






背景
随着大模型技术的快速发展,开源大模型在自然语言处理、代码生成、多语言理解等领域的应用日益广泛。
Qwen3是 Qwen 系列大型语言模型的最新成员。其旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
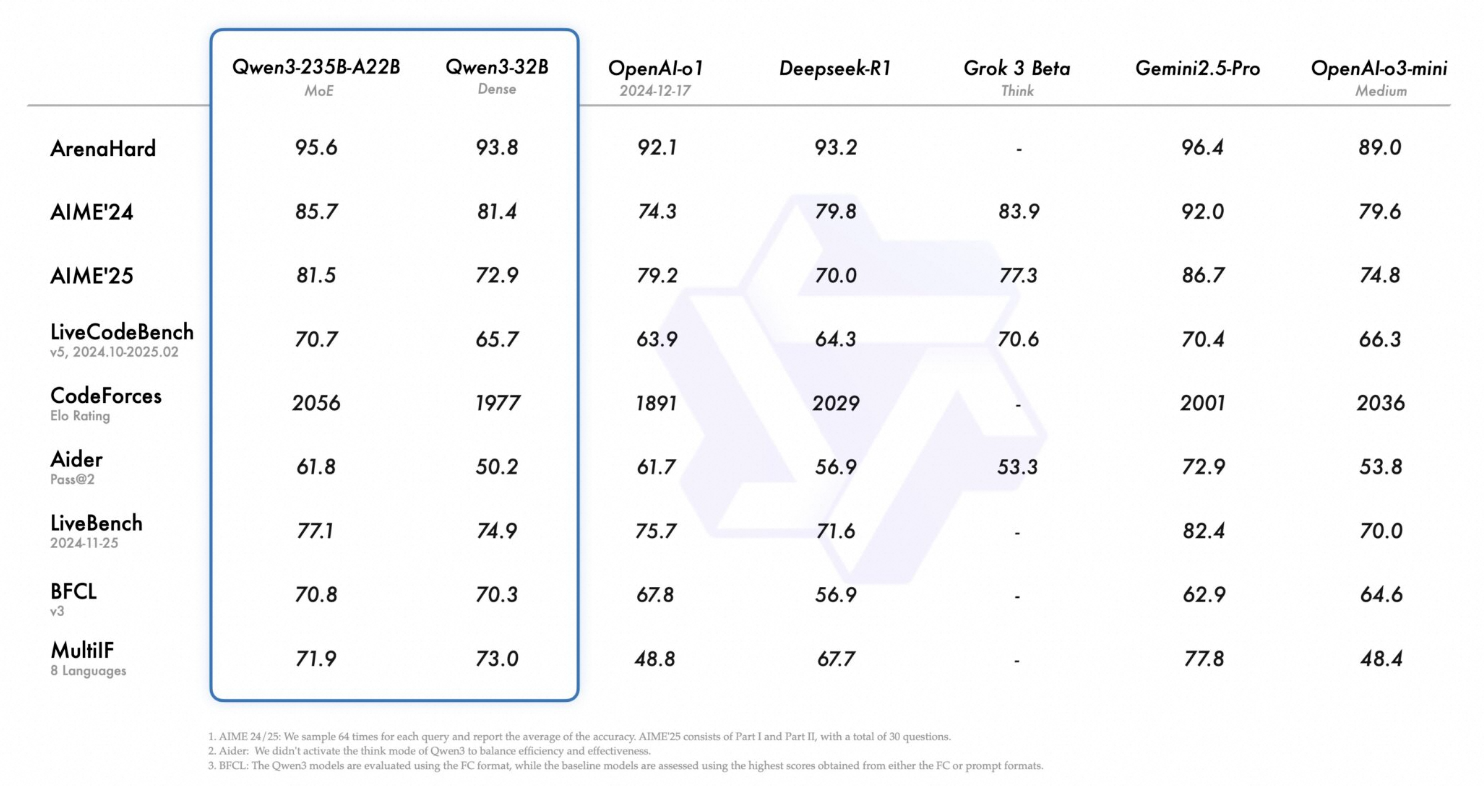
为帮助个人用户与企业用户便捷地拥有专属Qwen3模型服务,阿里云计算巢推出了Qwen3一键部署方案。该方案让用户无需深入理解底层技术细节,即可在 30分钟内 快速完成模型环境搭建与服务启动,真正实现“开箱即用”的企业级超大模型服务。该方案支持Vllm或Sglang部署,默认采用Vllm部署,支持用户自定义部署参数。详情可参考用户部署文档。
为什么选择Qwen3一键部署方案?
- 极速部署,省时省力
从部署配置到服务启动,整个流程只需30分钟,大幅缩短部署时间,助力用户快速上手。 - 开箱即用,零技术门槛
预置标准化环境与自动化编排模板,让用户无需关心底层技术细节,专注于业务创新。 - 高性能优化,低延迟高可用
阿里云GPU异构团队提供模型高性能推理优化,确保Qwen3在企业级场景中实现高可用。 - 灵活扩展,满足多样化需求
支持多种部署规模与场景,无论是单机部署还是分布式集群,都能轻松应对用户的不同需求。
本方案支持一键部署的模型
Qwen系列:
Deepseek系列:
- deepseek-ai/DeepSeek-R1(671B,双机版)
- deepseek-ai/DeepSeek-V3(双机版)
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
部署流程
-
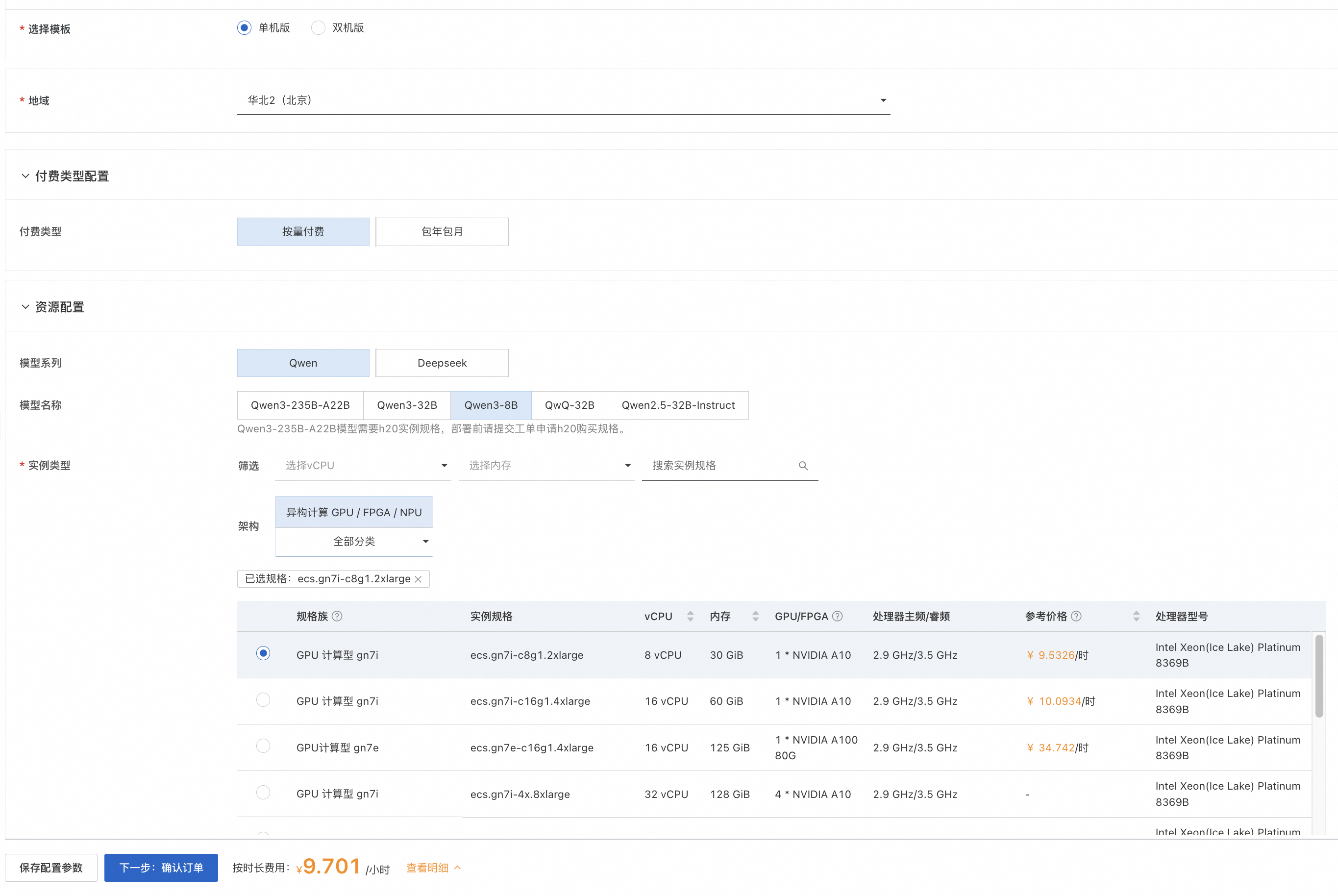
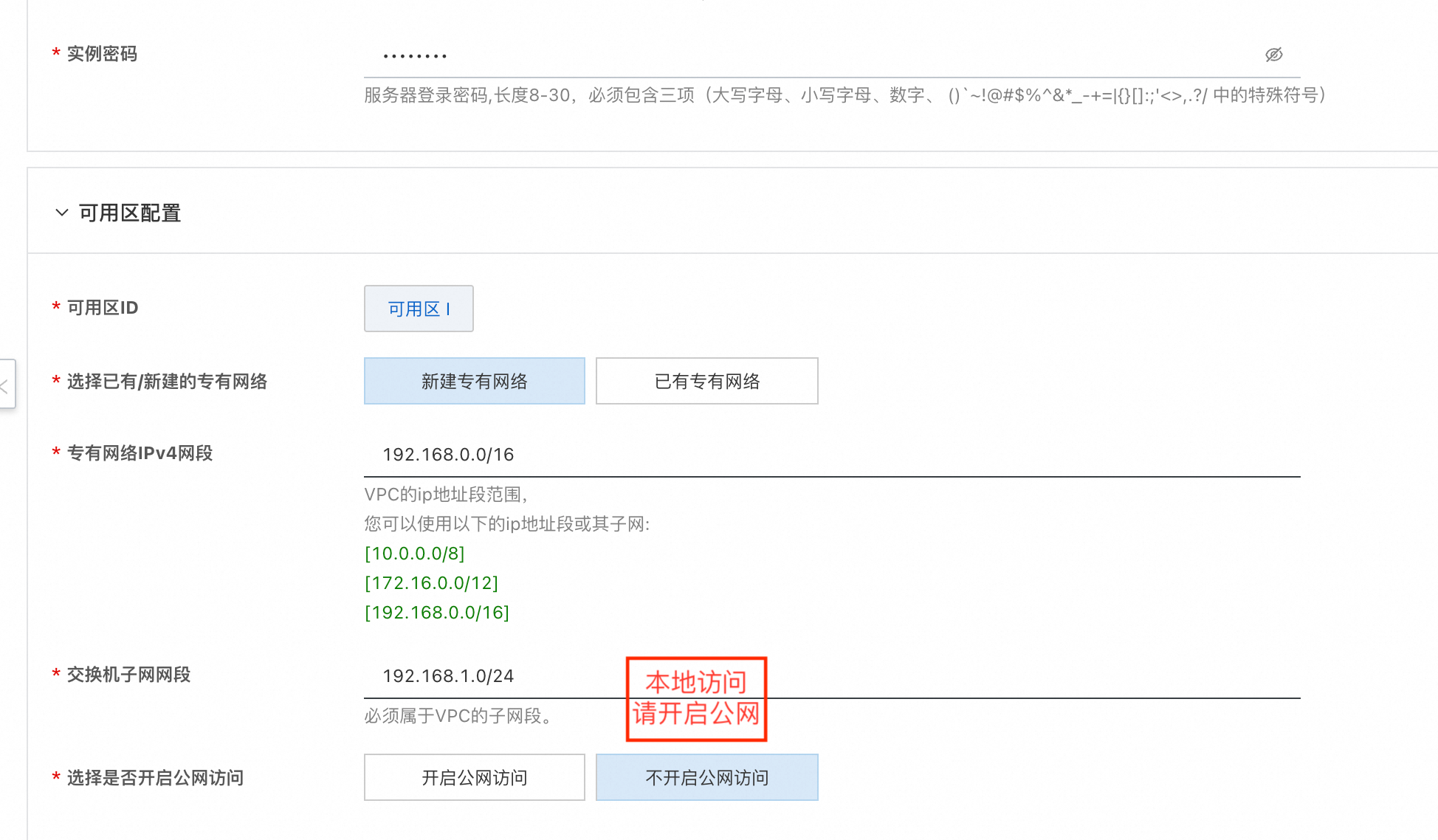
单击部署链接。选择单机版,个人用户建议选择Qwen3-8B。Qwen3-32B需8*A10以上实例规格,Qwen3-235B-A22B需提交工单申请H20实例规格。根据界面提示填写参数,可根据需求选择是否开启公网,可以看到对应询价明细,确认参数后点击下一步:确认订单。
-
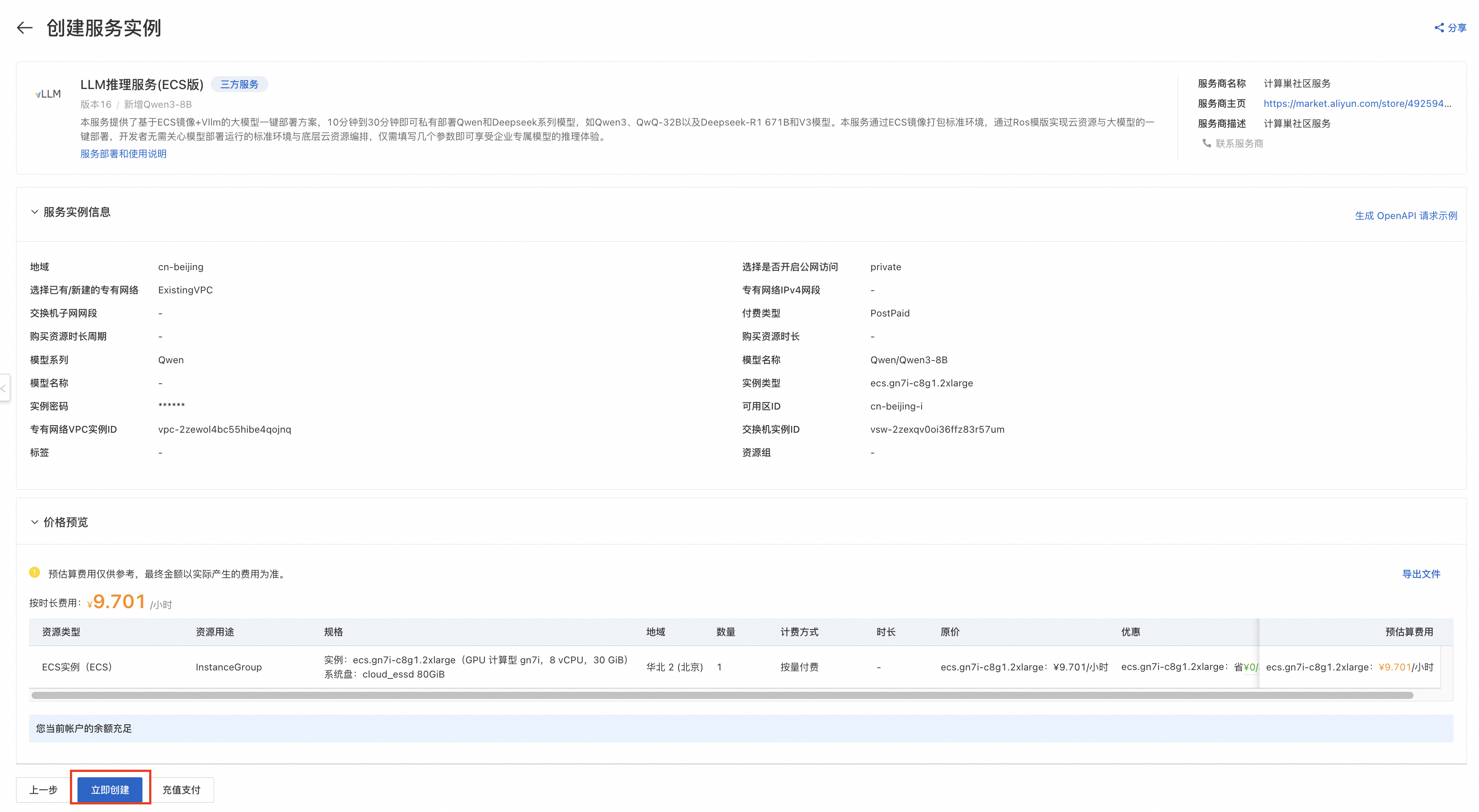
点击下一步:确认订单后可以看到价格预览,随后可点击立即部署,等待部署完成。
-
等待部署完成后,就可以开始使用服务了。点击服务实例名称,进入服务实例详情,使用Api调用示例即可访问服务。如果是内网访问,需保证ECS实例在同一个VPC下。
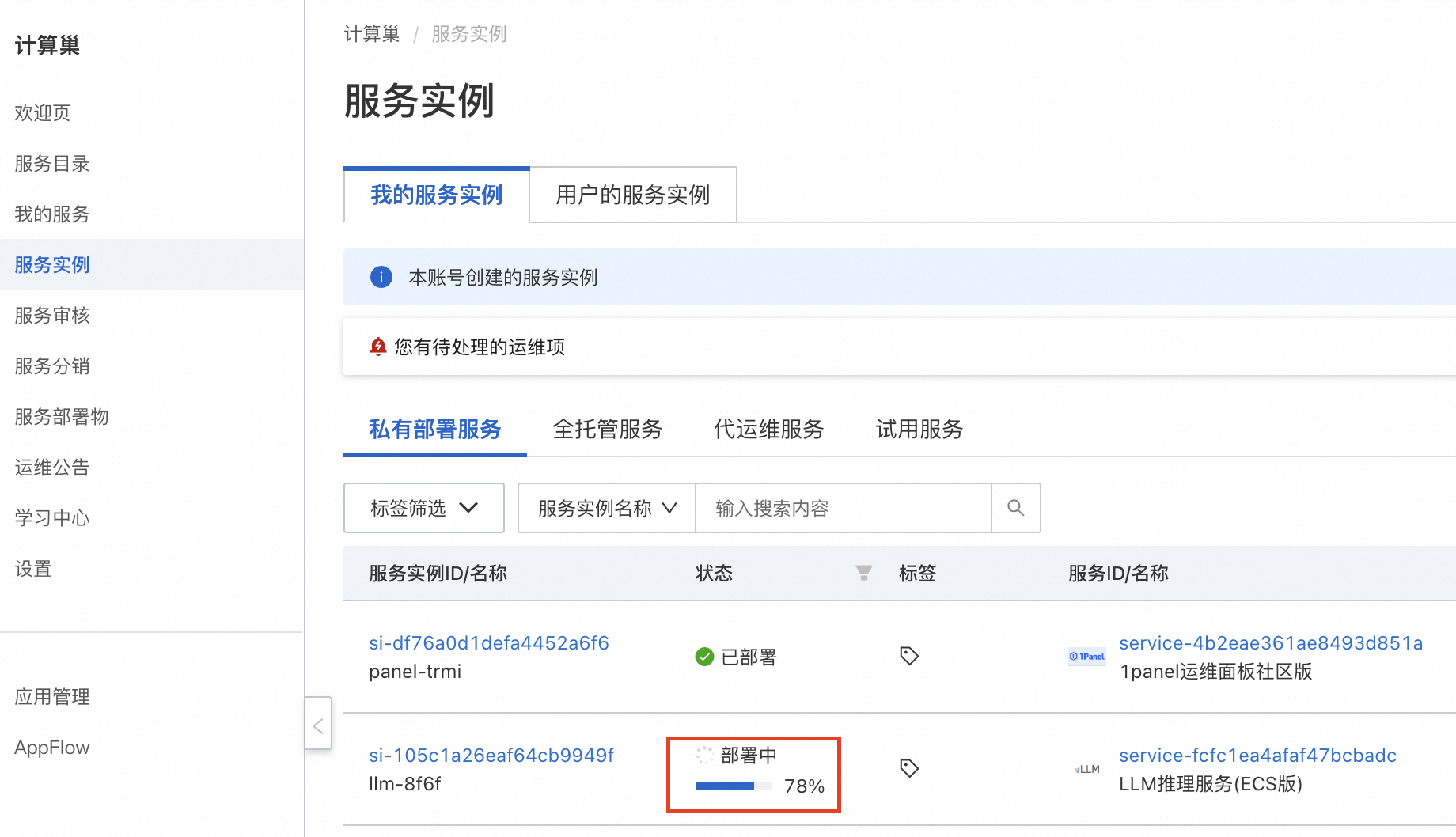

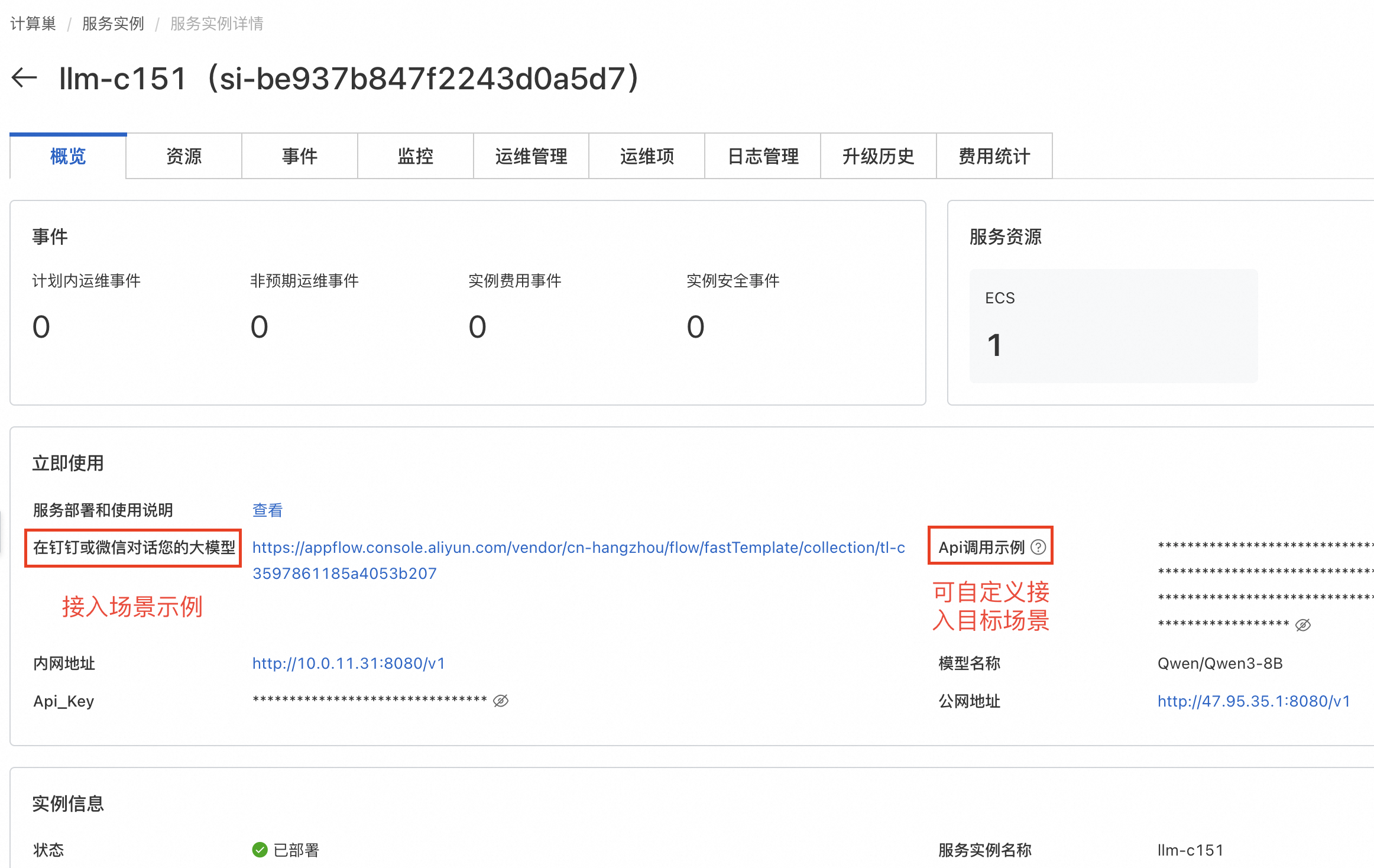
使用说明
公网API访问
复制Api调用示例,在本地终端中粘贴Api调用示例即可。默认为流式响应,将stream改为false即可关闭。content中为用户所提问题。
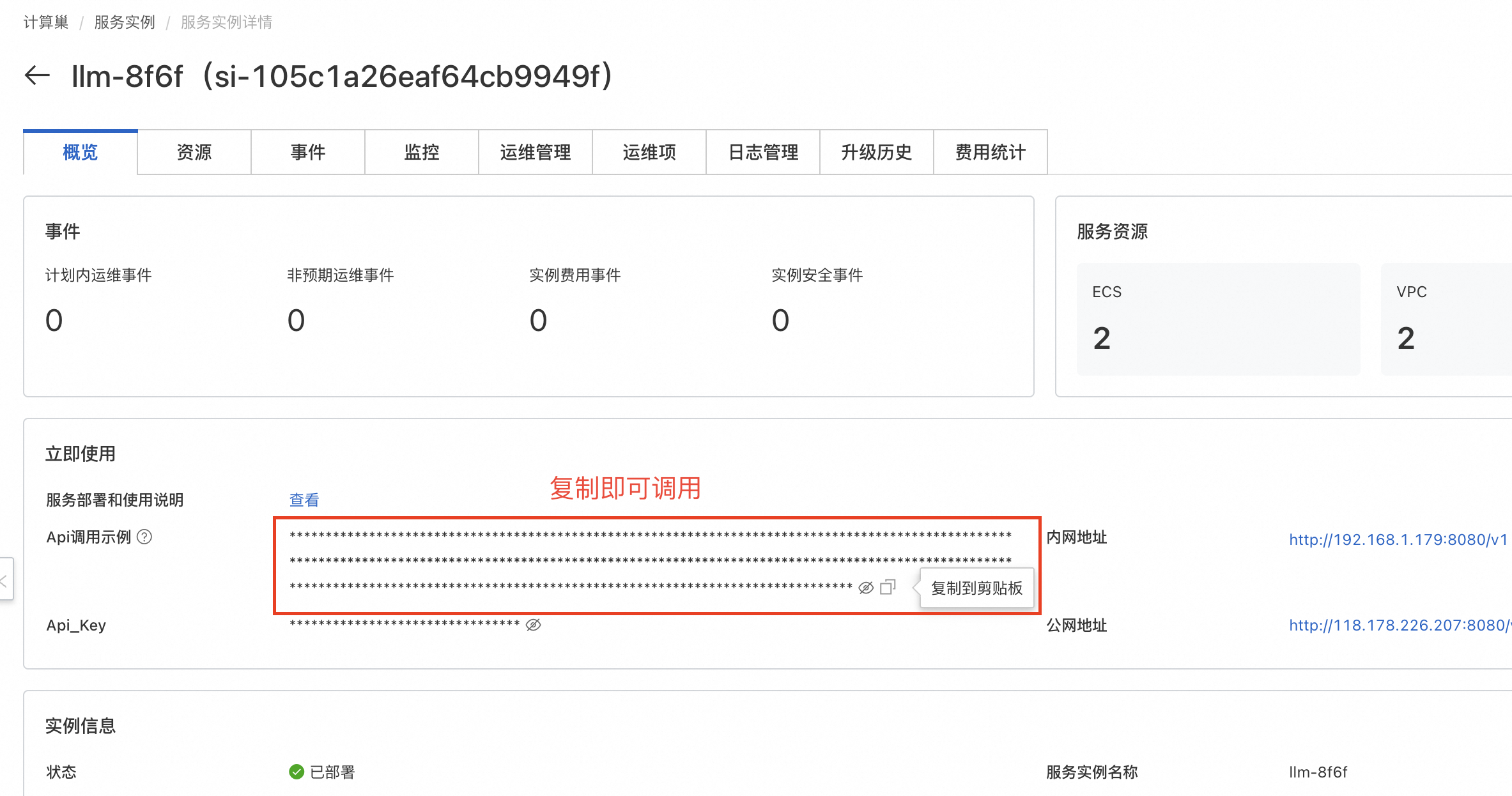

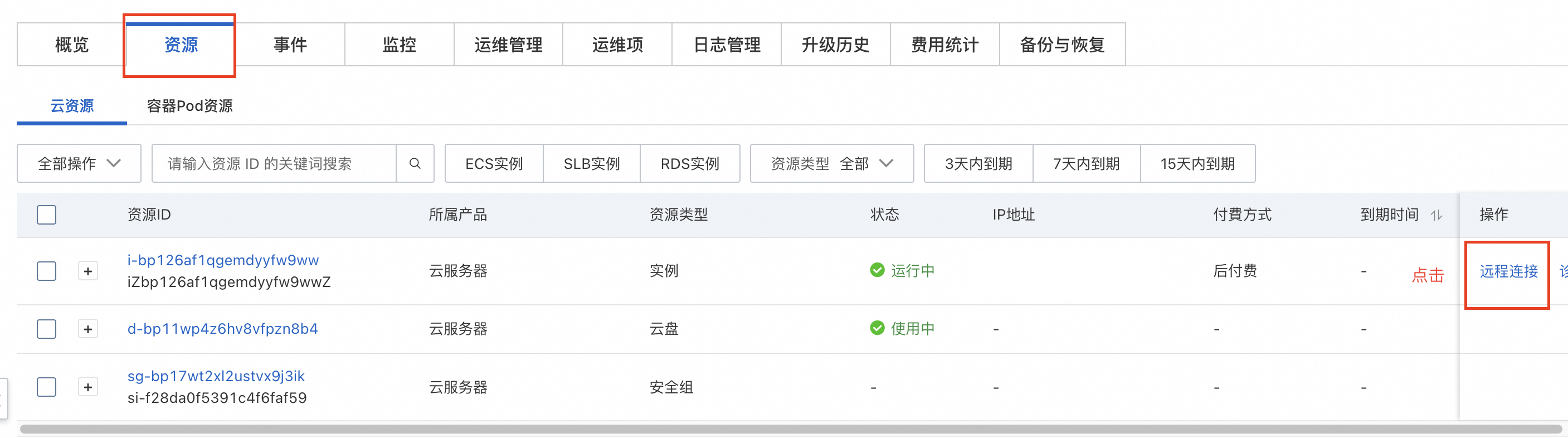
内网API访问
复制Api调用示例,在资源标签页的ECS实例中粘贴Api调用示例即可。也可在同一VPC内的其他ECS中访问。默认为流式响应,将stream改为false即可关闭。content中为用户所提问题。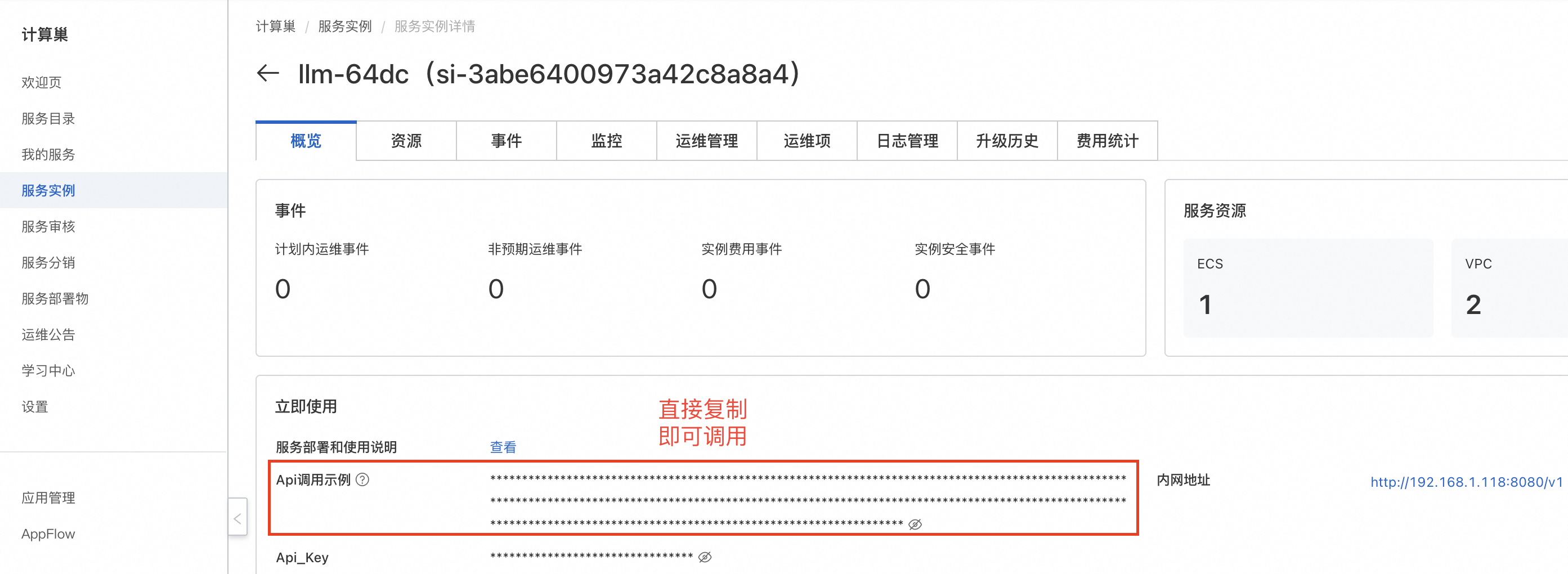

性能测试
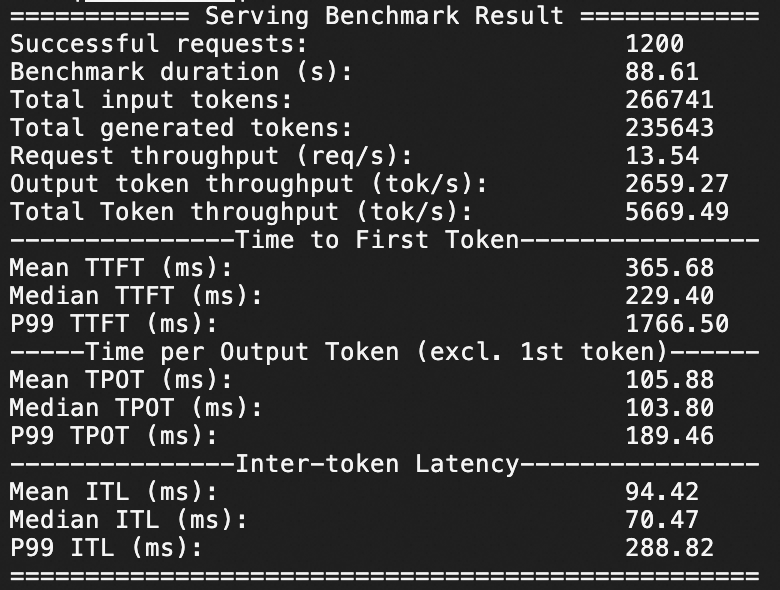
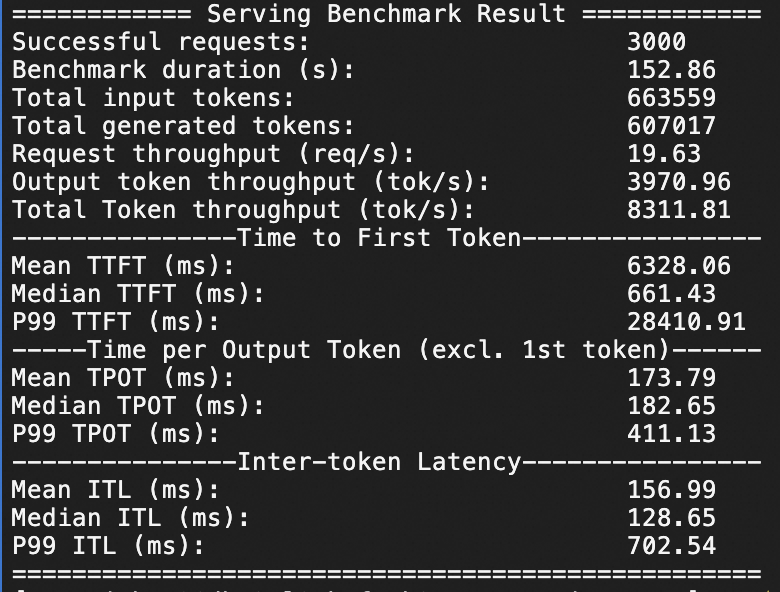
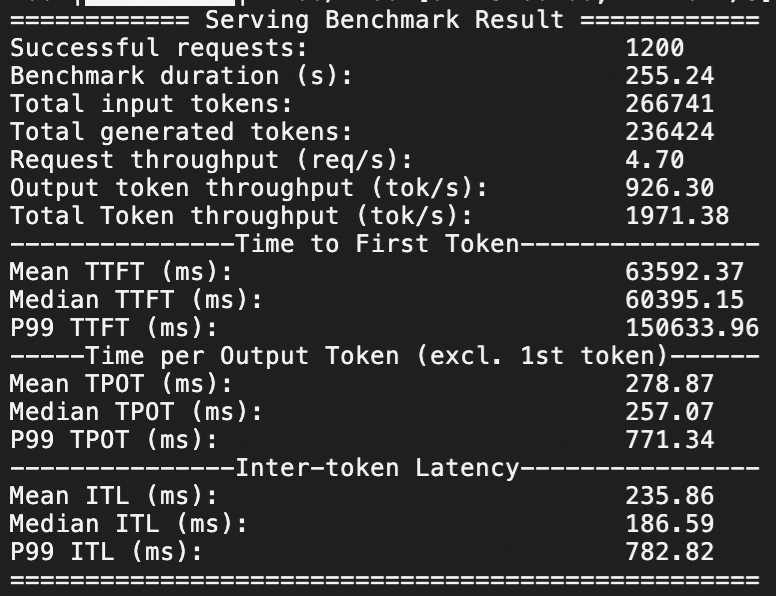
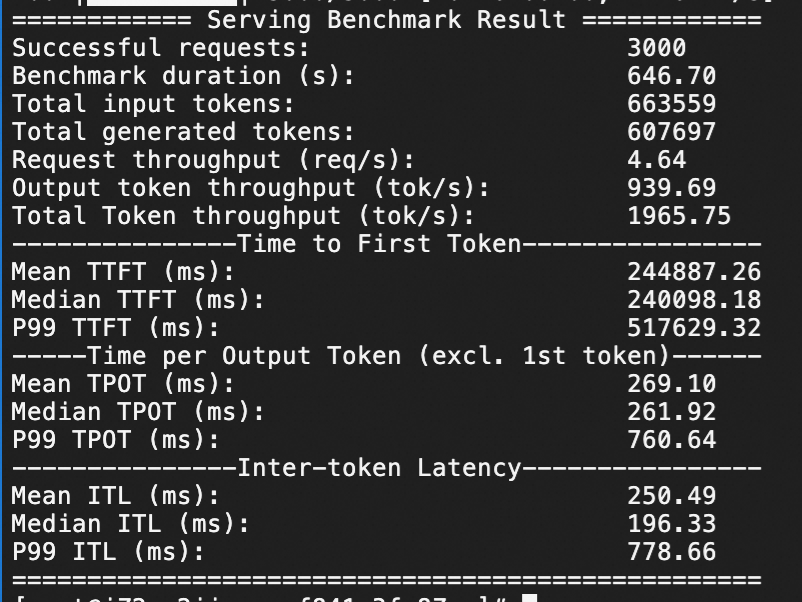
Qwen3-235B-A22B压测结果
本服务方案下,针对Qwen3-235B-A22B在ecs.ebmgn8v.48xlarge(H20)实例规格下,分别测试QPS为20情况下模型服务的推理响应性能,压测持续时间均为1分钟。
H20规格
QPS为20,1分钟1200个问答请求
QPS为50,1分钟3000个问答请求
Qwen3-32B压测结果
本服务方案下,针对Qwen3-32B在ecs.gn7i-8x.16xlarge(8*A10)实例规格下,分别测试QPS为20情况下模型服务的推理响应性能,压测持续时间均为1分钟。
8*A10规格
QPS为20,1分钟1200个问答请求
QPS为50,1分钟3000个问答请求


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









