



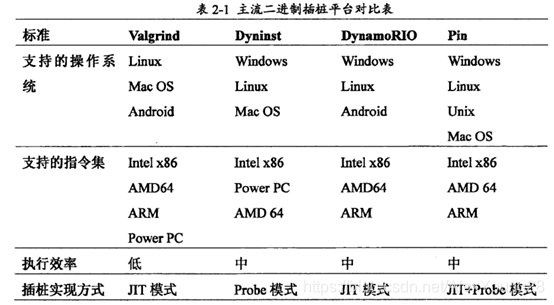
DynamoRIO:
设计架构:
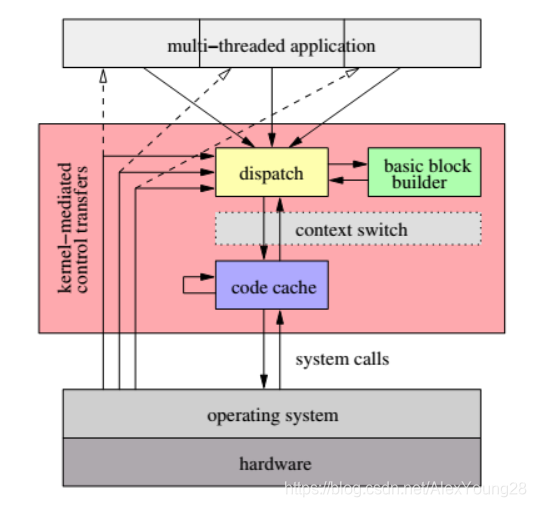
组件运转流程:
DynamoRIO框架在操作系统和应用程序之间,构成一个中间层。在该中间层中DynamoRIO将CPU的寄存器做一份完整的镜像,并以此为被测程序构造出一份虚拟的上下文。在DynamoRIO框架下运行着的程序都会使用这份模拟出来的运行时上下文,同时通过DynamoRIO中的上下文切换模块代码即被投入运行之前在真实的宿主机上恢复出原本被虚拟的上下文。
DynamoRIO的内核由三个模块组成:调度器(Dispatch)、基本块构建器(Basic block builder)和代码缓存器(Code cache)。其中基本块构建器负责从被测程序中切分出基本块并完成插桩,代码缓存器负责缓存并管理已经插桩完毕的基本块,最后由调度器来截获被测程序的指令,完成内存事件的分发并协调各个模块之间的工作。
性能提升策略:
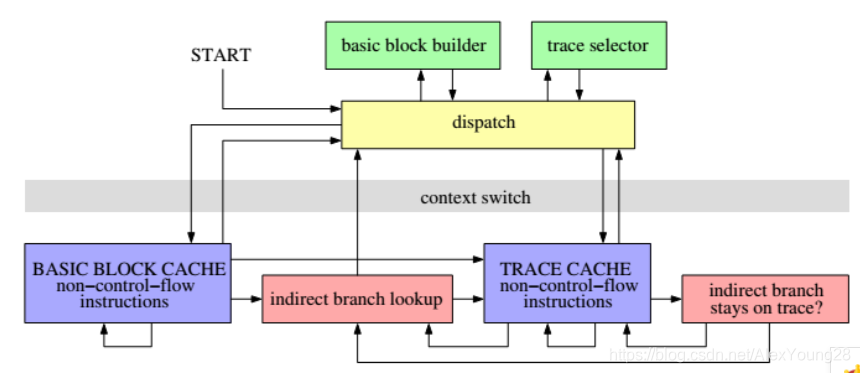
1. 指令缓存(Code cache)
DynamoRIO是一个进程级别的emulation软件,在应用和操作系统之间工作。通过code cache、linking和trace building可以提高emulation的效率。
DynamoRIO运行的代码和应用程序本身的代码,通过context switch分开。应用程序的代码被拷贝到指令缓存中,并像原生代码一样执行。当遇到一个跳转指令时,应用的machine state会被保存,控制转回到DynamoRIO,去寻找跳转指令所在的basic block。
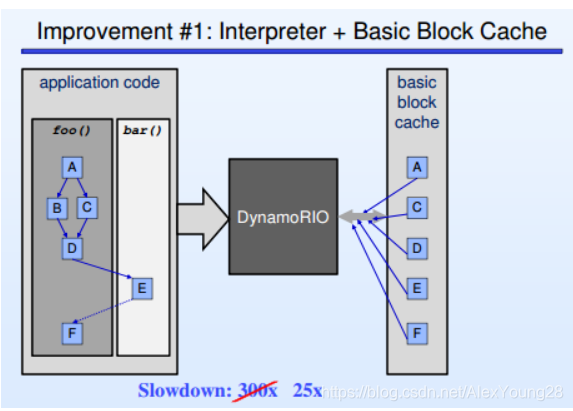
纯粹的emulation比原生代码执行慢大概300倍,DynamoRIO引进的code cache机制,可以把负荷降低到25倍左右:
1.1 基本块(Basic block)
DynamoRIO的basic block和编译器产生的basic block不太一样,因为DynamoRIO工作在运行时,考虑效率,没有对代码进行太多分析。所以与编译器对代码进行分析后产生的基本块可能有区别。
1.2 链接(Linking)
把每个basic block都拷贝到一个code cache中,进行原生运行,减少解释运行的开销。但是,需要对跳转指令进行解释,再返回到DynamoRIO去寻找这个目标指令。
(1) 直接链接
如果跳转的目标指令已经存在于code cache中,而且被直接跳转指令所指,DynamoRIO可以直接调准到code cache中的目标指令,避免context switch开销。
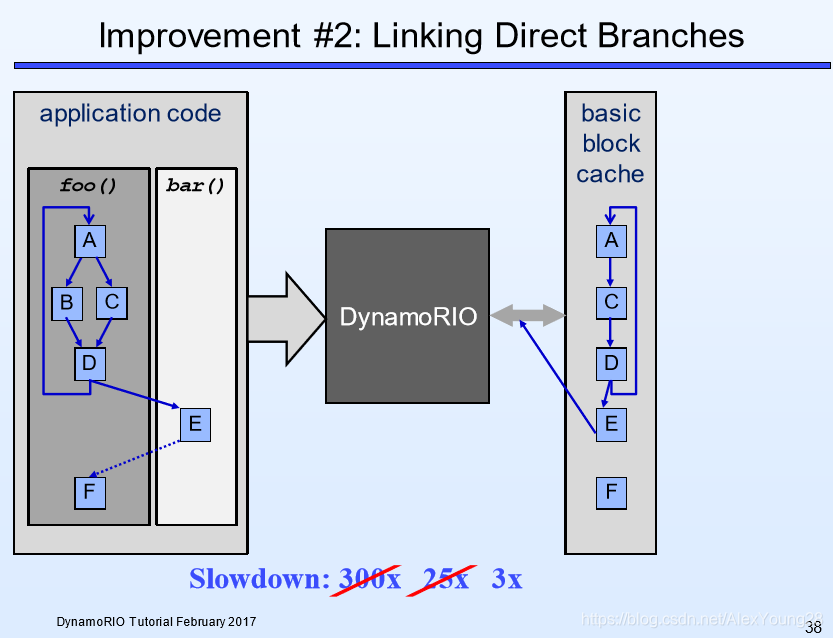
(2) 间接链接
条件转移指令无法像直接跳转指令使用直接链接,因为其目标不止一个。需要进行判断并查找队形的跳转目标。

1.3 执行流(Traces)
一些经常顺序执行的basic blocks被组合到一个执行流中,以减少分支提高程序的局部性。避免对间接跳转的查找,因为把间接跳转的目标放到了trace里。

功能:
DynamoRIO能同时覆盖函数级和指令级的插桩粒度,同时在框架内部实现一个完善的事件循环。在DynamoRIO的事件循环系统中,能捕获的事件种类非常丰富,包括信号接收、内存分配、每一条二进制指令的执行、新的动态链接库的载入等。分析程序的开发者能够通过DynamoRIO提供的API来捕获这些事件并设定好相应的回调函数。
性能:
根据官方文档说明,DynamoRIO在速度上比Pin更具有优势。
参考:
原理:https://blog.csdn.net/gengzhikui1992/article/details/50790553
配置:https://blog.csdn.net/woswod/article/details/89556676
实例:https://www.anquanke.com/post/id/169257
论文实例:何磊. 基于二进制指令插桩的C++程序缺陷检测技术的研究与实现[D].北京邮电大学,2017.
Valgrind
原理:
Valgrind主要由内核和工具构成,内核负责底层的二进制代码分析和JIT编译等工作,而工具则负责编写具体的插桩逻辑。在Valgrind中,所有的机器码,包括探针代码,都会被翻译成一种统一的中间指令,这种中间指令在Valgrind中被称为IR。IR是一种介于髙级语言和机器码之间的语言,IR使用Valgrind虚拟机中模拟的虚拟寄存器,并且与平台无关。
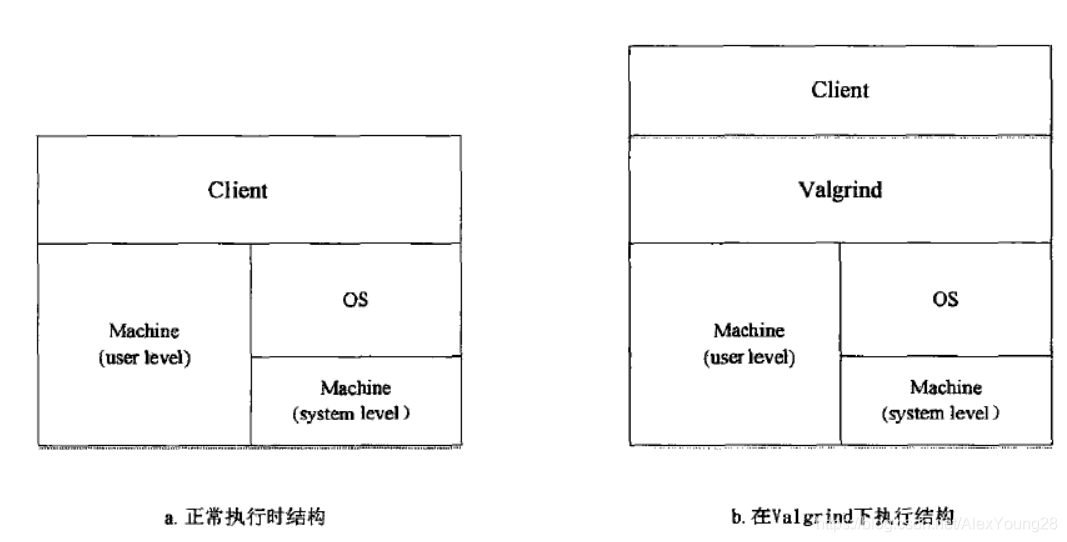
在执行翻译时,一条二进制机器码可能被翻译成多条IR。使用IR的好处是可以将插粧代码和被测程序的代码作统一的优化处理,并且能够使得框架可以更方便的在各个系统之间进行移植。Valgrind在实现操作系统API时也采取和Pin—样的手段,先将虚拟机中的保存的被测程序的上下文复制到实际的宿主机上,并在相应的系统API调用结束之后恢复之前的运行时上下文。值得注意的是,为了尽可能保持被测程序原来的运行逻辑,不让Valgrind使用的运行库和被测程序的运行库产生冲突,Valgrind本身不使用任何动态链接库,所有必要的库函数均有Valgrind重新实现并且静态链接到可执行文件中,从根本上消除了和被测程序发生动态链接库冲突的可能性。Valgrind执行检测的过程可以分为以下几步:
1. 初始化,启动器读取并分析指令,根据具体的系统启动正确的工具文件。
2. 读取机器码并进行反汇编,将机器码翻译成IR,并对IR进行第一次优化,包括展开复杂指令,消除冗余,死代码消除等。
3. 对IR进行插粧,在反汇编之后的IR指令中插入指定的探针,并再次进行指令优化。
4. 对IR指令进行寄存器分配,将虚拟的寄存器映射到实际的主机上去,最后根据宿主机的指令集对IR进行汇编,至此,代码块已经被插桩完毕并且可以直接在真实的硬件环境中运行。
5. 将翻译插桩完毕的代码交由调度器(Dispatcher)进行调度运行。调度器还负责对己经翻译完毕的代码块进行缓存,以提高程序的运行速度。
应用程序在Valgrind框架下的执行结构:
性能:
Valgrind号称“重量级”的分析框架,在加载空插件运行时,Valgrind的执行时间是原程序执行时间的4倍左右,而同样加载空插件时,Pin的执行时间是原程序执行时间1.2倍,由于有效的优化,DynamoRIO的执行时间是原程序执行时间的1.1倍。然而,由于所有的分析都需要进行统一的中间语言VEX的转化,基于Valgrind的分析系统可以在不同的操作系统和指令集基础上进行工作,例如Linux操作系统、Mac操作系统和ARM、Intel、AMD指令集,并且由于其细粒度的分析,其分析是非常精确的。为此,Valgrind作为动态插桩的框架也是有极其广阔的应用场景
参考:
原理:https://blog.mengy.org/how-valgrind-work/
实例:http://www.voidcn.com/article/p-tvljnlzf-hx.html
论文:李政宇. 基于混合执行的二进制程序模糊测试关键技术研究[D].北京邮电大学,2017.
Dyninst
原理:
为了实现灵活、高效的动态二进制代码修改,Dyninst 引入以下基本概念:
- point 与 snippet。Point 是在程序运行过程中允许 插入监控代码的位置, 可以是函数/子程序的入口点、出口 点,特定代码块的起始、终止点等。Snippet 则是在某 point 处插入的可执行代码。Snippet可以包含所有的正常指令流,如条件、循环、函数调用等。
- thread 与 image。Thread 代表一个运行的线程(根 据实际系统实现, thread 可以是实际的进程, 也可以是轻量 级线程) , 而 image 是程序的静态实例。
- mutator 与 mutatee。M utator 是基于 Dyninst API 实现的用于对特定应用程序二进制代码进行修改的工具程 序。Mutatee 则是被 mutator 动态修改的目标应用程序。 Mutator 通过调用 Dyninst API 动态创建 snippet, 插入到 mutatee 程序相应的 point 处, 实现对 mutatee 程序的动态 修改。

如图为Dyninst抽象图,左侧是mutator程序其中包含了 Dyninst API 调用代码、动态生成 snippet 代码的运行时编译器以及用于操纵目标进程的工具代码等。Dyninst基于 ptrace和procf系统调用实现对mutatee 目标进程的执行控制和代码修改。右侧是 mutatee 进程,其中包含原始代码、被插入的 snippet 代码和相应的运行库码等Dyninst API 提供了一个类型系统可以支持整数、浮点数、字符串等简单数据类型和数组、结构等复杂数据结构。此外,Dyninst 还允许对目标程序中定义的数据类型进行操作。Dyninst API允许对目标应用程序的事件加以响应。 目标应用程序事件一般分为两类: 被插入代码引发的事件和目标程序正常执行引发的事件。Dyninst API 允许在插入监控代码时注册特定事件的回调函数, 在相关事件发生时调用回调函数进行处理。
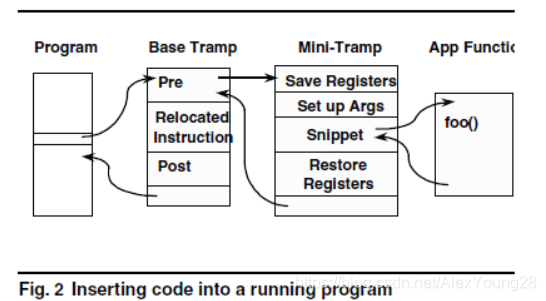
Dyninst使用code patching,可以用同一个接口支持静态和动态的插桩分析。首先,对于一个二进制image,Dyninst找到用户指定的插入点,然后把插入点的一条或几条指令替换成一个跳转指令,这个跳转指令指向一个Base Trampoline(蹦床),这个base trampoline包含有被替换的指令以及跳转到Mini Trampoline的指令。Mini Trampoline会保存/恢复当前的状态,并且执行相应的插入代码(Snippet)。
性能:
尽管 Dyninst 即可以支持静态插桩,也支持动态插桩,但目前并不能直接应用于采用混淆或加壳的代码。这是由于 Dyninst 的代码识别仅仅是基于静态分析,只能对程序中静态可分析的代码进行插桩,不支持对动态生成或重写的代码进行插桩。目前支持对程序中动态生成或重写代码插桩的平台大都是在程序执行过程中进行的,如 Valgrind、PIN 或Qemu 等。但这些工具对动态代码的插桩都是基于指令特征的,这直接导致在分析过程中会有大量冗余的插桩,从而增大分析的开销。
基于程序结构的动态插桩是在 Dyninst 的基础上,通过静态控制流分析获取程序的控制结构,在其中的某些控制转移点(动态捕获的位置)进行插桩操作。通过将静态控制流分析与动态插桩相结合,使得系统具备了插桩动态生成或重写代码的能力。
参考:
原理:https://blog.csdn.net/u010838822/article/details/14094287
实例:https://blog.csdn.net/ldzm_edu/article/details/65444800
论文实例:
蒋杰,徐涵,刘杰,杨灿群,胡庆丰.基于运行时代码修改的动态性能监控关键技术研究[J].计算机工程与科学,2009,31(S1):150-152+209.
刘建林. 可执行程序隐藏代码逆向分析技术研究[D].解放军信息工程大学,2011.
基于QEMU的动态二进制插桩技术
原理:
QEMU可进行应用级软件仿真和系统级软件仿真.进行系统级软件仿真时,QEMU提供包括处理器、存储器、总线以及中断控制器、MMU(memory management unit)、FPU(float point unit)以及其他外设的全系统仿真,可以不作修改运行任何客户机系统软件.QEM主要包含2方面任务:1)执行调度;2)动态二进制翻译.仿真执行时,QEMU判断当前PC(program counter)对应基本翻译块(translate block, TB)是否已经在TB Cache中,如果不在TB Cache中,则进行动态二进制翻译;否则,执行该基本翻译块的宿主机指令.当执行到未翻译的客户机指令序列时,则表明当前PC对应基本块的开始,QEMU产生基本翻译块,开始进行动态二进制翻译.动态二进制翻译包含翻译前端和翻译后端2个阶段,完成客户机指令序列到宿主机指令序列的语义等效转换.第1阶段,函数gen_intermediate_code读取客户机指令序列进行反汇编产生中间码(intermediate code).在一些学者的研究中,中间码或称为中间表示,或称为虚拟指令集.在这1阶段,跳转指令确定了基本翻译块的边界.第2阶段,函数tcg_gen_code遍历中间码,将中间码转换成宿主机指令,保存翻译块并加入TB Cache.
QEMU的动态翻译仿真执行流程,与Pin,Valgrind,DynamoRIO等工具的动态插桩过程十分类似.然而,Pin,Valgrind,DynamoRIO等不支持系统级程序的仿真执行,也不支持交叉动态二进制翻译.所谓交叉动态二进制翻译,即原二进制程序同翻译后的二进制程序体系结构不同.PinOS是一个通过Pin开发的全系统的插桩工具,但其仅能用于Linux架构,不支持嵌入式系统.而QEMU全系统仿真时完全掌握系统运行流程和仿真环境状态.因此,可以对其进行深度修改,使其具有二进制插桩功能,解决嵌入式全系统的软件动态分析的难题.而要使QEMU具有二进制插桩功能,必须解决3个问题:
1) 流程嵌入,即如何将插桩过程附加到QEMU仿真执行过程;
2) 桩点选择,即在基本块中如何选择决策探针插入位置;
3) 探针内容,即在探针中如何收集以及收集哪些客户机信息来满足插桩日志分析工具设计
使用QEMU实现二进制动态插桩,仅为一篇论文的设计思想,
参考论文为:
邹伟,高峰,颜运强.基于QEMU的动态二进制插桩技术[J].计算机研究与发展,2019,56(04):730-741.

















 2495
2495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









