got told to re-register updating block $blockId")// Re-registering will report our new block for free.asyncReregister()}logDebug(s"Told master about block $blockId")}/*** Actually send a UpdateBlockInfo message. Returns the master's response,* which will be true if the block was successfully recorded and false if* the slave needs to re-register.*/private def tryToReportBlockStatus(blockId: BlockId,info: BlockInfo,status: BlockStatus,droppedMemorySize: Long = 0L): Boolean = {if (info.tellMaster) {val storageLevel = status.storageLevelval inMemSize = Math.max(status.memSize, droppedMemorySize)val inTachyonSize = status.tachyonSizeval onDiskSize = status.diskSizemaster.updateBlockInfo(blockManagerId, blockId, storageLevel, inMemSize, onDiskSize, inTachyonSize)} else {true}}
可以看出就是拿取master发送一个更新BlockInfo的消息而已 , 而BlockManagerMasterActor获取到这个消息之后就会调用如下的代码:
/*** 更新blockInfo , 即每个BlockManager上的block信息发生变化都会发送updateBlockInfo请求到BlockManagerMaster , 进行BlockInfo的更新*/private def updateBlockInfo(blockManagerId: BlockManagerId,blockId: BlockId,storageLevel: StorageLevel,memSize: Long,diskSize: Long,tachyonSize: Long): Boolean = {if (!blockManagerInfo.contains(blockManagerId)) {if (blockManagerId.isDriver && !isLocal) {// We intentionally do not register the master (except in local mode),// so we should not indicate failure.return true} else {return false}}if (blockId == null) {blockManagerInfo(blockManagerId).updateLastSeenMs()return true}// 调用BlockManager的BlockManagerInfo的updateBlockInfo()方法更新block信息blockManagerInfo(blockManagerId).updateBlockInfo(blockId, storageLevel, memSize, diskSize, tachyonSize)// 每一个blcok可能会在多个BlockManager上面// 如果将StoreageLevel设置成带着 _2 的这种 , 那么就需要将block replicate一份 , 放到其他BlockManager上// 而blockLocations map其实是保存了每个blockId对应的BlcokManagerId的set集合// 所以 这里会更新blockLocations中的信息 , 因为是用set存储BlockManagerId , 因此自动就去重了var locations: mutable.HashSet[BlockManagerId] = nullif (blockLocations.containsKey(blockId)) {locations = blockLocations.get(blockId)} else {locations = new mutable.HashSet[BlockManagerId]blockLocations.put(blockId, locations)}if (storageLevel.isValid) {locations.add(blockManagerId)} else {locations.remove(blockManagerId)}// Remove the block from master tracking if it has been removed on all slaves.if (locations.size == 0) {blockLocations.remove(blockId)}true}
最后第三步 , 需要将设置了备份的block数据传输到别的BlockManager上去存储 :
在duPut操作的方法中最后一步有如下的操作:
// 重要 : 如果我们的持久化级别是定义了_2的这种后缀,说明需要对block进行备份(replica) ,然后传输到其它节点上if (putLevel.replication > 1) {data match {case ByteBufferValues(bytes) =>if (replicationFuture != null) {Await.ready(replicationFuture, Duration.Inf)}case _ =>val remoteStartTime = System.currentTimeMillis// Serialize the block if not already doneif (bytesAfterPut == null) {if (valuesAfterPut == null) {throw new SparkException("Underlying put returned neither an Iterator nor bytes! This shouldn't happen.")}bytesAfterPut = dataSerialize(blockId, valuesAfterPut)}// 调用replicate进行复制操作replicate(blockId, bytesAfterPut, putLevel)logDebug("Put block %s remotely took %s".format(blockId, Utils.getUsedTimeMs(remoteStartTime)))}}BlockManager.dispose(bytesAfterPut)if (putLevel.replication > 1) {logDebug("Putting block %s with replication took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))} else {logDebug("Putting block %s without replication took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))}updatedBlocks
其中replicate方法就是对数据进行备份:
private def replicate(blockId: BlockId, data: ByteBuffer, level: StorageLevel): Unit = {// Get cached list of peerspeersForReplication ++= getPeers(forceFetch = false)def getRandomPeer(): Option[BlockManagerId] = {// If replication had failed, then force update the cached list of peers and remove the peers// that have been already usedif (replicationFailed) {peersForReplication.clear()peersForReplication ++= getPeers(forceFetch = true)peersForReplication --= peersReplicatedTopeersForReplication --= peersFailedToReplicateTo}if (!peersForReplication.isEmpty) {Some(peersForReplication(random.nextInt(peersForReplication.size)))} else {None}}while (!done) {// 随机获取一个其它的BlockManagergetRandomPeer() match {case Some(peer) =>try {val onePeerStartTime = System.currentTimeMillisdata.rewind()logTrace(s"Trying to replicate $blockId of ${data.limit()} bytes to $peer")// 使用BlockTransferService将数据异步写入其他的BlockManager上blockTransferService.uploadBlockSync(peer.host, peer.port, peer.executorId, blockId, new NioManagedBuffer(data), tLevel)logTrace(s"Replicated $blockId of ${data.limit()} bytes to $peer in %s ms".format(System.currentTimeMillis - onePeerStartTime))peersReplicatedTo += peerpeersForReplication -= peerreplicationFailed = falseif (peersReplicatedTo.size == numPeersToReplicateTo) {done = true // specified number of peers have been replicated to}} catch {case e: Exception =>logWarning(s"Failed to replicate $blockId to $peer, failure #$failures", e)failures += 1replicationFailed = truepeersFailedToReplicateTo += peerif (failures > maxReplicationFailures) { // too many failures in replcating to peersdone = true}}case None => // no peer left to replicate todone = true}}}
随机获取一个BlockManagerId然后通过BlockTransferService将数据写入到其它的BlockManager上去 ,















 2417
2417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









