







C语言第三讲
基本数据结构
栈
在栈(stack)中,被删除的是最近插入的元素:
栈实现的是一种后进先出策略(而队列则是先进先出)
栈上insert操作称为压入(push),而无元素参数的delete操作称为弹出(pop)。
餐馆里的一摞盘子,“弹出”的顺序和压入的顺序相反,因为只有最上面的盘子才能够被取下来。
堆
算法
算法(Algorithm)是规则的有限集合,是为解决特定问题而规定的一系列操作。
算法设计的目标是正确、可读、健壮、高效、低耗
正确
- 对于几组输入数据能够得出满足结果的要求
- 对于精心选择的典型、苛刻的输入数据能够得出满足要求的结果
- 对于一切合法的输入数据都能够产生满足要求的结果
一般情况下,至少应以第二层含义的正确性作为衡量一个算法是否正确的标准。
//求n个数的最大值问题,给出核心处理的示意算法
max=0;
for(i=1;i<n;i++){
scanf("%f",&x);
if(x>max)
max=x;
}
显然,当n个数全为负时,最大值max为0 ,这个算法的正确性是不够标准的
可读
鲁棒性
对非法输入的抵抗能力,即使输入非法数据,也能够识别并加以处理。
高效率、低储存量
一个算法的执行时间是指算法中所有语句执行时间的总和。
每条语句的执行时间等于该条语句的执行次数乘以执行一次所需实际时间。
语句频度是指该语句在一个算法中重复执行的次数,一个算法的时间耗费就是该算法中所有语句频度之和。
算法中语句总的执行次数 f ( n ) f(n) f(n)是问题规模n的函数
T ( n ) = O ( f ( n ) ) T(n)=O(f(n)) T(n)=O(f(n)),其中 O O O是数量级
它表示随问题规模n的宏大,算法的执行时间的增长率和 f ( n ) f(n) f(n)的增长率相同,称作算法的渐进时间复杂度,简称时间复杂度
常数阶
m=i;
i=j;
j=temp;
该程序段的执行时间是一个与问题规模n无关的常数。
T
(
n
)
=
O
(
1
)
T(n)=O(1)
T(n)=O(1)
线性阶
for(i=1;1<=n;1++)
x=x+1;
其时间复杂度为 O ( n ) O(n) O(n)
for (i=1;1<=n;i++){
for(j=1;j<=n;j++){
y++;
}
}
其时间复杂度为 O ( n 2 ) O(n^2) O(n2)
模拟
超级玛丽
模拟的过程就是对真实场景尽可能的模拟,然后通过计算机强大的计算能力对结果进行预测。

题解:
https://www.luogu.com.cn/problem/solution/P1000
#include<stdio.h>
int main() {
printf(
" ********\n"
" ************\n"
" ####....#.\n"
" #..###.....##....\n"
" ###.......###### ### ###\n"
" ........... #...# #...#\n"
" ##*####### #.#.# #.#.#\n"
" ####*******###### #.#.# #.#.#\n"
" ...#***.****.*###.... #...# #...#\n"
" ....**********##..... ### ###\n"
" ....**** *****....\n"
" #### ####\n"
" ###### ######\n"
"##############################################################\n"
"#...#......#.##...#......#.##...#......#.##------------------#\n"
"###########################################------------------#\n"
"#..#....#....##..#....#....##..#....#....#####################\n"
"########################################## #----------#\n"
"#.....#......##.....#......##.....#......# #----------#\n"
"########################################## #----------#\n"
"#.#..#....#..##.#..#....#..##.#..#....#..# #----------#\n"
"########################################## ############\n"
);
return 0;
}
多项式输出

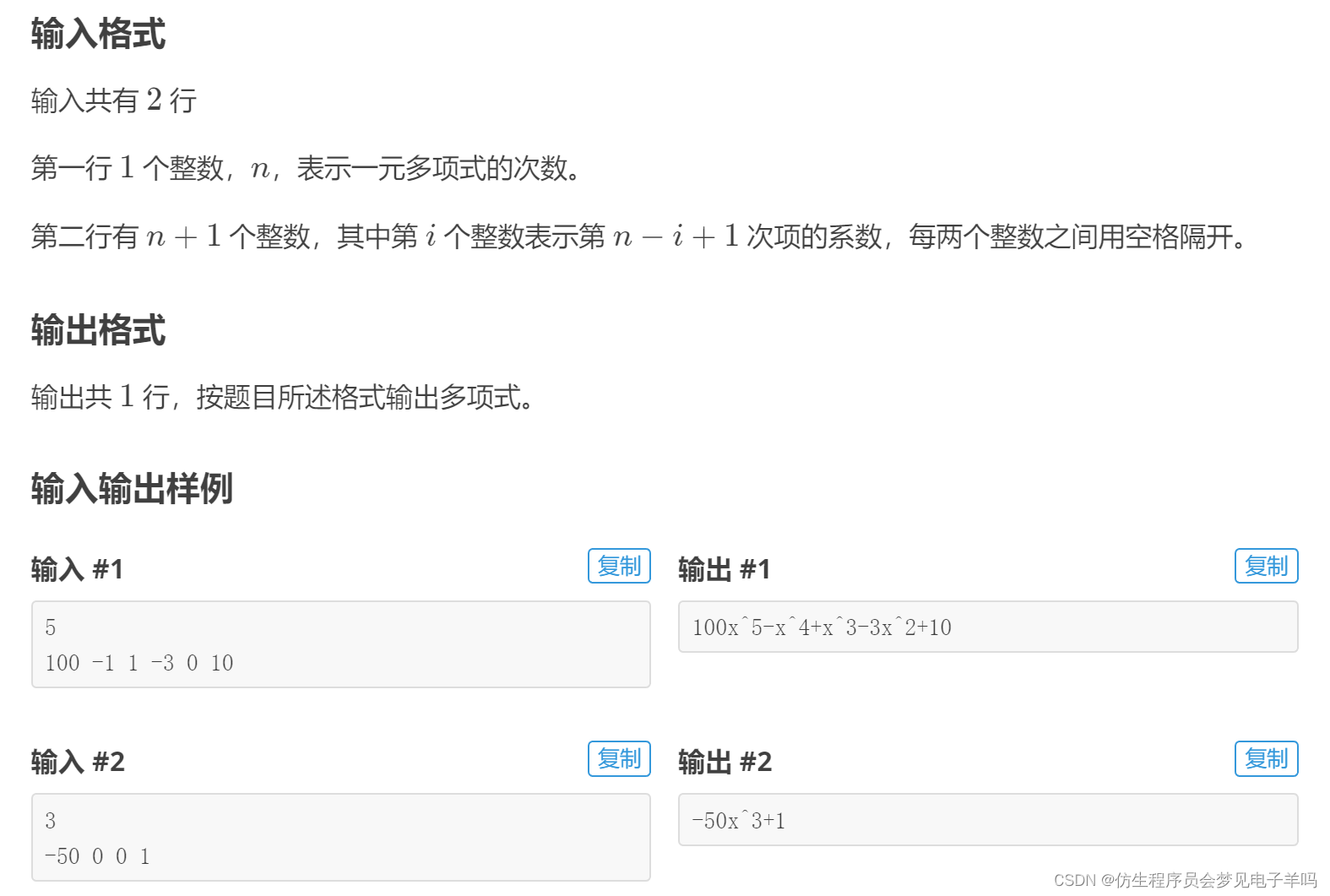
题解:
https://www.luogu.com.cn/problem/solution/P1067
枚举
三连击
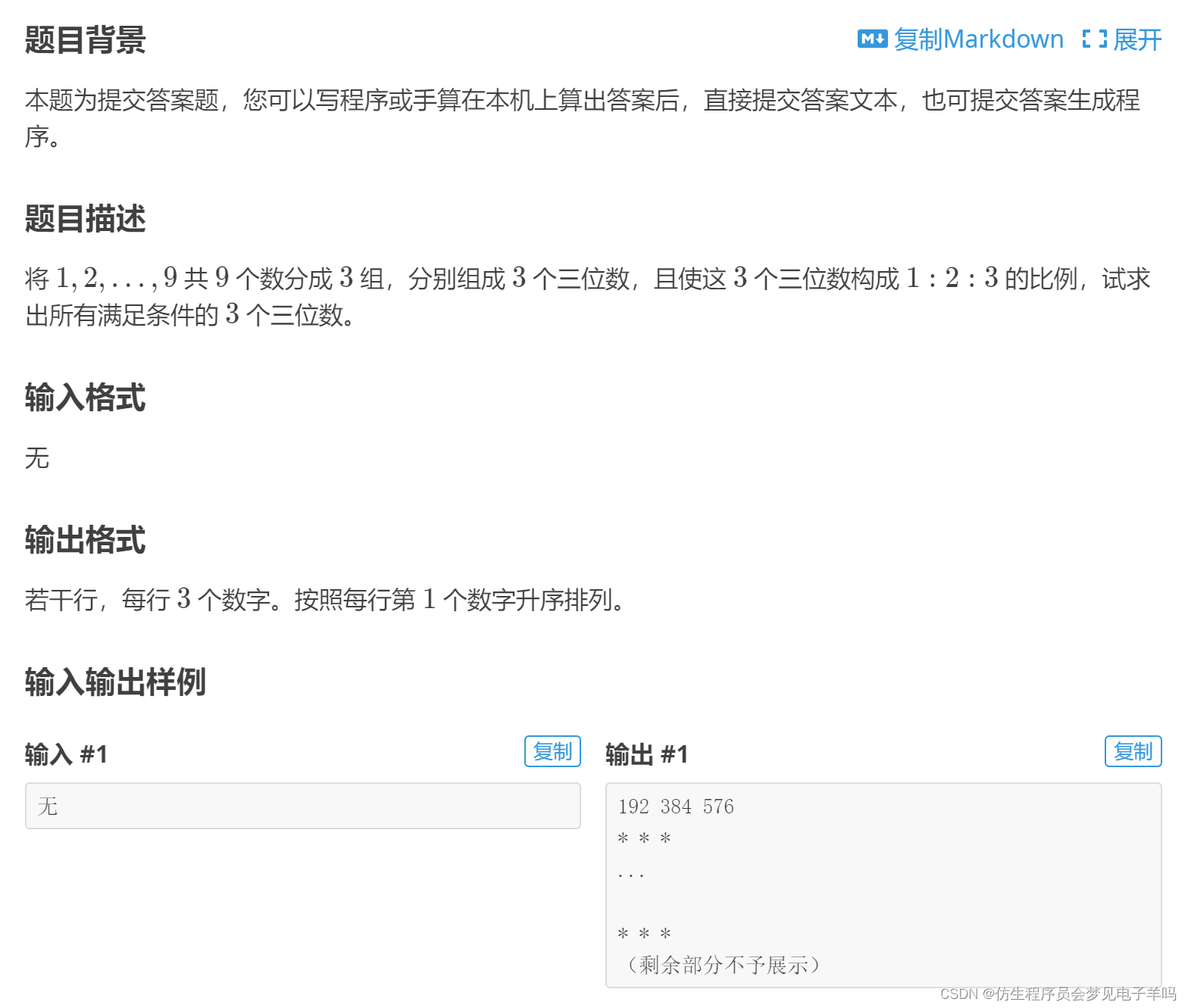
192 384 576
219 438 657
273 546 819
327 654 981
从123(最小)枚举,abc;abc2;abc3
当然,还有一种方法:
三个数 之比分别为1:2:3,也可以将第一个数设为a,从1开始(123,246,369)依次枚举,直到满足条件
可以用三个数字的每一位相加为45作为限制
题解:
https://www.luogu.com.cn/problem/solution/P1008?page=1
递归
如果函数调用它本身,那么此函数就是递归的。

汉诺塔
法国数学家爱德华·卢卡斯曾编写过一个印度的古老传说:在世界中心贝拿勒斯(在印度北部)的圣庙里,一块黄铜板上插着三根宝石针。印度教的主神梵天在创造世界的时候,在其中一根针上从下到上地穿好了由大到小的64片金片,这就是所谓的汉诺塔。不论白天黑夜,总有一个僧侣在按照下面的法则移动这些金片:一次只移动一片,不管在哪根针上,小片必须在大片上面。僧侣们预言,当所有的金片都从梵天穿好的那根针上移到另外一根针上时,世界就将在一声霹雳中消灭,而梵塔、庙宇和众生也都将同归于尽。
2
n
−
1
2^n-1
2n−1
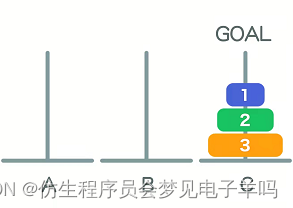
一个:1次
两个:3次
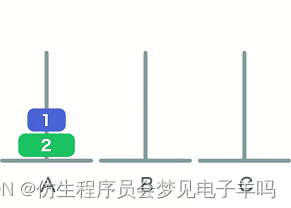
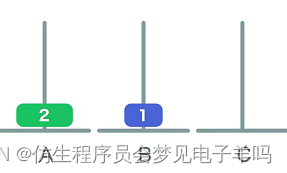
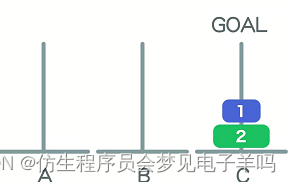

三个:7次
1—>C
2—>B
1—>B
3—>C
1—>A
2—>C
1—>C
n个:
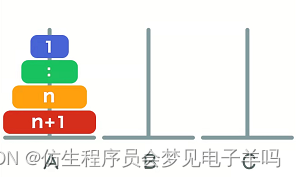
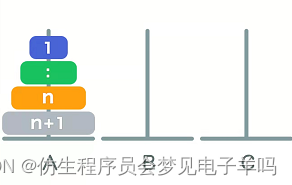
移动n个的次数+把最底层移动到C的次数(1次)+移动n个的次数
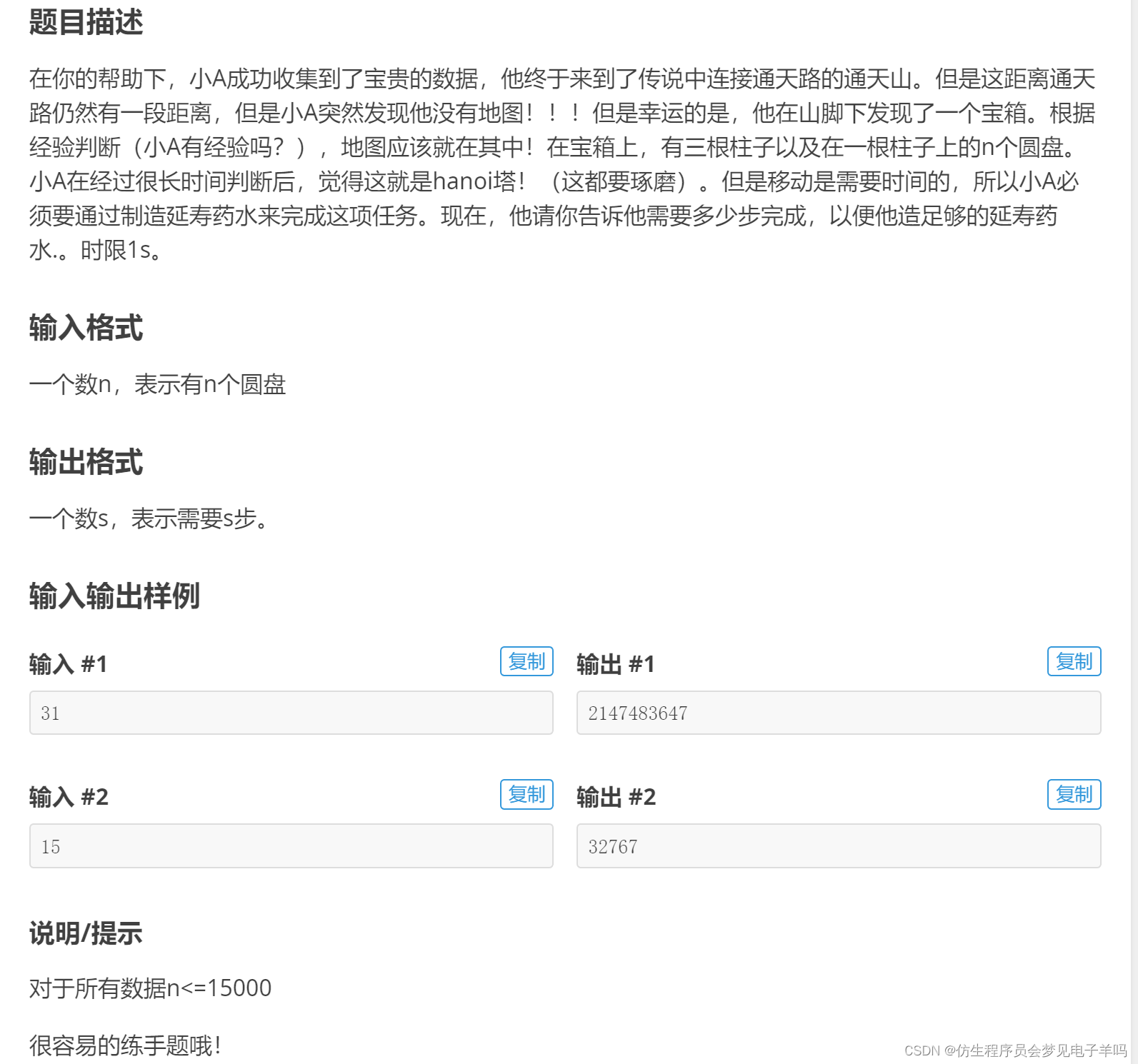
题解:
https://blog.csdn.net/Y673789476/article/details/124569813?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124569813-blog-82025409.t0_searchtargeting_v1&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124569813-blog-82025409.t0_searchtargeting_v1&utm_relevant_index=2
排序算法
| 算法 | 最坏情况运行时间 | 平均情况/期望运行时间 |
|---|---|---|
| 插入排序 | Θ ( n 2 ) Θ(n^2) Θ(n2) | Θ ( n 2 ) Θ(n^2) Θ(n2) |
| 归并排序 | Θ ( n l g n ) Θ(nlgn) Θ(nlgn) | Θ ( n l g n ) Θ(nlgn) Θ(nlgn) |
| 堆排序 | O ( n l g n ) Ο(nlgn) O(nlgn) | —— |
| 快速排序 | Θ ( n 2 ) Θ(n^2) Θ(n2) | Θ ( n l g n ) Θ(nlgn) Θ(nlgn)(期望) |
| 计数排序 | Θ ( k + n ) Θ(k+n) Θ(k+n) | Θ ( k + n ) Θ(k+n) Θ(k+n) |
| 基数排序 | Θ ( d ( k + n ) ) Θ(d(k+n)) Θ(d(k+n)) | Θ ( d ( k + n ) ) Θ(d(k+n)) Θ(d(k+n)) |
| 桶排序 | Θ ( n 2 ) Θ(n^2) Θ(n2) | Θ ( n 2 ) Θ(n^2) Θ(n2)(平均情况) |
插入法
冒泡排序
冒泡排序(相邻比序法)是一种简单的交换类排序方法,它是通过对相邻的数据元素进行交换,逐步将待排序序列变成有序序列的过程。
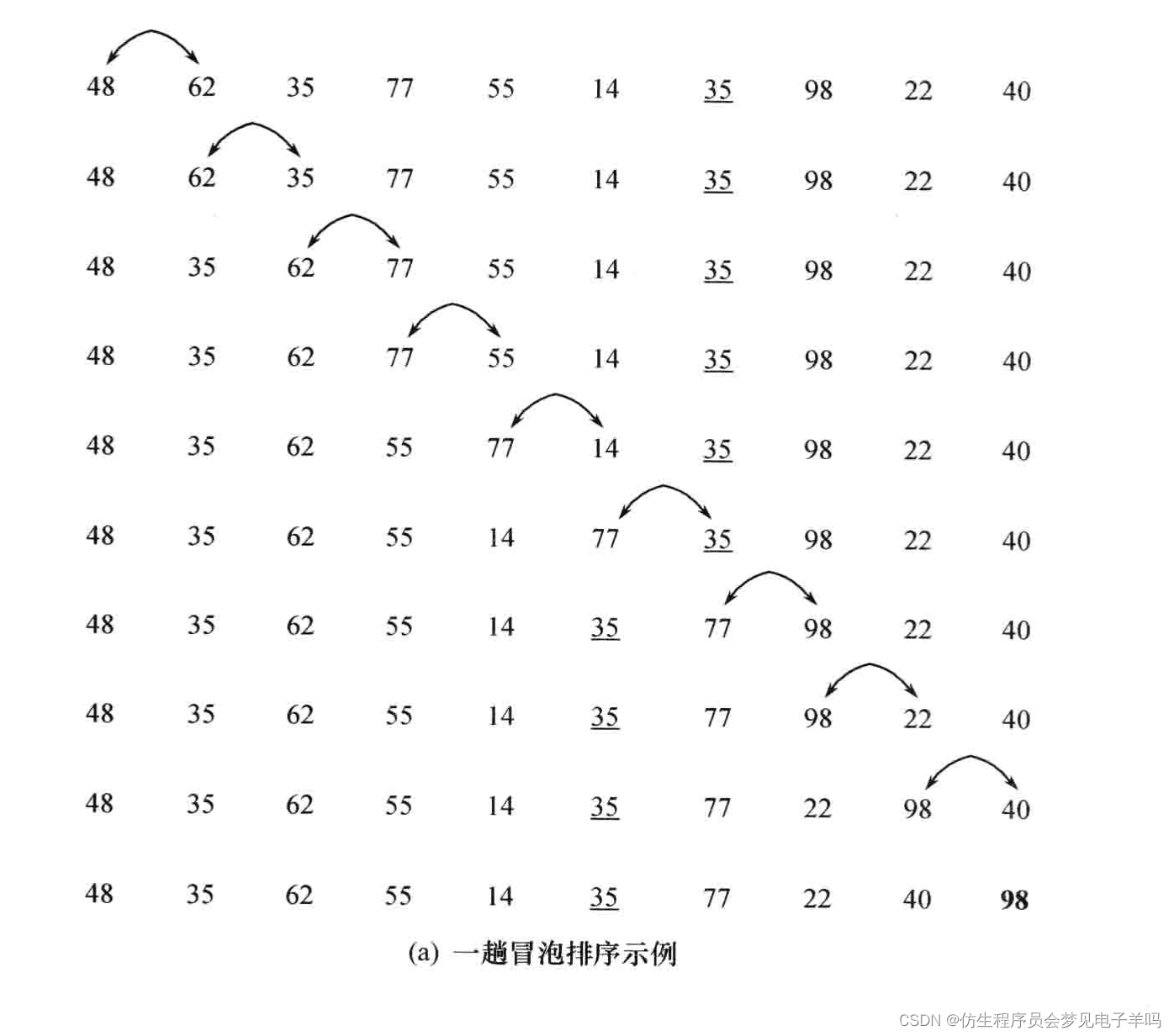
反复扫描待排序记录序列,顺次比较相邻的两个元素的大小,若逆序就交换位置。
在扫描的过程中,不断地将相邻记录中关键字大的记录向后移动,最后必然将待排序记录序列中最大关键字换到序列的末尾,这也是最大关键字记录应在的位置
然后进行第二趟冒泡排序,对前n-1个记录进行同样的操作,其结果是使次大的记录被放在第n-1个记录的位置上
然后进行第三趟冒泡排序,对前n-2个记录进行同样的操作,其结果是使次大的记录被放在第n-2个记录的位置上
如此反复,每一趟冒泡排序都将一个记录排到位,直到剩下一个最小的记录。
如果在某一趟冒泡排序的过程中,没有发现一个逆序,则可直接结束整个排序过程,所以冒泡排序过程最多进行n-1次。
给出序列{48,62,35,77,55,14,35,98,22,40}的第一次冒泡排序过程。
分治算法
众所周知,弗兰大学的总图书馆距离寝室非常遥远,来回不便。
有⼀天热爱看书的电子羊同学到图书馆借了 N 本书,出图书馆的时候,警报响了,于是保安把热爱看书的电子羊同学拦下,要检查⼀下哪本书没有登记出借。热爱看书的电子羊同学正准备把每⼀本书在报警器下过⼀下,以找出引发警报的书,但是保安露出不屑的眼神:你连二分查找都不会吗?于是保安把书分成两堆,让第⼀堆过⼀下报警器,报警器响;于是再把这堆书分成两堆…… 最终,检测了 logN 次之后,保安成功的找到了那本引起警报的书,露出了得意和嘲讽的笑容。于是阿东背着剩下的书走了。
从此,图书馆丢了 N - 1 本书。
许多有用的算法在结构上是递归的:为了解决一个给定的问题,算法一次或多次递归地调用其自身以解决若干子问题。
这些算法典型地遵循分治法的思想,将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。
二分搜索
假设有n个呈升序排列的数组元素(例如1~100),当我们需要查找一个数a究竟在哪个位置时,可以使用二分搜索:
将数组分为两份,用a的值比较n/2的值,如果大于则在(n/2,n]中,反之则小于,若等于则查找完毕。
将n/2分成两份,重复上述操作,直到找出值相等为止。
快速排序
递归常用于分治法中。分治法是将一个大问题划分成多个较小的问题,然后采用相同的算法分别解决这些小问题。
分治法的经典示例就是流行的排序算法:快速排序
假设要排序的数组的下标从1到n。
- 选择数组元素e(作为“分割元素”),然后重新排列数组使得元素从
1到i-1都是小于或等于元素e的,元素i包含e,而元素从i+1到n都是
大于或等于e的 - 通过递归地采用快速排序方法,对从1到i-1的元素进行排序
- 通过递归地采用快速排序方法,对从i+1到n的元素进行排序。

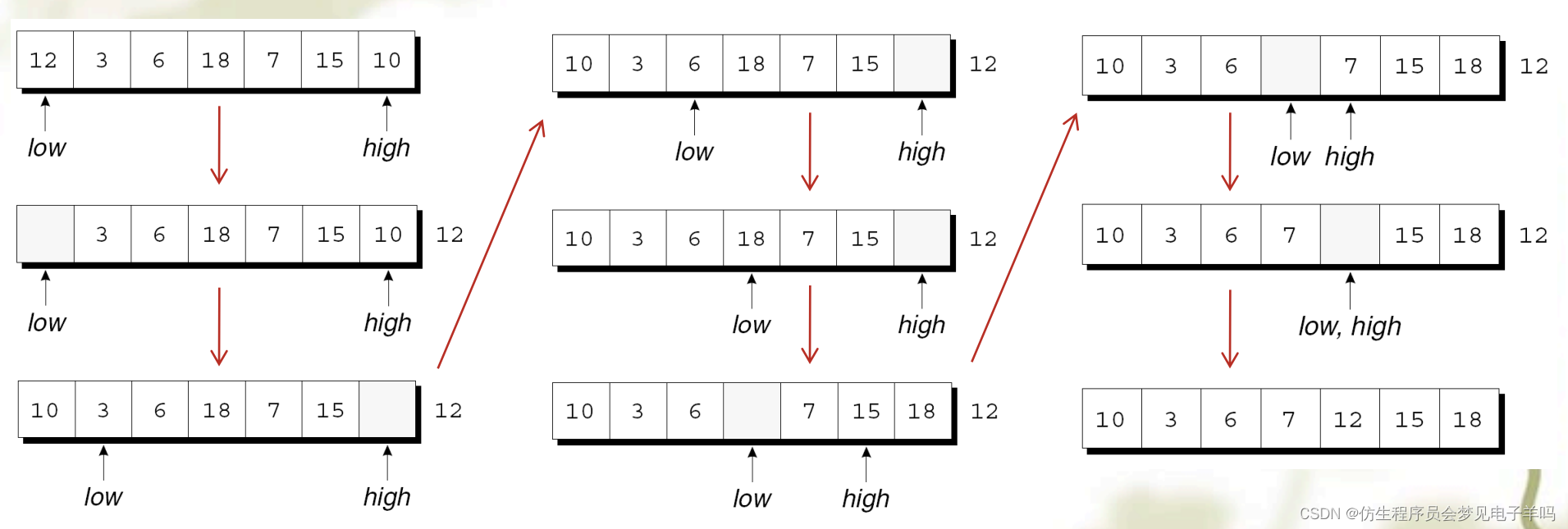
从最后一个图可以看出,分割元素左侧的所有元素都小于或等于12,而
其右侧的所有元素都大于或等于12。
既然己经分割了数组,那么就可以使用快速排序法对数组的前4个元素
(10,3,6,和7) 和后2个元素(15和18)进行递归快速排序了
让我们先来开发一个名为quicksort的递归函数,此
函数采用快速排序算法对整型数组进行排序

#include <stdio.h>
#define N 10
void quicksort(int a[], int low, int high);
int split(int a[], int low, int high);
int main(void)
{
int a[N], i;
printf("Enter %d numbers to be sorted: ", N);
for (i = 0; i < N; i++)
scanf("%d", &a[i]);
quicksort(a, 0, N - 1);
printf("In sorted order: ");
for (i = 0; i < N; i++)
printf("%d ", a[i]);
printf("\n");
return 0;
}
void quicksort(int a[], int low, int high)
{
int middle;
if (low >= high) return;
middle = split(a, low, high);
quicksort(a, low, middle - 1);
quicksort(a, middle + 1, high);
}
int split(int a[], int low, int high)
{
int part_element = a[low];
for (;;) {
while (low < high && part_element <= a[high])
high--;
if (low >= high) break;
a[low++] = a[high];
while (low < high && a[low] <= part_element)
low++;
if (low >= high) break;
a[high--] = a[low];
}
a[high] = part_element;
return high;
}
动态规划
动态规划通常用来解决最优化问题。
这类问题有很多可行解,每个解都有一个值,我们希望寻找到具有最优值(最大值或最小值)的解。
我们称这样的解为问题的一个最优解,而非最优解(因为可能有多个解都达到最优值。)
钢条切割
贪心算法
贪心算法在每一步都做出当时看起来最佳的选择。
总是做出局部最优的选择,寄希望于这样的选择能够导致全局最优解。
运用贪心策略在每一次转化时都取得了最优解。问题的最优子结构性质是该问题可用贪心算法求解的关键特征。贪心算法的每一次操作都对结果产生直接影响。贪心算法对每个子问题的解决方案都做出选择,不能回退。
贪心算法,一次遍历,只要今天价格小于明天价格就在今天买入然后明天卖出,时间复杂度O(n)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









