







目录
10. filtered: 某个表经过搜索条件过滤后剩余记录条数的百分比
上篇,我们已经讲到EXPLAIN输出语句中 Key_len的含义,接着上篇,我们继续讨论:
8、ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。当使用索引列等值匹配的条件去执行查询时,也就是在访问方法是const、 eq_ref、ref、ref_or_nul1.unique_subquery、index_subquery其中之一时,ref列展示的就是与索引列作等值匹配的结构是什么,比如只是一个常数或者是某个列。大家看下边这个查询:
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
可以看到 ref 列的值是 const,表明在使用idx_key1 索引执行查询时,与key1列作等值匹配的对象是一个常数
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;
带函数的情况
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s2.key1 = UPPER(s1.key1); 
9. rows:预估的需要读取的记录条数
`值越小越好`
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z'; 
预估会读取 到405条记录,filtered =100 表示 百分百符合要求
所以,最终经过搜索,结果真的找到了 405行记录
![]()
10. filtered: 某个表经过搜索条件过滤后剩余记录条数的百分比
#如果使用的是索引执行的单表扫描,那么计算时需要估计出满足除使用
到对应索引的搜索条件外的其他搜索条件的记录有多少条。
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND common_field = 'a';对于单表查询来说,这个filtered列的值没什么意义,我们`更关注在连接查询
中驱动表对应的执行计划记录的filtered值`,它决定了被驱动表要执行的次数(即:rows * filtered)
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.key1 = s2.key1 WHERE s1.common_field = 'a';根据驱动表的定义,s1 是驱动表(带where条件)

从执行计划中可以看出来,查询优化器打算把 s1 当作驱动表,s2 当作被驱动表。我们可以看到驱动表 s1 表的执行计划的 rows 列为 9688,filtered列为 10.80,这意味着驱动表 s1 的扇出值就是9895 x 10.80% =989.5,这说明还要对被驱动表执行大约 989次查询。
11.Extra (重要)
顾名思义,Extra 列是用来说明一些额外信息的,包含不适合在其他列中显示但十分重要的额外信息。我们可以通过这些额外信息来 更准确的理解MySQL到底将如何执行给定的查询语句。MySOL提供的额外信息有好几十个,我们就不一个一个介绍了,所以我们只挑比较重要的额外信息介绍给大家
No tables used
当查询语句的没有 FROM子句时将会提示该额外信息,比如:
EXPLAIN SELECT 1;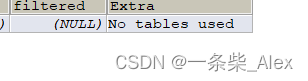
Impossible WHERE
#查询语句的`WHERE`子句永远为`FALSE`时将会提示该额外信息
EXPLAIN SELECT * FROM s1 WHERE 1 != 1;
Using Where
#当我们使用全表扫描来执行对某个表的查询,并且该语句的`WHERE`子句中有针对该表的搜索条件时,在`Extra`列中会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE common_field = 'a';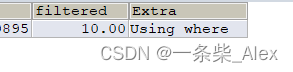
#当使用索引访问来执行对某个表的查询,并且该语句的`WHERE`子句中有除了该索引包含的列之外的其他搜索条件时,在`Extra`列中也会提示上述额外信息。
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' AND common_field = 'a';
No matching min/max row
#当查询列表处有`MIN`或者`MAX`聚合函数,但是并没有符合`WHERE`子句中的搜索条件的记录时,将会提示该额外信息
EXPLAIN SELECT MIN(key1) FROM s1 WHERE key1 = 'abcdefg';
Select tables optimized away
EXPLAIN SELECT MIN(key1) FROM s1 WHERE key1 = 'aAAaCJ'; #aAAaCJ是 s1表中key1字段真实存在的数据
Using index
当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以
使用覆盖索引的情况下,在`Extra`列将会提示该额外信息。比方说下边这个查询中只
需要用到`idx_key1`而不需要回表操作:(id是主键,在二级索引里有记录,不需要回表操作)(覆盖索引)
EXPLAIN SELECT key1,id FROM s1 WHERE key1 = 'a';
Using index condition
有些搜索条件中虽然出现了索引列,但却不能使用到索引(索引条件下推)
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';其中的 key1>'z'可以使用到索引,但是 key1 LIKE%a'却无法使用到索引,在以前版本的MySQL中是按照下边步骤来执行这个查询的:
- 先根据key1>z这个条件,从二级索引idx_key1 中获取到对应的二级索引记录
- 根据上一步骤得到的二级索引记录中的主键值进行 回表,找到完整的用户记录再检测该记录是否符合key1 LIKE%a 这个条件,将符合条件的记录加入到最后的结果集。
但是虽然 key1 LIKE%a不能组成范围区间参与 range 访问方法的执行,但这个条件毕竟只涉及到了key1列,所以MySQL把上边的步骤改进了一下:
。先根据key1 >z'这个条件,定位到二级索引idx_key1 中对应的二级索引记录。
对于指定的二级索引记录,先不着急回表,而是先检测一下该记录是否满足 key1 LIKE%a这个条件如果这个条件不满足,则该二级索引记录压根儿就没必要回表
。对于满足 key1 LIKE%a 这个条件的二级索引记录执行回表操作
我们说回表操作其实是一个随机I0,比较耗时,所以上述修改虽然只改进了一点点,但是可以省去好多回表操作的成本。IMySQL把他们的这个改进称之为索引条件下推 (英文名: Index Condition Pushdown)。如果在查询语句的执行过程中将要使用索引条件下推 这个特性,在Extra列中将会显示Using indexcondition,比如这样:

Using Join buffer
在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫`join buffer`的内存块来加快查询速度,也就是我们所讲的`基于块的嵌套循环算法`
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.common_field = s2.common_field;
Not exists
当我们使用左(外)连接时,如果`WHERE`子句中包含要求被驱动表的某个列等于`NULL`值的搜索条件,
而且那个列又是不允许存储`NULL`值的,那么在该表的执行计划的Extra列就会提示`Not exists`额外信息
EXPLAIN SELECT * FROM s1 LEFT JOIN s2 ON s1.key1 = s2.key1 WHERE s2.id IS NULL;
Using Uniou
如果执行计划的`Extra`列出现了`Using intersect(...)`提示,说明准备使用`Intersect`索引
#合并的方式执行查询,括号中的`...`表示需要进行索引合并的索引名称;
#如果出现了`Using union(...)`提示,说明准备使用`Union`索引合并的方式执行查询;
#出现了`Using sort_union(...)`提示,说明准备使用`Sort-Union`索引合并的方式执行查询。
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' OR key3 = 'a';
Zero limit
#当我们的`LIMIT`子句的参数为`0`时,表示压根儿不打算从表中读出任何记录,将会提示该额外信息
EXPLAIN SELECT * FROM s1 LIMIT 0;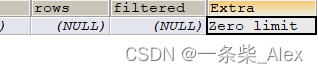
Using filesort
#有一些情况下对结果集中的记录进行排序是可以使用到索引的。
EXPLAIN SELECT * FROM s1 ORDER BY key1 LIMIT 10;
这个查询语句可以利用 idx_key1 索引直接取出 key1 列的10条记录,然后再进行回表操作就好了。但是很多情况下排序操作无法使用到索引,只能在内存中(记录较少的时候)或者磁盘中(记录较多的时候)进行排序,MySOL把这种在内存中或者磁盘上进行排序的方式统称为文件排序(英文名: filesort)。如果某个查询需要使用文件排序的方式执行查询,就会在执行计划的Extra列中显示Using filesort 提示,比如这样:
EXPLAIN SELECT * FROM s1 ORDER BY common_field LIMIT 10;
Using temporary
在许多查询的执行过程中,MySQL可能会借助临时表来完成一些功能,比如去重、排序之类的,比如我们
在执行许多包含`DISTINCT`、`GROUP BY`、`UNION`等子句的查询过程中,如果不能有效利用索引来完成
查询,MySQL很有可能寻求通过建立内部的临时表来执行查询。如果查询中使用到了内部的临时表,在执行
计划的`Extra`列将会显示`Using temporary`提示
EXPLAIN SELECT DISTINCT common_field FROM s1;

Key1字段 存在索引
EXPLAIN SELECT DISTINCT key1 FROM s1;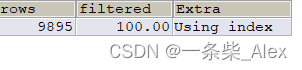
分组
#同上。
EXPLAIN SELECT common_field, COUNT(*) AS amount FROM s1 GROUP BY common_field;执行计划中出现`Using temporary`并不是一个好的征兆,因为建立与维护临时表要付出很大成本的,所以
我们`最好能使用索引来替代掉使用临时表`。比如:扫描指定的索引idx_key1即可
EXPLAIN SELECT key1, COUNT(*) AS amount FROM s1 GROUP BY key1;12. 小结
EXPLAIN不考虑各种Cache
EXPLAIN不能显示MySQL在执行查询时所作的优化工作
EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
部分统计信息是估算的,并非精确值















 6218
6218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









