







Spark on Yarn Executor Cores、Nums、Memory优化配置
三方面内容:executor 核心数目,executor 数量,executor 内存。对于driver memory 这个参数,设置比较灵活,一般1-8,这里不就不多说
设置以上三个参数,除了计算集群的节点数、节点Cores和内存大小外,还需要考虑以下四点因素:
spark使用yarn做资源管理,yarn后台使用一些守护进程中运行的,如NameNode,Secondary NameNode,DataNode,JobTracker和TaskTracker,因此在设置num-executors,需为每个节点预留1个core来保证这些守护进程平稳地运行。
Yarn ApplicationMaster(AM):
AM负责从ResourceManager申请资源,与NodeManager进行通信启动/停止任务,监控资源的使用。在Yarn上执行Spark也要考虑AM所需资源(1G和1个Executor)。
HDFS Throughput:
HDFS Client有多个并发线程写的问题,HDFS每个Executor的使用5个任务就可获取完全并发写。因此最好每个Executor的cores不高于5.
MemoryOverhead:
下面图片展示 spark-yarn-memory-usage
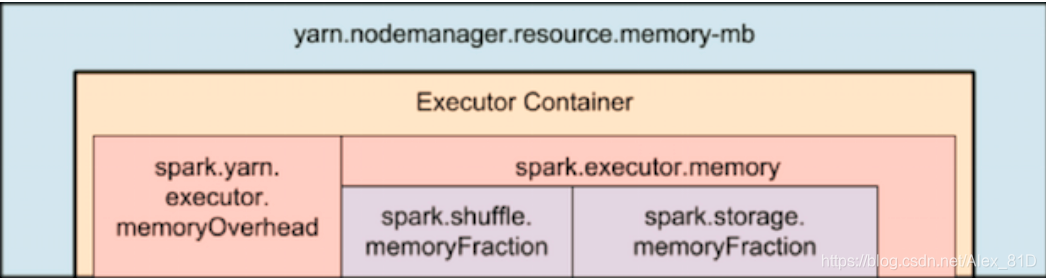
每个executor需要内存=spark-executor-memory+spark.yarm.executor.memoryOverhead
spark.yarm.executor.memoryOverhead=Max(384m,7%*spark.executor.memory)即大于等于384M
如果我们为每个executor申请20GB资源,实际上AM获取的资源20GB+7%*20GB=~23GB。
案例:3个节点,每个节点 8 核 + 32 GB RAM(都是真集群,1主三从)
由于每个 executor 都是一个 JVM 实例,所以我们可以给每个节点分配多个 executor。
前期准备:为系统的运行保留资源
文章原文的内容是:为了保证操作系统和 hadoop 进程的运行,每个节点要预留 1 个核心 + 1 GB 内存。所以每个节点可用的资源为:7 个核心 + 30 GB RAM。
但是如果你不希望你的系统陷入高负载的情况,你可以多预留一些资源,我个人的使用经验是每个节点预留 4 个核心 + 4 GB 内存。这块我以 6 个核心 + 28 GB (好计算)
1.确定每个 executor 的核心数量——“magic number”
executor 核心数量 = executor 能并发执行的任务(task)数量 ,研究表明,不是给 executor 分配越多的核心越好,任何一个 application 分配的核心数目超过 5 个只会导致性能下降,所以我们一般把 executor 核心数量设置为 5 及 5 以下的数字。在接下来的案例讲解中我们把核心数目设置为 3。
2.设置 executor 数量
每个节点的 executor 数量 = 6(每个节点的总核心数量) / 3(每个executor 的核心数量) = 2,
所以总的 executor 数量为 2(前面算的2) * 3(3个节点) = 6,由于 YARN 的 ApplicationMaster 需要占用一个 executor,所以我们设置的 executor 数量为 6 - 1 = 5。
注意:单次提交任务至少需要2核,即一个executor和一个driver(本质是也是executor)
3.设置 executor 分配的内存大小
在之前的步骤中,我们给每个节点分配了 2个 executor,每个节点可用的 RAM 是 28GB,所以每个 executor 的内存为 28 / 2 = 14 GB。
但是 spark 在向 YARN 申请内存时,YARN 会给每个 executor 多分配大小为 overhead 的内存,而 overhead = max(384 MB, 0.07 * spark.executor.memory)。
在我们的案例中 overhead = 0.07 * 14 = 0.98 GB > 384 MB,所以我们申请的内存大小为 14 - 0.98 ~ 13 GB。
driver:内存(1~13G)
最终我们得到的分配方案是:每个 executor 分配 3 个核心,设置 5 个 executor, 每个 executor 分配的内存为 13 GB。写成 spark-submit 命令为:
spark-submit
--master yarn
--num-executors 3
--executor-memory 13
--executor-cores 3 (这个代表每个executor核个数)
这个只提供一个计算方式,并不代表是最优的,可以自行进行计算

注意:driver:内存(1~13G),这个需要注意一下,我们需要先设置container的参数大小,否则会报错,具体看下面
扩展:理解2个配置项详解:
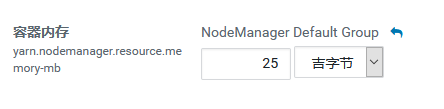
yarn.nodemanager.resource.memory-mb
从这个参数开始,我们来看 NodeManager 的配置项。这个参数其实是设置 NodeManager 预备从本机申请多少内存量的,用于所有 Container 的分配及计算。这个参数相当于一个阈值,限制了 NodeManager 能够使用的服务器的最大内存量,以防止 NodeManager 过度消耗系统内存,导致最终服务器宕机。这个值可以根据实际服务器的配置及使用,适度调整大小。
比如上面的那个算法:我们为 NodeManager 分配了 28GB 的内存。
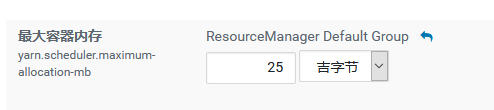
yarn.scheduler.maximum-allocation-mb
单个容器(container)可申请的最大内存资源,应用在运行时申请的内存不能超过这个配置项值,因为这个配置项是指定一个container最大的内存,实际分配内存时并不是按照这个配置项分配,所以这个配置项可以配置成和nodemanager的可用内存(yarn.nodemanager.resource.memory-mb)一样即可,这样的话,意味着只要这个节点的nodemanager可用内存哪怕只够跑一个container,这个container也是可以启动的。
参考链接:
https://blog.csdn.net/wx6gml18/article/details/111433509


















 4485
4485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











